Spark调研笔记第2篇 - 如何通过Spark客户端向Spark提交任务
Posted slvher
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark调研笔记第2篇 - 如何通过Spark客户端向Spark提交任务相关的知识,希望对你有一定的参考价值。
在上篇笔记的基础上,本文介绍Spark客户端的基本配置及Spark任务提交方式。
1. Spark客户端及基本配置
从Spark官网下载的pre-built包中集成了Spark客户端,如与hadoop ver1.x兼容的Spark客户端位于spark-1.3.1-bin-hadoop1/bin目录下。
Spark客户端通常部署在要提交计算任务的机器上,用来向集群提交应用。特别地,客户端自带的bin/pyspark脚本支持以交互模式向集群提交应用,在交互模式下测试spark python api的执行结果是很方便的。
Spark客户端的配置文件通常位于conf目录下,典型的配置文件列表如下所列:
spark-defaults.conf // 设置spark master地址、每个executor进程的内存、占用核数,等等
spark-env.sh // spark相关的各种环境变量
log4j.properties.template // 设置driver向console输出的日志的等级及格式
fairscheduler.xml.template // 设置调度方式
metrics.properties.template // 设置spark内部metrics系统,一般无需改动
slaves // 设置spark集群中的slave节点(即worker节点),无需改动
hadoop-default.xml // hadoop配置,主要是hdfs的配置
hadoop-site.xml // hadoop集群的访问配置(如master地址)在这些配置文件中,最重要的是spark-defaults.conf,典型配置模板如下所示。
# Default system properties included when running spark-submit.
# This is useful for setting default environmental settings.
# Example:
# spark.master spark://master:7077
# spark.eventLog.enabled true
# spark.eventLog.dir hdfs://namenode:8021/directory
# spark.serializer org.apache.spark.serializer.KryoSerializer
# spark.driver.memory 5g
# spark.executor.extraJavaOptions -XX:+PrintGCDetails -Dkey=value -Dnumbers="one two three"2. 如何向spark集群提交应用
Spark客户端自带的bin/spark-submit脚本可以用来向集群提交应用,如下面的示例命令通过Spark客户端提交了一个基于ALS算法的矩阵分解模型用来实现电影个性化推荐:
spark-1.3.0.5-bin/bin/spark-submit movie_als_rec.pyspark-submit支持的参数列表可从官网文档了解,也可打开spark-submit脚本查看,脚本中解析参数的代码片段如下:
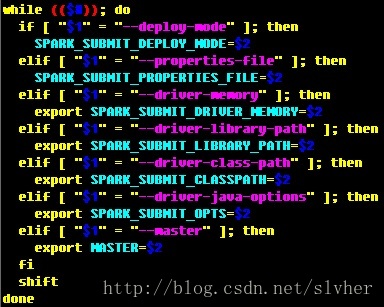
这里对deploy-mode参数做特别说明:
1) deploy mode分为client和cluster两种。
2) 若待提交的应用部署的节点与集群worker节点在物理网络上很近,则以client模式提交应用较为合理。在client模式下,driver由spark应用脚本所在机器节点的spark-submit直接调起,driver针对应用的输入/输出会打印至该节点的终端控制台。
3) 若spark应用脚本部署节点与spark集群worker节点物理网络距离较远,则以cluster提交可以减少driver和executors间的网络延时(因为正常情况下,应用分解出的若干tasks均会由driver负责调度executor来执行,每次调度均有网络开销)。
4) 目前以standalone或mesos方式部署的spark集群不支持cluster模式,基于Python的spark应用提交也不支持cluster模式。
未完待续,下篇笔记将会介绍Spark集群对应用的调度方式。
【参考资料】
1. Spark Configuration
==================== EOF ===================
以上是关于Spark调研笔记第2篇 - 如何通过Spark客户端向Spark提交任务的主要内容,如果未能解决你的问题,请参考以下文章