Python数据分析实战 —— 天猫订单数据分析
Posted zgrjddd
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python数据分析实战 —— 天猫订单数据分析相关的知识,希望对你有一定的参考价值。
文章目录
项目介绍
本项目将对2020年2月份的真实天猫订单成交数据(共28010条记录)进行数据清洗、数据可视化、数据分析,阐述销售现状、挖掘潜在规律、发现存在问题、提出可行性建议。
数据下载:https://tianchi.aliyun.com/competition/entrance/1/information
下面是这个项目的分析导图。

数据介绍
包含了天猫2020年2月份的共28010条订单数据,有以下7个字段:
订单编号:共28010条
总金额:该笔订单的总金额
买家实际支付金额:实际成交金额。分为已付款和未付款两种情况:
已付款:买家实际支付金额 = 总金额 - 退款金额
未付款:买家实际支付金额 = 0
收货地址:维度为省份,共包含31个省市
订单创建时间:2020年2月1日 至 2020年2月29日
订单付款时间:2020年2月1日 至 2020年3月1日
退款金额:付款后申请退款的金额。没有申请退款或没有付过款,退款金额为0
导入部分库
from plotly.offline import download_plotlyjs, init_notebook_mode
init_notebook_mode(connected=True)
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import plotly as py
import plotly.graph_objs as go
pyplot = py.offline.iplot
sns.set()
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
查看数据
data = pd.read_csv('/home/mw/input/tmall6650/tmall_order_report.csv')
data.head()
先了解数据的基本情况
data.info()

可以看到有有7个字段,'订单付款时间’的非空计数少于28010,两个时间的数据类型不合适分析需要修改。
数据预处理
数据格式整理
规范字段名
索引某些字段时提示KeyError,怀疑字段名称不规范。
修改前:
data.columns
Index(['订单编号', '总金额', '买家实际支付金额', '收货地址 ', '订单创建时间', '订单付款时间 ', '退款金额'], dtype='object')
发现收货地址和订单付款时间后面存在空格。删除这些空格,规范字段名称。
修改后:
data.rename(columns='收货地址 ': '收货地址', '订单付款时间 ':'订单付款时间', inplace=True)
data.columns
Index(['订单编号', '总金额', '买家实际支付金额', '收货地址', '订单创建时间', '订单付款时间', '退款金额'], dtype='object')
修改时间的数据类型
'订单创建时间’和’订单付款时间’的类型是object,将其改成日期格式,利用后期分析。
data['订单创建时间'] = pd.to_datetime(data['订单创建时间'])
data['订单付款时间'] = pd.to_datetime(data['订单付款时间'])
增加分析要使用的字段
data['创建时间'] = data['订单创建时间'].dt.strftime('%m月%d日')
data['付款时间'] = data['订单付款时间'].dt.strftime('%m月%d日')
data.head()
# 创建函数,用来将weekday返回的数字转化为对应星期几。
def to_weekday(a):
result = np.nan
if a == 0:
result = '周一'
elif a == 1:
result = '周二'
elif a == 2:
result = '周三'
elif a == 3:
result = '周四'
elif a == 4:
result = '周五'
elif a == 5:
result = '周六'
elif a == 6:
result = '周日'
return result
data['创建星期'] = data['订单创建时间'].dt.weekday.apply(to_weekday)
data['创建时刻'] = data['订单创建时间'].dt.hour
data['付款星期'] = data['订单付款时间'].dt.weekday.apply(to_weekday)
data['付款时刻'] = data['订单付款时间'].dt.hour
data.head()
简化地址
简化’收货地址’的省市名称,后续查看更方便。
简化前:
data['收货地址'].unique()
array(['上海', '内蒙古自治区', '安徽省', '湖南省', '江苏省', '浙江省', '天津', '北京', '四川省',
'贵州省', '辽宁省', '河南省', '广西壮族自治区', '广东省', '福建省', '海南省', '江西省', '甘肃省',
'河北省', '黑龙江省', '云南省', '重庆', '山西省', '吉林省', '山东省', '陕西省', '湖北省',
'青海省', '新疆维吾尔自治区', '宁夏回族自治区', '西藏自治区'], dtype=object)
简化后:
data['收货地址'] = data['收货地址'].str.replace('省','').str.replace('自治区','')
data['收货地址'] = data['收货地址'].str.replace('壮族','').str.replace('维吾尔','').str.replace('回族','')
data['收货地址'].unique()
array(['上海', '内蒙古', '安徽', '湖南', '江苏', '浙江', '天津', '北京', '四川', '贵州', '辽宁',
'河南', '广西', '广东', '福建', '海南', '江西', '甘肃', '河北', '黑龙江', '云南', '重庆',
'山西', '吉林', '山东', '陕西', '湖北', '青海', '新疆', '宁夏', '西藏'], dtype=object)
缺失值处理
'订单付款时间’存在缺失值,缺失数量为:3923。
sum(data['订单付款时间'].isnull())
3923
缺失比例为:14%。
sum(data['订单付款时间'].isnull()) / data.shape[0]
0.14005712245626561
# 检查数据
data[data['订单付款时间'].isnull() & data['买家实际支付金额']>0].size
0
检查得知’订单付款时间’为空的时候,实际付款金额都为0,没有出现错误数据。
实际生活中存在下单但是不付款的情况,缺失比例也没有超出预期,判断不需要对其进行处理。
异常值分析
data.describe()

从上表可以看到‘总金额’的最大值远远超过75%分位数,怀疑是异常值。
画个箱线图辅助判断
plt.boxplot(data['总金额'])
plt.show()
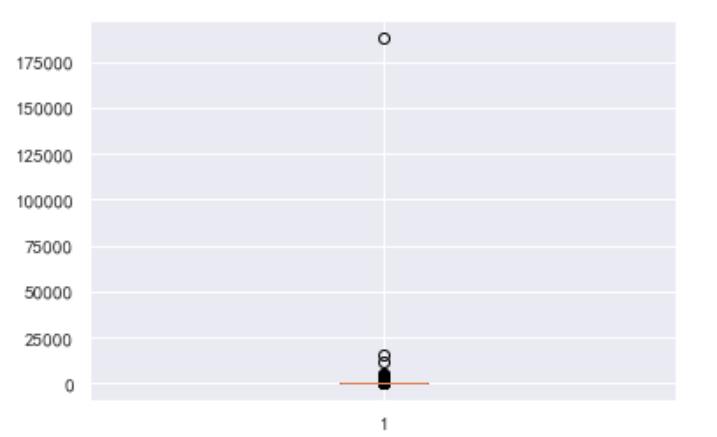
可以看到‘总金额’>175000的数据远离上极限,且25000到175000中间都是空白,判断总金额>175000的为异常值。
检查该异常情况的数量:
data[data['总金额'] > 175000]

‘总金额’大于175000的数据只有一条,并且没有付款,很有可能是乱点的,将其删除。
data = data.drop(index=data[data['总金额'] > 17500].index)
data.shape
(28009, 13)
'买家实际支付金额’异常值处理
plt.boxplot(data['买家实际支付金额'])
plt.show()

查看实际支付金额大于6000的数据:
data[data['买家实际支付金额'] > 6000]

付款金额不是十分高,而且数量只有2,符合实际,不处理。
退款金额’异常值处理
plt.boxplot(data['退款金额'])
plt.show()
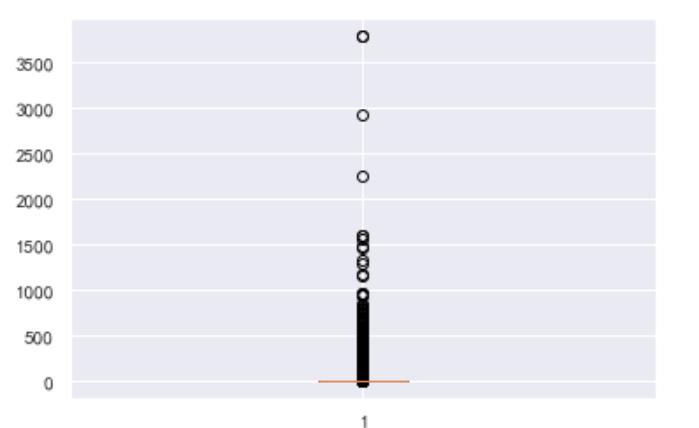
查看退款金额大于2000的数据:
data[data['退款金额'] > 2000]

退款金额=总金额,没有出现数据错误,而且数量少,符合生活中的实际情况,不处理。
重复值处理
np.sum(data.duplicated())
0
没有重复值。
数据分析
描述性统计
'订单付款时间’为空的代表买家没有付款,对应的’买家实际支付金额’为0的在描述性统计时应当成空值而不是0;
‘退款金额’为0代表没有退款,在进行描述性统计时也应当成空值处理。
data_desc = data.copy()
data_desc['买家实际支付金额'] = np.where(data_desc['订单付款时间'].isnull(), np.nan, data_desc['买家实际支付金额'])
data_desc['退款金额'] = data_desc['退款金额'].replace(0, np.nan)
data_desc.describe()
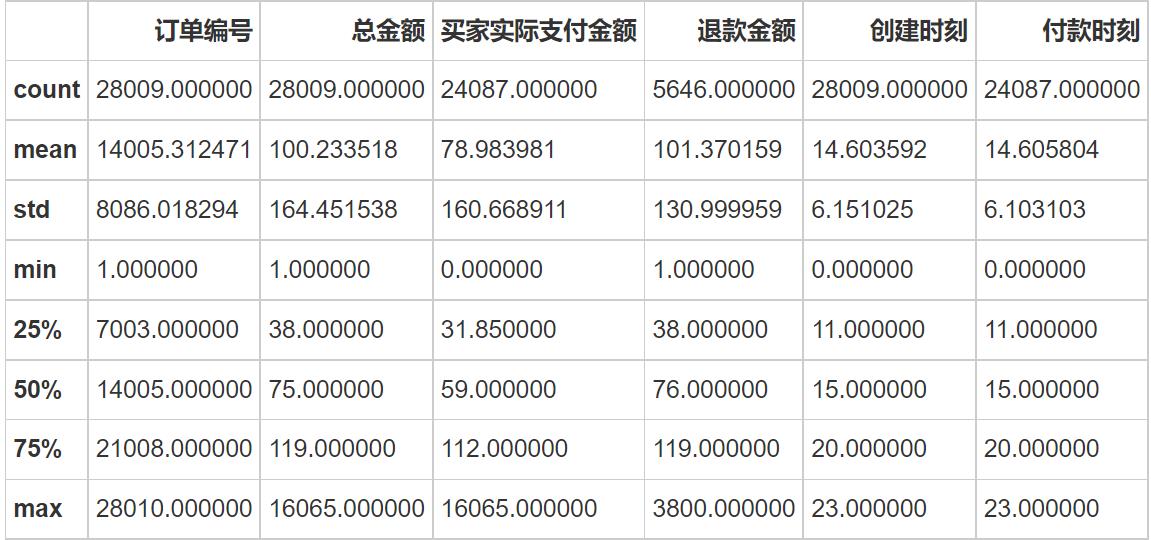
初步了解一下数据:
订单情况
共记录28009条订单,其中买家实际支付订单24087条(86.0%),买家有退款行为的订单5646条(占实际支付23.4%);
订单总金额
平均每单订单100.2元,金额最小1元,金额最大16065元;
实际支付金额
实际支付订单平均每单79.0元,金额最小0元,金额最大16065元;
退款金额
退款订单平均每单退款101.4元,金额最小1元,金额最大3800元。
总体销售情况
np.sum(data['买家实际支付金额'])
1902487.15
二月份的总销售额是190.25万
GMV_day = data[data['付款时间'] != 'NaT'].groupby('付款时间').sum()
order_day = data[data['付款时间'] != 'NaT'].groupby('付款时间').count()
trace1 = go.Scatter(x=GMV_day.index,
y=GMV_day['买家实际支付金额'],
mode='lines',
marker=dict(color='orange'),
name='销售额'
)
trace2 = go.Bar(x=order_day.index,
y=order_day['订单编号'],
name='订单数',
opacity=0.7,
marker=dict(color='steelblue'),
yaxis='y2'
)
layout = go.Layout(title='2020年2月销售额走势',
xaxis=dict(tickangle=45, dtick=1),
yaxis=dict(title='销售额(元)',zeroline=False),
yaxis_tickformat='auto',
yaxis2=dict(title='订单数', overlaying='y', side='right', showgrid=False),
annotations=[dict(x=0.1, xref='paper', y=0.95, yref='paper', text='二月份总销售额为190.25万',bgcolor='gainsboro',font='size':13, showarrow=False)],
legend=dict(x=0.1,y=0.85))
trace = [trace1, trace2]
fig = go.Figure(trace, layout)
pyplot(fig)
从上图我们可以得知以下信息:

二月份总销售额为190.25万;
2月16日以前销售额很少,仅在2月4日和2月9日达到两个小高峰,这两日的销售额为22000左右;
2月10日至2月16日销售额仅有0~1000;
2月17日开始销量持续增长,在2月25达到本月最高销售额(22.8万);
3月1日的销售额突然变低,销售额只有298。
问题分析:
2月初销量低可能是因为春节假期,查阅可知,2020年的春节假期为1月24日至2月2日,但是当时正是疫情开始,复工复产时间推迟至不早于2月9日24时,2月10日-2月16日正好是销售最低迷的时间,应该是因为消费者正开始复工复产,无暇消费。
3月1日销售额突降是因为该日订单只记录了在2月29日创建但在3月1日支付的,并不是3月1日的所有交易数据,在这里我们可以忽略3月1日。
建议:
2020年初疫情突发,导致本应在2月初春节结束恢复的销售,推迟至月中,甚至出现了日销量为0的情况。目前疫情已经常态化,应该准备多个应急方案,保证在突发事件发生时能及时举措,减少突发状况对销售的影响,如果竞争对手没有及时反应我司甚至能拔得头筹获得佳绩。
接下来分析,我们可以针对哪些方面作出改进,增加销售。
周趋势、日趋势分析
上面我们分析了月度销售情况,接下来看看每周和每天的销售情况
week_order = ['周一', '周二', '周三', '周四', '周五', '周六', '周日']
data_week_mean = [data.groupby('付款星期').sum()['买家实际支付金额'].loc[i] for i in week_order]
data_week_count = [data.groupby('付款星期').count()['订单编号'].loc[i] for i in week_order]
# 每个月有多少个周一、多少个周二是不固定的,如果单纯按周几分组求和,数量多的周x会占优。需要再求个平均。
data_week_mean = np.divide(data_week_mean, [4,4,4,4,4,5,4]) # 当月有4个周一4个周二...
data_week_count = np.divide(data_week_count, [4,4,4,4,4,5,4])
data_hour_mean = data.groupby('付款时刻').sum()
data_hour_count = data.groupby('付款时刻').count()
# 绘制周销售趋势图
trace_week1 = go.Scatter(x=week_order,
y=data_week_mean,
name='平均销售额',
marker=dict(color='orange')
)
trace_week2 = go.Bar(x=week_order,
y=data_week_count,
name='订单数',
opacity=0.7,
marker=dict(color='steelblue'),
yaxis='y2'
)
trace_week = [trace_week1, trace_week2]
layout1 = go.Layout(title='周销售趋势分析',
yaxis=dict(title='销售额(元)'),
yaxis2=dict(title='订单数', overlaying='y', side='right', showgrid=False),
legend=dict(x=0.9,y=1.4),
width=550, height=350)
fig1 = go.Figure(trace_week, layout1)
pyplot(fig1)
# 绘制日销售趋势图
trace_hour1 = go.Scatter(x=data_hour_mean.index,
y=data_hour_mean['买家实际支付金额'],
marker=dict(color='orange'),
name='平均销售额',
)
trace_hour2 = go.Bar(x=data_hour_count.index,
y=data_hour_count['订单编号'],
opacity=0.7,
marker=dict(color='steelblue'),
name='订单数',
yaxis='y2'
)
trace_hour = [trace_hour1, trace_hour2]
layout2 = go.Layout(title='日销售趋势分析',
xaxis=dict(title='时刻', dtick=1, tickangle=0),
yaxis=dict(title='销售额(元)'),
yaxis2=dict(title='订单数', overlaying='y', side='right', showgrid=False),
legend=dict(x=0.9,y=1.4),
width=550, height=350)
fig2 = go.Figure(trace_hour, layout2)
pyplot(fig2)
从上图我们可以得到以下信息:
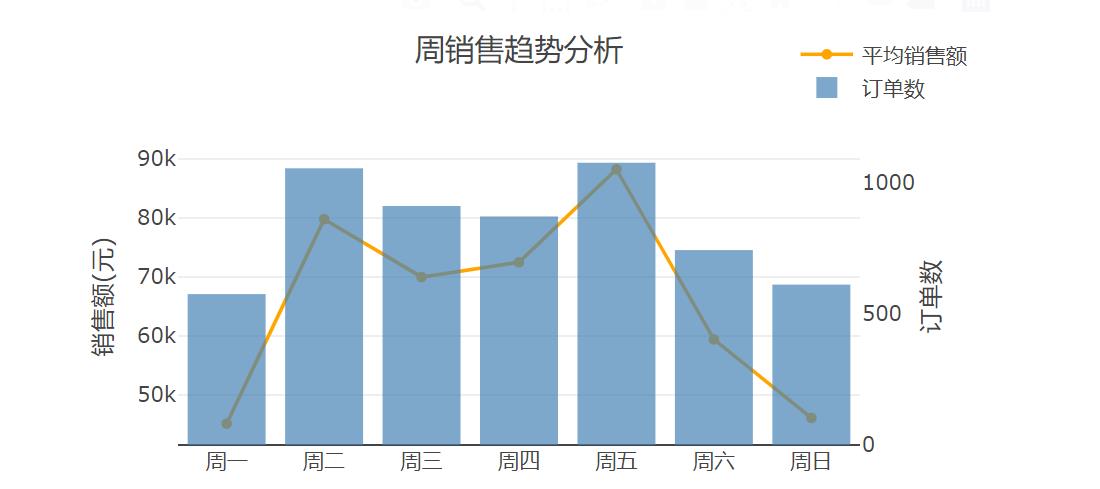
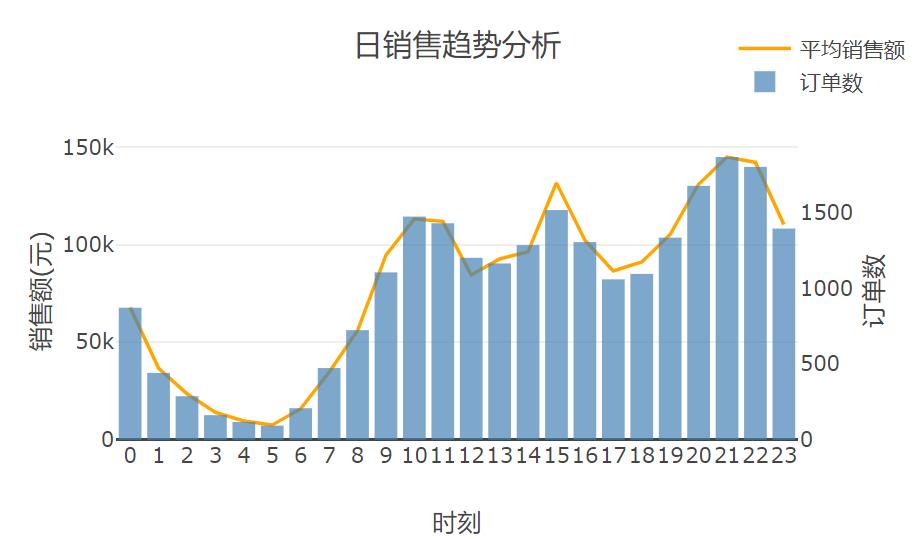
每周销售最好的时候是周五,其次是周二,最差的是周一;
周末并不是预想中销售最好的时间,甚至比大部分工作日差;
凌晨销售量低,从6点开始销量稳定提升,中午开始趋于稳定略有波动,在10时、15时、21时分别有一个高峰,22点以后销量开始下降;
销量最高的时间是晚上21点。
建议:
促销活动可以安排在周五开始,既可以提高原本的高销量,又可以拉动周末的消费;
促销信息、产品推广广告的推送时间最好安排在晚上9点,此时消费人数最多,信息的曝光量最大,能带来最大收益;
如果有条件多次推送信息,10点、15点、21点是较好的选择。
产品价格分析
因为数据集中即没有包含产品名称,也没有包含产品价格,我们姑且将订单总金额当成产品的价格,分析什么价格的产品更受消费者欢迎。
sns.histplot(data['总金额'])
plt.show()

总金额500以上的数据虽然很少但刻度很大,包含进来严重拉伸了图形,不利于分析。
筛选总金额500以内的数据,绘制直
以上是关于Python数据分析实战 —— 天猫订单数据分析的主要内容,如果未能解决你的问题,请参考以下文章