HUE配置Spark Notebook
Posted asin929
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HUE配置Spark Notebook相关的知识,希望对你有一定的参考价值。
在HUE3.10版中已经具有spark notebook的功能,但需要自己配置。
安装步骤
主要参照run-hue-spark-notebook-on-cloudera进行。
注意点
在第四步,
#download Livy
wget http://archive.cloudera.com/beta/livy/livy-server-0.2.0.zip
unzip livy-server-0.2.0.zip -d /<your_livy_dir>
#set environment variables for Livy
export SPARK_HOME=/opt/cloudera/parcels/CDH/lib/spark
export JAVA_HOME=/usr/java/jdk1.7.0_67-cloudera
export HADOOP_CONF_DIR=<your hadoop_conf_dir found in the previous step in Hue configuration>
export HUE_SECRET_KEY=<your Hue superuser password, this is usually the user you use when you log in to Hue Web UI the first time>
#run Livy. You must run Livy as a user who has access to hdfs, for example, the superuser hdfs.
su hdfs
/<your_livy_dir>/livy-server-0.2.0/bin/livy-server注意:HADOOP_CONF_DIR可能随着CDH的重启而改变,所以每次需要重新设置。也可以直接设置成固定的/etc/hadoop/conf,见CDH中服务的配置及启动 。
测试
val data = Array(1, 2, 3, 4 ,5)
val distData = sc.parallelize(data)
distData.map(s=>s+1).collect()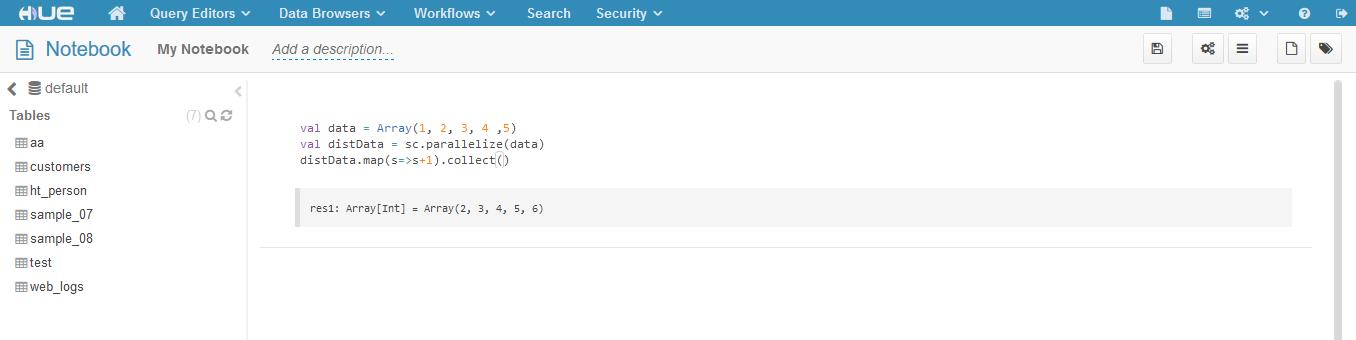
以上是关于HUE配置Spark Notebook的主要内容,如果未能解决你的问题,请参考以下文章