嵌入式Linux系统的电子书阅读器项目3——Encode & Font System
Posted zhou_chenz
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了嵌入式Linux系统的电子书阅读器项目3——Encode & Font System相关的知识,希望对你有一定的参考价值。
1.字符编码(Encode)与字体(Font)显示概述
如图1,大家在阅读器界面看到的不同字体和尺寸的"好"字(左边宋体小二,右边楷体小二),在电子书txt格式文档中的原始数据是如何存储的呢?
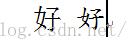
图1 左边宋体小二,右边楷体小二
实际上,采用不同编码格式,其表示方法是不同的,以下是四种常用编码格式的表示方法。
utf8: 0xE5A5BD
utf16-le: 0x7D59
utf16-be: 0x597D
ascii/gbk:0xBAC3
关于这四种常用编码方式的基本规则和概念,在此不详细介绍了,
有兴趣的爱好者可以看看阮一峰老师的这篇博客:
但自此说明的是,我把gbk和ascii码放在一起,是因为ascii本身只是标准英文字符集编码,是不包含汉字的,
gbk是在ascii字符集之后,按照相应规则,扩充了汉字库,并完全包含了ascii字符集(有点C和C++ 语法集的关系)。
但是gbk并不是国际通用汉字标准,只是中国大陆地区自制的编码标准,所以才有gbk编码的文本,容易出现乱码现象,
可能需要转换成unicode码才能互相传输显示(另外,港台汉字采用big-5编码)。
一个txt文档里的原始文字变成屏幕上显示的各种字体和大小的字符的过程如图2所示。通过基本概念的解释,
让爱好者意识,显示的字体和编码的字符是不同的基本概念,接下将详细介绍编码和字体系统的框架。
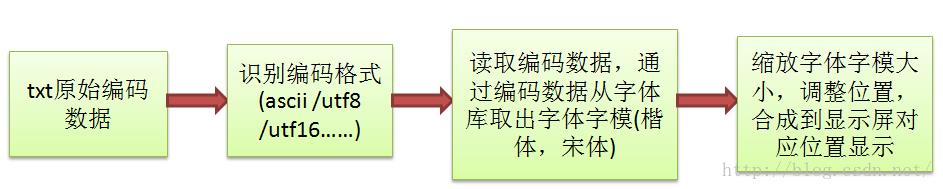
图2 原始txt文本编码数据到显示在屏幕上的字体转换过程
2.字符编码系统(Encode System) 架构与API
1).系统框架
字符编码系统由核心层与各个组件部分,其架构图如图3所示。每个组件都是可装载卸载的,即系统不需要实现所有组件,仅需要激活一个组件就能使用该组件在组件指定的特性和范围中运行,本项目其它子系统都是采用这种可装载卸载组件的方法架构和设计的。
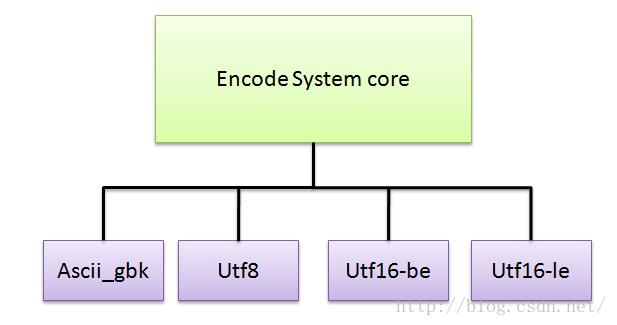
图3 字符编码系统框架
Encode System core:
字符编码系统的核心层,用于封装字符编码相关的复杂业务逻辑与数据交换,Book Engine通过输入原始txt文档文件,由Encode system内部组件自动匹配对应的编码格式,然后选用对应的解码格式化组件,无法匹配的字符编码格式文件将返回错误。
2). API简介
encode system 相关头文件在include/encode.h中声明。
encode:
编码系统核心结构描述符encode 声明如下:
typedef struct encode
char *name;
struct encode_attr attr;
int (*is_support)(char *file_buf_head);
int (*get_fmtcode_frm_buf)(__u8 *curr_addr, __u8 *buf_end, __u32 *fmtcode);
struct encode *next;
encode;
中获取。
attr:
encode 的属性attr包含了该encode对应编码格式所能自动识别的txt文件该编码前缀长度head_len(如:utf8格式文件头长度),
以及suppt_font_h,表示编码encode支持适配的的字体字模库的链表,并非每钟编码方式都能能支持所有的字库字模,本项目
编码格式所能支持的字体字模库对应表如表1所示。
表1 encode所支持的font对应关系表

is_support():
通过读取文件前head_len个字符,自动识别文件的编码格式,来选择自动对应的encode
get_fmtcode_frm_buf():
从已识别编码格式的文件中,获取经过unicode格式化的字符编码,系统可以unicode格式化后的字符编码到font
字体字模库中查询获取相应的字体字模bitmap。本系统格式化的unicode码其实就是utf16-be格式的编码,其它字符编码格式
都通过各自组件实现的get_fmtcode_frm_buf()函数转换成utf16-be格式的32位编码,提供给Book_engine去字库查询生产font
bitmap。
load_encode_md()/register_encode_md()/print_encode_md_lst():
这三支api和本项目第2篇之前display system类似,都是用来加载注册encode,以及调试打印,在此不多累述。
select_encode_for_file():
通过输入经过mmap到内存的过的 txt原始文件地址,自动识别获取文件对应的encode。
add_font_for_encode()/del_font_frm_encode():
为encode的attr中的suppt_font_h链表增加/删除所支持的font结构实体。
3). 核心函数与实现逻辑
encode system core层的核心函数的源代码实现在 encode/encode.c 文件中。
2)节中所介绍的API大部分都是链表相关的比较查询逻辑操作,具体细节可参考github上源代码,
并没有太多晦涩部分。
3.字符编码(Encode) 模块与组件
各encode编码格式文件所对应的不同前缀如表2所示。
表2 各字符编码格式文件前缀
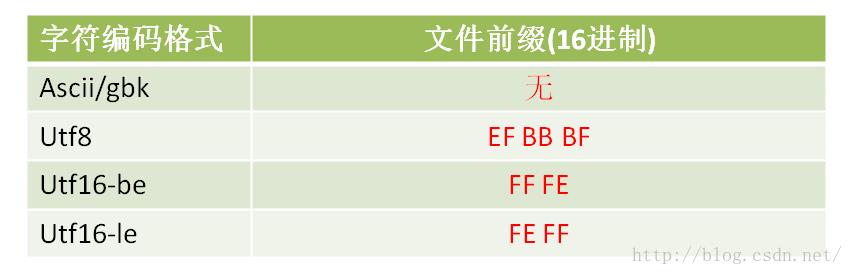
其实各个组件中自动识别对应文件编码格式而实现is_support()函数并不复杂(比图像格式简单),只需要获取文件前几个字节,与表2中的文件头前缀规则进行比较即可。
1).ASCII GBK 编码模块
ascii_gbk 模块的实现代码在encode/ascii_gbk.c文件中,该组件与utf8、utf16-be、utf16-le等几个模块一样,都需要填充实现对应的核心模块,然后将模块通过register_encode_md() 函数将模块注册到encode system core层里面,以便Book Engine 通过name来检索,调用。
static struct encode ascii_gbk =
.name = "ascii_gbk",
.is_support = is_ascii_gbk_encode,
.get_fmtcode_frm_buf = get_ascii_gbk_code_frm_buf,
.attr =
.head_len = 0,
.suppt_font_h = NULL,
,
;
该函数主要将encode模块加载并注册到系统核心,这点与其它子系统类似,不过encode组件的load_ 函数中,
需要调用add_font_for_encode()函数为相关的encode组件添加该encode所支持的字体(font),
目前各个encode模块所支持的font如表1所示。
get_ascii_gbk_code_frm_buf():
该函数将ascii 编码转换成格式化的unicode(utf16-be)码,保存在32位变量指针fmtcode所指的地方。
ascii码字符集被utf16-be兼容,因而只需转成32位即可。
2).UTF8 编码模块
utf8模块的实现代码在encode/utf8.c文件中。
get_utf8_code_frm_buf():
utf8组件的该函数,稍显复杂,原因是utf8编码本身要复杂一些(基本编码单元字节不固定),
需要参考并理解部分utf8原理才行。本函数是参考韦东山老师的实现,稍微修改,在此附上@韦东山老师的注释。
对于UTF-8编码中的任意字节B,如果B的第一位为0,则B为ASCII码,并且B独立的表示一个字符;
如果B的第一位为1,第二位为0,则B为一个非ASCII字符(该字符由多个字节表示)中的一个字节,
并且不为字符的第一个字节编码;
如果B的前两位为1,第三位为0,则B为一个非ASCII字符(该字符由多个字节表示)中的第一个字节,
并且该字符由两个字节表示;
如果B的前三位为1,第四位为0,则B为一个非ASCII字符(该字符由多个字节表示)中的第一个字节,
并且该字符由三个字节表示;
如果B的前四位为1,第五位为0,则B为一个非ASCII字符(该字符由多个字节表示)中的第一个字节,
并且该字符由四个字节表示;
因此,对UTF-8编码中的任意字节,根据第一位,可判断是否为ASCII字符;
根据前二位,可判断该字节是否为一个字符编码的第一个字节;
根据前四位(如果前两位均为1),可确定该字节为字符编码的第一个字节,并且可判断对
get_pre_one_bit_cnt():
用于获取utf8 编码基本单元的前导码,给get_utf8_code_frm_buf()函数进行处理,
具体实现也是参考@韦东山老师的源代码,下面给出它的注释:
获得前导为1的位的个数
比如二进制数 11001111 的前导1有2位
11100001 的前导1有3位
uft8 组件其它函数和ascii_gbk 基本类似,可以参考源代码,在此不多累述。
3).UTF16-le 编码模块
utf16-le模块的实现代码在encode/utf16_le.c文件中。
Utf16-le 编码的le表示little endian 即小端字节序,和计算机概念中通用的小端字节序是一个意思,
而本系统采用的统一unicode编码是Utf16-be格式,大端字节序,因而Utf16-le组件的get_utf16_le_code_frm_buf()
函数需要把小端字节序转换为大端字节序,并保存在32位变量fmtcode中。其它函数实现与前述模块类似,较utf8简单。
4).UTF16-be 编码模块
utf16-be模块的实现代码在encode/utf16_be.c文件中。
Utf16-be 编码的be表示big endian 即大端字节序,是本系统采用的标准格式的编码,可以通过Utf16-be编码去对应的
ascii字模库和freetype支持的矢量字体库检索获取对应的字体bitmap用于显示。该组件的get_utf16_le_code_frm_buf()
函数只需将2字节的Utf16-be 编码基本单元保存在32位变量中即可。
4.字体系统(Font System) 架构与API
1).系统框架
字体系统的框架如图4所示,与前几个子系统类似,还是使用核心层+组件模块的可装载拆卸模式。
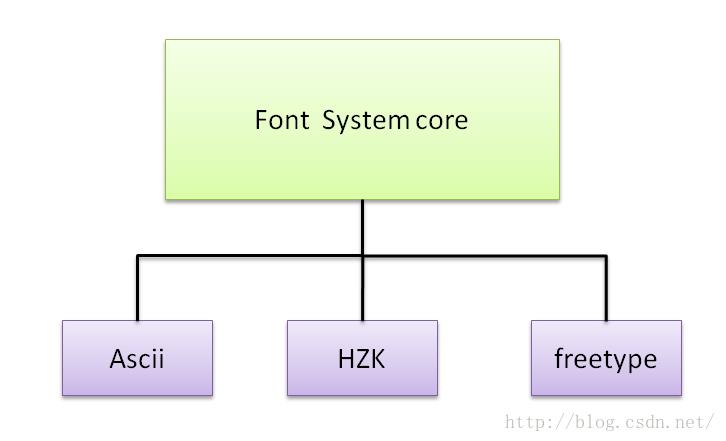
图4 字体系统框架
Font System core:
字体系统的核心层,用于封装font system相关的复杂业务逻辑与数据交换,Book Engine通过格式化的encode获取的编码,调用Font System core
中的函数来查询字体字模库,最后在字体字模库钟找出可供显示的字体bitmap,渲染(render)到显示屏上。
2). API简介
font system core 的api声明主要在include/font.h 头文件中
struct font:
fnont system 系统的核心描述符,其声明如下:
typedef struct font
char *name;
struct font_bitmap_attr attr;
int (*font_init)(char *font_filename, __u32 font_size);
int (*get_font_bitmap)(__u32 code, struct font_bitmap_attr *bitmap);
struct font *next;
font; struct font_bitmap_attr attr:
这个属性稍显复杂,主要是用来描述单个font的bitmap的各个属性,其中坐标相关的属性如图5所示。
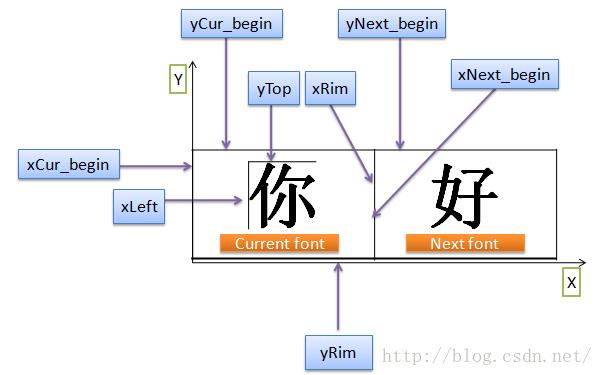
图5 一个font的坐标轴属性
每个font都是一个方块字,每个方块字都要维护font_bitmap_attr其在lcd显示屏上的坐标,以及下一个方块字的起始坐标。
非坐标相关属性中:
f_bpp——表示每个字体bitmap的bit per pixel,除了艺术彩色字,一般都是1.
pitch——对于单色位图, 两行pixel之间的跨度(gap)
bitmap_buffer——从字体字模库中取出的bitmap所在buffer的首地址指针。
get_font_obj():
根据name,从所有已经加载的font组件中,获取对应的struct font 实体。
其它API函数与其它模块类似都是相关的加载,注册,调试函数,在此不再累述。
3). 核心函数与实现 以上是关于嵌入式Linux系统的电子书阅读器项目3——Encode & Font System的主要内容,如果未能解决你的问题,请参考以下文章 嵌入式Linux系统的电子书阅读器项目2——Display System 嵌入式Linux系统的电子书阅读器项目4——Input Event System