CUDA 学习CUDA 内存
Posted tiemaxiaosu
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了CUDA 学习CUDA 内存相关的知识,希望对你有一定的参考价值。
一、CPU内存
在传统的CPU模型中,内存是线性内存或平面内存,单个CPU核可以无约束地访问任何地址内存。在内存处理中有两个重要的概念,一个是存储带宽,即在一定时间内从DRAM 读出或写入的数据量。另一个是延迟,即响应一个获取内存的请求所花费的时间,通常这个时间会是上百个处理器周期。
二、高速缓存
高速缓存是硬件上非常接近处理器核的高速存储器组。高速缓存的最大速度与缓存的大小成反比关系。一级缓存是最快的,但它的大小一般限制在16KB、32KB、64KB。通常每次CPU核会分配一个单独的一级缓存。二级缓存相对而言慢一些,但是它更大,通常有256KB-512KB。三级缓存可能存在也可能不存在,如果存在,通常是几兆字节大小。二级缓存或三级缓存一般在处理器的核之间是共享的,或者作为连接于特定处理器的独立缓存来维护。在传统CPU上,一般而言,至少三级缓存在处理器核之间是共享的。处理器核便可通过设备上这块共享内存快速地进行通信。
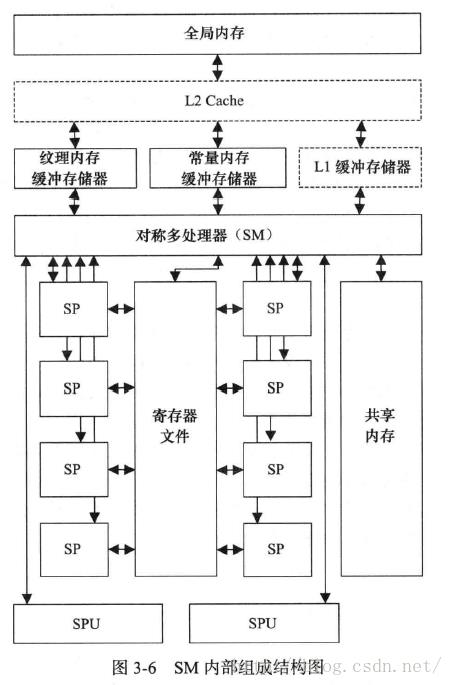
G80与GT2000系列GPU没有与CPU中高速缓存等价的存储器,但它们却是有两块基于硬件托管的缓存,即常理内存与纹理内存,它们类似CPU中的只读缓存。与CPU不同,GPU主要依赖基于程序员托管的缓存或共享内存区。
费米架构的GPU实现中,不采用基于程序员托管的数据缓存。而是,GPU中每个SM有一个一级缓存,这个一级缓存既是基于程序员托管的又是基于硬件托管的。在所有的SM之间有一个共享的二级缓存。如图6-1

三、数据存储类型
GPU提供不同层次若干区域供程序员存放数据,每块区域根据其能达到的最大带宽以及延迟而定义,如下表:

最快速也是最受偏爱的寄存器是设备中的寄存器,接着是共享内存,如基于程序员托管的一级缓存,然后是常理内存,纹理内存,常规设备内存,最后则是主机端内存。主要不同存储之间的存储速度的数量级的变化规律。
备注:
纹理内存:是针对全局内存的一个特殊视图,用来存储插值计算所需的数据,例如,显示2D或3D图像时需要的查找表。它拥有基于硬件进行插值的特性。
常理内存:用于存储那些只读的数据,所有的GPU卡均对其进行缓存。与纹理内存一样,常理内存也是全局内存建立的一个视图。

以上是关于CUDA 学习CUDA 内存的主要内容,如果未能解决你的问题,请参考以下文章