Hbase中的各个组件介绍
Posted 疯狂哈丘
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hbase中的各个组件介绍相关的知识,希望对你有一定的参考价值。
文章目录
一、Hbase中的4大组件
1、hbase-client
客户端,用来访问hbase集群。可以和Hbase交互,也可以和HRegionServer交互。都是通过hbase rpc来访问对应的接口。
这里的客户端模式有多种,可以是Thrift、Avro、Rest等。
另外,hbase-client自身会缓存region的一些信息。
2、Zookeeper
作用:
- HMaster的HA,哪个HMaster先抢到zk上的锁,哪个就是active
- 存储-ROOT-表的地址,HMaster的地址
- 存储所有HRegionServer的状态,监控HRegionServer的上下线
- 存储Hbase的一些schema和table的元数据
3、HMaster
HMaster可以启动多个,通过选举机制来保证只有一个HMaster正常运行并提供服务,其他的HMaster作为standby来保证HA。
HMaster主要负责表和Region的管理工作。如:
- 用户对表的增删改查
- 管理RegionServer的负载均衡,调整Region的分布
- 在RegionServer宕机或下线后,负责迁移RegionServer上的Region到其他的RegionServer上
- Region在分裂后,负责分配新的Region
4、HRegionServer
HRegionServer是hbase中真正的工作节点,主要负责响应用户的I/O请求,向HDFS文件系统读写数据,以及Region的数据文件的合并和拆分等,是Hbase中最核心的模块。
在Hbase中,一张表由多个的HRegion组成,一个HRegionServer中管理着多个HRegion对象。而一个HRegion由多个HStore组成,每个HStore对象都对应着表的一个列族(Column Family)。之后,一个HStore又由一个MemStore和多个StoreFile组成。这些StoreFile就是hbase存储在hdfs上的数据文件,MemStore表示还在内存中未刷新到文件上的那些数据。
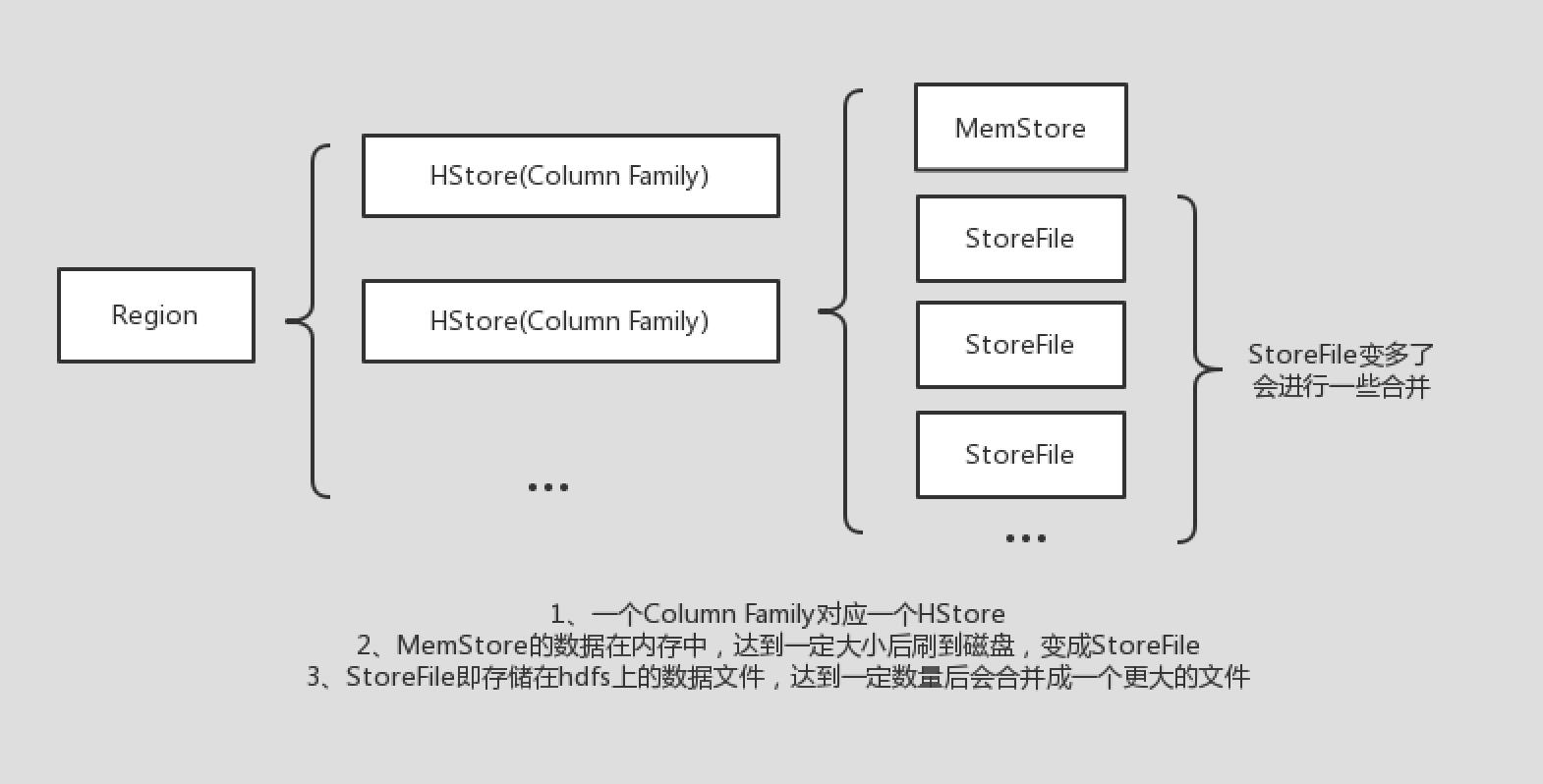
MemStore是基于LSM算法来写数据的,当大小达到一定的量后,会将内存中的数据刷新到磁盘,形成一个新的StoreFile。随着程序的不断运行,StoreFile的数量会越来越多,所以HRegionServer还需要定期的去合并这些StoreFile。
另外,当数据越来越多,一个Region下的StoreFile的总大小会越来越大,为了更好的查询性能,HRegionServer会负责将达到一定大小的Region分裂成两个Region。分配的过程大概就是原Region下线,然后分裂出来的两个新Region由HMaster来分配给相应的HRegionServer(根据负载均衡算法)。
HRegionServer还有一个HLog对象,主要实现了WAL机制。因为hbase是将数据先写到内存,堆积到一定程度才刷新到磁盘,如果HRegionServer突然宕机,就会导致一部分数据丢失。所以通过WAL机制,我们可以保证HRegionServer宕机后数据依旧可以通过WAL日志来恢复。每一个HRegionServer实例只会有一个HLog对象,也就是该HRegionServer上各个表的HRegion的写操作全部记录在一个WAL文件中。
在HRegionServer宕机后,主要数据恢复流程大概如下:
- HMaster通过zk检测到有HRegionServer下线,开始处理它遗留的WAL文件
- 将该WAL文件中不同Region的数据进行拆分,然后放到对应的Region的目录下
- 接着HMaster开始将这些失效的Region进行分配,也就是各个在线的HRegionServer都可能领到这些Region
- HRegionServer实例分配到Region后,发现对应的Region目录下有WAL文件需要处理,就会读取这些数据进行回放,数据也就重新加载到MemStore中去了
二、Hbase 组件的HA保证
1、zk的HA保证
作为一个分布式协调系统,zk本身就有做HA。只要有足够的zk实例在运行,zk就可以正常的提供服务。
zk一般建议部署单数台的实例,这主要和他的选举机制有关。zk在读数据的时候可以去任何一台节点读取数据,但是在写数据时需要把请求转发给leader节点进行处理,如果无法选出leader节点的话,zk集群是无法正常工作的。leader的选举规则是某个节点必须获得超过一半的选票才可以成为leader,所以如果挂掉n/2台,选举无法进行,zk集群就无法提供服务了。举几个例子:
- 假设有2台zk节点,挂掉了一台后,只剩下一台zk节点,这时候只能获取到一个投票,没有超过1/2,所以剩下的那台zk节点也无法成为leader,集群无法提供服务(此时容忍度是可以挂掉0台)
- 假设有3台zk节点,挂掉了一台后,只剩下2台zk节点,这时候可以获取到2个投票,占2/3,超过了1/2,所以zk可以选出leader,是可以正常工作的(此时容忍度是可以挂掉1台)
- 假设有4台zk节点,挂掉两台后,只剩下两台zk节点,这时候只能获取到两个投票,没有超过1/2,所以剩下的那台zk节点也无法成为leader,集群无法提供服务(此时容忍度是可以挂掉1台)
从上面3个例子可以看出,1台zk节点和2台zk节点的容忍度都是0台,3台zk节点和4台zk节点的容忍度都是1台。可以推出2n-1和2n的效果是一样的,没必要花更多的资源去部署多余的zk节点。因此普遍建议部署奇数台zk节点即可。
hbase有许多地方都依赖于zk,如果zk无法正常工作,会严重影响hbase的运行。因此建议zk至少部署3个实例。
2、HMaster的HA保证
HMaster一般采用一主多备的方式来保证HA。HMaster在启动后通过尝试创建zk节点来成为Active,其他没有创建成果的则成为standby。如果active节点的HMaster因为一些原因挂掉了,standby的HMaster实例就可以迅速成为新的active然后开始工作。
HMaster的HA依赖于zk,因此只要zk能正常提供服务,HMaster只要部署2台即可保证高可用。
3、HRegionServer的HA保证
HRegionServer只是一个工作节点,负责一部分的Region,因此只要不是所有的HRegionServer全挂了,都不会对hbase有什么影响。
HRegionServer下线后,HMaster会将它负责的那些Region分发给其他的HRegionServer来管理。
以上是关于Hbase中的各个组件介绍的主要内容,如果未能解决你的问题,请参考以下文章