跪求王者荣耀推塔以及杀人时的英语语音!比如“双杀”就是double killed,跪求大杀特杀,三
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了跪求王者荣耀推塔以及杀人时的英语语音!比如“双杀”就是double killed,跪求大杀特杀,三相关的知识,希望对你有一定的参考价值。
跪求王者荣耀推塔以及杀人时的英语语音!比如“双杀”就是double killed,跪求大杀特杀,三杀,四杀,五杀,终结,我方防御塔被摧毁,摧毁敌方防御塔,被防御塔击杀的英语单词!词组!感激不尽!

一血:佛斯特不辣的 第一个血液(就这个最准)
终结:傻挡(本来应该是傻特挡,但是“特”被连读省略了) 停止下来
大杀特杀:KO(哦)零 死破瑞 前三个连读,后三个连读。 无节制的欢乐杀戮😂
杀人如麻:乳癌(读到一起,ruai)母配置 暴怒(真的😂)
无人能挡:暗四道破波哦(波哦 读到一起去,类似bou) 不能停止的
像神:搞的来客 像神(😂)。。。
天下无爽:来真的瑞 传说😂
kill读法:(几杀都是xxx kill)kì哦(杀)
双杀:大波哦(波哦老规矩读一起 bou) kill 直译也是双杀,用了double(两个的而不是two(就是二))
三杀:锤波哦(老规矩) kill 三倍的杀戮(三倍的,所以不是three)
四杀:苦熬(读到一起,类似kuao)拽 kill(quatra应该是前缀一类,标准意思是正方形框架(但是这里肯定不是))
五杀:喷他kill(penta也是前缀(美国口语指五角大厦(不准😂。。)))
团灭:à死特(特 读的要轻) 被彻底击败(可以算输了吧😂)
队友杀人了:暗 爱呢(nē)迷 孩子 宾 死累摁 一个敌人被击杀了(后面就没啥了)
队友挂了:暗 爱来 孩子 宾 死累摁 一个同盟者被杀了
你杀人了:有 海雾 死累摁 暗 爱呢(nē)迷(我这个没咋听到过😂) 你已经杀死了一名敌人
被杀了。。:有 海雾 宾 死累摁。 (你被杀死了)
被塔打死(当然也可以是小兵):艾克斯Qtèi的 (被处死(这个给力))
塔没了:要 特若特 孩子 宾 第四找爱的 你的炮塔已经被摧毁了。
推塔了:要 特母 孩子 第四找爱的 择 特若特 你的队伍已经摧毁了一个炮塔。
纯手打,就希望大家看着爽。再重申一遍,汉字按英文还原不是纯听的,所以准确度可靠,你可以按记忆中的音调念。
用宇宙玩
参考技术A all kill3 tri-kill
4 quart-kill
5 quaint-kill
over
our defence is down
put down their defences
killed by defences
(maybe再加个tower?的确不太了解防御塔是什么东西)
如果对你有帮助请采纳谢谢。追问
谢谢了
不过终结好像是shut down
本回答被提问者和网友采纳Python爬取王者荣耀全英雄台词语音及对应的文本
写在前面
很久之前就萌生了想爬取王者荣耀英雄台词语音,因为语音资源不是很好找,从官网获得的话,也比较麻烦。最近刚好有朋友需要语音素材,于是我就顺便帮了他一把。
完成这次爬虫,前前后后大概花了8个小时左右,用了之前没用到的库,和一些函数用法,导致bug,以至于花费时间来解决。而且因为自己过于盲目地爬取,一开始没有具体分析,到后来慢慢完善,总共写了三个版本。通过这次的练习,自己也有些许收获。
第一个版本,写一半发现,爬取失败;
第二个版本,能够顺利爬取语音及相关文本,但是不够全面;
第三个版本,顺利地爬取了全部语音及相关文本,并进行合理地合成,方便欣赏。
本文主要介绍第三个版本。
环境
- python3.9
- pycharm
网页分析
首先来到含有英雄全部语音的页面
https://pvp.qq.com/story201904/index.html#/voice?id=144
进入网页后,进行检查,如下图,找到data_zlk_lb.json这个文件,可以很清晰的见到想要爬取的台词语音及相关的文本。
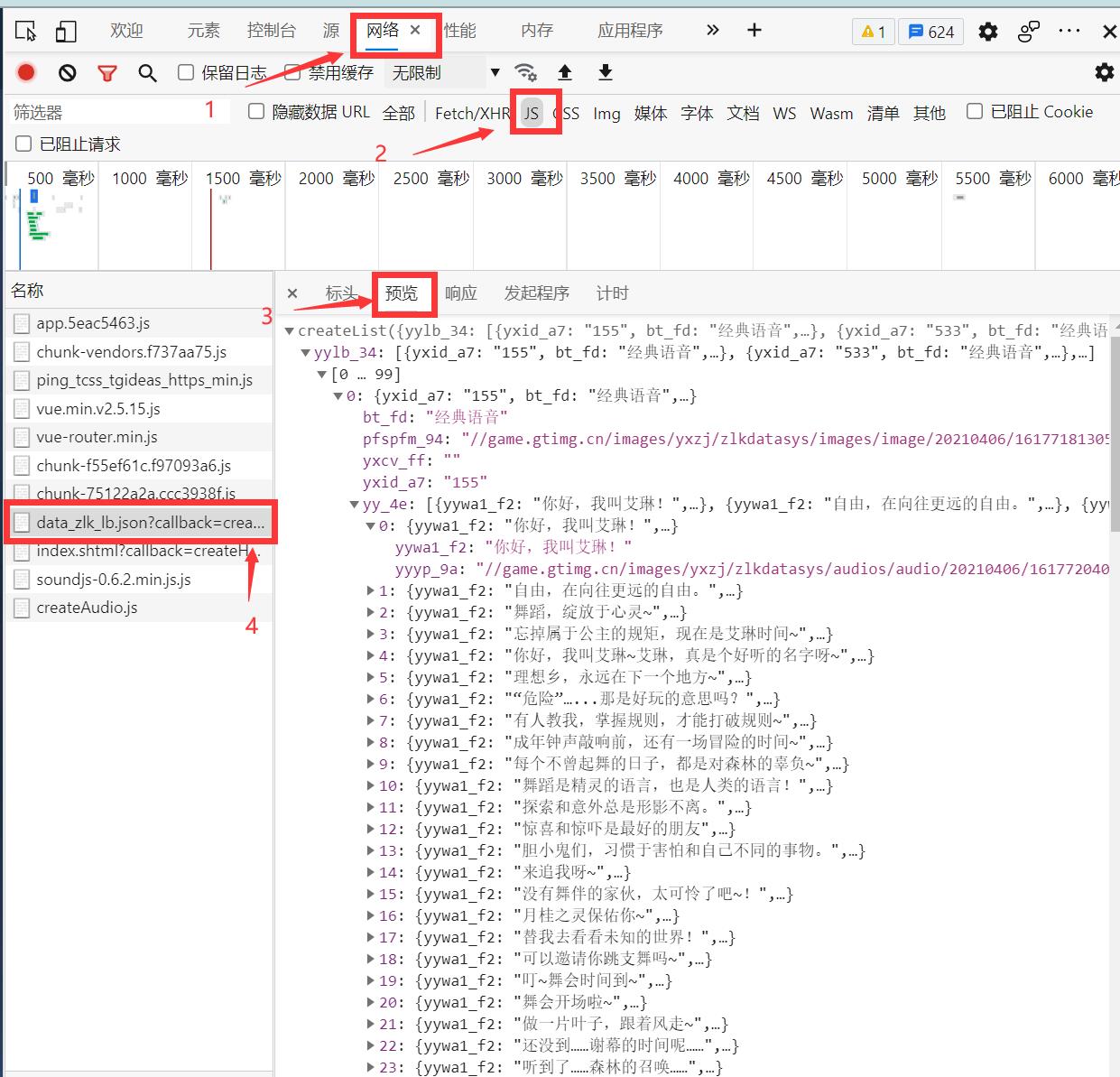
切换到标头,即可找到需要的URL
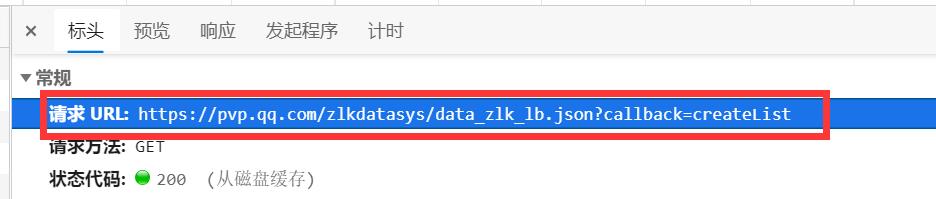
到这,目标一就找到了。
- 如:取一个语音的MP3文件链接,做演示
//game.gtimg.cn/images/yxzj/zlkdatasys/audios/audio/20210406/16177204029921.mp3
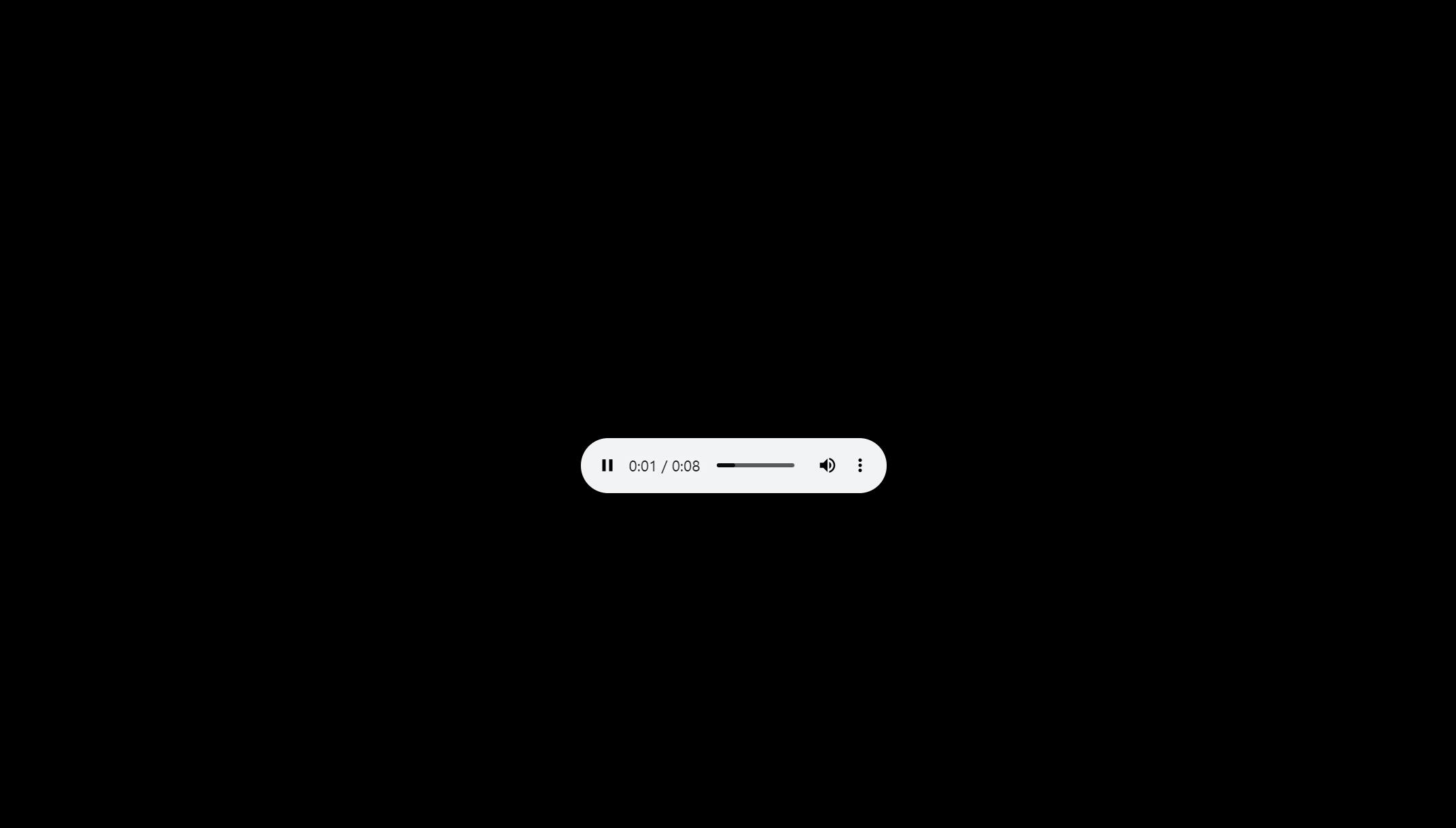
这八秒的语音对应的台词就是:你好,我叫艾琳!
有了目标一,是不是有小伙伴想问,难道还有目标二?
当然!因为在这个页面,除了这些,我们最多还能得到的是声优的信息,和英雄的编号,得不到英雄的名称,不方便最后文件的命名。
为了提高最后文件的可读性,最好能够台词与英雄名相匹配。
匹配的关键桥梁就是,英雄编号!
可以来到第二个详情页:英雄资料页面
https://pvp.qq.com/web201605/herolist.shtml
其实,我之前有写过一篇关于这个页面的内容爬取,可以参考一下:
python爬取王者荣耀英雄的背景故事
这样就完成了目标二。
更多的思路体现在代码的注释中
爬虫代码实现及说明
# -*- coding: UTF-8 -*-
"""
# @Time: 2021/8/10 12:13
# @Author: 远方的星
# @CSDN: https://blog.csdn.net/qq_44921056
"""
import os
import re
import json
import requests
import chardet
from pydub import AudioSegment
from fake_useragent import UserAgent
# 随机产生请求头
ua = UserAgent(verify_ssl=False, path='D:/Pycharm/fake_useragent.json')
# 提前创建一个文件夹,方便创建子文件夹
path_f = "./王者语音"
if not os.path.exists(path_f):
os.mkdir(path_f)
# 随机切换请求头
def random_ua():
headers = {
"accept-encoding": "gzip", # gzip压缩编码 能提高传输文件速率
"user-agent": ua.random
}
return headers
# 创建文件夹
def path_creat(name):
_path = "./王者语音/{}/".format(name)
if not os.path.exists(_path):
os.mkdir(_path)
return _path
# 下载语音内容
def download(file_name, text, path): # 下载函数
file_path = path + file_name
with open(file_path, 'wb') as f:
f.write(text)
f.close()
# 获取英雄名称及对应编号
def get_hero_num():
url = 'https://pvp.qq.com/web201605/js/herolist.json'
response = requests.get(url=url, headers=random_ua()).text
hero_list = re.findall('"ename": (.+?),', response, re.S) # 得到英雄的编号列表
hero_name = re.findall('"cname": "(.+?)"', response, re.S) # 得到英雄的名字列表
return hero_list, hero_name
def text_json():
url = 'https://pvp.qq.com/zlkdatasys/data_zlk_lb.json'
param = {
'callback': 'createList'
}
res = requests.get(url=url, headers=random_ua(), params=param)
res.encoding = chardet.detect(res.content)['encoding']
res = res.text.replace('createList(', '').replace(')', '') # 去掉不符合json格式的部分字符串数据
res_json = json.loads(res) # 将字符串json格式化
hero = res_json["yylb_34"] # 所有英雄语音信息
return hero
# 处理台词文本
def text_deal(text):
text_result = '' # 为台词连接做准备
for j in range(len(text)):
text_result += text[j] # 将台词连起来
text_result += '\\n\\n' # 加一个断句的换行符
text_result = text_result.encode(encoding='utf-8')
return text_result
def main():
hero_list, hero_name = get_hero_num() # 获取英雄编号及名称
hero_s = text_json()
for i in range(len(hero_s)): # len(hero_s)
hero = hero_s[i]["yxid_a7"] # 英雄编号
hero_index = hero_list.index(hero) # 获取英雄名称对应的索引
name_result = hero_name[hero_index] # 确定英雄名称
path = path_creat(name_result) # 创建子文件夹
voice_list = hero_s[i]["yy_4e"] # 语音列表
num = 1
text = []
silence = AudioSegment.silent(duration=1000) # 1秒的空期
try: # 有部分英雄的语音合成会失败
for j in range(len(voice_list)):
voice_text = voice_list[j]["yywa1_f2"] # 语音文本
text.append(voice_text) # 拼接文本
voice_url = 'http:' + voice_list[j]["yyyp_9a"] # 语音mp3的url
voice = requests.get(url=voice_url, headers=random_ua()).content
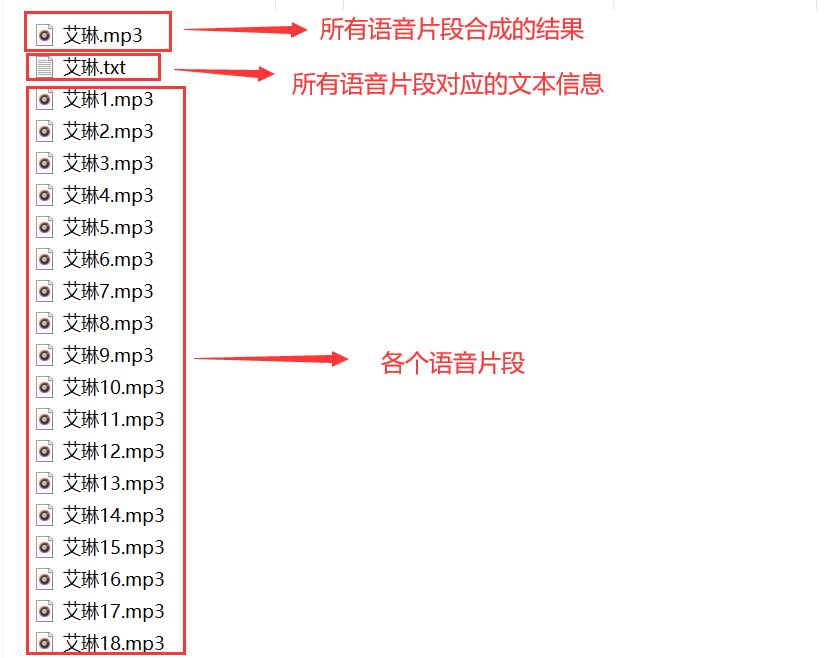
voice_name = name_result + '{}.mp3'.format(num)
download(voice_name, voice, path) # 下载单个语音
sound = AudioSegment.from_file(path + voice_name, format="mp3") # 读取下载的MP3文件
silence += sound # 语音合成
num += 1
silence.export(path + '{}.mp3'.format(name_result), format="mp3") # 导出合成语音
print('{}语音合成成功\\n'.format(name_result))
except:
print('{}语音合成失败\\n'.format(name_result))
text_result = text_deal(text) # 最终的文本
text_name = name_result + '.txt' # 语音文本文件名称
download(text_name, text_result, path) # 下载语音文本
print("{}的语音文本信息下载完毕!\\n".format(name_result))
if __name__ == '__main__':
main()
- 运行结果
- 代码的简单说明:
①、对于fake_useragent这个库,可以参考
Python爬虫有用的库:fake_useragent,自动生成请求头
②、对于chardet这个库,可以参考
③、对于pydub这个库,可以参考
④、为什么提前创立path_f = "./王者语音"
在练习的过程中,我发现,使用os.mkdir只方便创建下一个等级的目录,而我需要两级,所以提前创立了一个。
⑤、json.loads(),将字符串格式化
可以提前将爬取的txt文件,放到json在线解析,尝试一下。工具很多,
如:https://www.json.cn/
基本上出错的原因都是格式错误,常见的错误有,是""而不是''。本文中遇到的错误是,多了几个字符串,用replace替换掉,或者删除掉都可以,本文采取的替换。
- 其它说明
①、通过本文爬虫,可以帮助你了解 json 数据的解析和提取需要的数据。
②、本文利用 Python 爬虫一键下载王者荣耀英雄台词语音,实现过程中也会遇到一些问题,多思考和调试,最终解决问题,也能理解得更深刻。
③、代码可直接复制运行,如果对你有帮助,记得点个赞哦,也是对作者最大的鼓励,不足之处可以在评论区多多指正、交流。
作者:远方的星
CSDN:https://blog.csdn.net/qq_44921056
本文仅用于交流学习,未经作者允许,禁止转载,更勿做其他用途,违者必究。
以上是关于跪求王者荣耀推塔以及杀人时的英语语音!比如“双杀”就是double killed,跪求大杀特杀,三的主要内容,如果未能解决你的问题,请参考以下文章