论文笔记A Comprehensive Study of Deep Video Action Recognition
Posted CV-杨帆
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文笔记A Comprehensive Study of Deep Video Action Recognition相关的知识,希望对你有一定的参考价值。
论文链接:A Comprehensive Study of Deep Video Action Recognition
目录
- A Comprehensive Study of Deep Video Action Recognition
- Abstract
- 1. Introduction
- 2. Datasets and Challenges
- 3. An Odyssey of Using Deep Learning for Video Action Recognition
- 4. Evaluation and Benchmarking
- 5. Discussion and Future Work
- 5.1. Analysis and insights
- 5.2. Data augmentation
- 5.3. Video domain adaptation
- 5.4. Neural architecture search
- 5.5. Efficient model development
- 5.6. New datasets
- 5.7. Video adversarial attack
- 5.8. Zero-shot action recognition
- 5.9. Weakly-supervised video action recognition
- 5.10. Fine-grained video action recognition
- 5.11. Egocentric action recognition
- 5.12. Multi-modality
- 5.13. Self-supervised video representation learning
- 6. Conclusion
- 参考
A Comprehensive Study of Deep Video Action Recognition
Yi Zhu, Xinyu Li, Chunhui Liu, Mohammadreza Zolfaghari, Yuanjun Xiong,
Chongruo Wu, Zhi Zhang, Joseph Tighe, R. Manmatha, Mu Li
Amazon Web Services
yzaws,xxnl,chunhliu,mozolf,yuanjx,chongrwu,zhiz,tighej,manmatha,mli@amazon.com
Abstract
Video action recognition is one of the representative tasks for video understanding. Over the last decade, we have witnessed great advancements in video action recognition thanks to the emergence of deep learning. But we also encountered new challenges, including modeling long-range temporal information in videos, high computation costs, and incomparable results due to datasets and evaluation protocol variances. In this paper, we provide a comprehensive survey of over 200 existing papers on deep learning for video action recognition. We first introduce the 17 video action recognition datasets that influenced the design of models. Then we present video action recognition models in chronological order: starting with early attempts at adapting deep learning, then to the two-stream networks, followed by the adoption of 3D convolutional kernels, and finally to the recent compute-efficient models. In addition, we benchmark popular methods on several representative datasets and release code for reproducibility. In the end, we discuss open problems and shed light on opportunities for video action recognition to facilitate new research ideas.
视频动作识别是视频理解的代表性课题之一。在过去的十年中,由于深度学习的出现,我们见证了视频动作识别的巨大进步。但我们也遇到了新的挑战,包括在视频中建模远程时间信息,高计算成本,以及由于数据集和评估协议的差异而导致的不可比较的结果。在这篇论文中,我们提供了一个全面的调查超过200篇现有的深度学习视频动作识别的论文。我们首先介绍了影响模型设计的17个视频动作识别数据集。然后,我们按时间顺序介绍视频动作识别模型:从早期适应深度学习的尝试开始,然后是双流网络,然后是采用3D卷积核,最后是最近的计算效率模型。此外,我们在几个有代表性的数据集和发布代码上对流行的方法进行了基准测试,以提高可重复性。最后,我们讨论了视频动作识别的开放问题,并阐明了视频动作识别的机会,以促进新的研究思路。
1. Introduction
One of the most important tasks in video understanding is to understand human actions. It has many real-world applications, including behavior analysis, video retrieval, human-robot interaction, gaming, and entertainment. Human action understanding involves recognizing, localizing, and predicting human behaviors. The task to recognize human actions in a video is called video action recognition. In Figure 1, we visualize several video frames with the associated action labels, which are typical human daily activities such as shaking hands and riding a bike.
理解人的动作是视频理解中最重要的任务之一。它在现实世界中有许多应用,包括行为分析、视频检索、人机交互、游戏和娱乐。对人类行为的理解包括识别、定位和预测人类行为。在视频中识别人类动作的任务称为视频动作识别。在图1中,我们可视化了几个带有相关动作标签的视频帧,这些动作标签是典型的人类日常活动,如握手和骑自行车。

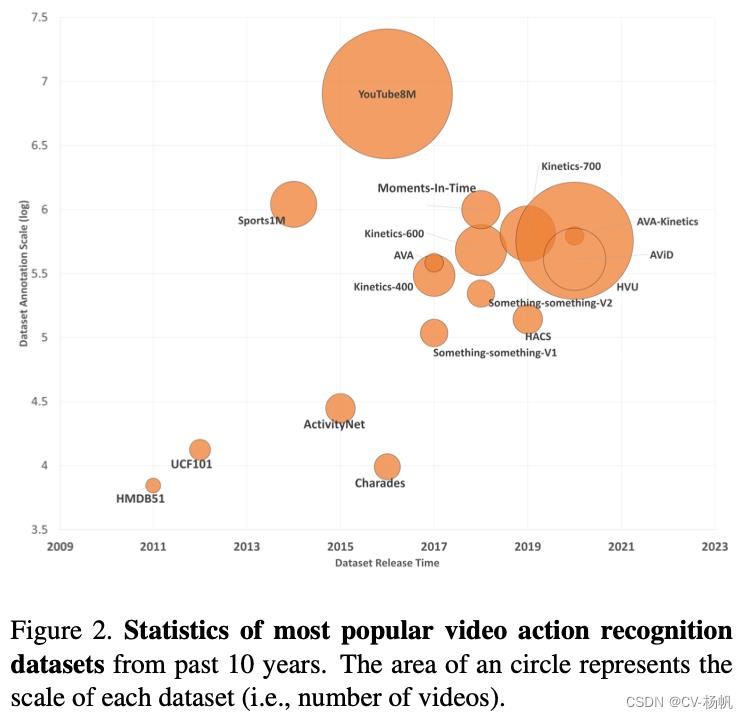
Over the last decade, there has been growing research interest in video action recognition with the emergence of high-quality large-scale action recognition datasets. We summarize the statistics of popular action recognition datasets in Figure 2. We see that both the number of videos and classes increase rapidly, e.g, from 7K videos over 51 classes in HMDB51 [109] to 8M videos over 3, 862 classes in YouTube8M [1]. Also, the rate at which new datasets are released is increasing: 3 datasets were released from 2011 to 2015 compared to 13 released from 2016 to 2020.
在过去的十年中,随着高质量的大规模动作识别数据集的出现,人们对视频动作识别的研究兴趣日益浓厚。我们在图2中总结了流行的动作识别数据集的统计数据。我们看到视频和课程的数量都在快速增长,例如,从HMDB51[109]中的51个课程上的7K视频到YouTube8M[1]中的3862个课程上的8M视频。此外,新数据集发布的速度也在增加:2011年至2015年发布了3个数据集,而2016年至2020年发布了13个数据集。
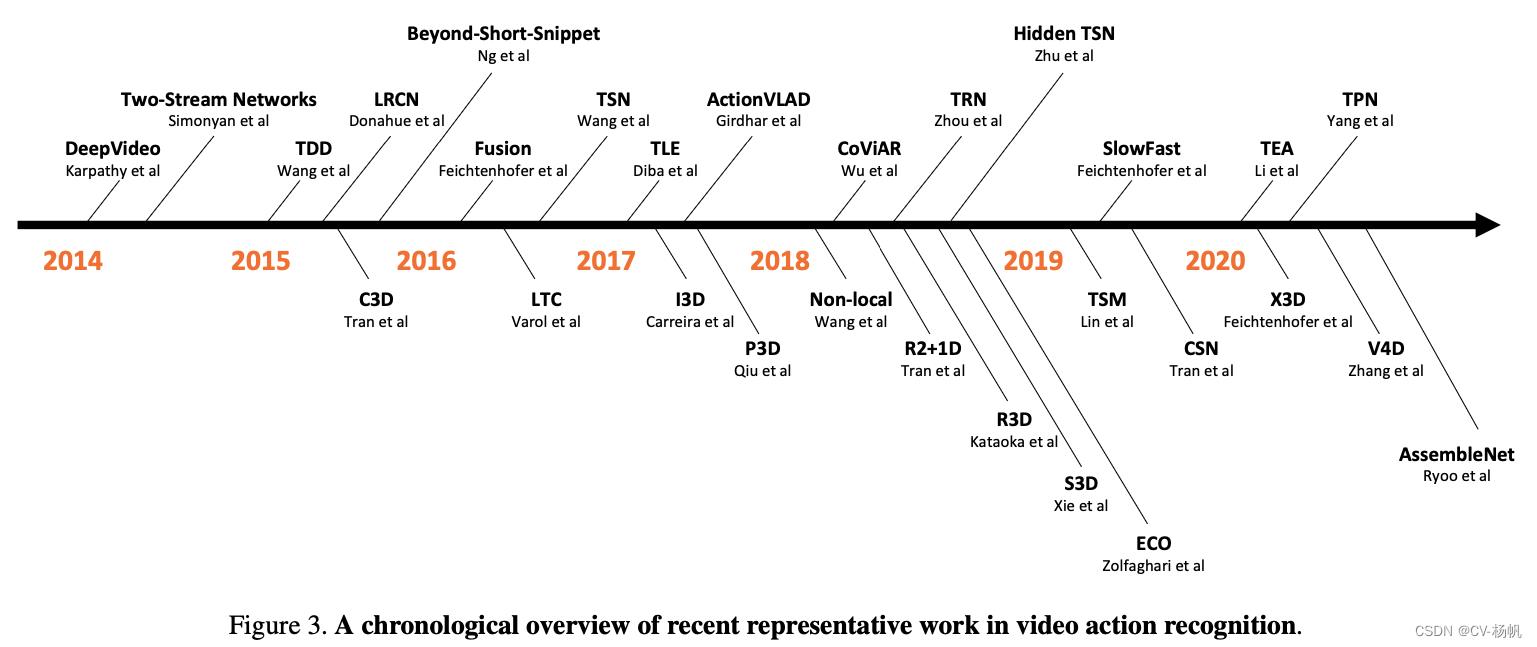
Thanks to both the availability of large-scale datasets and the rapid progress in deep learning, there is also a rapid growth in deep learning based models to recognize video actions. In Figure 3, we present a chronological overview of recent representative work. DeepVideo [99] is one of the earliest attempts to apply convolutional neural networks to videos. We observed three trends here. The first trend started by the seminal paper on Two-Stream Networks [187], adds a second path to learn the temporal information in a video by training a convolutional neural network on the optical flow stream. Its great success inspired a large number of follow-up papers, such as TDD [214], LRCN [37], Fusion [50], TSN [218], etc. The second trend was the use of 3D convolutional kernels to model video temporal information, such as I3D [14], R3D [74], S3D [239], Non-local [219], SlowFast [45], etc. Finally, the third trend focused on computational efficiency to scale to even larger datasets so that they could be adopted in real applications. Examples include Hidden TSN [278], TSM [128], X3D [44], TVN [161], etc.
得益于大规模数据集的可用性和深度学习的快速发展,基于深度学习的视频动作识别模型也得到了快速发展。在图3中,我们按时间顺序概述了最近的代表性作品。DeepVideo[99]是最早将卷积神经网络应用于视频的尝试之一。我们观察到三个趋势。第一个趋势是由关于双流网络的开创性论文[187]开始的,增加了第二条路径,通过在光流流上训练卷积神经网络来学习视频中的时间信息。它的巨大成功启发了大量后续的论文,如TDD [214], LRCN [37], Fusion [50], TSN[218]等。第二个趋势是使用3D卷积核对视频时间信息建模,如I3D[14]、R3D[74]、S3D[239]、Non-local[219]、SlowFast[45]等。最后,第三个趋势专注于计算效率,以扩展到更大的数据集,以便它们可以在实际应用中采用。示例包括隐藏TSN[278]、TSM[128]、X3D[44]、TVN[161]等。
Despite the large number of deep learning based models for video action recognition, there is no comprehensive survey dedicated to these models. Previous survey papers either put more efforts into hand-crafted features [77, 173] or focus on broader topics such as video captioning [236], video prediction [104], video action detection [261] and zero-shot video action recognition [96]. In this paper:
尽管有大量基于深度学习的视频动作识别模型,但还没有针对这些模型的全面研究。以前的调查论文要么把更多的精力放在手工制作的功能上[77,173],要么关注更广泛的主题,如视频字幕[236]、视频预测[104]、视频动作检测[261]和零镜头视频动作识别[96]。在本文中:
We comprehensively review over 200 papers on deep learning for video action recognition. We walk the readers through the recent advancements chronologically and systematically, with popular papers explained in detail.
我们全面审查了200多篇关于深度学习在视频动作识别中的应用的论文。我们将按时间顺序和系统地向读者介绍最近的进展,并对流行论文进行详细解释。
We benchmark widely adopted methods on the same set of datasets in terms of both accuracy and efficiency.We also release our implementations for full reproducibility .
在准确性和效率方面,我们在同一组数据集上对广泛采用的方法进行了基准测试。我们还发布了我们的实现以实现完全的可再现性。
We elaborate on challenges, open problems, and opportunities in this field to facilitate future research.
我们详细阐述了该领域的挑战、开放问题和机遇,以促进未来的研究。
The rest of the survey is organized as following. We first describe popular datasets used for benchmarking and existing challenges in section 2. Then we present recent advancements using deep learning for video action recognition in section 3, which is the major contribution of this survey. In section 4, we evaluate widely adopted approaches on standard benchmark datasets, and provide discussions and future research opportunities in section 5.
调查的其余部分组织如下。我们首先在第2节中描述用于基准测试的流行数据集和现有的挑战。然后,我们在第3部分介绍了使用深度学习进行视频动作识别的最新进展,这是本次调查的主要贡献。在第4节中,我们评估了标准基准数据集上广泛采用的方法,并在第5节中提供了讨论和未来的研究机会。
2. Datasets and Challenges
2.1. Datasets
Deep learning methods usually improve in accuracy when the volume of the training data grows. In the case of video action recognition, this means we need large-scale annotated datasets to learn effective models.
深度学习方法的准确性通常随着训练数据量的增长而提高。在视频动作识别的情况下,这意味着我们需要大规模的带注释的数据集来学习有效的模型。
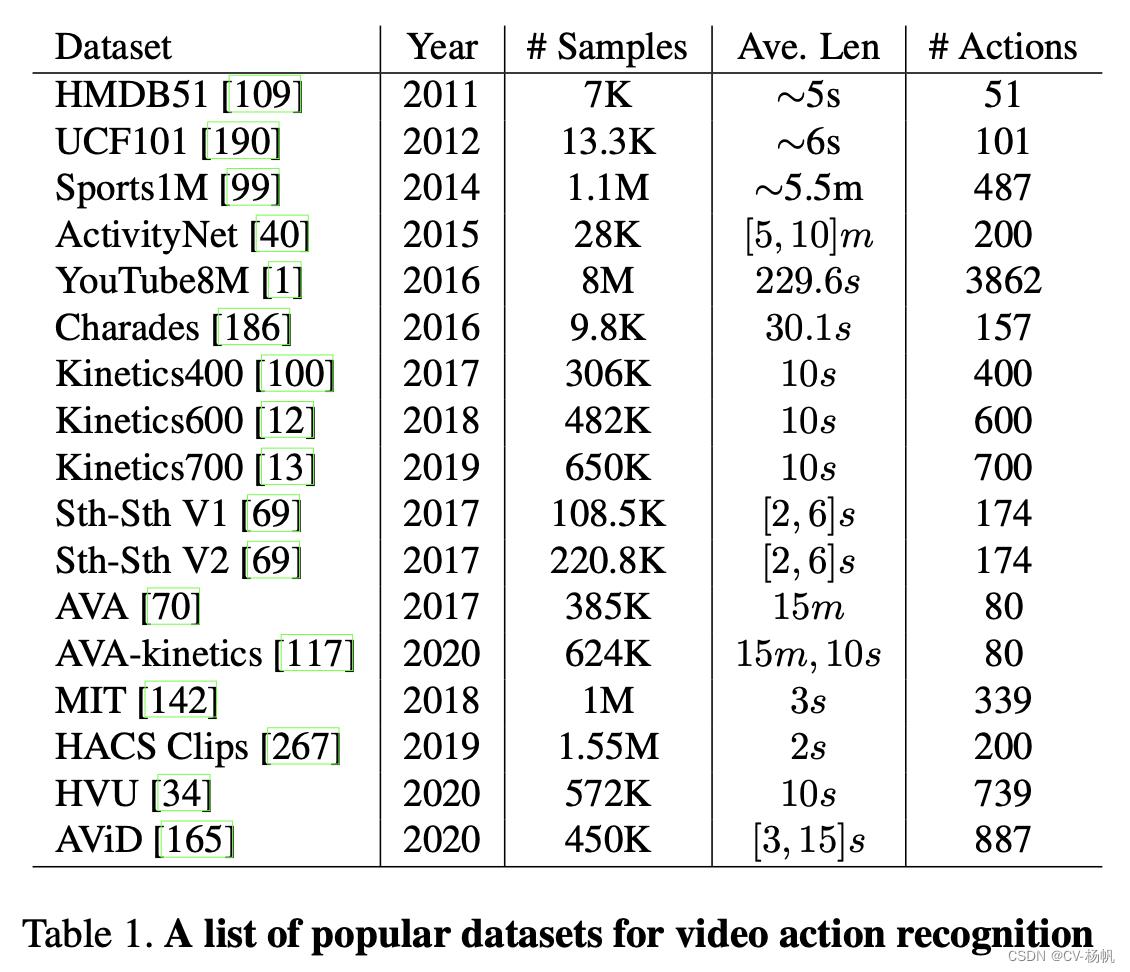
For the task of video action recognition, datasets are often built by the following process: (1) Define an action list, by combining labels from previous action recognition datasets and adding new categories depending on the use case. (2) Obtain videos from various sources, such as YouTube and movies, by matching the video title/subtitle to the action list. (3) Provide temporal annotations manually to indicate the start and end position of the action, and (4) finally clean up the dataset by de-duplication and filtering out noisy classes/samples. Below we review the most popular large-scale video action recognition datasets in Table 1 and Figure 2.
对于视频动作识别任务,数据集通常通过以下过程构建:(1)定义一个动作列表,将之前动作识别数据集中的标签组合起来,并根据用例添加新的类别。(2)通过将视频标题/字幕与动作列表进行匹配,获取各种来源的视频,如YouTube和电影。(3)手动提供时间注释,以指示动作的开始和结束位置。(4)最后通过去重复和过滤噪声类/样本来清理数据集。下面我们回顾表1和图2中最流行的大规模视频动作识别数据集。
HMDB51 [109] was introduced in 2011. It was collected mainly from movies, and a small proportion from public databases such as the Prelinger archive, YouTube and Google videos. The dataset contains 6, 849 clips divided into 51 action categories, each containing a minimum of 101 clips. The dataset has three official splits. Most previous papers either report the top-1 classification accuracy on split 1 or the average accuracy over three splits.
HMDB51[109]于2011年问世。这些数据主要来自电影,还有一小部分来自公共数据库,如普雷林格档案、YouTube和谷歌视频。该数据集包含6,849个剪辑,分为51个动作类别,每个动作类别至少包含101个剪辑。该数据集有三次官方拆分。以前的大多数论文要么报告分裂1的前1分类准确率,要么报告三次分裂的平均准确率。
UCF101 [190] was introduced in 2012 and is an extension of the previous UCF50 dataset. It contains 13,320 videos from YouTube spreading over 101 categories of human actions. The dataset has three official splits similar to HMDB51, and is also evaluated in the same manner.
UCF101[190]于2012年引入,是之前UCF50数据集的扩展。它包含了来自YouTube的13320个视频,传播了101种人类行为。该数据集有三个官方分割,类似于HMDB51,也以相同的方式进行评估。
Sports1M [99] was introduced in 2014 as the first large-scale video action dataset which consisted of more than 1 million YouTube videos annotated with 487 sports classes. The categories are fine-grained which leads to low interclass variations. It has an official 10-fold cross-validation split for evaluation.
Sports1M[99]于2014年推出,是第一个大规模视频动作数据集,由100多万YouTube视频组成,注释了487个体育课程。类别是细粒度的,这导致了类间的低变化。它有一个官方的10倍交叉验证拆分用于评估。
ActivityNet [40] was originally introduced in 2015 and the ActivityNet family has several versions since its initial launch. The most recent ActivityNet 200 (V1.3) contains 200 human daily living actions. It has 10, 024 training, 4, 926 validation, and 5, 044 testing videos. On average there are 137 untrimmed videos per class and 1.41 activity instances per video.
ActivityNet[40]最初于2015年推出,ActivityNet家族自最初推出以来有几个版本。最新的ActivityNet 200 (V1.3)包含200个人类日常生活行为。它有10,024个训练视频、4,926个验证视频和5,044个测试视频。平均而言,每个类有137个未修剪的视频,每个视频有1.41个活动实例。
YouTube8M [1] was introduced in 2016 and is by far the largest-scale video dataset that contains 8 million YouTube videos (500K hours of video in total) and annotated with 3, 862 action classes. Each video is annotated with one or multiple labels by a YouTube video annotation system. This dataset is split into training, validation and test in the ratio 70:20:10. The validation set of this dataset is also extended with human-verified segment annotations to provide temporal localization information.
YouTube8M[1]于2016年推出,是迄今为止规模最大的视频数据集,包含800万YouTube视频(总共50万小时的视频),并注释了3862个动作类。每个视频都由YouTube视频标注系统标注一个或多个标签。该数据集按70:20:10的比例分为训练、验证和测试。该数据集的验证集还扩展了人类验证的段注释,以提供时间定位信息。
Charades [186] was introduced in 2016 as a dataset for real-life concurrent action understanding. It contains 9, 848 videos with an average length of 30 seconds. This dataset includes 157 multi-label daily indoor activities, performed by 267 different people. It has an official train-validation split that has 7, 985 videos for training and the remaining 1, 863 for validation.
2016年,Charades[186]作为一个用于理解现实并发动作的数据集被引入。它包含9848个视频,平均长度为30秒。该数据集包括157项多标签的日常室内活动,由267名不同的人进行。它有一个官方的训练-验证分割,有7985个视频用于训练,剩下的1863个用于验证。
Kinetics Family is now the most widely adopted benchmark. Kinetics400 [100] was introduced in 2017 and it consists of approximately 240k training and 20k validation videos trimmed to 10 seconds from 400 human action categories. The Kinetics family continues to expand, with Kinetics-600 [12] released in 2018 with 480K videos and Kinetics700[13] in 2019 with 650K videos.
Kinetics Family是目前最广泛采用的基准。Kinetics400[100]于2017年推出,由大约240k的训练视频和20k的验证视频组成,从400个人体动作类别中删减到10秒。Kinetics系列继续扩大,2018年发布了Kinetics-600[12],包含480K视频,2019年发布了Kinetics700[13],包含650K视频。
20BN-Something-Something [69] V1 was introduced in 2017 and V2 was introduced in 2018. This family is another popular benchmark that consists of 174 action classes that describe humans performing basic actions with everyday objects. There are 108, 499 videos in V1 and 220, 847 videos in V2. Note that the Something-Something dataset requires strong temporal modeling because most activities cannot be inferred based on spatial features alone (e.g. opening something, covering something with something).
20BN-Something-Something [69] V1于2017年引入,V2于2018年引入。这个系列是另一个流行的基准测试,由174个动作类组成,描述人类对日常物体执行的基本动作。V1中有108,499个视频,V2中有220,847个视频。请注意,something - something数据集需要强大的时间建模,因为大多数活动不能仅根据空间特征推断(例如,打开某物,用某物覆盖某物)。
AVA [70] was introduced in 2017 as the first large-scale spatio-temporal action detection dataset. It contains 430 15-minute video clips with 80 atomic actions labels (only 60 labels were used for evaluation). The annotations were provided at each key-frame which lead to 214, 622 training, 57, 472 validation and 120, 322 testing samples. The AVA dataset was recently expanded to AVA-Kinetics with 352,091 training, 89,882 validation and 182,457 testing samples [117].
AVA[70]于2017年问世,是首个大规模时空动作检测数据集。它包含430个15分钟的视频剪辑,带有80个原子动作标签(只有60个标签用于评估)。在每个关键帧上提供注释,得到214 622个训练,57 472个验证和120 322个测试样本。AVA数据集最近扩展到AVA- kinetics,包含352091个训练、89,882个验证和182,457个测试样本[117]。
Moments in Time [142] was introduced in 2018 and it is a large-scale dataset designed for event understanding. It contains one million 3 second video clips, annotated with a dictionary of 339 classes. Different from other datasets designed for human action understanding, Moments in Time dataset involves people, animals, objects and natural phenomena. The dataset was extended to Multi-Moments in Time (M-MiT) [143] in 2019 by increasing the number of videos to 1.02 million, pruning vague classes, and increasing the number of labels per video.
Moments in Time[142]于2018年引入,是一个旨在理解事件的大规模数据集。它包含100万个3秒的视频片段,用339个类的字典注释。不同于其他为理解人类行为而设计的数据集,瞬间数据集包括人、动物、物体和自然现象。2019年,该数据集扩展到Multi-Moments in Time (M-MiT)[143],将视频数量增加到102万,修剪模糊类,并增加每个视频的标签数量。
HACS [267] was introduced in 2019 as a new large-scale dataset for recognition and localization of human actions collected from Web videos. It consists of two kinds of manual annotations. HACS Clips contains 1.55M 2-second clip annotations on 504K videos, and HACS Segments has 140K complete action segments (from action start to end) on 50K videos. The videos are annotated with the same 200 human action classes used in ActivityNet (V1.3) [40].
HACS[267]是一种新的大规模数据集,用于从网络视频中收集人类行为的识别和定位。它由两种手工注释组成。HACS剪辑包含1.55M 2秒剪辑注释504K视频,HACS片段有140K完整的动作片段(从动作开始到结束)50K视频。这些视频使用ActivityNet (V1.3)[40]中使用的200个人类动作类进行注释。
HVU [34] dataset was released in 2020 for multi-label multi-task video understanding. This dataset has 572K videos and 3, 142 labels. The official split has 481K, 31K and 65K videos for train, validation, and test respectively. This dataset has six task categories: scene, object, action, event, attribute, and concept. On average, there are about 2, 112 samples for each label. The duration of the videos varies with a maximum length of 10 seconds.
HVU[34]数据集于2020年发布,用于多标签多任务视频理解。这个数据集有572K个视频和3142个标签。官方拆分有481K、31K和65K视频分别用于训练、验证和测试。这个数据集有六个任务类别:场景、对象、动作、事件、属性和概念。平均而言,每个标签大约有2112个样品。视频时长各不相同,最长10秒。
AViD [165] was introduced in 2020 as a dataset for anonymized action recognition. It contains 410K videos for training and 40K videos for testing. Each video clip duration is between 3-15 seconds and in total it has 887 action classes. During data collection, the authors tried to collect data from various countries to deal with data bias. They also remove face identities to protect privacy of video makers. Therefore, AViD dataset might not be a proper choice for recognizing face-related actions.
AViD[165]于2020年推出,作为匿名动作识别的数据集。它包含410K的训练视频和40K的测试视频。每个视频剪辑的时长在3-15秒之间,总共有887个动作类。在数据收集过程中,作者试图收集不同国家的数据,以处理数据偏差。为了保护视频制作者的隐私,他们还删除了面部身份。因此,AViD数据集可能不是识别人脸相关动作的合适选择。

Figure 4. Visual examples from popular video action datasets.
Top: individual video frames from action classes in UCF101 and Kinetics400. A single frame from these scene-focused datasets often contains enough information to correctly guess the category. Middle: consecutive video frames from classes in Something-Something. The 2nd and 3rd frames are made transparent to indicate the importance of temporal reasoning that we cannot tell these two actions apart by looking at the 1st frame alone. Bottom: individual video frames from classes in Moment in Time. Same action could have different actors in different environments.图4。来自流行视频动作数据集的可视化示例。
上图:UCF101和Kinetics400中动作类的独立视频帧。来自这些以场景为中心的数据集的单个帧通常包含足够的信息来正确猜测类别。中间:来自某某类的连续视频帧。第二帧和第三帧是透明的,以表明时间推理的重要性,我们不能通过单独看第一帧来区分这两个行为。底部:来自“时刻”中的各个类的单独视频帧。相同的动作在不同的环境中可能有不同的参与者。
Before we dive into the chronological review of methods, we present several visual examples from the above datasets in Figure 4 to show their different characteristics. In the top two rows, we pick action classes from UCF101 [190] and Kinetics400 [100] datasets. Interestingly, we find that these actions can sometimes be determined by the context or scene alone. For example, the model can predict the action riding a bike as long as it recognizes a bike in the video frame. The model may also predict the action cricket bowling if it recognizes the cricket pitch. Hence for these classes, video action recognition may become an object/scene classification problem without the need of reasoning motion/temporal information. In the middle two rows, we pick action classes from Something-Something dataset [69]. This dataset focuses on human-object interaction, thus it is more fine-grained and requires strong temporal modeling. For example, if we only look at the first frame of dropping something and picking something up without looking at other video frames, it is impossible to tell these two actions apart. In the bottom row, we pick action classes from Moments in Time dataset [142]. This dataset is different from most video action recognition datasets, and is designed to have large inter-class and intra-class variation that represent dynamical events at different levels of abstraction. For example, the action climbing can have different actors (person or animal) in different environments (stairs or tree).
在按时间顺序回顾这些方法之前,我们在图4中展示了上述数据集中的几个可视化示例,以展示它们的不同特征。在前两行中,我们从UCF101[190]和Kinetics400[100]数据集中选择动作类。有趣的是,我们发现这些行为有时只取决于情境或场景。例如,只要模型识别出视频帧中的自行车,它就可以预测骑自行车的动作。该模型在识别板球场地的情况下,也可以预测板球运动。因此,对于这些类来说,视频动作识别可能成为一个不需要推理运动/时间信息的目标/场景分类问题。在中间的两行中,我们从Something-Something数据集[69]中选择动作类。该数据集关注人-物交互,因此粒度更细,需要强大的时间建模。例如,如果我们只看扔东西和捡东西的第一帧而不看其他视频帧,就不可能区分这两个动作。在最下面一行,我们从Moments In Time数据集[142]中选择动作类。该数据集不同于大多数视频动作识别数据集,设计为具有较大的类间和类内变化,代表不同抽象级别的动态事件。例如,动作攀爬可以有不同的演员(人或动物)在不同的环境(楼梯或树)。
2.2. Challenges
There are several major challenges in developing effective video action recognition algorithms.
In terms of dataset, first, defining the label space for training action recognition models is non-trivial. It’s because human actions are usually composite concepts and the hierarchy of these concepts are not well-defined. Second, annotating videos for action recognition are laborious (e.g., need to watch all the video frames) and ambiguous (e.g, hard to determine the exact start and end of an action). Third, some popular benchmark datasets (e.g., Kinetics family) only release the video links for users to download and not the actual video, which leads to a situation that methods are evaluated on different data. It is impossible to do fair comparisons between methods and gain insights.
在数据集方面,首先,为训练动作识别模型定义标签空间是非常重要的。这是因为人类行为通常是复合概念,这些概念的层次结构并没有很好的定义。其次,为动作识别标注视频是费力的(例如,需要观看所有的视频帧)和模糊的(例如,难以确定动作的确切开始和结束)。第三,一些流行的基准数据集(例如,Kinetics家族)只发布视频链接供用户下载,而不发布实际的视频,这导致了一种情况,方法是在不同的数据上评估。不可能在方法之间进行公平的比较并获得深刻的见解。
In terms of modeling, first, videos capturing human actions have both strong intra- and inter-class variations. People can perform the same action in different speeds under various viewpoints. Besides, some actions share similar movement patterns that are hard to distinguish. Second, recognizing human actions requires simultaneous understanding of both short-term action-specific motion information and long-range temporal information. We might need a sophisticated model to handle different perspectives rather than using a single convolutional neural network. Third, the computational cost is high for both training and inference, hindering both the development and deployment of action recognition models. In the next section, we will demonstrate how video action recognition methods developed over the last decade to address the aforementioned challenges.
在建模方面,首先,捕捉人类行为的视频具有很强的类内和类间变异。人们可以在不同的视点下以不同的速度执行相同的动作。此外,有些动作有着相似的运动模式,很难区分。其次,识别人类行为需要同时理解特定于动作的短期运动信息和长期时间信息。我们可能需要一个复杂的模型来处理不同的视角,而不是使用单一的卷积神经网络。第三,训练和推理的计算成本都很高,阻碍了动作识别模型的开发和部署。在下一节中,我们将演示视频动作识别方法是如何在过去十年中发展起来的,以解决上述挑战。
3. An Odyssey of Using Deep Learning for Video Action Recognition
In this section, we review deep learning based methods for video action recognition from 2014 to present and introduce the related earlier work in context.
在本节中,我们将回顾从2014年开始的基于深度学习的视频动作识别方法,以呈现和介绍相关的早期工作。
3.1. From hand-crafted features to CNNs
Despite there being some papers using Convolutional Neural Networks (CNNs) for video action recognition, [200, 5, 91], hand-crafted features [209, 210, 158, 112], particularly Improved Dense Trajectories (IDT) [210], dominated the video understanding literature before 2015, due to their high accuracy and good robustness. However, handcrafted features have heavy computational cost [244], and are hard to scale and deploy.
尽管有一些论文使用卷积神经网络(CNN)进行视频动作识别,[200,5,91],手工制作的特征[209,210,158,112],特别是改进的密集轨迹(IDT)[210],由于其高精度和良好的鲁棒性,在2015年之前主导了视频理解文献。但是,手工制作的功能具有很高的计算成本[244],并且难以扩展和部署。
With the rise of deep learning [107], researchers started to adapt CNNs for video problems. The seminal work DeepVideo [99] proposed to use a single 2D CNN model on each video frame independently and investigated several temporal connectivity patterns to learn spatio-temporal features for video action recognition, such as late fusion, early fusion and slow fusion. Though this model made early progress with ideas that would prove to be useful later such as a multi-resolution network, its transfer learning performance on UCF101 [190] was 20% less than hand-crafted IDT features (65.4% vs 87.9%). Furthermore, DeepVideo [99] found that a network fed by individual video frames, performs equally well when the input is changed to a stack of frames. This observation might indicate that the learnt spatio-temporal features did not capture the motion well. It also encouraged people to think about why CNN models did not outperform traditional hand-crafted features in the video domain unlike in other computer vision tasks [107, 171].
随着深度学习的兴起[107],研究人员开始使CNN适应视频问题。开创性的工作DeepVideo [99]建议在每个视频帧上独立使用单个2D CNN模型,并研究了几种时间连接模式来学习视频动作识别的时空特征,例如后期融合,早期融合和慢融合。虽然该模型在多分辨率网络等后来被证明是有用的想法方面取得了早期进展,但它在UCF101 [190]上的迁移学习性能比手工制作的IDT特征低20%(65.4%对87.9%)。此外,DeepVideo [99]发现,当输入更改为帧堆栈时,由单个视频帧馈送的网络表现同样出色。这一观察结果可能表明,所学的时空特征没有很好地捕捉到运动。它还鼓励人们思考为什么CNN模型在视频领域的表现不如其他计算机视觉任务的传统手工制作功能[107,171]。
3.2. Two-stream networks
Since video understanding intuitively needs motion information, finding an appropriate way to describe the temporal relationship between frames is essential to improving the performance of CNN-based video action recognition.
由于视频理解直观地需要运动信息,找到一种合适的方法来描述帧间的时间关系对于提高基于cnn的视频动作识别的性能至关重要。
Optical flow [79] is an effective motion representation to describe object/scene movement. To be precise, it is the pattern of apparent motion of objects, surfaces, and edges in a visual scene caused by the relative motion between an observer and a scene. We show several visualizations of optical flow in Figure 5. As we can see, optical flow is able to describe the motion pattern of each action accurately. The advantage of using optical flow is it provides orthogonal information compared to the the RGB image. For example, the two images on the bottom of Figure 5 have cluttered backgrounds. Optical flow can effectively remove the nonmoving background and result in a simpler learning problem compared to using the original RGB images as input.
光流[79]是描述物体/场景运动的一种有效的运动表示方法。准确地说,它是由观察者与场景之间的相对运动所引起的视觉场景中物体、表面和边缘的视运动模式。我们在图5中展示了光流的几个可视化图。我们可以看到,光流能够准确地描述每个动作的运动模式。使用光流的优点是,与RGB图像相比,它提供了正交的信息。例如,图5底部的两张图片,背景就比较杂乱。光流可以有效地去除不移动的背景,与使用原始RGB图像作为输入相比,会产生更简单的学习问题。

Figure 5. Visualizations of optical flow. We show four image-flow pairs, left is original RGB image and right is the estimated optical flow by FlowNet2 [85]. Color of optical flow indicates the directions of motion, and we follow the color coding scheme of FlowNet2 [85] as shown in top right.
图5。光流的可视化。我们展示了四组图像流对,左边是原始RGB图像,右边是FlowNet2估计的光流[85]。光流的颜色表示运动方向,我们遵循FlowNet2[85]的颜色编码方案如右上所示。
In addition, optical flow has been shown to work well on video problems. Traditional hand-crafted features such as IDT [210] also contain optical-flow-like features, such as Histogram of Optical Flow (HOF) and Motion Boundary Histogram (MBH).
此外,光流已被证明在视频问题上工作得很好。传统手工制作的特征,如IDT[210]也包含类似光流的特征,如光流直方图(Histogram of Optical Flow, HOF)和运动边界直方图(Motion Boundary Histogram, MBH)。
Hence, Simonyan et al. [187] proposed two-stream networks, which included a spatial stream and a temporal stream as shown in Figure 6. This method is related to the two-streams hypothesis [65], according to which the human visual cortex contains two pathways: the ventral stream (which performs object recognition) and the dorsal stream (which recognizes motion). The spatial stream takes raw video frame(s) as input to capture visual appearance information. The temporal stream takes a stack of optical flow images as input to capture motion information between video frames. To be specific, [187] linearly rescaled the horizontal and vertical components of the estimated flow (i.e., motion in the x-direction and y-direction) to a [0, 255] range and compressed using JPEG. The output corresponds to the two optical flow images shown in Figure 6. The compressed optical flow images will then be concatenated as the input to the temporal stream with a dimension of H×W×2L, where H, W and L indicates the height, width and the length of the video frames. In the end, the final prediction is obtained by averaging the prediction scores from both streams.
因此,Simonyan等[187]提出了两流网络,包括一个空间流和一个时间流,如图6所示。这种方法与双流假说(two-streams hypothesis)有关[65],根据该假说,人类视觉皮层包含两条通路:腹侧流(执行物体识别)和背侧流(识别运动)。空间流以原始视频帧(s)为输入,捕获视觉外观信息。时间流以一堆光流图像作为输入,捕获视频帧之间的运动信息。具体来说,[187]将估计流的水平和垂直分量(即x方向和y方向的运动)线性缩放到[0,255]范围,并使用JPEG进行压缩。输出对应于图6所示的两张光流图像。然后将压缩后的光流图像拼接成维度为H×W×2L的时间流的输入,其中H、W和L分别表示视频帧的高度、宽度和长度。最后,将两个流的预测分数取平均值得到最终的预测结果。
By adding the extra temporal stream, for the first time, a CNN-based approach achieved performance similar to the previous best hand-crafted feature IDT on UCF101 (88.0% vs 87.9%) and on HMDB51 [109] (59.4% vs 61.1%). [187] makes two important observations. First, motion information is important for video action recognition. Second, it is still challenging for CNNs to learn temporal information directly from raw video frames. Pre-computing optical flow as the motion representation is an effective way for deep learning to reveal its power. Since [187] managed to close the gap between deep learning approaches and traditional hand-crafted features, many follow-up papers on twostream networks emerged and greatly advanced the development of video action recognition. Here, we divide them into several categories and review them individually.
通过首次添加额外的时间流,基于cnn的方法获得了类似于之前在UCF101 (88.0% vs 87.9%)和HMDB51 [109] (59.4% vs 61.1%)上的最佳手工特性IDT的性能。[187]做了两个重要的观察。首先,运动信息对视频动作识别很重要。其次,对于cnn来说,直接从原始视频帧中学习时间信息仍然具有挑战性。预计算光流作为运动表示是深度学习展示其威力的有效途径。自从[187]成功地缩小了深度学习方法和传统手工特征之间的差距以来,许多关于双流网络的后续论文出现了,极大地推动了视频动作识别的发展。在这里,我们将它们分为几个类别并分别进行回顾。
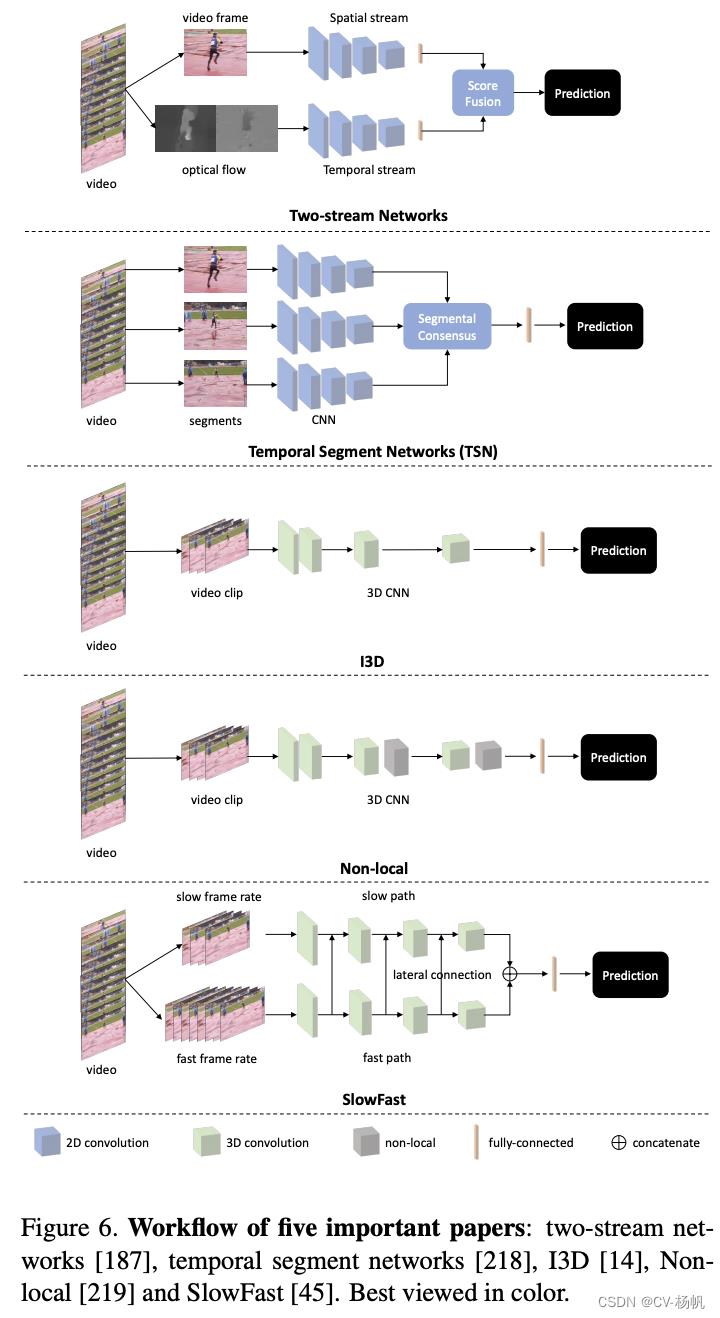
Figure 6. Workflow of five important papers: two-stream networks [187], temporal segment networks [218], I3D [14], Nonlocal [219] and SlowFast [45]. Best viewed in color.
图6。五篇重要论文的工作流程:双流网络[187],时间段网络[218],I3D [14], Nonlocal[219]和SlowFast[45]。最好用彩色观看。
3.2.1 Using deeper network architectures
Two-stream networks [187] used a relatively shallow network architecture [107]. Thus a natural extension to the two-stream networks involves using deeper networks. However, Wang et al. [215] finds that simply using deeper networks does not yield better results, possibly due to overfitting on the small-sized video datasets [190, 109]. Recall from section 2.1, UCF101 and HMDB51 datasets only have thousands of training videos. Hence, Wang et al. [217] introduce a series of good practices, including crossmodality initialization, synchronized batch normalization, corner cropping and multi-scale cropping data augmentation, large dropout ratio, etc. to prevent deeper networks from overfitting. With these good practices, [217] was able to train a two-stream network with the VGG16 model [188] that outperforms [187] by a large margin on UCF101. These good practices have been widely adopted and are still being used. Later, Temporal Segment Networks (TSN) [218] performed a thorough investigation of network architectures, such as VGG16, ResNet [76], Inception [198], and demonstrated that deeper networks usually achieve higher recognition accuracy for video action recognition. We will describe more details about TSN in section 3.2.4.
双流网络[187]采用了相对较浅的网络架构[107]。因此,对双流网络的自然扩展涉及到使用更深层次的网络。然而,Wang等人[215]发现,简单地使用更深的网络并不能产生更好的结果,这可能是由于对小型视频数据集的过拟合[190,109]。回顾2.1节,UCF101和HMDB51数据集只有数千个训练视频。因此,Wang等人[217]引入了一系列好的实践,包括跨模态初始化、同步批处理归一化、拐角裁剪和多尺度裁剪数据增强、大dropout率等,以防止更深层次的网络过拟合。有了这些良好的实践,[217]能够用VGG16模型[188]训练一个双流网络,其性能大大优于UCF101[187]。这些良好实践已被广泛采用,并仍在使用。后来,时间段网络(TSN)[218]对VGG16、ResNet[76]、Inception[198]等网络架构进行了深入研究,并证明更深层次的网络通常可以实现更高的视频动作识别精度。我们将在3.2.4节中详细描述TSN。
3.2.2 Two-stream fusion
Since there are two streams in a two-stream network, there will be a stage that needs to merge the results from both networks to obtain the final prediction. This stage is usually referred to as the spatial-temporal fusion step.
由于在一个两流网络中有两个流,将会有一个阶段需要合并来自两个网络的结果,以获得最终的预测。这一阶段通常被称为时空融合步骤。
The easiest and most straightforward way is late fusion, which performs a weighted average of predictions from both streams. Despite late fusion being widely adopted [187, 217], many researchers claim that this may not be the optimal way to fuse the information between the spatial appearance stream and temporal motion stream. They believe that earlier interactions between the two networks could benefit both streams during model learning and this is termed as early fusion.
最简单、最直接的方法是后期融合,它对来自两种流的预测进行加权平均。尽管后期融合被广泛采用[187,217],但许多研究者认为这可能不是融合空间外观流和时间运动流之间信息的最佳方式。他们认为,在模型学习过程中,两个网络之间的早期交互可以使两种流都受益,这被称为早期融合。
Fusion [50] is one of the first of several papers investigating the early fusion paradigm, including how to perform spatial fusion (e.g., using operators such as sum, max, bilinear, convolution and concatenation), where to fuse the network (e.g., the network layer where early interactions happen), and how to perform temporal fusion (e.g., using 2D or 3D convolutional fusion in later stages of the network). [50] shows that early fusion is beneficial for both streams to learn richer features and leads to improved performance over late fusion. Following this line of research, Feichtenhofer et al. [46] generalizes ResNet [76] to the spatiotemporal domain by introducing residual connections between the two streams. Based on [46], Feichtenhofer et al. [47] further propose a multiplicative gating function for residual networks to learn better spatio-temporal features. Concurrently, [225] adopts a spatio-temporal pyramid to perform hierarchical early fusion between the two streams.
融合[50]是研究早期融合范式的几篇论文中的第一篇,包括如何执行空间融合(例如,使用运算符如和、最大、双线性、卷积和拼接),在哪里融合网络(例如,发生早期交互的网络层),以及如何执行时间融合(例如,在网络的后期使用2D或3D卷积融合)。[50]表明,早期的融合有利于两个流学习更丰富的特性,并导致比后期融合更好的性能。遵循这一研究路线,Feichtenhofer等人[46]通过引入两个流之间的残余连接,将ResNet[76]推广到时空域。Feichtenhofer等[47]在[46]的基础上进一步提出了残差网络的乘法门控函数,以更好地学习时空特征。同时,[225]采用时空金字塔在两个流之间进行分层早期融合。
3.2.3 Recurrent neural networks
Since a video is essentially a temporal sequence, researchers have explored Recurrent Neural Networks (RNNs) for temporal modeling inside a video, particularly the usage of Long Short-Term Memory (LSTM) [78].
由于视频本质上是一个时间序列,研究人员探索了循环神经网络(rnn)在视频中进行时间建模,特别是使用长短期记忆(LSTM)[78]。
LRCN [37] and Beyond-Short-Snippets [253] are the first of several papers that use LSTM for video action recognition under the two-stream networks setting. They take the feature maps from CNNs as an input to a deep LSTM network, and aggregate frame-level CNN features into videolevel predictions. Note that they use LSTM on two streams separately, and the final results are still obtained by late fusion. However, there is no clear empirical improvement from LSTM models [253] over the two-stream baseline [187]. Following the CNN-LSTM framework, several variants are proposed, such as bi-directional LSTM [205], CNN-LSTM fusion [56] and hierarchical multi-granularity LSTM network [118]. [125] described VideoLSTM which includes a correlation-based spatial attention mechanism and a lightweight motion-based attention mechanism. VideoLSTM not only show improved results on action recognition, but also demonstrate how the learned attention can be used for action localization by relying on just the action class label. Lattice-LSTM [196] extends LSTM by learning independent hidden state transitions of memory cells for individual spatial locations, so that it can accurately model long-term and complex motions. ShuttleNet [183] is a concurrent work that considers both feedforward and feedback connections in a RNN to learn long-term dependencies. FASTER [272] designed a FAST-GRU to aggregate clip-level features from an expensive backbone and a cheap backbone. This strategy reduces the processing cost of redundant clips and hence accelerates the inference speed.
LRCN[37]和Beyond-Short-Snippets[253]是在双流网络设置下使用LSTM进行视频动作识别的几篇论文中的第一篇。他们将CNN的特征图作为深度LSTM网络的输入,并将帧级CNN特征聚合为视频级预测。注意,他们分别在两个流上使用LSTM,最终结果仍然是通过后期融合获得的。然而,相比双流基线[187],LSTM模型[253]并没有明显的经验改进。在CNN-LSTM框架的基础上,提出了几种变体,如双向LSTM[205]、CNN-LSTM融合[56]和分层多粒度LSTM网络[118]。[125]描述了包括基于相关的空间注意机制和基于轻量运动的注意机制的VideoLSTM。VideoLSTM不仅展示了动作识别的改进结果,而且还展示了如何仅依靠动作类标签将习得的注意力用于动作定位。晶格-LSTM[196]通过学习单个空间位置的记忆单元的独立隐藏状态跃迁来扩展LSTM,从而能够准确地模拟长期和复杂的运动。ShuttleNet[183]是一项并行工作,它考虑了RNN中的前馈和反馈连接,以学习长期依赖关系。FASTER[272]设计了一种FAST-GRU来聚合来自昂贵主干和廉价主干的剪辑级特征。该策略降低了冗余片段的处理成本,从而提高了推理速度。
However, the work mentioned above [37, 253, 125, 196, 183] use different two-stream networks/backbones. The differences between various methods using RNNs are thus unclear. Ma et al. [135] build a strong baseline for fair comparison and thoroughly study the effect of learning spatiotemporal features by using RNNs. They find that it requires proper care to achieve improved performance, e.g., LSTMs require pre-segmented data to fully exploit the temporal information. RNNs are also intensively studied in video action localization [189] and video question answering [274], but these are beyond the scope of this survey.
然而,上面提到的工作[37,253,125,196,183]使用不同的双流网络/骨干。因此,使用rnn的各种方法之间的区别还不清楚。Ma等人[135]为公平比较建立了一个强有力的基线,并深入研究了使用rnn学习时空特征的效果。他们发现需要适当的关注来实现改进的性能,例如,LSTMs需要预先分割的数据来充分利用时间信息。rnn在视频动作定位[189]和视频问答[274]中也被深入研究,但这些都超出了本次调查的范围。
3.2.4 Segment-based methods
Thanks to optical flow, two-stream networks are able to reason about short-term motion information between frames. However, they still cannot capture long-range temporal information. Motivated by this weakness of two-stream networks , Wang et al. [218] proposed a Temporal Segment Network (TSN) to perform video-level action recognition. Though initially proposed to be used with 2D CNNs, it is simple and generic. Thus recent work using either 2D or 3D CNNs, are still built upon this framework.
由于光流,双流网络能够推理帧之间的短期运动信息。然而,他们仍然不能捕获远程时间信息。基于双流网络的这一弱点,Wang等人[218]提出了一种时间段网络(TSN)来执行视频级别的动作识别。虽然最初建议与2D cnn一起使用,但它简单而通用。因此,最近使用2D或3D cnn的工作仍然建立在这个框架上。
To be specific, as shown in Figure 6, TSN first divides a whole video into several segments, where the segments distribute uniformly along the temporal dimension. Then TSN randomly selects a single video frame within each segment and forwards them through the network. Here, the network shares weights for input frames from all the segments. In the end, a segmental consensus is performed to aggregate information from the sampled video frames. The segmental consensus could be operators like average pooling, max pooling, bilinear encoding, etc. In this sense, TSN is capable of modeling long-range temporal structure because the model sees the content from the entire video. In addition, this sparse sampling strategy lowers the training cost over long video sequences but preserves relevant information.
具体来说,如图6所示,TSN首先将整个视频分割成几个片段,这些片段沿时间维度均匀分布。然后TSN在每个视频片段中随机选择一个视频帧,通过网络转发。在这里,网络共享来自所有段的输入帧的权重。最后,对采样的视频帧进行分段一致性聚合。分段共识可以是像平均池、最大池、双线性编码等操作符。在这个意义上,TSN能够建模远程时间结构,因为模型看到的是整个视频的内容。此外,这种稀疏采样策略降低了长视频序列的训练成本,但保留了相关信息。
Given TSN’s good performance and simplicity, most two-stream methods afterwards become segment-based two-stream networks. Since the segmental consensus is simply doing a max or average pooling operation, a feature encoding step might generate a global video feature and lead to improved performance as suggested in traditional approaches [179, 97, 157]. Deep Local Video Feature (DVOF) [114] proposed to treat the deep networks that trained on local inputs as feature extractors and train another encoding function to map the global features into global labels. Temporal Linear Encoding (TLE) network [36] ap- peared concurrently with DVOF, but the encoding layer was embedded in the network so that the whole pipeline could be trained end-to-end. VLAD3 and ActionVLAD [123, 63] also appeared concurrently. They extended the NetVLAD layer [4] to the video domain to perform video-level encoding, instead of using compact bilinear encoding as in [36]. To improve the temporal reasoning ability of TSN, Tempo- ral Relation Network (TRN) [269] was proposed to learn and reason about temporal dependencies between video frames at multiple time scales. The recent state-of-the-art efficient model TSM [128] is also segment-based. We will discuss it in more detail in section 3.4.2.
由于TSN的良好性能和简单性,大多数双流方法后来都变成了基于段的双流网络。由于分段共识只是进行一个最大或平均池操作,因此特征编码步骤可能会生成一个全局视频特征,并像传统方法[179,97,157]中建议的那样,导致性能的提高。深度局部视频特征(Deep Local Video feature, DVOF)[114]提出将对局部输入进行训练的深度网络作为特征提取器,并训练另一个编码函数将全局特征映射到全局标签。时间线性编码(TLE)网络[36]与DVOF并行,但编码层嵌入到网络中,可实现端到端训练。VLAD3和ActionVLAD[123,63]也同时出现。他们将NetVLAD层[4]扩展到视频域以执行视频级的编码,而不是像[36]那样使用紧凑的双线性编码。为了提高TSN的时间推理能力,节拍关系网络(Tempo- ral Relation Network, TRN)[269]被提出来学习和推理视频帧之间在多个时间尺度上的时间依赖性。最近最先进的高效模型TSM[128]也是基于分段的。我们将在3.4.2节中更详细地讨论它。
3.2.5 Multi-stream networks
Two-stream networks are successful because appearance and motion information are two of the most important properties of a video. However, there are other factors that can help video action recognition as well, such as pose, object, audio and depth, etc.
双流网络之所以成功,是因为外观和运动信息是视频最重要的两个属性。然而,还有其他因素可以帮助视频动作识别,如姿势,对象,音频和深度等。
Pose information is closely related to human action. We can recognize most actions by just looking at a pose (skeleton) image without scene context. Although there is previous work on using pose for action recognition [150, 246], P-CNN [23] was one of the first deep learning methods that successfully used pose to improve video action recognition. P-CNN proposed to aggregates motion and appearance information along tracks of human body parts, in a similar spirit to trajectory pooling [214]. [282] extended this pipeline to a chained multi-stream framework, that computed and integrated appearance, motion and pose. They introduced a Markov chain model that added these cues successively and obtained promising results o
以上是关于论文笔记A Comprehensive Study of Deep Video Action Recognition的主要内容,如果未能解决你的问题,请参考以下文章