基于netty的消息队列设计
Posted 杨龙飞的博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于netty的消息队列设计相关的知识,希望对你有一定的参考价值。
一.什么是消息队列
消息队列技术是分布式应用间信息交换的一种技术,消息队列可驻留在内存或磁盘上,队列存储消息直到它们被应用程序读走,通过消息队列,应用程序可以独立地执行,而不需要知道彼此的位置……….当然,上面所说,是比较抽象的,简单点来说,消息队列,就是一个消息的转发器,联系应用间关系的枢纽.
二.何时需要消息队列
上面简单了解了消息队列,那么,我们什么时候会用到消息队列,用它能给我们的程序带来什么好处,这是我们应该考虑的事情.当需要使用消息队列时,首先需要考虑它的必要性,可以使用mq的场景很多,比如说业务解耦/最终一致性/广播/错峰流控等,反之,如果需要强一致性性,RPC更合适.
1.解耦
解耦是消息队列要解决的最本质问题。所谓解耦,简单点讲就是一个事务,只关心核心的流程。而需要依赖其他系统但不那么重要的事情,有通知即可,无需等待结果。换句话说,基于消息的模型,关心的是“通知”,而非“处理”。
举个例子:我们注册成功一个网站,注册成功后往往需要向用户发送一个邮件通知,但是这其实已经不是我们系统的核心流程了,如果外部系统速度慢,就会有很大的延时,用户肯定不希望点击注册后几分钟后才看到结果,我们只需要通知邮件系统我们注册成功了,至于邮件什么时候发,不是用户直接在乎的.
2.最终一致性:
最终一致性指的是两个系统的状态保持一致,要么都成功,要么都失败。当然有个时间限制,理论上越快越好,但实际上在各种异常的情况下,可能会有一定延迟达到最终一致状态,但最后两个系统的状态是一样的。
举个例子:
大家都用支付宝给银行卡转过帐,如果支付宝扣钱成功,则银行卡加钱一定成功,反之则一起回滚.
最终一致性,主要是用“记录”和“补偿”的方式。在做所有的不确定的事情之前,先把事情记录下来,然后去做不确定的事情,结果可能是:成功、失败或是不确定,“不确定”(例如超时等)可以等价为失败。成功就可以把记录的东西清理掉了,对于失败和不确定,可以依靠定时任务等方式把所有失败的事情重新搞一遍,直到成功为止。
4.错峰与流控
试想上下流对于事情的处理能力是不同的,比如,Web前端每秒承受上千万的请求,并不是什么神奇的事情,只需要加多一点机器,再搭建一些LVS负载均衡设备和nginx等即可,但数据库的处理能力却十分有限,这时,消息队列就能处理这个问题,对于前端的请求先发送到消息队列中,数据库处理机器根据自己的最大处理能力从消息队列服务器上拉数据,消息队列上堆积的数据可以采用持久化,这样,即使处理会出现延时,但前端页面不会出现大量的无响应页面.
三.消息队列的设计
前面简单介绍了消息队列的基本概念.下面,我就说说我对自己个项目的
设计:
1.项目需求
- 实现一个基于发布订阅的消息队列.
- broker提供可靠的消息服务,要保证数据同步落盘后才能向生产者返回发送成功ACK,消费成功,失败都会返回ack.消费超时重投.
- 采用实时推送模式(暂时只考虑由broker push消息给消费者),消息一旦到达broker,要立马推送给消费者,消息延迟不能高于50ms.
- 消息支持简单的属性过滤.
- 消息存储基于文件系统(初步设想),自己实现一个简单的文件系统
- 消息要先持久化再给发送者响应发送成功,重启后消息数据不丢失.
暂时就想到这么多,以后优化还可以考虑消费者集群等……
2.消息队列包含的主要模块:
- broker:消息中间件服务器模块,负责消息的路由、负载均衡,对于生产者、消费者进行消息的应答回复处理(ACK),是连接生产者和消费者的桥梁枢纽.
- consumer:消息中间件中的消费者模块,负责接收生产者过来的消息,在设计的时候,会对消费者进行一个集群花管理,同一个集群标识的消费者,会构成一个大的消费者集群,作为一个整体,接收生产者投递过来的消息. 同时,提供消费者接收消息相关的API给客户端进行调用.
- producer:消息中间件中的生产者模块,负责生产特定主题(Topic)的消息,传递给对此主题感兴趣的消费者,同时提供生产者生产消息的API接口,给客户端使用。
- core:消息处理的核心模块,负责消息的内存存储、应答控制、对消息进行多线程任务分派处理。
- model:定义消息类型的数据模型对象.
- netty:主要封装了Netty网络通信相关的核心模块代码,比如订阅消息事件的路由分派策略、消息的编码、解码器等等。
- serialize:利用Kryo这个优秀高效的对象序列化、反序列框架对消息对象进行序列化网络传输。
3.消息队列的架构设计
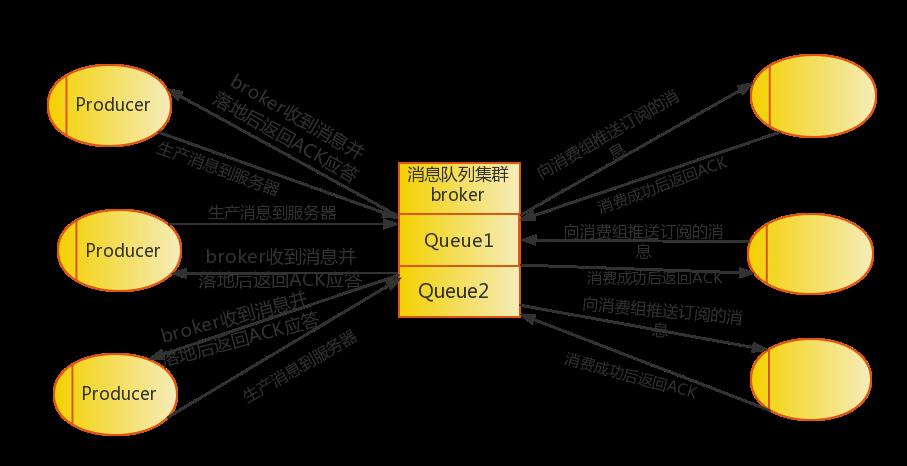
4.主要的数据结构
- 请求数据和回应数据的来源
Consumer, //这个消息来自消费者.
Broker, //这个消息broker.
Produce //此消息来自生产者.
- 生产者或者消费者的请求类型.
Message, //Producer 发送的消息
ConsumerResult, //消费者的消费结果.
Subscript, //Consumer的订阅消息
Stop //消费者的退订消息- broker的回应消息类型
SendResult, //broker回应给生产者的ACK
Message, //消息 由broker发送给消费者的消息.
AckSubscript //消费者订阅主题后,broker- 生产者和消费者的一次请求的数据结构,不管请求来自谁,.是何类型,客户端(生产者和消费者)发送的请求的结构体一值为StormRequest:
private String requestId; //请求的Id.
private Object parameters; //请求的参数
private RequestResonseFromType fromType; //消息来自哪里private RequestType requestType; //请求的类型- broker回应生产者或消费者的消息结构体.
private String requestId; //对应的回应的是哪个请求
private Object response;// 回应的消息
private RequestResonseFromType fromtype; //消息来自哪里
private ResponseType responseType; //响应的类型- 订阅请求消息
private String groupId; //消费者属于哪个消费组.
private String topic; //消费者要订阅的主题.
private String propertieName; //订阅的过滤属性名
private String propertieValue; //订阅的过滤值
private String clientKey; //客户端的id.在我们的系统中服务器端收到的数据只能是StormRequest,客户端收到的数据只能是StormResponse.
Producer 是客户端.
Consumer 也是客户端,
broker是服务器
producer ——> broker 是request.
consumer ——> broker 是request.
broker ——>consumer 是response
broker ——>producer 是response.
规定以上模型,方便我们对数据的编解码.
以上是关于基于netty的消息队列设计的主要内容,如果未能解决你的问题,请参考以下文章