FFmpeg学习音频基础
Posted 贺二公子
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了FFmpeg学习音频基础相关的知识,希望对你有一定的参考价值。
原文地址:https://www.cnblogs.com/ssyfj/p/14649438.html
文章目录
一:音频入门
(一)声音三要素

1.音调(音频)
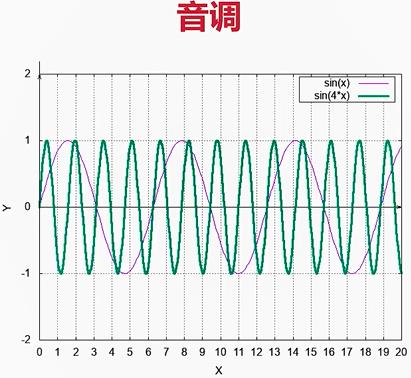
2.音量(振幅)
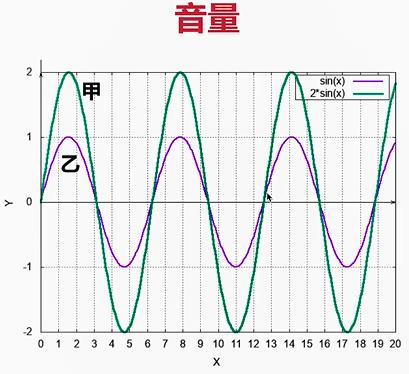
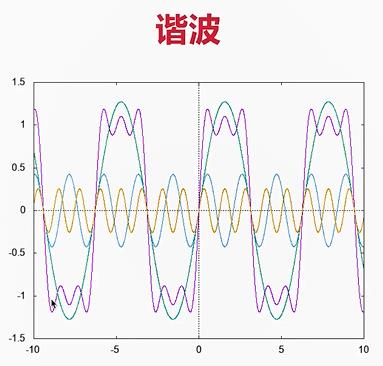
3.音色(谐波)
- 粉色曲线是最接近自然界中的波形(基频+多种不同频率音频合并:如黄色、蓝色)
- 绿色曲线为基频(主频率),可以看到粉色曲线都是在主频率上微调(走势是基本一致的)
- 越接近正弦波,声音一般越好听,畸形或产生噪波
(二)模数转换
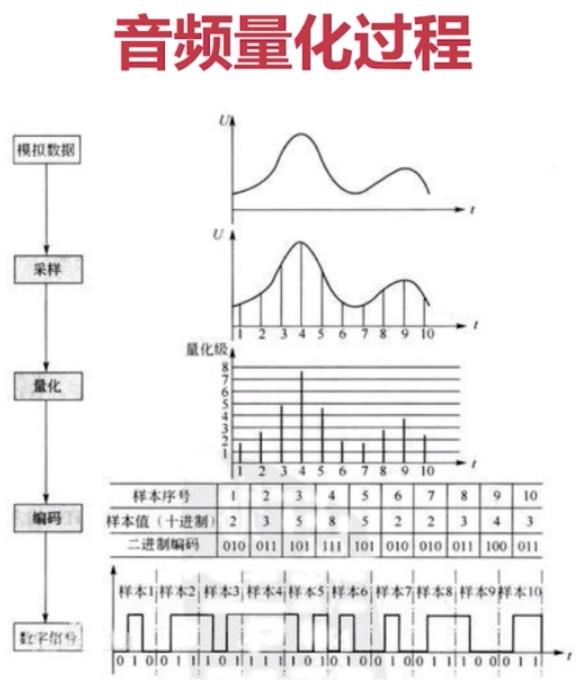
模拟信号和数字信号之间可以相互转换:
- 模拟信号一般通过PCM脉码调制(Pulse Code Modulation)方法量化为数字信号,即让模拟信号的不同幅度(采样大小)分别对应不同的二进制值,例如采用8位编码可将模拟信号量化为2^8=256个量级,实用中常采取24位或30位编码;
- 数字信号一般通过对载波进行移相(Phase Shift)的方法转换为模拟信号。
补充:通常的 不同幅度(采样大小) 分别对应不同的二进制值==采样率(每秒采样次数)为48000、32000、16000等等;采样率越高,数据信号还原为模拟信号的还原度越高!!!
计算机、计算机局域网与城域网中均使用二进制数字信号,目前在计算机广域网中实际传送的则既有二进制数字信号,也有由数字信号转换而得的模拟信号。但是更具应用发展前景的是数字信号。
(三)音频原始数据
音视频常用格式有以下两种:
- PCM数据:纯音频数据;
- WAV(多媒体文件):既可以存储PCM原始数据(多用),又可以存储压缩数据;
其实WAV就是在PCM原始数据之上,加上了一个头,包含了基本信息(使得播放器使用正确的参数去播放PCM数据)


采样率48000,位深度 16bit ,通道数2
知道这三个参数,那么基本我们就知道了
设备1秒内可以采集到多少音频数据是:
\\qquad 48000 * 16 * 2 = 1536000 位
\\qquad 48000 * 16 * 2 / 8 = 192000 字节.
\\qquad
也就是我的设备在一秒内可以采集192000
这么大的码流显然无法在我们的网络中传输!!!(不能带宽全给音视频传输吧),所以要进行音频数据压缩!!!
(四)音频帧大小的计算(采样率和时间间隔的区别)
采样率是指在1秒中的采样次数,而时间间隔是指每采取一帧音频数据所要时间间隔!!!
假设音频采样率 = 8000,采样通道 = 2,位深度 = 16,采样间隔 = 20ms
\\qquad
首先我们计算一秒钟总的数据量,采样间隔采用20ms的话,说明每秒钟需采集50次,这个计算大家应该都懂,那么总的数据量计算为
\\qquad
一秒钟总的数据量 = 8000 * 2*16/8 = 32000
\\qquad
所以每帧音频数据大小 = 32000/50 = 640
\\qquad
每个通道样本数 = 640/2 = 320
解析:#define MAX_AUDIO_FRAME_SIZE 192000
是指双通道下,采用48k采样率,位深为16位,采样时间为1s
\\qquad 48000×2×16/8=192000字节
(五)PCM存储格式
PCM存储格式大体分为两种Planner和Packed。以双声道为例,L表示左声道,R表示右声道,如下为两种格式的存储方式:
- Planner:LLLLLLLL… RRRRRRRR…
- Packed:LRLRLRLRLR…
FFMpeg中对音频Format定义如下:
enum AVSampleFormat
AV_SAMPLE_FMT_NONE = -1,
AV_SAMPLE_FMT_U8, ///< unsigned 8 bits
AV_SAMPLE_FMT_S16, ///< signed 16 bits
AV_SAMPLE_FMT_S32, ///< signed 32 bits
AV_SAMPLE_FMT_FLT, ///< float
AV_SAMPLE_FMT_DBL, ///< double
AV_SAMPLE_FMT_U8P, ///< unsigned 8 bits, planar
AV_SAMPLE_FMT_S16P, ///< signed 16 bits, planar
AV_SAMPLE_FMT_S32P, ///< signed 32 bits, planar
AV_SAMPLE_FMT_FLTP, ///< float, planar
AV_SAMPLE_FMT_DBLP, ///< double, planar
AV_SAMPLE_FMT_S64, ///< signed 64 bits
AV_SAMPLE_FMT_S64P, ///< signed 64 bits, planar
AV_SAMPLE_FMT_NB ///< Number of sample formats. DO NOT USE if linking dynamically
;
我们这里以WASAPI为例,在windows中WASAPI捕获的数据格式总是FLT,即浮点Packed格式,而新版的FFMpeg中仅仅支持FLTP格式压缩(应该是需要自行编译FFMpeg库并附加其他压缩库,如有错请指正),目前网络中的大部分博客均是老版FFMpeg所以还都在使用其他格式。因此我们需要对PCM数据进行重新采样。
(六)WAV header
在查看音频数据压缩方式前,先了解 WAV header的数据结构:
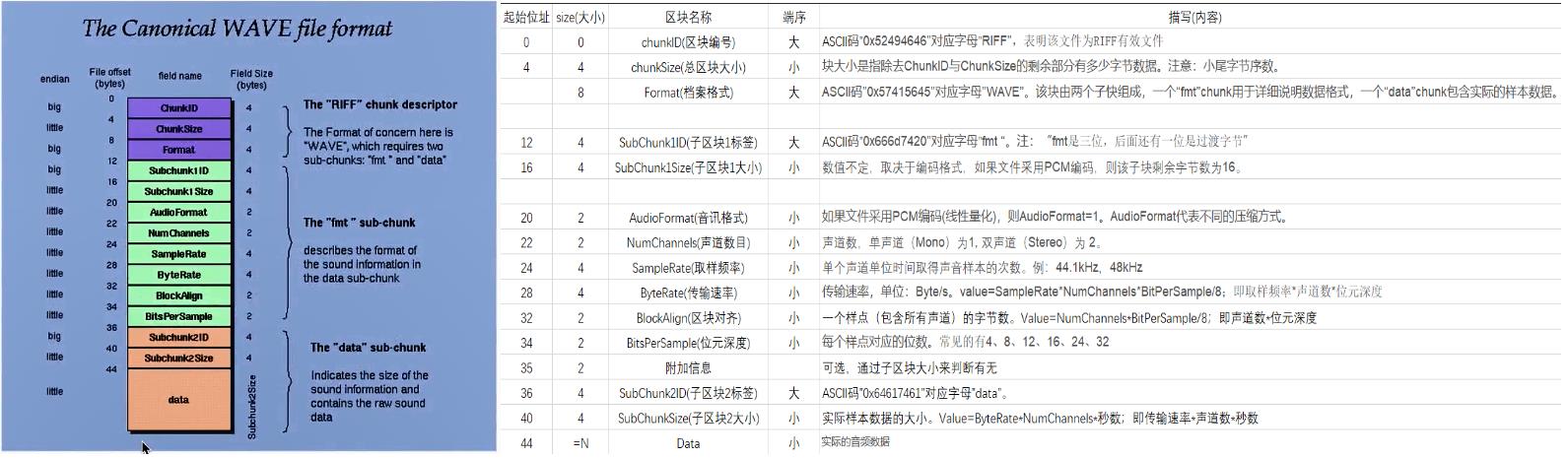
WAV例子:
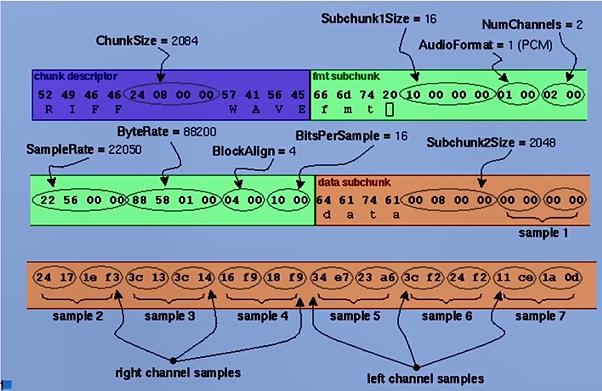
因为是4字节对齐,所以每个sample大小4字节;而之所以是4字节,取决于blockAlign字段=(幅度大小×通道数);
二:音频处理流程

(一)直播客户端的处理流程
我们讲解的音视频都是基于娱乐直播进行讲解的,所以我们必须对整个流程非常清楚。
如下图,是一个基本的直播客户端的处理流程图:
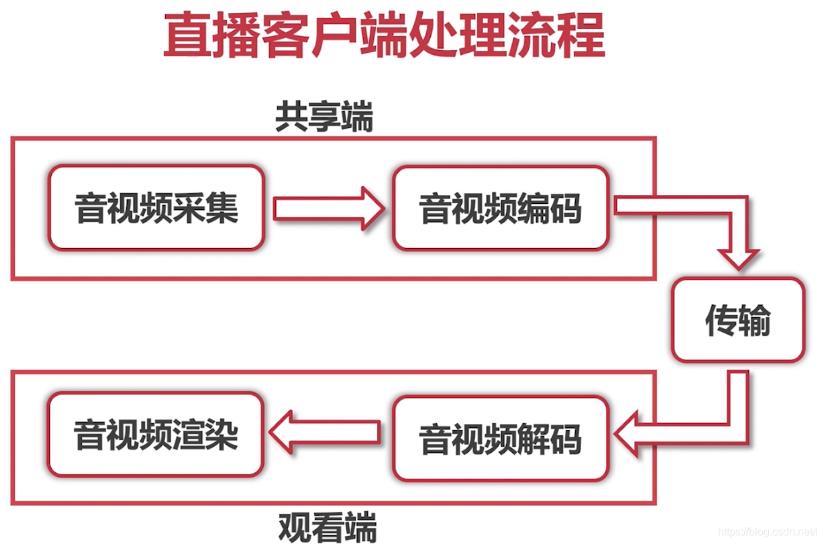
直播客户端分为几个模块,我们需要对每个模块做的事情非常清楚。总的来说我们直播客户端分为两个端:共享端和观看端。
- 共享端包含:音视频采集,音视频编码两个模块
- 观看端包含:音视频解码,音视频渲染两个模块。
1.音视频采集:
音频采集一般我们只需要简单调用一下api就能实现,每个操作系统都提供了相对应的api, 只是对于不同的平台各不相同。
如android端有audioRecord, mediaRecord等,我们什么时候使用audioRecord,什么时候使用MediaRecord,这个我们需要非常清楚它的应用场景。
同样在ios 端有苹果提供的AVFoundation框架提供了很多音视频采集的方法,其中有很常用的底层方法AudioUnit。
2.音视频编码:
我们采集到音视频之后并不能直接传输,因为这个数据太大了,超出了我们网路的设备的负载。
如果我们直接传输这么大量的数据,很容易出现各种问题,因此我们必须对这些数据进行压缩后再进行传输,这个压缩的过程就是对音视频的编码处理。
编码后的数据就是非常小的数据了。
对于编码这块的知识也非常多,我们后续也会详细讲解。
编码分为有损编码和无损编码。我们什么时候用有损编码,什么时候使用无损编码? 有损编码去掉的是哪些数据?这些原理我们都需要很清楚明白。
3.音视频传输:
编码时候,我们就需要把数据传输到对端,这个传输的过程也是非常复杂的,需要对网络知识有个较好的理解。后续我也讲到这些。
4.音视频解码:
对端收到传输的数据后,需要对编码的数据进行解码,把压缩的数据还原后才能进行播放渲染。解码这块是跟编码相对应的,用什么方式编码,就需要用对应的方式解码。
5.音视频渲染:
解码获取得到原始数据之后,音频交给扬声器播放(实际是交给驱动,驱动交给驱动硬件模块进行处理),视频交给渲染器进行渲染。
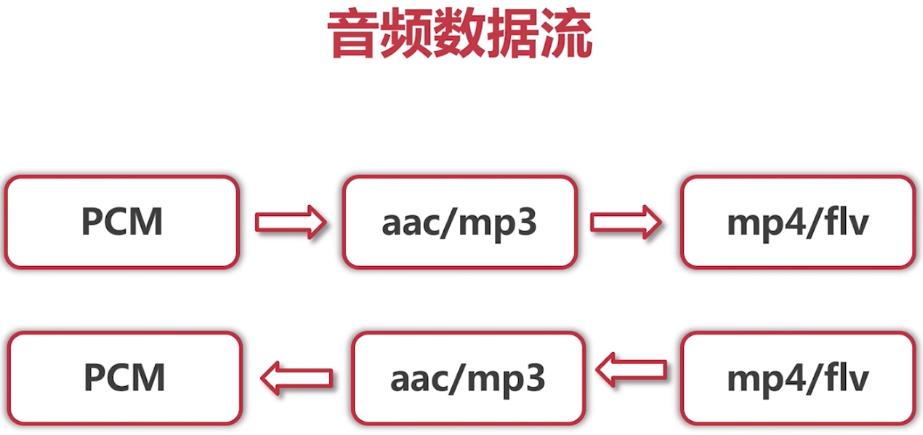
(二)音频数据的流转(格式的转换)
我们需要知道我们采集数据后,采集的是什么数据,是PCM数据(模拟数据转数字信号,数字信号就是PCM)。然后经过编码之后,编码出的是什么格式的数据(aac/mp3)。这都是我们需要理解的。
对于录制的视频,我们最后将音视频保存入容器中;对于直播来说,我们并不需要最后一步,不需要将他存入容器中!!!
如下图是音频数据流的流转过程:
三:音频采集
(一)各平台音频采集方式
1.Android端音频采集:https://blog.csdn.net/u010029439/article/details/85056767
android平台上的音频采集一般就两种方式:
- 使用MediaRecorder进行音频采集。
MediaRecorder 是基于 AudioRecorder 的 API(最终还是会创建AudioRecord用来与AudioFlinger进行交互) ,它可以 直接将采集到的音频数据转化为执行的编码格式,并保存。
这种方案相较于调用系统内置的用用程序,便于开发者在UI界面上布局,而且系统封装的很好,便于使用,唯一的 缺点是使用它录下来的音频是经过编码的,没有办法的得到原始的音频。
同时MediaRecorder即可用于音频的捕获也可以用于视频的捕获相当的强大。实际开发中没有特殊需求的话,用的是比较多的! - 使用AudioRecord进行音频采集。
AudioRecord 是一个比较偏底层的API,它可以获取到一帧帧PCM数据,之后可以对这些数据进行处理。
AudioRecord这种方式 采集最为灵活,使开发者最大限度的处理采集的音频,同时它 捕获到的音频是原始音频PCM格式的!
像做变声处理的需要就必须要用它收集音频。
在实际开发中,它也是最常用来采集音频的手段。如直播技术采用的就是AudioRecorder采集音频数据。
2.Ios端音频采集:https://blog.51cto.com/u_13505171/2057075
3.Windows音频采集:https://blog.csdn.net/machh/article/details/83546258
(二)FFMpeg采集音频方式(集成上面所有平台)
(1)通过命令方式(不同平台可能不同):https://www.cnblogs.com/ssyfj/p/14576359.html
先查看可用设备:
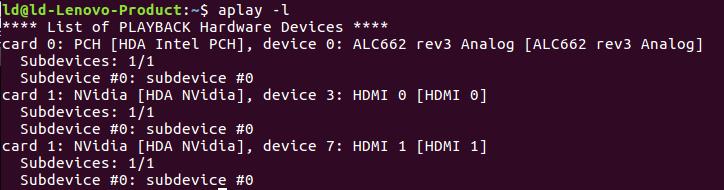
其中card中:PCH与NVidia是声卡类型,可以通过查看cat /proc/asound/cards文件查看所有在主机中注册的声卡列表:

其中device设备中:
- HDMI:是高清多媒体接口(High Definition Multimedia Interface,HDMI)是一种全数字化视频和声音发送接口,可以发送未压缩的音频及视频信号。
- alc662是声卡:声卡 (Sound Card)也叫音频卡(港台称之为声效卡),是计算机多媒体系统中最基本的组成部分,是实现声波/数字信号相互转换的一种硬件。声卡的基本功能是把来自话筒、磁带、光盘的原始声音信号加以转换,输出到耳机、扬声器、扩音机、录音机等声响设备,或通过音乐设备数字接口(MIDI)发出合成乐器的声音
所以:想要录取声音,我们必须选取card:0,其他的device与subdevice可以任意
选取对应设备获取输入:
ffmpeg -f alsa -i hw:0 alsaout.wav
(2)通过API方式:如下(三)
(三)FFmpeg编程采集音频
1.打开输入设备
#include <libavutil/log.h>
#include <libavcodec/avcodec.h>
#include <libavdevice/avdevice.h>
#include <libavformat/avformat.h>
int main(int argc,char* argv)
char* devicename = "hw:0";
char errors[1024];
int ret;
av_register_all();
av_log_set_level(AV_LOG_DEBUG);
//注册所有的设备,包括我们需要的音频设备
avdevice_register_all();
//获取输入(采集)格式
AVInputFormat *iformat = av_find_input_format("alsa");
//打开输入设备
AVFormatContext* fmt_ctx=NULL;
AVDictionary* options=NULL;
ret = avformat_open_input(&fmt_ctx,devicename,iformat,&options);
if(ret<0)
av_strerror(ret,errors,1024);
av_log(NULL,AV_LOG_ERROR,"Failed to open audio device,[%d]%s\\n",ret,errors);
av_log(NULL,AV_LOG_INFO,"Success to open audio device\\n");
return 0;
gcc -o od 01OpenDevice.c -I /usr/local/ffmpeg/include/ -L /usr/local/ffmpeg/lib/ -lavutil -lavformat -lavcodec -lavdevice

2.从音频设备中读取音频数据
#include <libavutil/log.h>
#include <libavcodec/avcodec.h>
#include <libavdevice/avdevice.h>
#include <libavformat/avformat.h>
int main(int argc,char* argv)
char* devicename = "hw:0";
char errors[1024];
int ret,count=0;
AVFormatContext* fmt_ctx=NULL;
AVDictionary* options=NULL;
AVInputFormat *iformat=NULL;
AVPacket packet; //包结构
av_register_all();
av_log_set_level(AV_LOG_DEBUG);
//注册所有的设备,包括我们需要的音频设备
avdevice_register_all();
//获取输入(采集)格式
iformat = av_find_input_format("alsa");
//打开输入设备
ret = avformat_open_input(&fmt_ctx,devicename,iformat,&options);
if(ret<0)
av_strerror(ret,errors,1024);
av_log(NULL,AV_LOG_ERROR,"Failed to open audio device,[%d]%s\\n",ret,errors);
av_log(NULL,AV_LOG_INFO,"Success to open audio device\\n");
//开始从设备中读取数据
while((ret=av_read_frame(fmt_ctx,&packet))==0&&count++<500)
av_log(NULL,AV_LOG_INFO,"Packet size:%d(%p),cout:%d\\n",packet.size,packet.data,count);
//释放空间
av_packet_unref(&packet);
//关闭设备、释放上下文空间
avformat_close_input(&fmt_ctx);
return 0;
gcc -o gap 02GetAudioPacket.c -I /usr/local/ffmpeg/include/ -L /usr/local/ffmpeg/lib/ -lavutil -lavformat -lavcodec -lavdevice
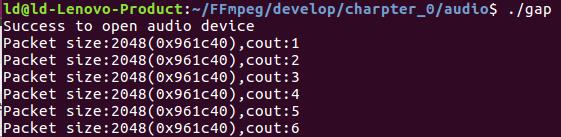
包的大小同码率/8=字节数
3.录制成为音频文件
- 流程:创建文件—>将音频数据写入到文件中—>关闭文件
#include <stdio.h>
#include <libavutil/log.h>
#include <libavcodec/avcodec.h>
#include <libavdevice/avdevice.h>
#include <libavformat/avformat.h>
int main(int argc,char* argv)
char* devicename = "hw:0";
char errors[1024];
int ret,count=0,len;
FILE* fp = NULL;
AVFormatContext* fmt_ctx=NULL;
AVDictionary* options=NULL;
AVInputFormat *iformat=NULL;
AVPacket packet; //包结构
av_register_all();
av_log_set_level(AV_LOG_DEBUG);
//注册所有的设备,包括我们需要的音频设备
avdevice_register_all();
//获取输入(采集)格式
iformat = av_find_input_format("alsa");
//打开输入设备
ret = avformat_open_input(&fmt_ctx,devicename,iformat,&options);
if(ret<0)
av_strerror(ret,errors,1024);
av_log(NULL,AV_LOG_ERROR,"Failed to open audio device,[%d]%s\\n",ret,errors);
av_log(NULL,AV_LOG_INFO,"Success to open audio device\\n");
//打开文件
fp = fopen("./audio.pcm","wb");
if(fp==NULL)
av_log(NULL,AV_LOG_ERROR,"Failed to open out file,[%d]%s\\n",ret,errors);
goto fail;
//开始从设备中读取数据
while((ret=av_read_frame(fmt_ctx,&packet))==0&&count++<500)
av_log(NULL,AV_LOG_INFO,"Packet size:%d(%p),cout:%d\\n",packet.size,packet.data,count);
len = fwrite(packet.data,packet.size,1,fp);
fflush(fp);
if(len!=packet.size)
av_log(NULL,AV_LOG_WARNING,"Warning,Packet size:%d not equal writen size:%d\\n",len,packet.size);
else
av_log(NULL,AV_LOG_INFO,"Success write Packet to file");
//释放空间
av_packet_unref(&packet);
fail:
if(fp)
fclose(fp);
//关闭设备、释放上下文空间
avformat_close_input(&fmt_ctx);
return 0;
gcc -o wad 03WriteAudioData.c -I /usr/local/ffmpeg/include/ -L /usr/local/ffmpeg/lib/ -lavutil -lavformat -lavcodec -lavdevice
注意:播放时需要指定格式,通过查看配置文件获取采样率等信息
sudo gedit /etc/pulse/daemon.conf

ffplay -ar 44100 -ac 2 -f s16le audio.pcm
四:音频压缩
(一)音频有损压缩技术(消除冗余信息)

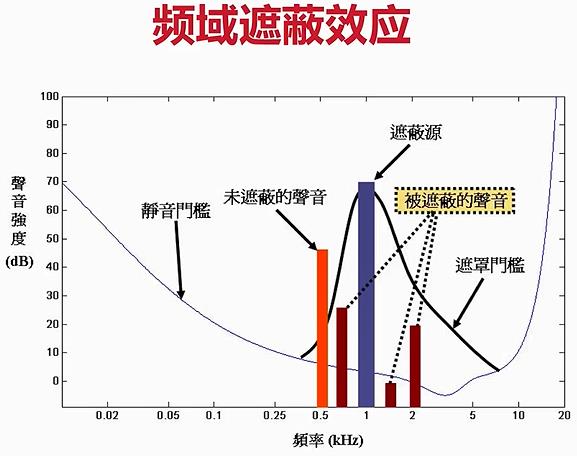
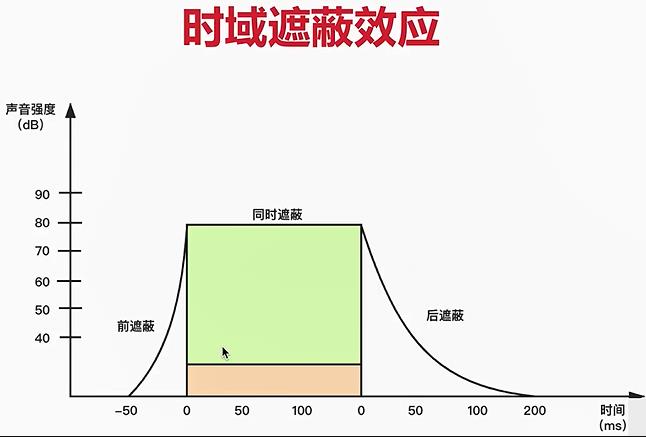
注意:频域遮蔽效应和时域遮蔽效应的纵轴都是声音强度;
- 频域遮蔽的横轴是频率,是指在频率相近的声音,在一定的范围内(遮蔽门槛下的声音),声音强度大的会遮蔽声音强度小的声音。
- 时域遮蔽的横轴是时间,是指在时间相近的声音,声音强度大的会遮蔽声音强度小的声音,而且在发声前的部分较弱的声音(前遮蔽)和发声后的部分较弱的声音都会被屏蔽掉(后遮蔽)。
(二)音频无损压缩技术
- 哈夫曼编码
- 算术编码
- 香农编码
(三)音频编码过程
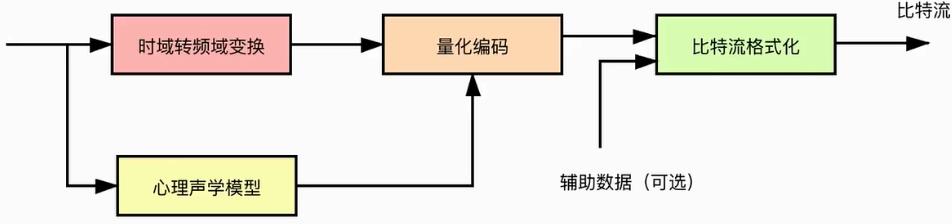
- 原始数据
- 传入给两个模块进行处理
- 时域转频域变换(将一段长时间的数据,转换为多种频段的数据,从而获取我们需要的频段数据)
- 心理声学模型(前面的有损压缩过程)
- 将两种数据(真正需要编码的数据)汇总,进行量化,编码
- 形成比特流
(四)常见的音频编码器

其中最常见的是OPUS和AAC:延迟小,压缩率高
- 实时互动系统可以用opus(在线教育、会议),其中WebRTC默认使用OPUS
- 泛娱乐化直播一般使用AAC(最广泛),opus一般不支持,推广上有些困难
- 两个系统融合,需要将opus与AAC互转
- speex:回音消除,降噪模块等可实现。
- G.711:有些会与固话相联系,固话用的就是G.711,或者G.722 (声音损失严重,但是可以在窄宽带下传输)
音频编码器性能质量对比:
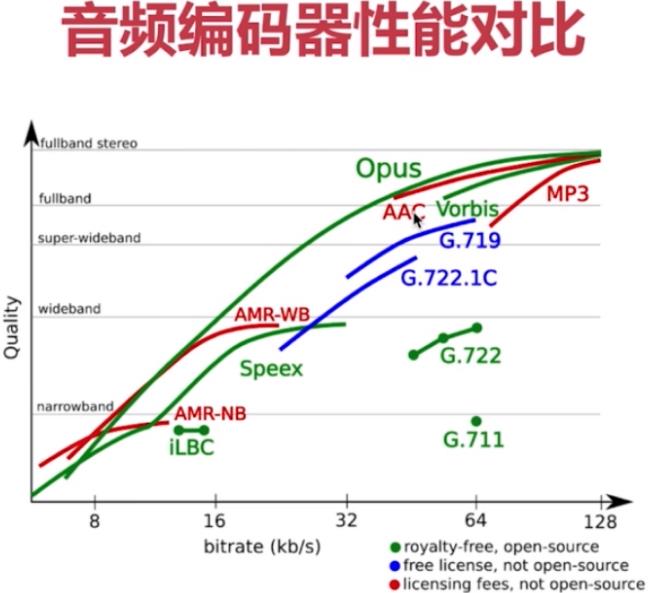
- 横轴:比特率越大(质量越好),但是传输速度可能较低;所以对于实时性要求高的,如OPus,在窄带时,会降低质量,从而提高传输速度
- 纵轴:带宽质量(窄带、宽带、全带),硬件设施有关
音频编码码率对比:(结合上面性能图)
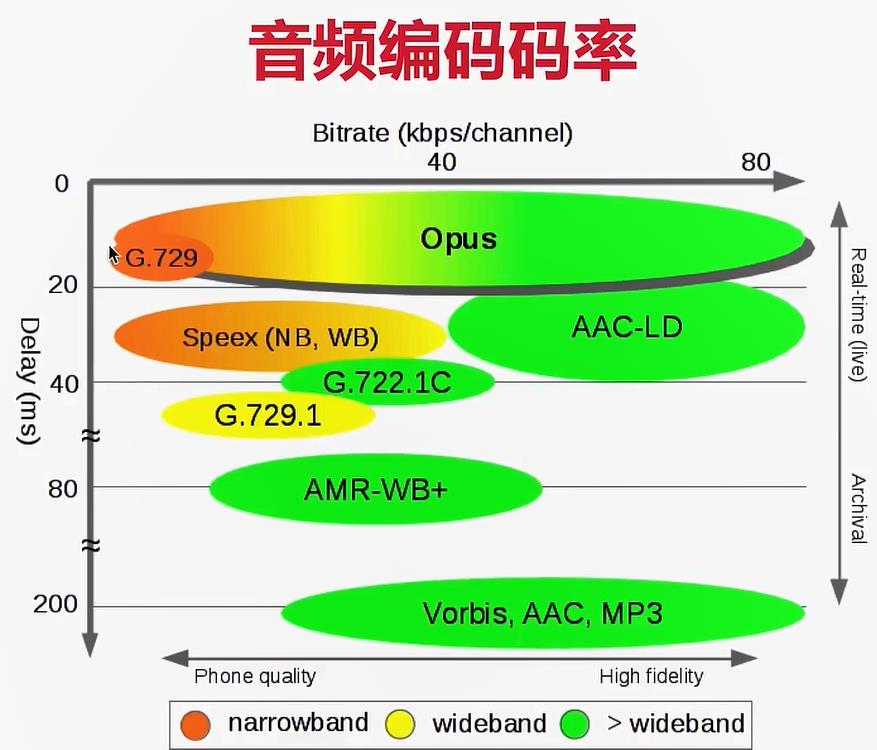
纵轴是延迟(0~200ms),横轴是码率。延迟越低,码率越小:
- Opus延迟较低,所以在20ms内,码率从0~20kb/s
- 而在码率较小时(0~20kb/s),AAC延迟则较大,在200ms附近,所以AAC不适用于实时性直播,适合于有一定延迟的直播。如果使用AAC于实时通信,那么可以选择AAC-LD低延迟类型
五:AAC编码
(一)AAC编码器介绍

MP3相对来说存储的压缩比较低,压缩后的文件还是比较大。而AAC压缩率高,压缩后文件较小,并且保真性能好,还原数据后,与原始数据相似性高。
AAC常用规格中:AAC HE V1使用较少,因为被V2取代。
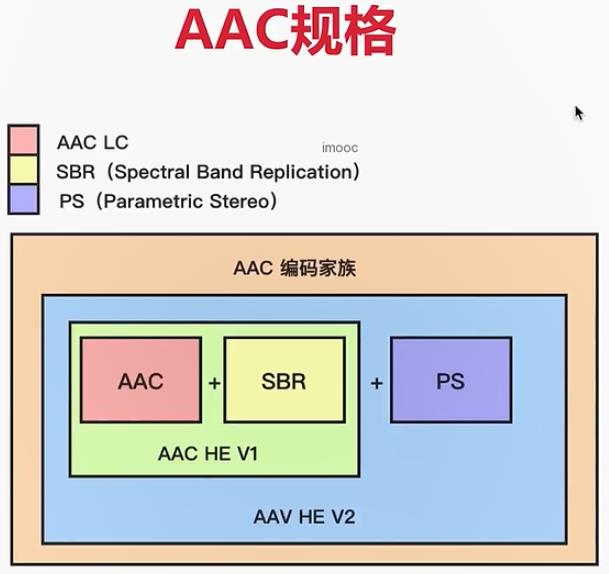
- AAC LC:码流越大(AAC LC,128k),存储信息量越大,音质越好,保真性高。码流越小,压缩比越高,去除的冗余信息多,会对重要的数据造成一定的损失。
- AAC HE:按频谱分别保存;低频(基频)保存主要成分,高频(谐频)和音色有很大关系,将高频单独放大去保证音质。实现进一步压缩。
- AAC HE V2:参数化,保存差异,进一步减少码流大小。

对于AAC格式:ADTS相对于ADIF而言,虽然每一帧前面都有header信息,但是却可以实现随时拖动播放,不必每次从头播放

补充:音频一帧数据计算—假设音频采样率 = 8000,采样通道 = 2,位深度 = 8,采样间隔 = 20ms
首先我们计算一秒钟总的数据量,采样间隔采用20ms的话,说明每秒钟需采集50次(1s=1000ms),那么总的数据量计算为
一秒钟总的数据量 =8000 * 2*8/8 = 16000(Byte)
\\qquad
所以每帧音频数据大小 = 16000/50 =320(Byte)
\\qquad
每个通道样本数 = 320/2 = 160(Byte)
(二)ADTS格式
ADTS头,适用性广,更加适用于流的传输,尤其对于直播系统
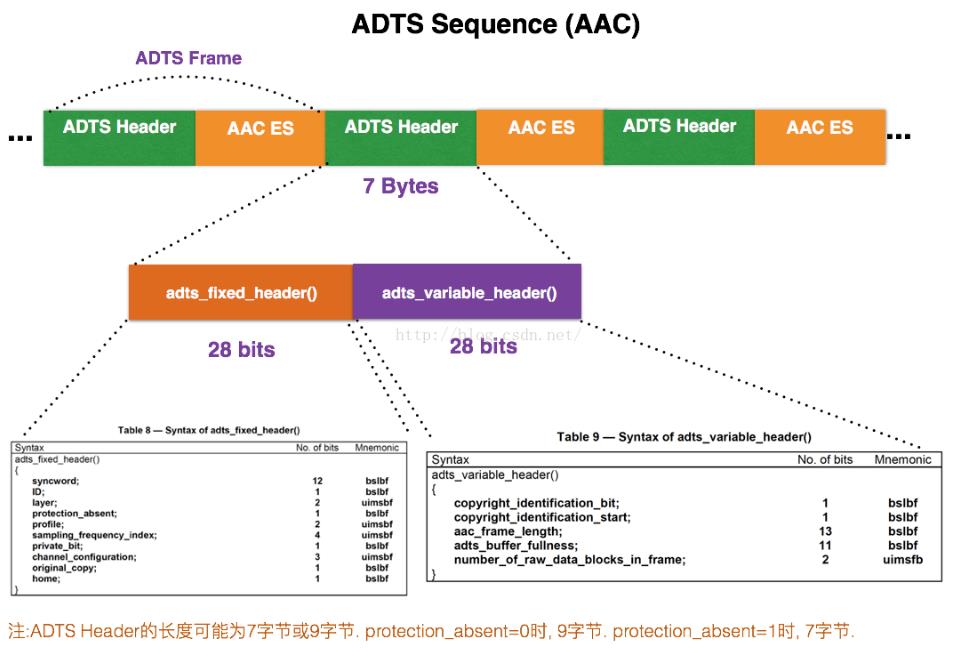
每一帧的ADTS的头文件都包含了音频的采样率,声道,帧长度等信息,这样解码器才能解析读取。
一般情况下ADTS的头信息都是7个字节,分为2部分:
adts_fixed_header();
adts_variable_header();
1.adts_fixed_header();

- syncword :总是0xFFF, 代表一个ADTS帧的开始, 用于同步。解码器可通过0xFFF确定每个ADTS的开始位置。因为它的存在,解码可以在这个流中任何位置开始, 即可以在任意帧解码。
- ID:MPEG Version: 0 for MPEG-4,1 for MPEG-2
- Layer:always: ‘00’
- protection_absent:Warning, set to 1 if there is no CRC and 0 if there is CRC #0表示需要CRC校验,1不需要
- profile:表示使用哪个级别的AAC,如01 Low Complexity(LC) – AAC LC; profile的值等于 Audio Object Type的值减1。 profile=(audio_object_type - 1)
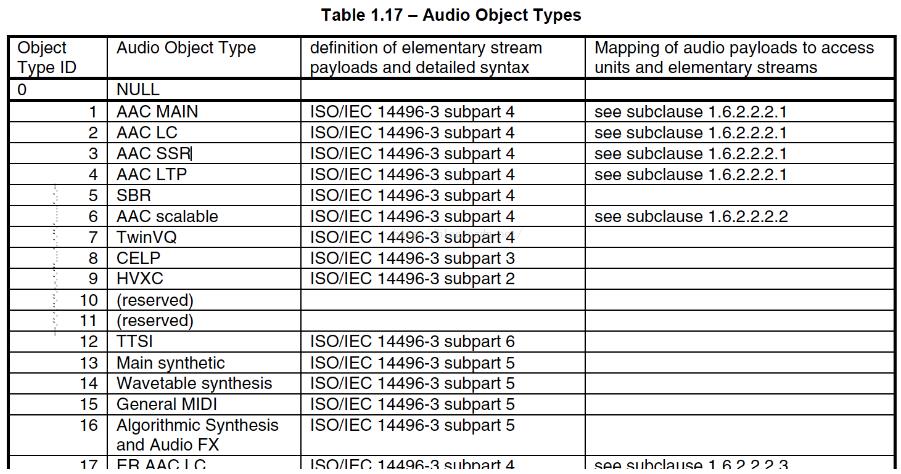
- sampling_frequency_index:采样率的下标
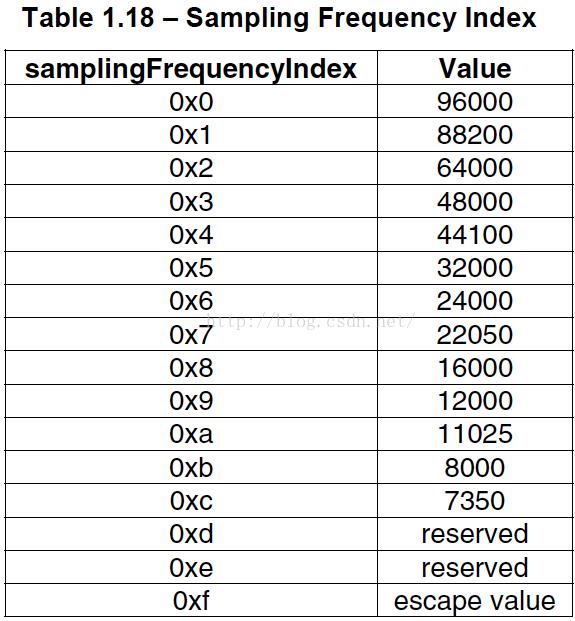
- channel_configuration:声道数,比如2表示立体声双声道
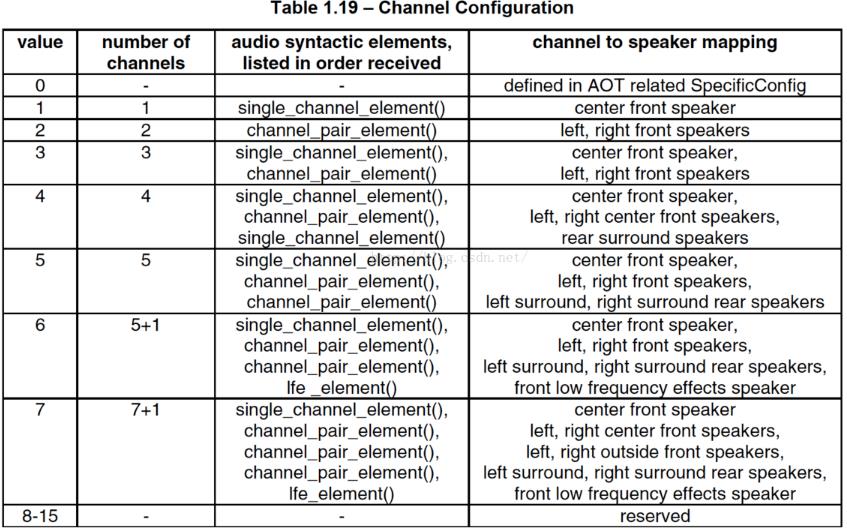
2.adts_variable_header();

- aac_frame_length:一个ADTS帧的长度包括ADTS头和AAC原始流。frame length, this value must include 7 or 9 bytes of header length:
- aac_frame_length = (protection_absent == 1 ? 7 : 9) + size(AACFrame)
- protection_absent=0时, header length=9bytes
- protection_absent=1时, header length=7bytes
- aac_frame_length = (protection_absent == 1 ? 7 : 9) + size(AACFrame)
- adts_buffer_fullness:0x7FF 说明是码率可变的码流。
- number_of_raw_data_blocks_in_frame:表示ADTS帧中有number_of_raw_data_blocks_in_frame + 1个AAC原始帧。
- number_of_raw_data_blocks_in_frame == 0 表示说ADTS帧中有一个AAC数据块。
- (一个AAC原始帧包含一段时间内1024个采样及相关数据)
3.代码实现头部的添加:https://www.cnblogs.com/ssyfj/p/14579909.html
void adts_header(char *szAdtsHeader, int dataLen)
int audio_object_type = 2; //通过av_dump_format显示音频信息或者ffplay获取多媒体文件的音频流编码acc(LC),对应表格中Object Type ID -- 2
int sampling_frequency_index = 4; //音频信息中采样率为44100 Hz 对应采样率索引0x4
int channel_config = 2; //音频信息中音频通道为双通道2
int adtsLen = dataLen + 7; //采用头长度为7字节,所以protection_absent=1 =0时为9字节,表示含有CRC校验码
szAdtsHeader[0] = 0xff; //syncword :总是0xFFF, 代表一个ADTS帧的开始, 用于同步. 高8bits
szAdtsHeader[1] = 0xf0