数据存储方式——KVELL:快速持续键值存储的设计与实现
Posted Dreamchaser追梦
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据存储方式——KVELL:快速持续键值存储的设计与实现相关的知识,希望对你有一定的参考价值。
文章目录
前言
最近在和小伙伴们做开源项目,方向就是数据存储,最近也是调研学习很多知识,也看了一些论文,KVELL就是其中一篇,感觉挺不错的,就拿出来分享一下。
有兴趣的小伙伴可以去看一下,题目叫做KVell: the Design and Implementation of a Fast Persistent Key-Value Store。
一、背景
1.当前流行的两种存储范式
目前持久KVs主要有两种范式:
- LSM KVs
被广泛认为是写为主的工作负载的最佳选择。LSM KVs在流行的系统中使用,如RocksDB和Cassandra。 - B树KVs
被认为更适合读密集型工作负载。在MongoDB中使用了B树及其变体
2.SSD性能的发展
我们考虑一下在过去5年中引入的三种设备:
• Config-SSD. A 32-core 2.4GHz Intel Xeon, 128GB ofRAM, and a 480GB Intel DC S3500 SSD (2013).
• Config-Amazon-8NVMe.An A WS i3.metal instance, with 36 CPUs (72 cores) running at 2.3GHz, 488GB of RAM, and 8 NVMe SSD drives of 1.9TB each (brand unknown, 2016 technology).
• Config-Optane. A 4-core 4.2GHz Intel i7, 60GB of RAM, and a 480GB Intel Optane 905P (2018).
IOPS
(每秒输入输出次数,是一个用于计算机存储设备(如硬盘(HDD)、固态硬盘(SSD)或存储区域网络(SAN))性能测试的量测方式). 表1显示了这三种设备的最大读写IOPS数以及随机和顺序带宽。首先,IOPS的数量和带宽显著增加。其次,在较老的设备上,随机写操作比顺序写操作要慢得多,但现在已经不是这样了。类似地,混合随机读写不再会像老式设备那样导致性能低下。例如,Config-Optane使用在2018年Q3发布的Intel Optane 905P驱动器,不管读写的混合方式如何,它都能维持500K+ IOPS,而且随机访问也只比顺序访问稍微慢一点。
延迟和带宽
下表展示了三个设备的延迟和带宽测量值,它们是设备队列深度的函数,其中一个核心执行随机写操作。上一代设备只能通过少量的同步I/O请求维持亚毫秒级的响应时间(在Config-SSD的情况下是32个)。Config-Amazon-8NVMe和Config-Optane支持更高的并行性,这两个驱动器都能够以亚毫秒级的延迟响应256个同时发生的请求。当设备队列中的请求太少时,这两个驱动器只能达到其带宽的一小部分。因此,即使在现代设备上,也必须在发送太少的并发请求(导致次优带宽)和发送太多(导致高延迟)之间保持良好的平衡。

吞吐量降低
下表显示了这三种设备上的IOPS随时间的变化。这张图也显示了设备技术的进步。例如,配置ssd可以在40分钟内维持50K的写入IOPS,但随后它的性能慢慢下降到11K IOPS。较新的ssd就不会有这个问题,而且随着时间的推移,IOPS会保持在较高的水平。

I / O突发
图2显示了Config-Amazon-8NVMe和Config-Optane上队列深度为64的4K写操作的延迟。由于内部维护操作,老一代ssd在写量大的工作负载中受到延迟高峰的影响。在Config-SSD上,我们观察到5小时后延迟峰值高达100ms,而正常的写入延迟为1.5ms。图2中没有显示这些结果,因为这个设备的峰值大小会掩盖其他设备的结果。Config-Amazon-8NVMe驱动器也会受到周期性延迟高峰的影响。最大观察到的延迟是15ms(而99.1%是3ms)。在Config-Optane驱动器上,潜伏期的峰值不规律地发生,它们的幅度通常小于1ms,观察到的最大峰值为3.6ms(相比之下,99%的峰值为700us)。

3.NVMe ssd上当前KVs的问题
3.1 CPU是瓶颈
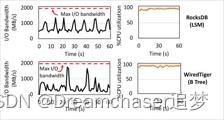
图3. Config-Optane。
RocksDB(LSM KV)和WiredTiger(B树KV)的I /O带宽(左)和CPU消耗(右)时间线。 这两个系统都无法利用整个设备的I / O带宽。工作负载:YCSB写入50%–读取50%,均匀密钥分配,KV项大小为1KB。
CPU是LSM KVs的瓶颈
LSM KVs通过吸收内存缓冲区中的更新来优化写密集型工作负载。当缓冲区满时,它被刷新到磁盘。然后,后台线程将刷新的缓冲区合并到持久存储中维护的树状结构中。磁盘结构包含多个级别,级别大小不断增加。每一层都包含多个不可变的排序文件,它们的键值范围不一致(除了第一层,它是为写内存缓冲区保留的)。为了在磁盘上保留这种结构,LSM KVs实现了称为压缩的CPU和I/O密集维护操作,该操作将LSM树中较低级别的数据合并到较高级别的数据,维护项目排序并丢弃重复项。
在较旧的设备上,压缩会争夺磁盘带宽,但是合并、索引和内核代码也会争夺CPU时间,而在较新的设备上,CPU已经成为主要的瓶颈。分析显示,RocksDB在压缩上花费了高达60%的CPU时间(28%用于合并数据,15%用于构建索引,剩下的用于读取和写入磁盘数据)。压缩需求源于LSM的设计要求,即顺序磁盘访问和在磁盘上保持数据排序。这种设计对于旧的驱动器是有益的,在这些驱动器中,花费CPU周期来保持数据排序和确保长时间顺序的磁盘访问是值得的。
CPU是B树KVs的瓶颈
有两种变体B树为持久性存储设计:B +树和Bϵ树。B+树在叶子中包含KV项。内部节点只包含键并用于路由。通常,内部节点驻留在内存中,叶子驻留在持久存储中。每个叶节点都有一个已排序的KV项范围,并且叶节点被链接到一个链表中,便于扫描。最先进的B+树(例如,WiredTiger)依靠缓存来实现良好的性能。更新首先写入每个线程的提交日志,然后写入缓存。最终,当数据从缓存中被逐出时,树将使用新信息进行更新。更新使用序列号,这是扫描所必需的。读操作遍历缓存,只有在项目未被缓存时才访问树。
有两种类型的操作可以将数据持久化到树中:
- 检查点和
- 驱逐。
检查点定期发生,或者在日志中达到某个大小阈值时发生。检查点对于保持提交日志的大小有限制是必要的。驱逐将脏数据从缓存写入树中。当缓存中的脏数据量超过某个阈值时,将触发驱逐。
Bϵ树是B +树的变体,增强临时存储键和值在每个节点的缓冲区。最终,当缓冲区满了时,KV项沿着树结构向下延伸,并被写入持久存储。
B树的设计容易产生同步开销。WiredTiger中的剖析揭示了这一点:工作线程花费47%的时间忙于等待日志中的插槽(在__log_wait_for_earlier_slot函数中,该函数使用sched_yield系统调用来忙碌等待)。这个问题源于不能足够快地推进序列号进行更新。在更新的主代码路径中,不包括内核所花费的时间,WiredTiger只花费18%的时间来执行客户端请求逻辑,其余时间用于等待。WiredTiger还需要执行后台操作:从页面缓存中清除脏数据占总时间的12%,管理提交日志占总时间的5%。内核中只有25%的时间用于读写调用,其余的时间用于futex和yield函数。
Bϵ树也经历同步开销。因为Bϵ树保持磁盘上的数据命令有序,工作线程最终修改共享数据结构,导致争用。对TokuMX的分析表明,线程将30%的时间花费在锁或用于保护共享页面的原子操作上。缓冲也被证明是Bϵ树中的一个主要开销来源。在YCSB中,一个工作负载TokuMX花费超过20%的时间将数据从缓冲区移动到叶子中的正确位置。这些同步开销大大超过了其他开销。
3.2 LSM和B树KVs的性能波动
除了受制于cpu之外,LSM和B树KVs都受到了显著的性能波动。图4显示了RocksDB和WiredTiger运行YCSB核心工作负载a的吞吐量随时间的波动。吞吐量是每秒测量一次的。在LSM和B树KVs中,基本问题是相似的:客户端更新会因为维护操作而停止。
在LSM KVs中,吞吐量下降是因为有时更新需要等待压缩完成。当LSM树的第一级已满时,更新需要等待,直到通过压缩使空间可用。但是,我们已经看到,当LSM KVs在现代驱动器上运行时,压缩会遇到CPU瓶颈。随着时间的推移,吞吐量方面的性能差异会上升一个数量级:RocksDB平均维持63K /s的请求,但在写入停止时下降到1.5K。分析显示,写线程大约有22%的时间被搁置,等待内存组件被刷新。内存组件的刷新被延迟,因为压缩无法跟上更新的速度。
降低压实对性能影响的解决方案已被提出,即延迟压缩或者仅在系统空闲时运行它们,但是这些解决方案不适合在高端ssd上运行。例如,Config-Optane机器以2GB/s的速度刷新内存组件。延迟压缩超过几秒钟会导致大量的工作积压和浪费空间。
在B树中,用户工作负载中的暂停也会影响性能。用户写入被延迟,因为驱逐不能足够快地进行。暂停导致吞吐量下降了一个数量级,从120 Kops/s下降到8.5 Kops/s。我们的结论是,在这两种情况下,诸如压缩和驱逐之类的维护操作严重干扰用户的工作负载,导致持续数秒的暂停。因此,新的KV设计应避免维护操作。

二、KVELL
1.KVs设计原则
-
不共享。在KVell中,这可以转化为支持并行性和最小化KV工作线程之间的共享状态,以减少CPU开销。
-
不要在磁盘上排序,而是将索引保存在内存中。KVell将未排序的项目保存在磁盘的最终位置,避免了昂贵的重新排序操作。
-
目标是减少系统调用,而不是连续的I/O。KVell的目标不是顺序磁盘访问,它利用了这样一个事实:随机访问几乎和现代ssd上的顺序访问一样高效。相反,它努力通过批处理I/O来最小化系统调用造成的CPU开销。
-
不提交日志。KVell不缓冲更新,因此不需要依赖于提交日志,避免了不必要的I/O。
1.1 不共享
对于单个读和写的常见情况,处理请求的工作线程不需要与其他线程同步。每个线程处理给定的键子集的请求,并维护一个线程私密的数据结构集来管理这组键。
关键数据结构是:
- (i)一个轻量级内存B树索引,用于跟踪键在持久存储中的位置
- (ii) i / O队列,从持久存储负责有效地存储和检索信息
- (iii)自由列表,部分内存磁盘块列表包含用于存储项和(iv)页面缓存——KVell使用自己不依赖于os级结构的内部页面缓存。扫描是在内存中的B树索引上需要最小同步的惟一操作。
与传统KV设计相比,这种无共享方法是一个关键的区别,在传统KV设计中,所有或大多数主要数据结构都由所有工作线程共享。传统的方法需要对每个请求进行同步,这是KVell完全避免的。分区请求可能会导致负载不平衡,但我们发现,如果使用合适的分区,这种影响很小。
1.2 不要在磁盘上排序,而是将索引保存在内存中
KVell不会对工作线程的工作集中的数据进行排序。因为KVell不对键进行排序,所以它可以将项保存在磁盘上的最终位置。磁盘上完全没有顺序减少了插入项的开销(即找到插入的正确位置),并消除了与磁盘上的维护操作(或者写入磁盘之前的排序)相关的CPU开销。在磁盘上以无序方式存储密钥尤其有利于写操作,并有助于实现较低的尾延迟。
在扫描期间,连续的键不再在同一个磁盘块中,这可能是一个缺点。然而,可能令人惊讶的是,对于具有中型和大型kv -项的工作负载(例如YCSB基准测试或生产工作负载中的扫描,如我们在第6节中所示),扫描性能不会受到显著影响。
1.3 目标是减少系统调用,而不是顺序I/O
在KVell中,所有操作(包括扫描)都对磁盘执行随机访问。因为随机访问和顺序访问一样有效,所以KVell不会浪费CPU周期来强制执行顺序I/O。
与LSM KVs类似,KVell将请求批量发送到磁盘。然而,目标是不同的。LSM KVs主要使用批处理I/O和对KV项进行排序,以便利用顺序磁盘访问。KVell对I/O请求进行批处理,主要目标是减少系统调用的数量,从而减少cpu开销。
批量是需要折中的,正如在第2节中看到的,磁盘需要一直处于忙碌状态,以实现其峰值IOPS,但只有在硬件队列中包含的请求数小于给定数量(例如Config-Optane上的256个请求)时,磁盘才会以亚毫秒级的延迟响应。一个高效的系统应该向磁盘推送足够的请求,以使它们保持忙碌,但是不要让大的请求队列淹没它们,这会导致高延迟。
在具有多个磁盘的配置中,每个worker只在一个磁盘上存储文件。这种设计决策对于限制每个磁盘挂起的请求数量非常关键。实际上,由于worker之间不通信,所以它们不知道其他worker向给定磁盘发送了多少请求。如果worker将数据存储在单个磁盘上,那么对磁盘的请求数量是有限的(批处理大小乘以每个磁盘上的worker数量)。如果工作者要访问所有磁盘,那么磁盘可能有多达(批大小乘以工作者总数)的挂起请求。
1.4 不提交日志
KVell只在更新被持久化到最终位置的磁盘上之后才承认更新,而不依赖于提交日志。一旦更新被提交给工作线程,它将在下一个I/O批中持久化到磁盘上。删除提交日志允许KVell仅将磁盘带宽用于有用的客户机请求处理。
2.KVELL实现
2.1 客户端操作界面
KVell实现了与LSM KVs相同的核心接口:
- 写Update(k,v)
将值 v与键 k关联。Update(k,v)只在值被持久化到磁盘后返回 - 读Get(k)
Get(k)返回k的最近值 - 范围扫描Scan(k1,k2)。
返回k1和k2之间的KV项目范围。
2.2 磁盘数据结构
为了避免碎片化,适合相同大小范围的项被存储在相同的文件中。我们称这些文件为slab。KVell以块粒度访问slab,也就是我们机器上的页面大小(4KB)。
如果项小于页面大小(例如,多个项可以容纳在一个页面中),KVell会在slab中的项前面加上时间戳、键大小和值大小。大于4K的项在磁盘上每个块的开头都有一个时间戳头。对于小于页面大小的项,将在适当的位置进行更新。对于较大的项,一次更新包括将项目附加到slab上,然后在项目曾经所在的地方写一个墓碑。当一个项更改大小时,KVell首先将更新后的项写入新slab,然后从旧slab中删除它。
2.3 内存中的数据结构
索引
KVell依赖于快速而轻量级的内存索引,这些索引具有可预测的插入和查找时间来查找磁盘上项的位置。KVell为每个worker使用一个内存中的B树来存储磁盘上项目的位置。项根据其键(前缀)建立索引。我们使用前缀而不是哈希来保持范围扫描的键的顺序。B树在存储中/大型数据时性能很差,但当数据(大部分)能放入内存且键很小时,速度很快。KVell利用了这个属性,并且只使用B树存储查找信息(前缀和位置信息占13B)。
KVell的树实现目前平均每个条目使用19B(存储前缀、位置信息和B树结构),相当于1.7GB的RAM来存储100M个条目。在YCSB工作负载(1KB项)上,索引相当于数据库大小的1.7%。我们发现这个值在实践中是合理的。KVell目前不显式地支持将B树的一部分刷新到磁盘,但是B树数据是从mmap-ed文件中分配的,可以由内核调出。
页面缓存
KVell维护自己的内部页面缓存,以避免从持久存储中获取频繁访问的页面。缓存的页面大小是一个系统参数。页面缓存会记住哪些页面缓存在索引中,并按照LRU顺序从缓存中回收页面。
确保索引中的查找和插入具有最小的CPU开销对于获得良好的性能至关重要。我们的第一个页面缓存实现使用快速uthash哈希表作为索引。但是,当页面缓存很大时,散列中的插入可能会花费高达100ms的时间(增长散列表的时间),从而提高了尾延迟。切换到B树可以消除这些延迟峰值。
空闲列表
当从一个slab中删除一个项时,它在该slab中的位置将插入到每个slab的内存堆栈中,我们称之为slab的空闲列表。然后在磁盘上的项目位置写入一个tombstone。为了绑定内存使用,我们只保留内存中最后的N个释放的位置(目前N被设置为64)。其目标是限制内存使用,同时保持在不需要额外磁盘访问的情况下重用每批I/O的多个空闲点的能力。
当(N + 1)th项被释放时,KVell使其磁盘tombstone指向第一个被释放的位置。然后KVell从内存堆栈中删除第一个被释放的位置,并插入(N +1)被释放的位置。当(N +2)th项被释放时,它的tombstone指向第二个被释放的位置,以此类推。简而言之,KVell维护N个独立的堆栈,它们的头驻留在内存中,其余的在磁盘上。这使得Kvell在每批I/O能重用最多N个空闲点。如果只有一个堆栈,KVell就必须从磁盘上依次读取N个tombstone,以找到下一个被释放的N个位置。
2.4 有效地执行I/O
KVell依赖于Linux (AIO)的异步I/O API将请求发送到磁盘,最多分批发送64个请求。通过批量处理请求,KVell将系统调用的开销分摊到多个客户机请求上。我们选择使用Linux异步I/O,是因为它为我们提供了一种通过单个系统调用执行多个I/Os的方法。我们估计,如果这样的调用在同步I/O API中可用,性能将大致相同。
我们拒绝了两个流行的执行I/O的替代方案:(1)使用依赖于OS页面缓存的mmap (例如,RocksDB),和(2)使用直接读写I/O系统调用(例如,TokuMX)。这两种技术的效率都不如使用AIO接口。表3总结了我们的发现,展示了在Config-Optane上可以实现的最大IOPS,随机写入4K块(这需要对设备进行读-修改-写操作)。被访问的数据集比可用RAM大3倍。

第一种方法是依赖os级页面缓存。在单线程情况下,这种方法的性能不是最优的,因为当发生页面错误时,它一次只能发出一次磁盘读取(由于数据是随机访问的,所以提前读取值设置为0)。此外,脏页只定期刷新到磁盘。这在大多数情况下会导致次优化的队列深度,然后是I/Os的爆发。当数据集不能完全装入RAM时,内核还必须从进程的虚拟地址空间映射和取消映射页出页,这会带来显著的CPU开销。对于多线程,在刷新LRU时,页面缓存会受到锁开销的影响(平均每32KB刷新一个锁到磁盘),以及系统使远程核心的TLB项失效的速度。实际上,当一个页面从虚拟地址空间中取消映射时,需要在所有访问过该页面的核心上使虚拟到物理的映射失效,这将导致IPI通信带来巨大的开销。
第二种方法是依赖于直接I/O。然而,当请求以同步方式完成时(每个线程有一个挂起的请求),直接I/O读/写系统调用不会填充磁盘队列。因为没有必要处理从虚拟地址空间映射和取消映射页面的复杂逻辑,此技术优于mmap方法。
相反,批处理I/O每个批处理只需要一个系统调用,并允许KVell控制设备队列长度,以实现低延迟和高带宽。尽管理论上I/O批处理技术可以应用于LSM和B树KVs,但实现将需要很大的努力。在B树中,不同的操作可能会对I/O产生冲突的影响(例如,由插入引起的叶的分裂,然后是两个叶的合并)。此外,数据可能由于重新排序而在磁盘上移动,这也使得异步批处理请求难以实现。写请求的批处理已经通过内存组件在LSM KVs中实现。然而,批处理略微增加了读取路径的复杂性,因为工作人员必须确保压缩线程不会删除所有需要读取的文件。
2.5 客户端操作实施
算法1总结了KVell架构。为简单起见,该算法只显示单页KV项。当一个请求进入系统,根据它的键被分配给worker(第3行和第5行,算法1). worker线程执行磁盘I/O并处理客户端请求的逻辑。
得到(k)。读取一个项(第17-22行,算法1)包括从索引中获取它在磁盘上的位置,并读取相应的页。如果已经缓存了页面,则不需要访问持久存储,并且值将同步返回给客户机。如果没有,则处理请求的worker将其推入其I/O引擎队列。
更新(k、v)。更新一个项(第24-35行,算法1)包括首先读取存储它的页面,修改值,然后将该页面写入磁盘。删除一个项目包括写入一个tombstone值和在slab的空闲列表中添加项目位置。在添加新项时重用释放的位置,如果不存在空闲位置,则追加项目。KVell仅在更新的项完全持久化到磁盘时(即io_getevents系统调用通知我们,与更新对应的磁盘写操作已经完成(算法1的第37行),才确认更新已经完成。脏数据会立即刷新到磁盘,因为KVell的页面缓存不用于缓冲区更新。通过这种方式,KVell提供了比最先进的KVs更强的持久性保证。例如,RocksDB只在提交日志同步到磁盘的粒度上保证持久性。在典型的配置中,同步只发生在几批更新中。
扫描(k1, k2)。扫描包括(1)从索引中获取键的位置,(2)读取对应的页面。为了计算键的列表,KVell扫描所有的索引:一个线程简单地依次锁定、扫描和解锁所有worker的索引,最后合并结果以获得一个要从KV读取的键的列表。然后使用Get()命令执行读取,该命令绕过了索引查找(因为KVell已经访问了索引)。扫描是唯一需要在线程之间共享的操作。KVell返回与扫描触及的每个键相关联的最新值。相比之下,RocksDB和WiredTiger都在KV快照上执行扫描。
2.6 故障模型与恢复
KVell目前的实现是为无故障运行而优化的。在崩溃的情况下,所有的平板被扫描,内存中的索引被重新构建。即使扫描使顺序磁盘带宽最大化,在非常大的数据集上恢复仍然需要几分钟。
如果一个项在磁盘上出现了两次(例如,在将一个项从一个slab迁移到另一个slab的过程中发生了崩溃),那么只有最近的项保存在内存索引中,而另一个项插入到空闲列表中。对于大于块大小的项,KVell使用时间戳标头来丢弃仅被部分写入的项。
KVell是为能够自动写入4KB页面的驱动器设计的,即使在电源故障的情况下也是如此。通过避免对页面进行就地修改,在新页面中写入新值,然后在第一次写入操作完成后在slab的空闲列表中添加旧位置,可以解除该约束。
ps:该论文实现是开源得,KVELL
总结
KVELL是一种比较新的数据存储方案,该方案主要是针对近年来性能不断提升的SSD去设计的。
其核心就是内存索引+非顺序存储。同时对于SSD还有一些优化,比如类似fatcache的Slab机制,底层批处理I/O,非共享设计等等。
总之,KVELL是针对现代SSD存储设计的一种存储方案,某种程度上又回到了原始的读写方式(顺序读写->随机读写)。
不得不感叹一句,设计的魅力在于权衡!
以上是关于数据存储方式——KVELL:快速持续键值存储的设计与实现的主要内容,如果未能解决你的问题,请参考以下文章