经典卷积神经网络介绍
Posted NodYoung
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了经典卷积神经网络介绍相关的知识,希望对你有一定的参考价值。
AlexNet
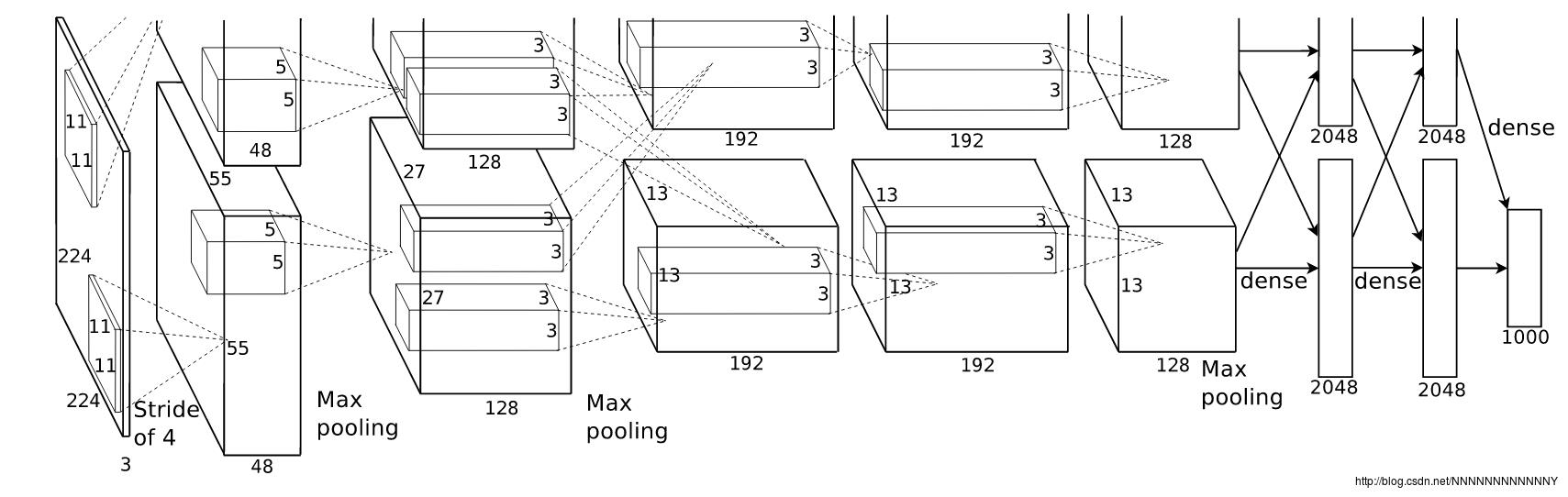
2012年,Hinton的学生Alex Krizhevsky提出了深度卷积神经网络模型AlexNet,获得当年ILSVRC(Image Large Scale Visual Recognition Challenge)比赛分类项目的冠军。
AlexNet主要使用到的新技术如下:
a) 成功使用ReLU作为CNN的激活函数,并验证了其在较深网络中的有效性,解决了Sigmod在网络较深时的梯度弥散问题。
b) 训练时在最后几个全连接层使用Dropout随机忽略一部分神经元以避免模型过拟合,
c) 使用重叠的最大池化。AlexNet全部使用最大池化,避免平均池化的模糊效果;并提出让步长比池化核的尺寸小,这样池化层的输出之间会有重叠覆盖,特升了特征的丰富性。
d) 提出LRN(Local Response Normalization,局部响应归一化)层,如今已很少使用。
e) 使用CUDA加速深度卷积神经网络的训练。当初用的还是两块GRX 580 GPU,发展的好快呀。
f) 数据增强,随机从256*256的原始图像中截取224*224大小的区域作为网络输入。
整个AlexNet有5个卷积层和3个全连接层。
其参数图如下:
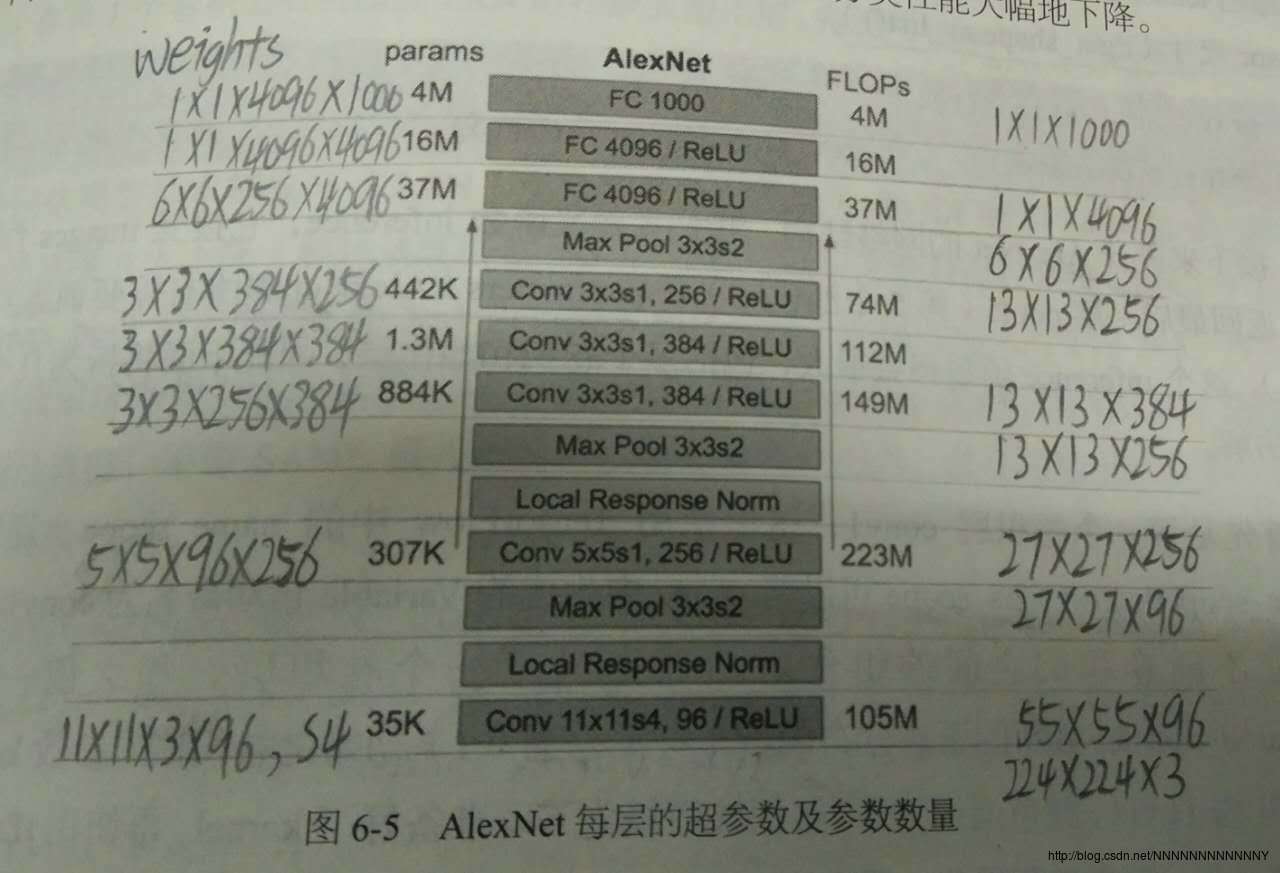
关于计算params和FLOPs的方法,参看Deep Learning for Computer Vision: Memory usage and computational considerations
使用tensorflow实现AlexNet
参考网址:https://github.com/tensorflow/models/tree/master/tutorials/image/alexnet
VGGNet
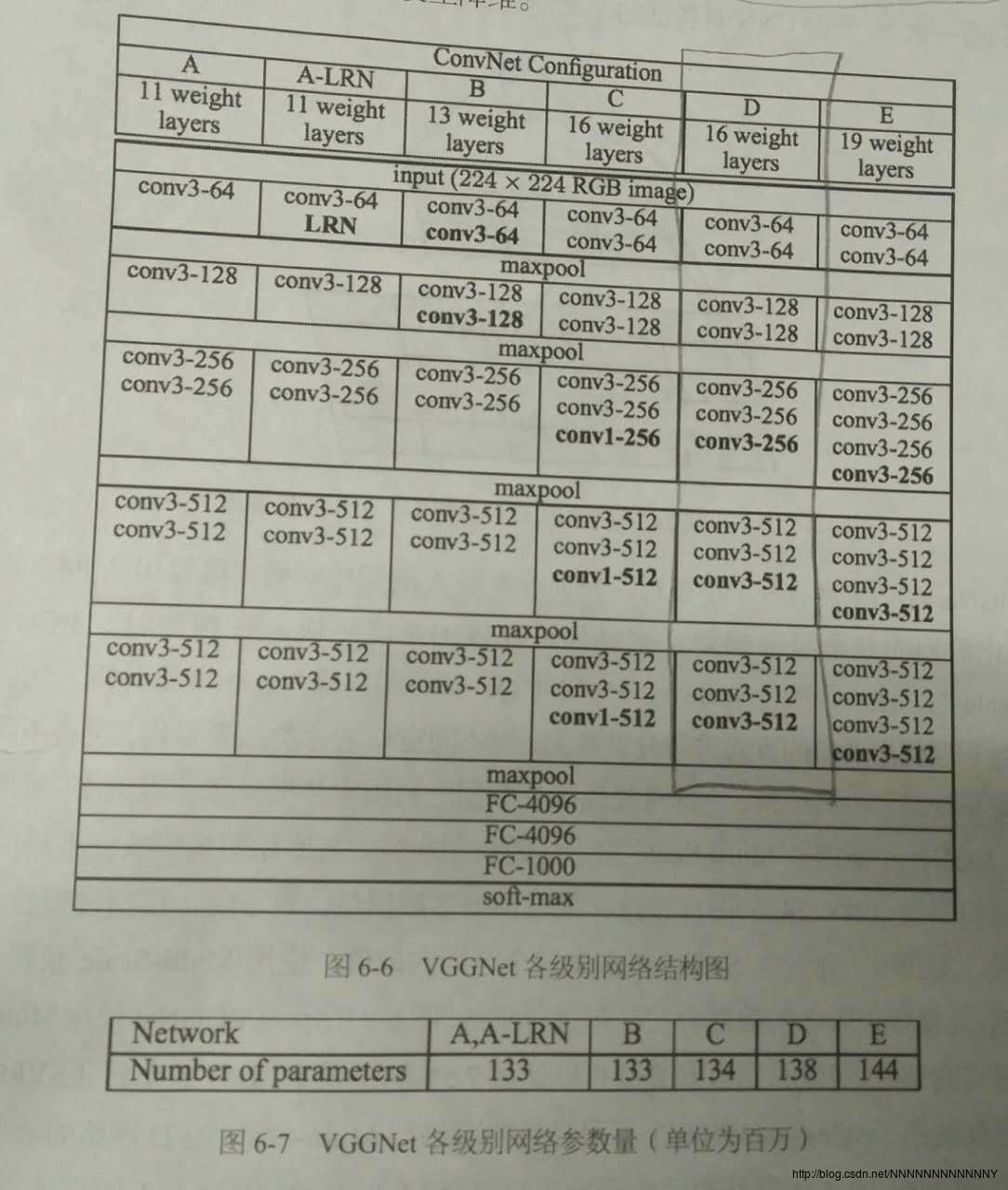
VGGNet结构非常简洁,其特点如下:
a) 通过反复堆叠3*3的小型卷积核和2*2的最大池化层构建。
b) VGGNet拥有5段卷积,每一段卷积网络都会将图像的边长缩小一半,但将卷积通道数翻倍:64 —>128 —>256 —>512 —>512 。这样图像的面积缩小到1/4,输出通道数变为2倍,输出tensor的总尺寸每次缩小一半。
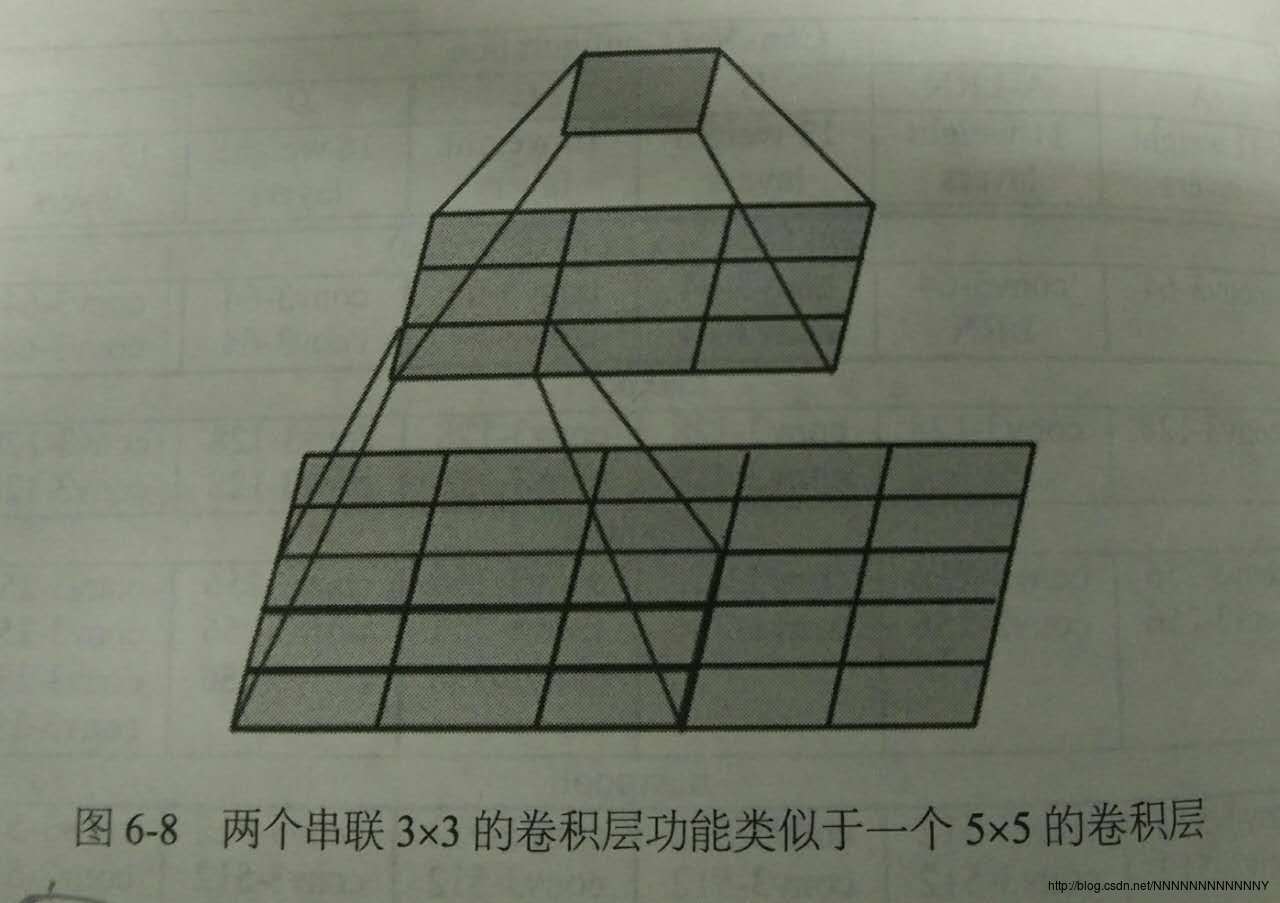
c) 经常多个完全一样的3*3的卷积层堆叠在一起。这其实是非常有用的设计:3个3*3的卷积层串联相当于1个7*7的卷积层,即一个像素会跟周围7*7的像素产生关联,可以说感受野大小是7*7。而且前者拥有比后者更少的参数量,
3×3×37×7=55%
。更重要的是,3个3*3的卷积层拥有比1个7*7的卷积层更多的线性变换(前者可以使用三次ReLU激活函数),使得CNN对特征的学习能力更强。
d) 训练时有个小技巧:先训练级别A的简单网络,再复用A网络的权重初始化后几个复杂模型,这样训练收敛的速度更快。
使用tensorflow实现VGGNet
参考网址:https://github.com/machrisaa/tensorflow-vgg
Google Inception Net
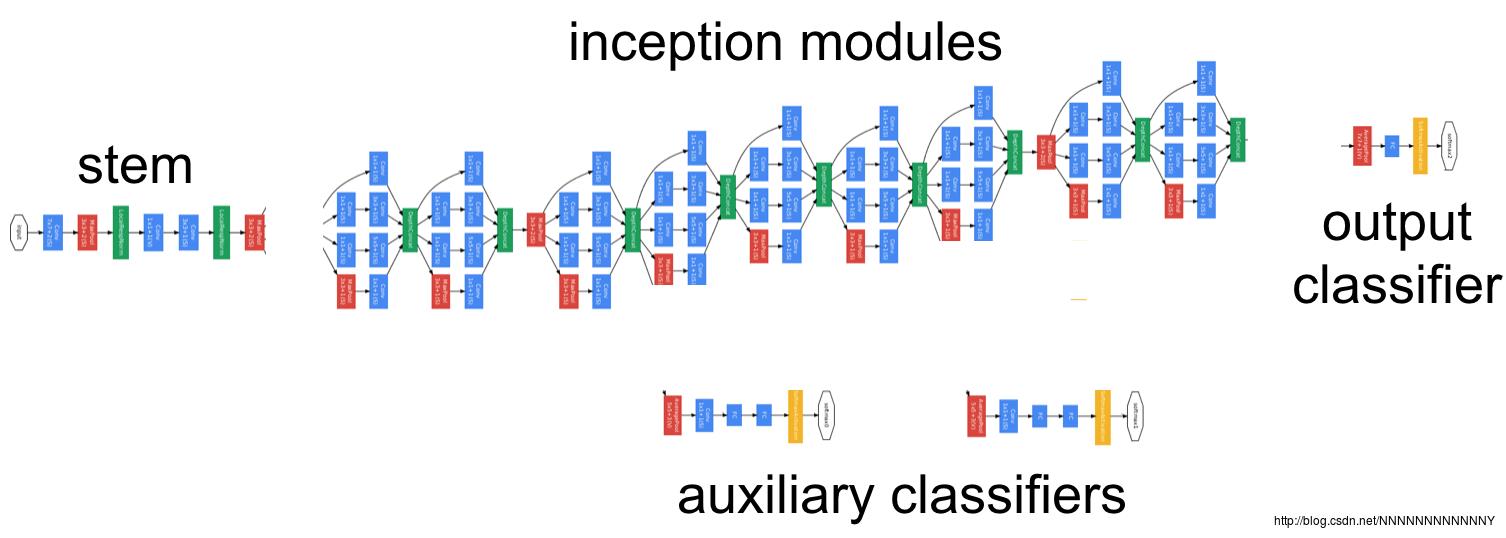
具有如下特点:
a) 在控制了计算量和参数量的同时,获得了非常好的分类性能。Inception V1有22层深,但其计算量只有15亿次浮点运算,同时只有500万的参数量,即为AlexNet参数量(6000万)的1/12。为什么要降低参数量?第一,参数越多模型越庞大,(同样深度下)需要供模型学习的数据量就越大,而目前高质量的数据又很贵;第二,参数越多,耗费的计算资源也越大。Inception V1参数少但效果好的原因之一就在于其模型参数更深、表达能力更强。
b) 去除了最后的全连接层,使用1*1的卷积层来替代,这样是模型训练更快并减轻了过拟合。关于这方面可参见:为什么使用卷积层替代CNN末尾的全连接层
c) 精心设计的Inception Module(Network In Network的思想)有选择地保留不同层次的高阶特征,最大程度地丰富网络的表达能力。一般来说卷积层要提升表达能力,主要依靠增加输出通道数(副作用是计算量大和过拟合)。因为每一个输出通道对应一个滤波器,同一个滤波器共享参数只能提取一类特征,因此一个输出通道只能做一种特征处理。Inception Module一般情况下有4个分支:第一个分支为1*1卷积(性价比很高,低成本(计算量小)的跨通道特征变换,同时可以对输出通道升维和降维),第二个分支为1个1*1卷积再接分解后(factorized)的1*n和n*1卷积 (Factorization into small convolutions的思想),第三个分支和第二个类似但一般更深一些,第四个分支为最大池化(增加了网络对不同尺度的适应性,Multi-Scale的思想)。因此Inception Module通过比较简单的特征抽象(分支1)、比较复杂的特征抽象(分支2和分支3)和一个简化结构的池化层(分支4)有选择地保留不同层次的高阶特征,这样可以最大程度地丰富网络的表达能力。
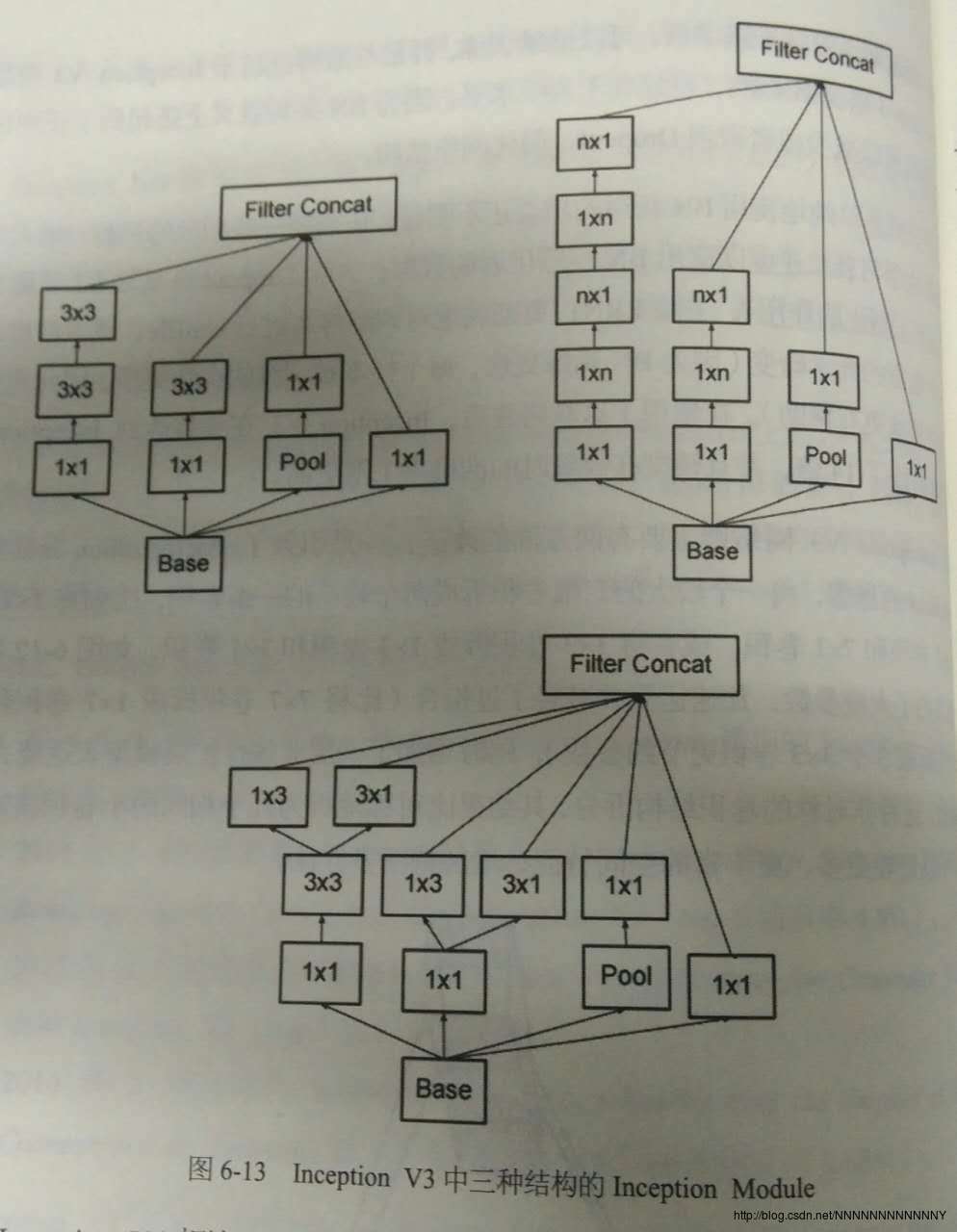

d) Inception V2提出了著名的Batch Normalization方法。BN用于神经网络某层时,会对每一个mini-batch数据内部进行标准化(normalization)处理,是输出规范化到N(0, 1)的正态分布,减少了Internal Covariate shift。关于这方面可参见: 为什么会出现Batch Normalization层
e) Inception V3引入了Factorization into small convolutions的思想,将一个较大的二维卷积拆成两个较小的一维卷积。比如,将7*7卷积拆成1*7和7*1两个卷积。这样做节约了大量参数,加速运算并减轻了过拟合(比将7*7卷积拆成3个3*3卷积更节约参数);并且论文指出这种非对称的卷积结构拆分比对称地拆分为几个相同的小卷积核效果更明显,可以处理更多、更丰富的空间特征,增加特征多样性。
使用tensorflow实现inception_v3
参考网址:https://github.com/tensorflow/models/blob/master/slim/nets/inception_v3.py
ResNet
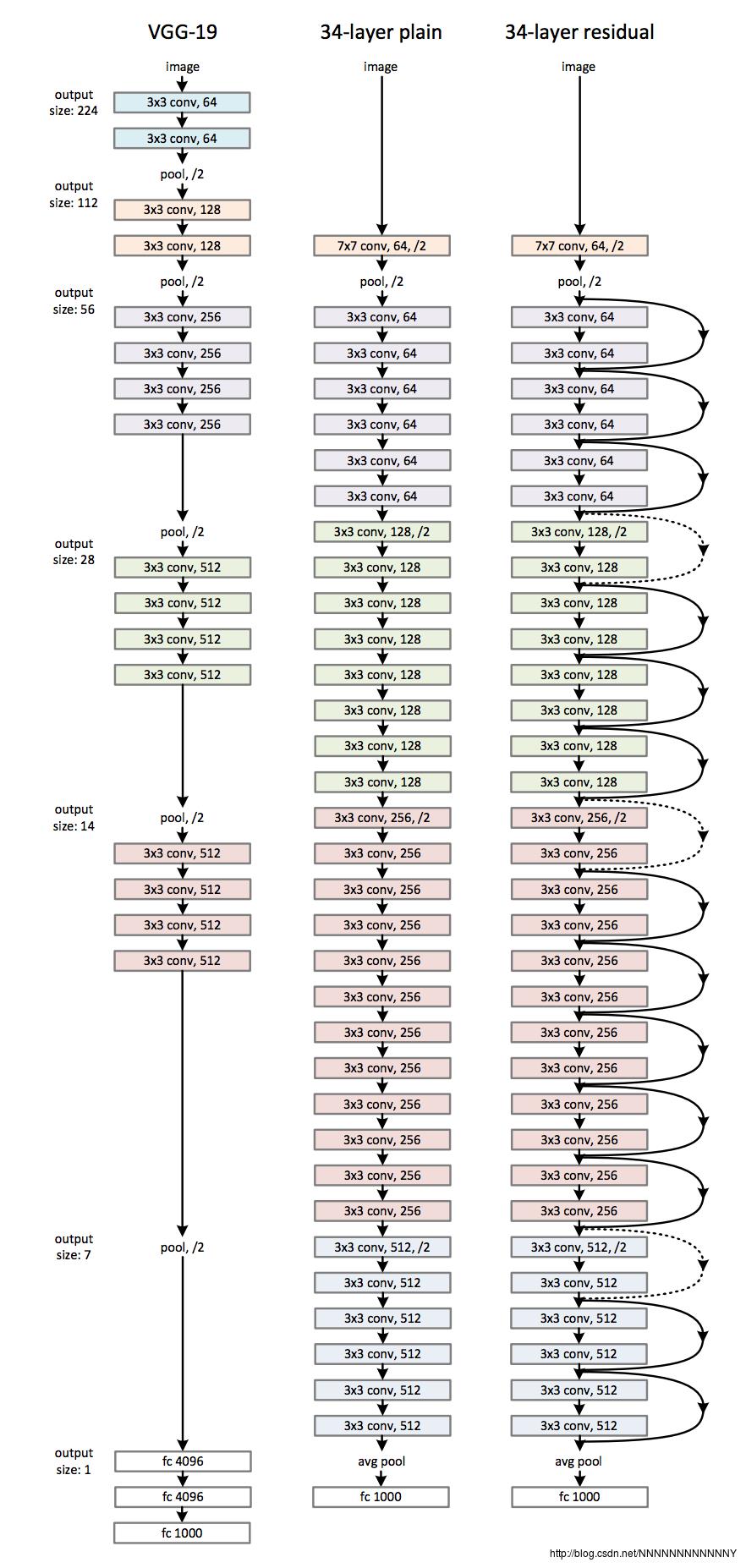
这是一种新的网络思想,说一下我自己的理解。
为什么会出现Residual Learning
人们观察到一个典型现象:当网络一直加深时,准确率会趋于峰值,然后再加深网络准确率反而会下降(在训练集和测试集上均是如此,这显然就不是过拟合了)。ResNet作者把这种现象称为degradation problem。
然后大家开始想,前向传播过程中信息量越来越少是不错,但也不至于逼近效果越来越差呀。聪明的小伙子(严肃来讲应该是大神)He提出:把新增加的层变为恒等映射(identity mappings),这样至少效果不会越来越差吧。既然网络能拟合函数H(x),是不是也能同样拟合H(x)-x。说干就干,实验是检验真理的唯一标准。于是得出结论“拟合H(x)-x比直接拟合H(x)更简单”(当然理论上他也有一套自己的解释:如果我们想要得到的最优结果是x,拟合前者显然更简单,权重直接为0即可;虽然现实中我们想要的并非x,但我们想要的更应该接近x而非接近0吧)。哈哈,深度残差网络就这样诞生了。
ResNet单元模块
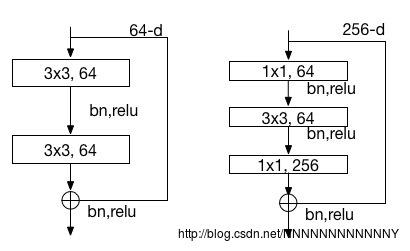
如上图所示为两种类型的block,block定义如下:
对于block里只有两个卷积的情况,
F=W2σ(W1x)
上述公式里两者相加存在一个问题:
1. 各个维度相同,直接相加即可
2. 维度不同(在第一张图网络的虚线处,feature map尺寸大小和通道数均发生变化),论文中说给x加个 Ws 的映射。我的理解是对x加个池化(stride=2)即可满足尺寸变化,然后再利用
1*1小卷积升维即可。
ResNet网络特点
a) 网络较瘦,控制了参数数量;
b) 存在明显层级,特征图个数逐层递进,保证输出特征表达能力;
c) 没有使用Dropout,利用BN和全局平均池化进行正则化,加快了训练速度;
d) 层数较高时减少了3x3卷积个数,并用1x1卷积控制了3x3卷积的输入输出特征图数量,称这种结构为“瓶颈”(bottleneck)。
参考:https://zhuanlan.zhihu.com/p/22447440
使用tensorflow实现Resnet_v2
参考网址:https://github.com/tensorflow/models/blob/master/slim/nets/resnet_v2.py
参考:
1.以上相关模型的论文,这里就不贴了
2.书籍《Tensorflow实战》
以上是关于经典卷积神经网络介绍的主要内容,如果未能解决你的问题,请参考以下文章