走进并行时代之GPU篇
Posted threepigs
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了走进并行时代之GPU篇相关的知识,希望对你有一定的参考价值。
上回讲了传统的GPU体系结构,它是完全按照graphics pipeline来设计的,每一级硬件对应与pipeline的的一个stage。其中有两级是可编程的,即vertex shader和pixel shader。在传统的GPU架构下的GPU编程其实就是编写这两个shader的函数,然后通过DX或者OGL的pipeline接口写入GPU设备,通过绘制一遍流水线来实现shader功能。编写shader的通常编程方法是DX下的HLSL,OGL下的GLSL以及NV自己开发的一种语言cg来用于跨这两种平台,这三种语言语法基本上类似,会一种就等于会其他几种。用这种接口的一个弊端就是你必须了解graphics pipeline的原理,才能编写shader函数来实现你需要的通用功能,需要你把一些通用的算法map到graphics pipeline上面,这就是最开始的GPGPU研究的课题。为了隐藏流水线的具体细节,Stanford的图形实验室开发了brook语言,这也是目前AMD的brook+的前身,该语言提供了一种类c的编程接口,把底层的pipeline封装起来,DX或者OGL的接口作为后端。这样使得可编程性大大提高,算法的map由编译器实现。当然这样做损失了性能,编译器设计的好坏对于性能的保持至关重要。
这种传统的GPU架构用于通用计算有着几个问题。一,每次计算都需要扫一遍流水线,增加了额外的流水线开销。二,这种与流水线绑定的硬件设计,它的数据输入和数据输入都是固定的,数据流向也是固定,使得无法在其上设计通用的编程模式,必须遵循流水线的格式。即使有brook这种语言,最后也还是用DX和OGL来作为后端。
统一渲染架构
各显卡厂商为了不让GPU吊死在graphics这一棵树上,对GPGPU的推广那是不遗余力。NV对HPC这块市场虎视眈眈,积极的参加SC会议,2006年12月发布是市面上第一款统一渲染架构的GPU核心—G80,接着推出专用于HPC的Tesla,美其名曰“个人超级计算机”以及发布CUDA来作为通用计算的编程模型。自此GPU正式进入通用计算领域。
统一渲染架构用一句话来描述就是把原本不同硬件stage的可编程shader整个成统一的一套计算资源,是通过调度器来实现逻辑上的分级。在图形方面,这样做能够提高GPU作为显卡的性能,在实际的游戏和三维图形绘制过程中,顶点和像素处理的计算量本就不是固定的,分别用固定的硬件stage来实现显得不够灵活,很容易出现瓶颈,而用统一的一套计算单元的话就可以很灵活根据实际的负载来分配计算单元。在通用计算方面,这样的整合使得GPU的通用性更强。抛开一些用于图形方面的固定部分,如光栅化硬件等,统一渲染架构的GPU已经和CPU的设计类似了,以后还将介绍Intel即将发布的Larrabee显卡,那基本上就是一多核的CPU。这样的设计更有利于对GPU指令集的设计,从而能够设计出其上的更通用的编程模型,CUDA就得益于这种通用的统一渲染架构的设计。
G80体系结构
因为我自己用的是8800,所以在这里主要介绍G80。AMD的RV系列统一架构核心和G80系列大同小异,有些关键的不同接下来的篇幅会稍微提提。有一点得提一下,虽然06年12月的G80是市面上第一款统一渲染架构显卡,但其实统一渲染架构的思想05年就出现过,无意中发现05年的MICRO上的《Shader Performance Analysis on a Modern GPU Architecture》这篇文章的ATTILA架构就是统一渲染架构的,虽然ATTILA在最终只是一款模拟器,并没有真正的芯片流出,但这是我见过的最早的统一渲染思想的GPU了。那时候nv内部可能也已经在设计G80了。
G80的相关资料网上很多,不过基本上都只是功能上的一种介绍,都没给出具体的硬件细节,我是希望能够像了解CPU那样深入到指令流水线,最好能够精确到各个时钟周期。不过GPU毕竟不像CPU,存在着开源的IP核,GPU的IP核都掌握在各显卡厂商手中,很难了解太多的硬件细节。我主要综合nv官方的文档以及一些paper上的讨论,再结合nv的技术论坛上面的一些讨论贴等,对G80的硬件机制做了些猜测,欢迎拍砖。
介绍下主要的资料来源:
一。G80相关paper,在这里推荐几篇个人觉得不错的。
NVIDIA TESLA:A Unified Graphics and Computing Architecture。MICRO 08上的一篇论文,主要介绍G80和CUDA。
LU,QR and Cholesky Factorizations using Vector Capabilities of GPUs。UCB的一篇技术报告,主要是从性能上来分析GPU架构。特别是有一小节介绍了GPU的Memory System,作者自己做测试来分析GPU相关的Cache机制以及测试了访问memory需求的时钟数。
二。nv技术论坛上的一些讨论贴,nv的开发人员会在上面回答,可靠性还是可以得到保证的吧。
三。CUDA学习资料
CUDA的编程模式非常的接近硬件机制,可以通过CUDA来猜测内部的硬件细节。比较好一点的CUDA学习资料就是nv的官方文档NVIDIA_CUDA_Programming_Guide,还有就是UIUC的一个CUDA课程的课件,上面有几次课讲得还是有点硬,可以借鉴下。
四。其他网站的一些技术资料
http://www.anandtech.com/video/showdoc.aspx?i=2870上面介绍的G80
http://anandtech.com/video/showdoc.aspx?i=3334上面介绍了GT200,GT200是GTX280的核心,架构和G80差不多,只不过计算单元几乎翻倍,所以GTX280的性能比8800高一倍左右吧。
http://www.realworldtech.com/page.cfm?ArticleID=RWT090808195242&p=1这篇也是讲GT200的,关于指令执行单元这块讲得不错。
毕竟是商业的处理器,很多硬件细节都没有公布,只能通过网上的一些资料拼拼凑凑猜测一下。
和研究CPU一样,了解GPU的体系结构最先想到的就是指令集了,不过G80的native ISA并没公布,一方面由于商业机密,另一方面也是GPU的指令集更新换代太快,也没有兼容性,不像x86那样。所以就算给你了,也只是了解下,也很难根据具体的ISA来做相关的优化编程,这样可移植性太差,把自己绑定在一款具体的显卡上了。不过Intel即将发布的Larrabee是采用了扩展x86来作为GPU的指令集。虽然无法得到native ISA,不过CUDA提供了一套上层的汇编ptx来提供指令集的GPU编程。周昆的BSGP语言就是把ptx来作为编译器后端,引起了nv的兴趣,这回拿到的nv合作伙伴教授奖应该就是由于这个成果。由于CUDA的编程模式和GPU底层的硬件非常接近,合着CUDA编程来了解G80会更加透彻一点。

上图就是G80的总体架构图,没有了vertex shader也没有了pixel shader,代之的是128个sp以及一些相关的线程调度器。在这里有两类的调度器,一类是graphics相关的,用来做顶点和像素计算的调度分发指令,从而区分vertex和pixel shader,128个SP组成的计算单元并行的执行流水线的各个stage。另一类就是专门用来做通用计算,主要对CUDA线程块的调度。我并不打算介绍G80的显卡功能,主要是介绍G80作为通用计算的执行流水线。
CUDA是专门用来做GPU通用计算的,它是C语言的一个极小扩展,这些扩展就是为了在普通的C程序,无缝的添加GPU代码。对程序员来说,利用GPU编程就和调用普通的函数一样。声明一个kernel函数作为GPU的入口函数,由于GPU的存储系统是显存,它和系统内存是分开的,GPU的代码并不能直接的访问系统内存,于是kernel函数的数据输入输出就必须得显式的通过CUDA相关的API来做。这也是AMD想弄fusion的一个原因,想弄个统一的存储器。数据段搞定了就差指令段了,nvcc编译器把GPU代码(kernel函数以及其他调用到的GPU函数)编译成G80的native指令,这段代码序列就是即将在GPU设备中运行的代码段。接着在kernel函数的调用点嵌入一个stub函数,该函数是CUDA代码的runtime system,做相应的初始化以及入口函数调用,这里的入口函数调用是通过CUDA的driver,发射编译好的GPU mative代码到G80设备,然后启动GPU计算。于是乎CPU和GPU就并行的执行各自的代码。
回到上面的架构图,G80虽然有128个SP,不过并不是这些SP都是独立的执行自己的指令,从图上可以看出,这些SP被分成了16个SM,每个SM是一个SIMD的多处理器,执行的同一条指令,各个SM之间是独立的。另外图上还有一个TPC的概念,2个SM组成了一个TPC,这个概念主要用于图形流水线,可以看出属于同一个TPC的两个SM是共享纹理单元的,根据一致性的原则,在进行图形绘制的过程中,一般可以将邻接的4个像素绑定处理,每个像素4个分量就需要16个处理单元,刚好2个SM。这与通用计算无关,也就不去说它了。主要是看看SM的执行机制。
在这里得先说下CUDA的线程结构。GPU是靠多线程来充分的利用这么多的SP,创建的线程的数目在kernel函数调用时确定,当然由于硬件的限制,支持的线程数是有上限的。目前的CUDA是data-parallel而不是task-parallel,所有的线程的函数都是同一个kernel,只是把数据进行划分而并行处理,而不是多个任务进行并行执行。这个主要还是受GPU硬件本身的限制。这些线程有活动和非活动之分,所谓活动的也就是已经获得了硬件资源,可以随时执行,就类似于就绪状态。线程执行所需的硬件资源主要有下面几种:IP寄存器肯定是要的,还需要运行时刻用到的其他寄存器,另外还有相关的memory。
创建的线程被分为许多的块(block),每个块包含许相同数量的线程。图中的Compute work distribution部件是一个全局的调度器,当有某个SM上活动的线程块执行完退出的时候,来负责把非活动的线程块分配到某个SM的,这样一个block就是该全局调度器的最小调度单位。调度也不需要太多的工作,只需要把刚刚退出的线程块的硬件资源分给即将调度的线程块。G80就是利用把线程所需的硬件资源划分成不交的各个部分来实现线程切换的零等待,每个线程都有它自己的一套运行时刻寄存器组,在切换的时候就并不需要做相应的上下文切换。每个block都有共享的一块shared memory,这块memory的访问速度是cache级别的,位于SM内部,block内的所有线程都可以可以共享之。shared memory也是G80开始特有的硬件结构,利用好这块内存可以大大的优化算法。不过每个SM的shared memory大小是有限的,G80是16K,GT200是24K,因此每个SM可以同时容纳的活动block的数目是和每个block所用的shared memory大小相关的。只要一个block块被分配了上诉的三个主要硬件资源,那么就可以进入SM的就绪队列等待执行了。
现在终于可以开始介绍核心的SM执行机制了。下图就是SM的结构。
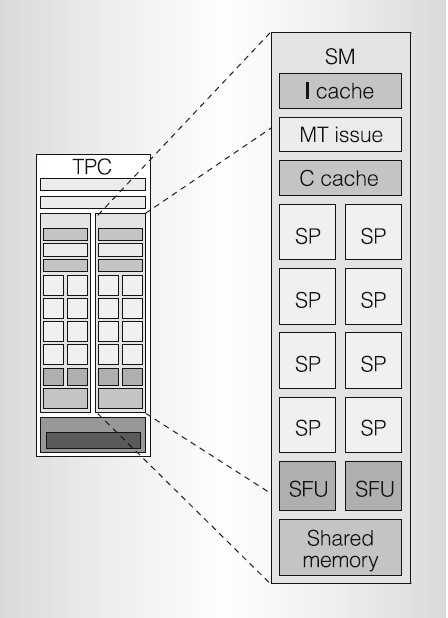
在SM中只有8个SP,计算单元是有限的,因此每个就绪的block就又分为许多的warp,目前的硬件下面warp的大小是32,也就是说SM每次调度32个线程执行。也许你会有疑问只有8个SP,怎么执行32个线程呢?这确实是一个很疑惑的问题,nv的技术论坛上也很多人在问,经过综合各方面的资料,稍微了解了一些G80的这种机制。我们先从SM的架构图开始,首先一个指令Cache,就如我们所知,SM是一个SIMD的结构,这8个SP共享一条指令path。MT的issue单元就从指令Cache取址,然后译码、发射到SP内执行。一个SM最多允许24个warp执行,warp间的切换是零等待,可以随时执行。这样就可以通过这些活动的warp来做访问内存的延迟隐藏以及指令流水线执行期的等待隐藏。这点和CPU不一样,CPU对访存的隐藏是通过Cache,但是Cache需要大量的晶体管,而GPU是希望把更多的晶体管用于计算单元。CPU对指令执行的隐藏则利用的是指令级的并行性以及指令的乱序执行。GPU并没有OOO机制,他是完全的按照指令的顺序一条一条的执行下来,当某条指令需要等待时就马上切换到另一个warp。回答一开始的问题,只有8个SP,那么我们就分为4个clock来执行一个warp总行了吧。这样做确实怪怪的,这应该是nv为了能够更好的隐藏延迟,充分把SP计算单元填满所做的一个trade off吧。我也只能做一点点猜测。首先decoder部件的频率和是SP的计算频率是不同的,可以查到decoder的core clock比SP的频率慢了一倍多,所以每发射一条指令,实际上SP已经经历了2个clock,因此你的warp至少得是16个线程才保证你执行完了之后不用等待issue部件的下一条指令。根据CUDA的programming guide 5.1.1.1的说法是为了发射一条指令需要4个SP clock,如果这样的话那么就不难理解为什么在目前的G80硬件下面一个warp的大小是32了。只是有个疑问就是为什么nv要把发射硬件做得这么慢,需要4个clock才能发射一条指令,这个估计也就nv内部的硬件设计师才能回答的问题了。不过我想为了支持双发射也是原因之一。G80的一个SP里面有一个Integer Scalar Unit、一个32位的MAD(乘加) Scalar Unit和一个32位的MUL Scalar Unit,衡量GPU性能是用每秒多少次浮点运算,这里主要是考虑FP单元,可以把MAD和MUL做双发射,同时执行。我上面介绍的一个网站对SM的细节讲得挺好,可以参考一下来看SM的双发射。
http://www.realworldtech.com/page.cfm?ArticleID=RWT090808195242&p=9
按照那篇文章的说法就是这发射指令的4个clock被分为两部分,前两个clock来发射MAD指令(刚好是一个Core clock),后两clock用来发射MUL,这里注意发射的这4个clock发射的两条指令是属于同一个warp,因为要支持双发射必须你的MAD指令后面刚好跟着一条MUL,这就需要编译器做些调度工作了。总得来说用了4个clock发射指令,那么自然的就需要32个线程组成一个warp,用4个clock执行这个warp instruction。
我们来看看这些warp是如何来隐藏指令流水线的延迟的。根据nv技术论坛上的内部人员的说法:指令执行的延迟大概是20个时钟,那么我们只需要6个warp来做延迟,也就是说当一个warp开始执行以后需要24个时钟左右才结束,那么这20个时钟就可以拿来发射别的warp的指令,4 clocks/warp*6 warps刚好是24个时钟。
nv的G80和amd的统一渲染架构RV600的一个最大的区别就是G80的SP是标量单元,而RV600则是向量单元,如果做显卡来使用的话这个问题不大,因为都是按像素像素的处理,但如果用于通用计算就麻烦了,这个需要程序员和编译器都要做些优化,能够把几条变量指令打包成一条向量指令才能最大程度的发挥他的所有计算单元,就类似于SSE的优化。
最后就是G80的memory system,比如Cache的设计和TLB的设计之类的技术,可以看看上面推荐的技术报告
LU,QR and Cholesky Factorizations using Vector Capabilities of GPUs
不过里面的结论都只是自己测试后的结论,官方并没公布这些细节,也就没什么好讲的了。
总算把G80介绍完了,看了很多资料也,做了很多推测才完成。G80,G92一直到如今的GT200,都是差不多的机制,看看下一代的统一渲染架构能够玩出什么花样来吧。另外也非常期待Intel的Larrabee,这个利用许多In order的CPU cores来实现GPU功能的另类GPU。
以上是关于走进并行时代之GPU篇的主要内容,如果未能解决你的问题,请参考以下文章