深度学习Group Convolution分组卷积Depthwise Convolution和Global Depthwise Convolution
Posted 超级无敌陈大佬的跟班
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度学习Group Convolution分组卷积Depthwise Convolution和Global Depthwise Convolution相关的知识,希望对你有一定的参考价值。
目录
2. 深度分离卷积(Depthwise Convolution)
原文链接:https://www.cnblogs.com/shine-lee/p/10243114.html
本文主要介绍减少参数量、计算量的卷积形式:
- Group Convolution(分组卷积)
- Depthwise Convolution(深度分离卷积)
- Global Depthwise Convolution()
1. 分组卷积(Group Convolution)
1.1 分组卷积与普通卷积的区别
Group convolution是将输入层的不同特征图进行分组,然后采用不同的卷积核再对各个组进行卷积,这样会降低卷积的计算量。因为一般的卷积都是在所有的输入特征图上做卷积,可以说是全通道卷积,这是一种通道密集连接方式(channel dense connection)。而group convolution相比则是一种通道稀疏连接方式(channel sparse connection)。
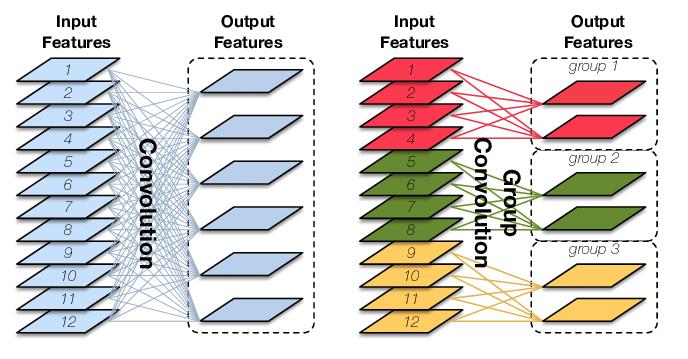
1)常规卷积(Convolution):
如果输入feature map尺寸为𝐶∗𝐻∗𝑊,卷积核有𝑁个,输出feature map与卷积核的数量相同也是𝑁,每个卷积核的尺寸为𝐶∗𝐾∗𝐾,𝑁个卷积核的总参数量为𝑁∗𝐶∗𝐾∗𝐾,输入map与输出map的连接方式如上图左所示。
2)分组卷积(Group Convolution)
Group Convolution是对输入feature map进行分组,然后每组分别卷积。假设输入feature map的尺寸仍为𝐶∗𝐻∗𝑊,输出feature map的数量为𝑁个,如果设定要分成𝐺个groups,则每组的输入feature map数量为𝐶 / 𝐺,每组的输出feature map数量为𝑁 / 𝐺,每个卷积核的尺寸为𝐶/𝐺∗𝐾∗𝐾,卷积核的总数仍为𝑁个,每组的卷积核数量为𝑁 / 𝐺,卷积核只与其同组的输入map进行卷积,卷积核的总参数量为𝑁∗𝐶 / 𝐺∗𝐾∗𝐾,可见,总参数量减少为原来的 1 / 𝐺,其连接方式如上图右所示,group1输出map数为2,有2个卷积核,每个卷积核的channel数为4,与group1的输入map的channel数相同,卷积核只与同组的输入map卷积,而不与其他组的输入map卷积。
1.2 分组卷积的用途
- 减少参数量,分成𝐺组,则该层的参数量减少为原来的1 / 𝐺
- Group Convolution可以看成是structured sparse,每个卷积核的尺寸由𝐶∗𝐾∗𝐾变为𝐶/𝐺∗𝐾∗𝐾,可以将其余(𝐶−𝐶 / 𝐺)∗𝐾∗𝐾的参数视为0,有时甚至可以在减少参数量的同时获得更好的效果(相当于正则)。
- 当分组数量等于输入map数量,输出map数量也等于输入map数量,即𝐺=𝑁=𝐶,𝑁个卷积核每个尺寸为1∗𝐾∗𝐾时,Group Convolution就成了Depthwise Convolution,参见MobileNet和Xception等,参数量进一步缩减。
1.3 分组卷积的注意点
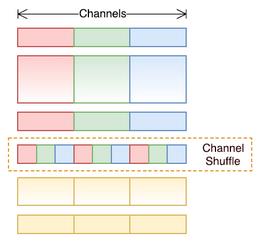
分组卷积使用后,最好将各组卷积的结果做一个shuffle打乱,让不同组卷积的特征能够通信。
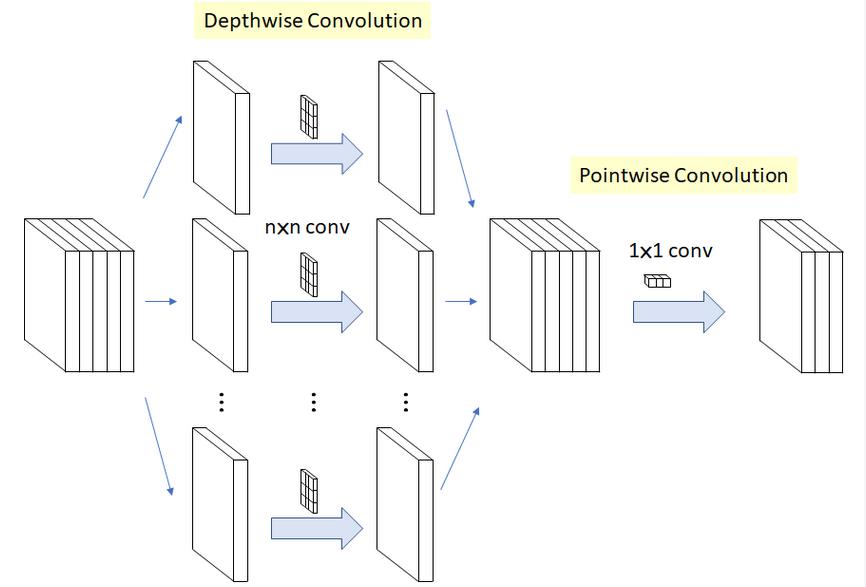
2. 深度分离卷积(Depthwise Convolution)
当分组数量等于输入map数量,输出map数量也等于输入map数量,即𝐺=𝑁=𝐶,𝑁个卷积核每个尺寸为1∗𝐾∗𝐾时,Group Convolution就成了Depthwise Convolution,参见MobileNet和Xception等,参数量进一步缩减,如下图所示:
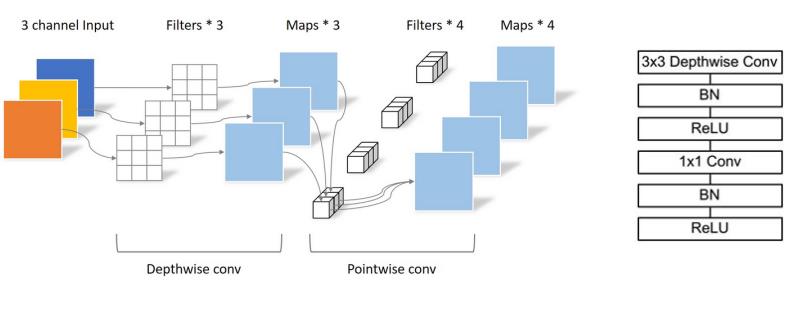
深度分离卷积在mobileNet中联合Pointwise conv一起使用:
3. Global Depthwise Convolution
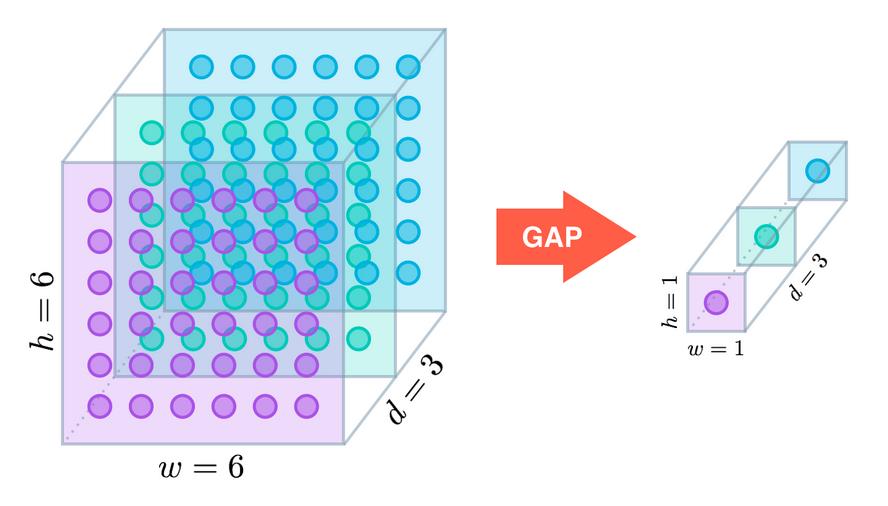
(ps:这个卷积没怎么用过)如果分组数𝐺=𝑁=𝐶,同时卷积核的尺寸与输入map的尺寸相同,即𝐾=𝐻=𝑊,则输出map为𝐶∗1∗1即长度为𝐶的向量,此时称之为Global Depthwise Convolution(GDC),见MobileFaceNet,可以看成是全局加权池化,与 Global Average Pooling(GAP) 的不同之处在于,GDC 给每个位置赋予了可学习的权重(对于已对齐的图像这很有效,比如人脸,中心位置和边界位置的权重自然应该不同),而GAP每个位置的权重相同,全局取个平均,如下图所示:
以上是关于深度学习Group Convolution分组卷积Depthwise Convolution和Global Depthwise Convolution的主要内容,如果未能解决你的问题,请参考以下文章