《Linux从0到99》四 Linux编译器(gcc/g++)和调试器(gdb)
Posted RONIN_WZ
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了《Linux从0到99》四 Linux编译器(gcc/g++)和调试器(gdb)相关的知识,希望对你有一定的参考价值。
Linux编译器和调试器的使用
1. Linux编译器gcc/g++使用
01 预处理
主要处理源代码文件中的以“#”开头的预编译指令。
- 删除所有的#define并展开所有的宏定义。
- 处理所有的条件预编译指令,如
“#if”、“#endif”、“#ifdef”、“#elif”和“#else”。- 处理“#include”预编译指令,将文件内容替换到它的位置,这个过程是递归进行的,文件中可能包含#include。
- 删除所有的注释,“//”和“/**/”。
- 保留所有的#pragma 编译器指令,编译器需要用到他们,如:#pragma once 是为了防止有文件被重复引用。
- 添加行号和文件标识,以便于编译时编译器产生调试用的行号信息和编译时产生编译错误或警告是能够显示行号。
用法: gcc –E XXXX.c –o XXXX.i
选项: -E 只激活预处理,这个不生成文件,你需要把它重定向到一个输出文件里面
实例:
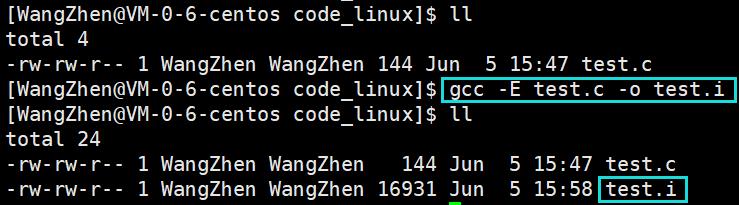
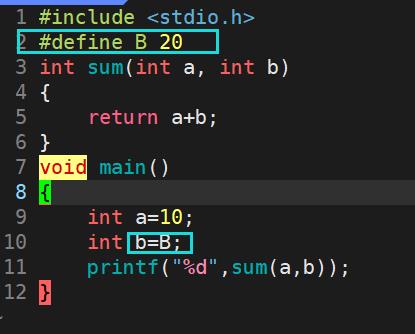
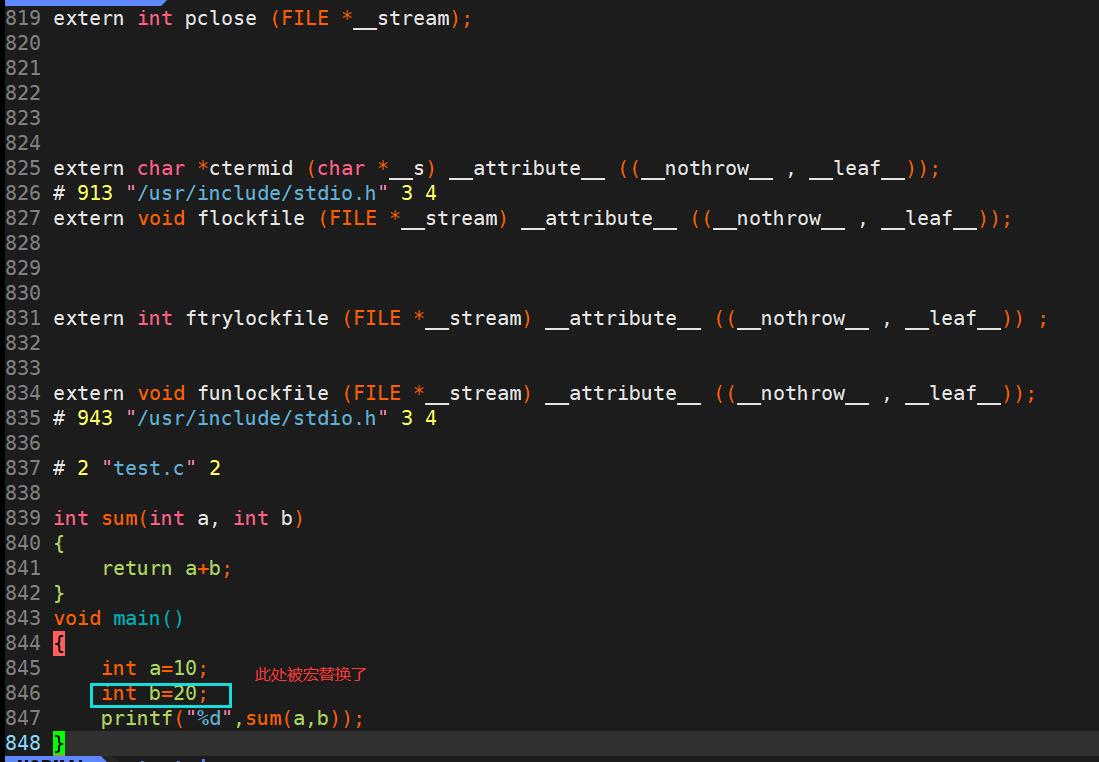
02 编译
把预编译之后生成的后缀为.i,进行一系列词法分析、语法分析、语义分析及优化后,生成相应的汇编代码文件。
- 词法分析: 利用类似于“有限状态机”的算法,将源代码程序输入到扫描机中,将其中的字符序列分割成一系列的记号。
- 语法分析: 语法分析器对由扫描器产生的记号,进行语法分析,产生语法树。由语法分析器输出的语法树是一种以表达式为节点的树。
- 语义分析: 语法分析器只是完成了对表达式语法层面的分析,语义分析器则对表达式是否有意义进行判断,其分析的语义是静态语义——在编译期能分期的语义,相对应的动态语义是在运行期才能的语义。
- 优化: 源代码级别的一个优化过程。
- 目标代码生成: 由代码生成器将中间代码转换成目标机器代码,生成一系列的代码序列——汇编语言表示。
- 目标代码优化: 目标代码优化器对上述的目标机器代码进行优化:寻找合适的寻址方式、使用位移来替代乘法运算、删除多余的指令等。
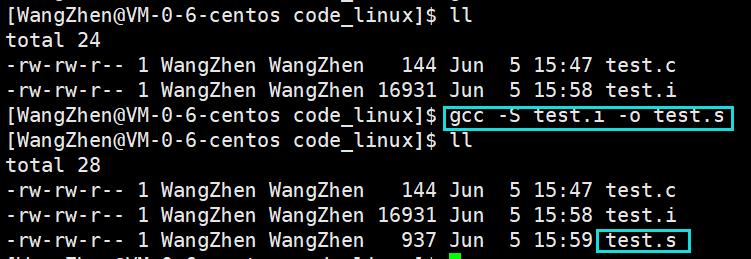
用法: gcc –S XXXX.i –o XXXX.s
选项: -S 编译到汇编语言不进行汇编和链接
实例:
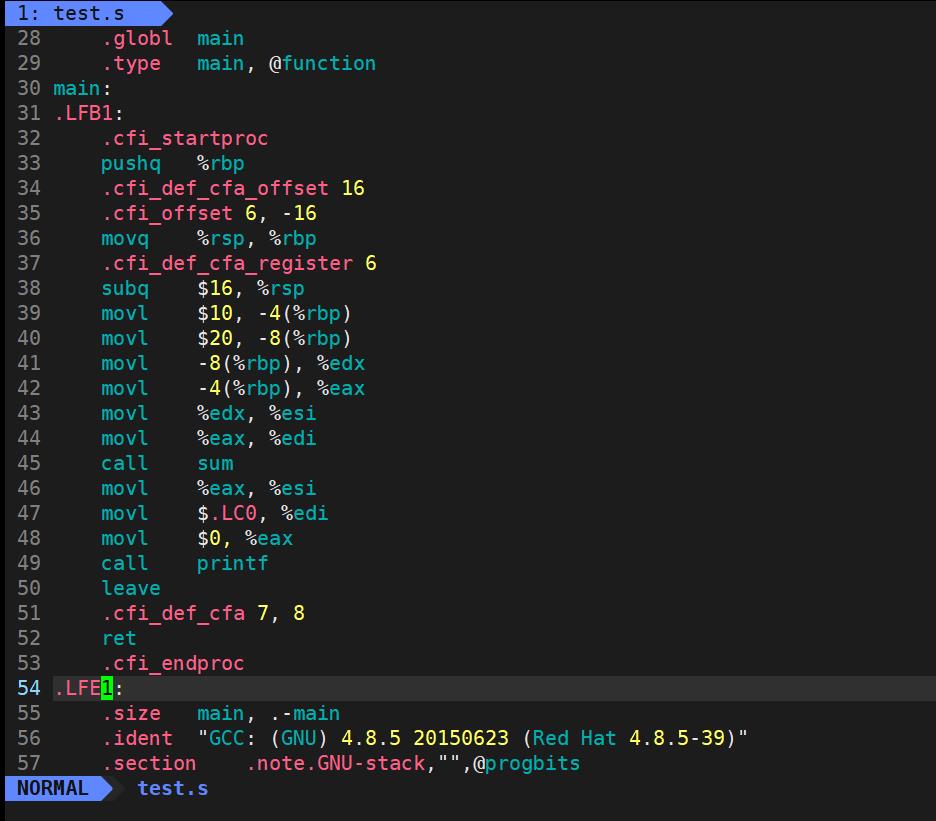
03 汇编
将汇编代码转变成机器可以执行的指令(机器码文件)。 汇编器的汇编过程相对于编译器来说更简单,没有复杂的语法,也没有语义,更不需要做指令优化,只是根据汇编指令和机器指令的对照表一一翻译过来,汇编过程有汇编器as完成。经汇编之后,产生目标文件。
用法: gcc –c XXXX.s –o XXXX.o
选项: -c 编译到目标代码
实例:
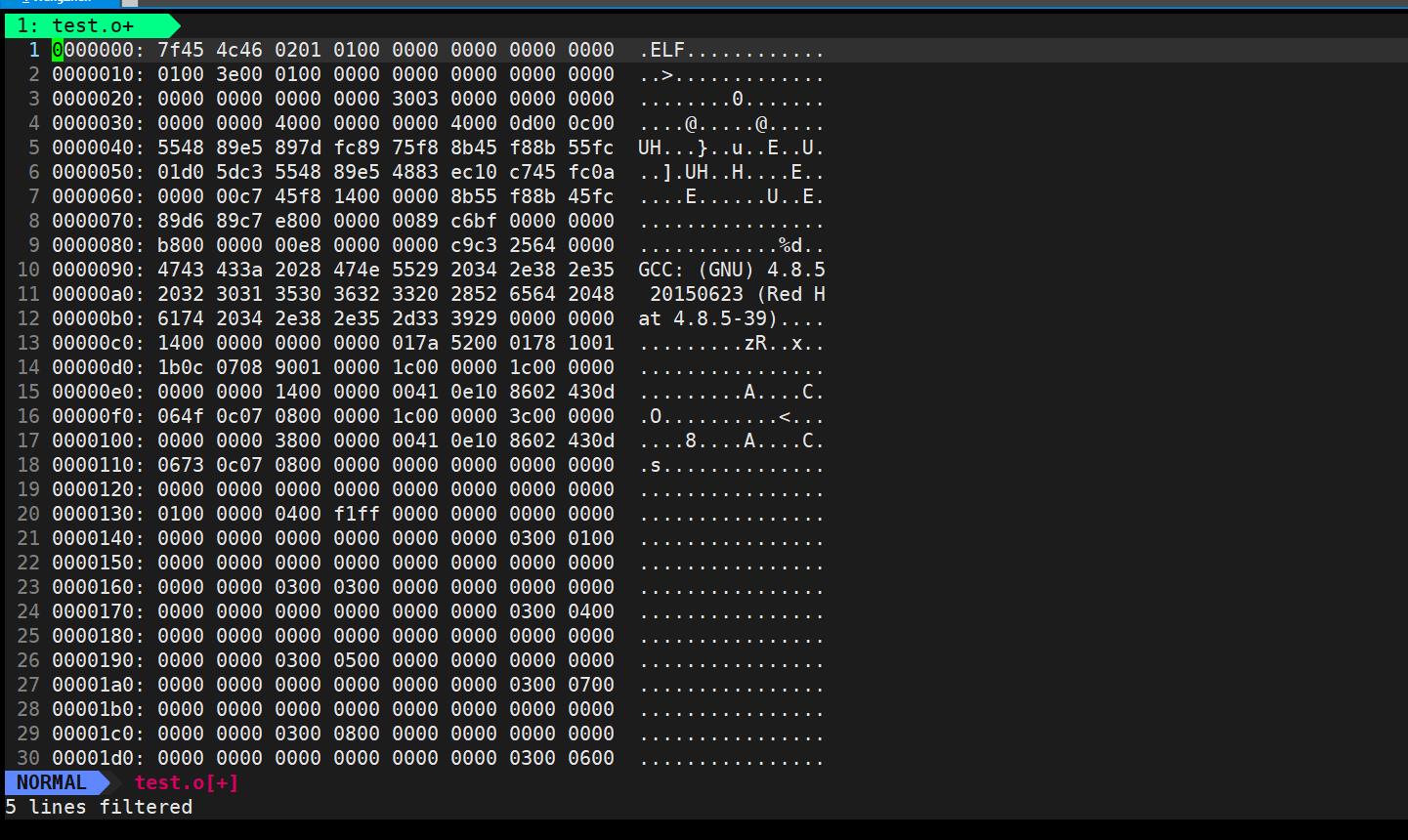
以二进制形式查看test.o
vim -b test.o在底行模式输入:%!xxd
04 连接
将不同的源文件产生的目标文件进行链接,从而形成一个可以执行的程序。链接分为静态链接和动态链接,gcc默认生成的二进制程序,是动态链接的,这点可以通过 file 命令来验证.
实例:
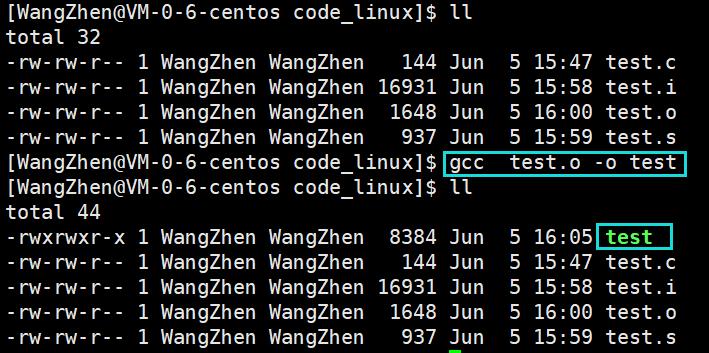
静态链接:
函数和数据被编译进一个二进制文件。在使用静态库的情况下,在编译链接可执行文件时,链接器从库中复制这些函数和数据并把它们和应用程序的其它模块组合起来创建最终的可执行文件。
特点:
- 运行速度快:静态链接的优点就是,在可执行程序中已经具备了所有执行程序所需要的任何东西,在执行的时候运行速度快。
- 空间浪费:因为每个可执行程序中对所有需要的目标文件都要有一份副本,所以如果多个程序对同一个目标文件都有依赖,会出现同一个目标文件都在内存存在多个副本;
- 更新困难:每当库函数的代码修改了,这个时候就需要重新进行编译链接形成可执行程序。
动态链接:
动态链接的基本思想是把程序按照模块拆分成各个相对独立部分,在程序运行时才将它们链接在一起形成一个完整的程序,而不是像静态链接一样把所有程序模块都链接成一个单独的可执行文件。
**共享库:**就是即使需要每个程序都依赖同一个库,但是该库不会像静态链接那样在内存中存在多分,副本,而是这多个程序在执行时共享同一份副本;
特点:
- 更新方便:更新时只需要替换原来的目标文件,而无需将所有的程序再重新链接一遍。当程序下一次运行时,新版本的目标文件会被自动加载到内存并且链接起来,程序就完成了升级的目标。
gcc选项:
- -E 只激活预处理,这个不生成文件,你需要把它重定向到一个输出文件里面
- -S 编译到汇编语言不进行汇编和链接
- -c 编译到目标代码
- -o 文件输出到 文件
- -static 此选项对生成的文件采用静态链接
- -g 生成调试信息。GNU 调试器可利用该信息。
- -shared 此选项将尽量使用动态库,所以生成文件比较小,但是需要系统由动态库.
- -O0
- -O1
- -O2
- -O3 编译器的优化选项的4个级别,-O0表示没有优化,-O1为缺省值,-O3优化级别最高
- -w 不生成任何警告信息。
- -Wall 生成所有警告信息。
2. Linux调试器gdb
01 背景知识
- 程序的发布方式有两种,debug模式和release模式。Linux默认生存的可执行程序是动态链接且release方式发布的。
- 要使用gdb调试,必须在源代码生成二进制程序的时候, 加上 -g 选项
GDB的功能:
- 启动你的程序,可以按照你的自定义的要求随心所欲的运行程序。
- 可让被调试的程序在你所指定的调置的断点处停住。(断点可以是条件表达式)
- 当程序被停住时,可以检查此时你的程序中所发生的事。
- 你可以改变你的程序,将一个BUG产生的影响修正从而测试其他BUG。
02 常用指令
启动gdb:gdb 二进制文件
退出gdb:ctrl+d 或者quit
调试指令:
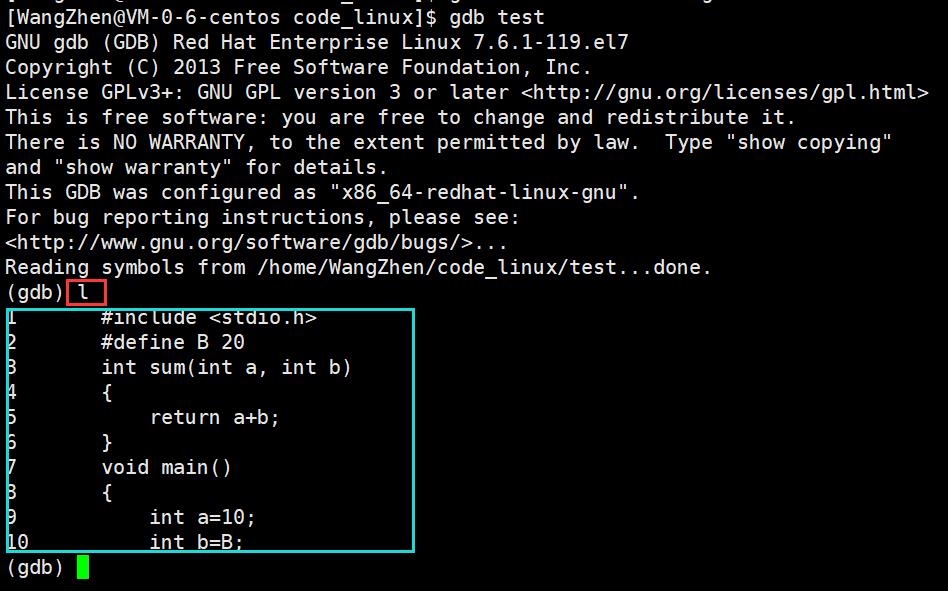
list/l 行号:显示binFile源代码,接着上次的位置往下列,每次列10行
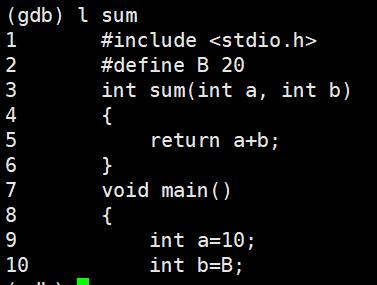
list/l 函数名:列出某个函数的源代码
r/run:运行程序
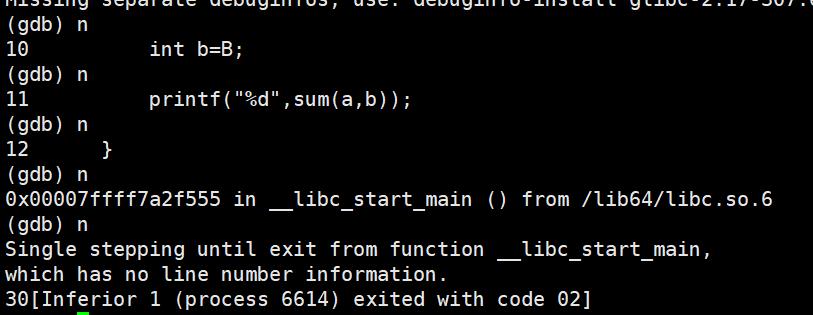
n 或 next:单条执行
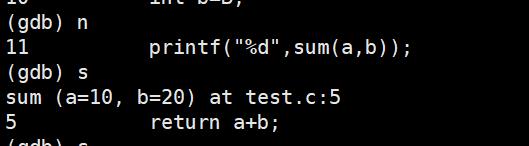
s或step:进入函数调用
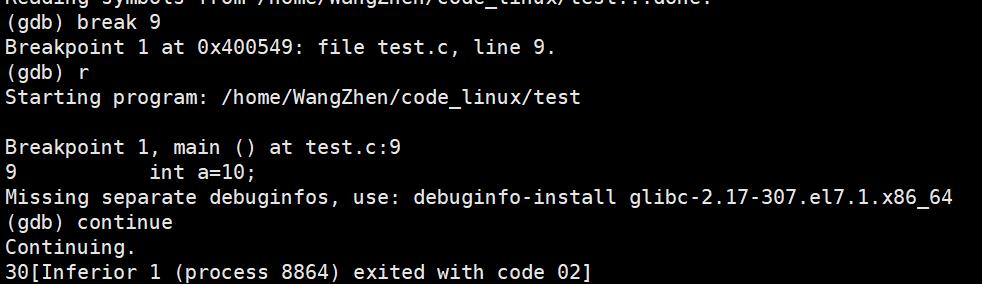
break(b)行号:在某一行设置断点
break 函数名:在某个函数开头设置断点
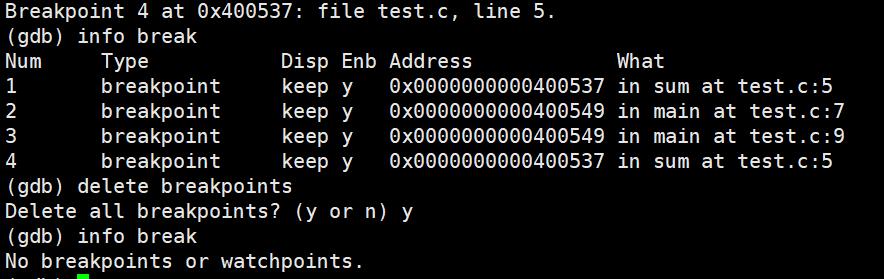
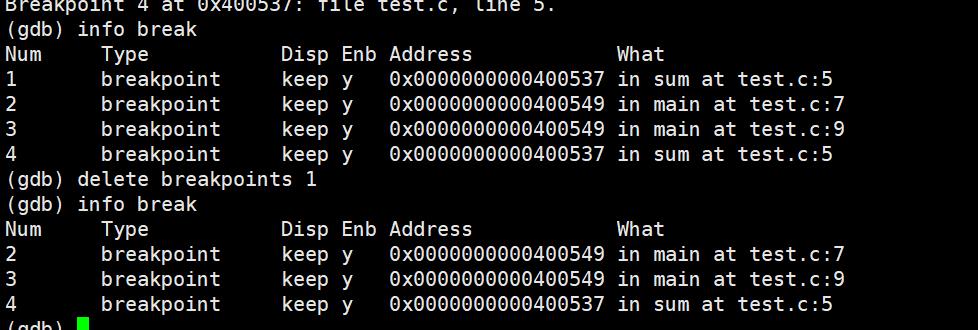
info break/info breakpoints:查看断点信息。
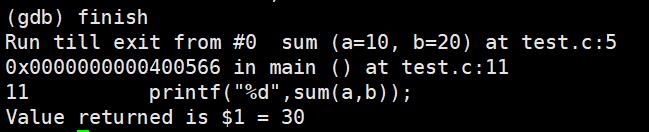
finish:执行到当前函数返回,然后停下来等待命令
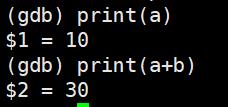
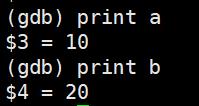
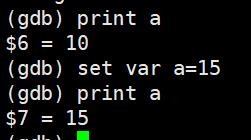
print(p):打印表达式的值,通过表达式可以修改变量的值或者调用函数
p 变量:打印变量值.
set var:修改变量的值
continue(或c):从当前位置开始连续而非单步执行程序
delete breakpoints:删除所有断点
delete breakpoints n:删除序号为n的断点
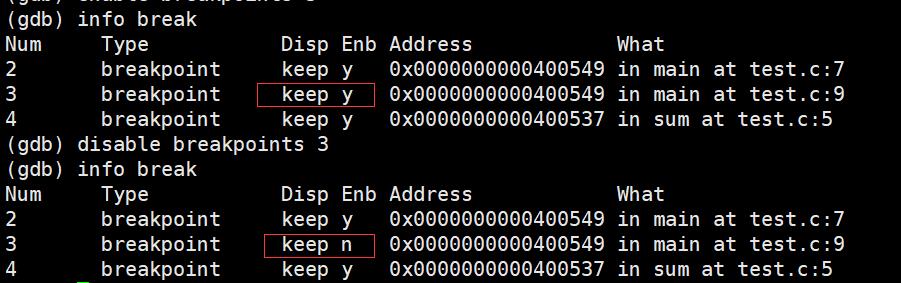
disable breakpoints:禁用断点
enable breakpoints:启用断点
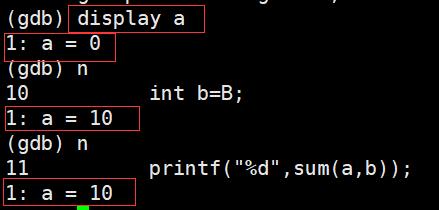
display 变量名:跟踪查看一个变量,每次停下来都显示它的值
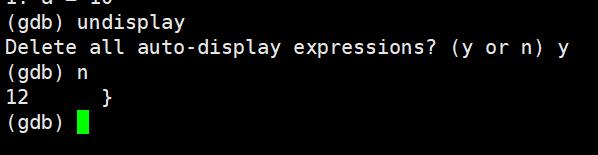
undisplay:取消对先前设置的那些变量的跟踪
until X行号:跳至X行
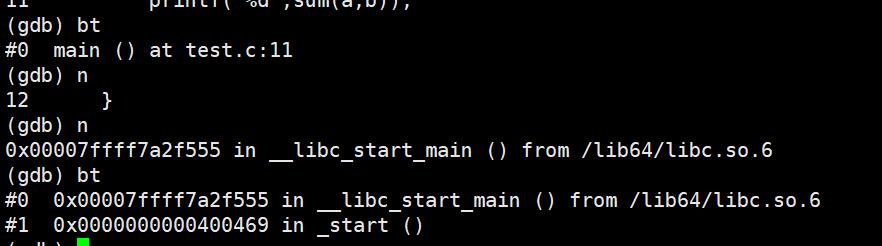
breaktrace(或bt):查看各级函数调用及参数
info(i) locals:查看当前栈帧局部变量的值






3. make与Makefile
01 背景以及定义
Linux 环境下的程序员如果不会使用GNU make来构建和管理自己的工程,应该不能算是一个合格的专业程序员,至少不能称得上是 Unix程序员。
在 Linux(unix )环境下使用GNU 的make工具能够比较容易的构建一个属于你自己的工程,整个工程的编译只需要一个命令就可以完成编译、连接以至于最后的执行。不过这需要我们投入一些时间去完成一个或者多个称之为Makefile 文件的编写。
所要完成的Makefile 文件 描述了整个工程的编译、连接等规则。其中包括:工程中的哪些源文件需要编译以及如何编译、需要创建哪些库文件以及如何创建这些库文件、如何最后产生我们想要的可执行文件。 尽管看起来可能是很复杂的事情,但是为工程编写Makefile 的好处是能够使用一行命令来完成“自动化编译”,一旦提供一个(通常对于一个工程来说会是多个)正确的 Makefile。编译整个工程你所要做的事就是在shell 提示符下输入make命令。整个工程完全自动编译,极大提高了效率。
make是一个命令工具,它解释Makefile 中的指令。在Makefile文件中描述了整个工程所有文件的编译顺序、编译规则。Makefile 有自己的书写格式、关键字、函数。像C 语言有自己的格式、关键字和函数一样。而且在Makefile 中可以使用系统shell所提供的任何命令来完成想要的工作。Makefile在绝大多数的IDE 开发环境中都在使用,已经成为一种工程的编译方法。
02 理解makefile高效的原理
- make会在当前目录下找名字叫“Makefile”或“makefile”的文件。
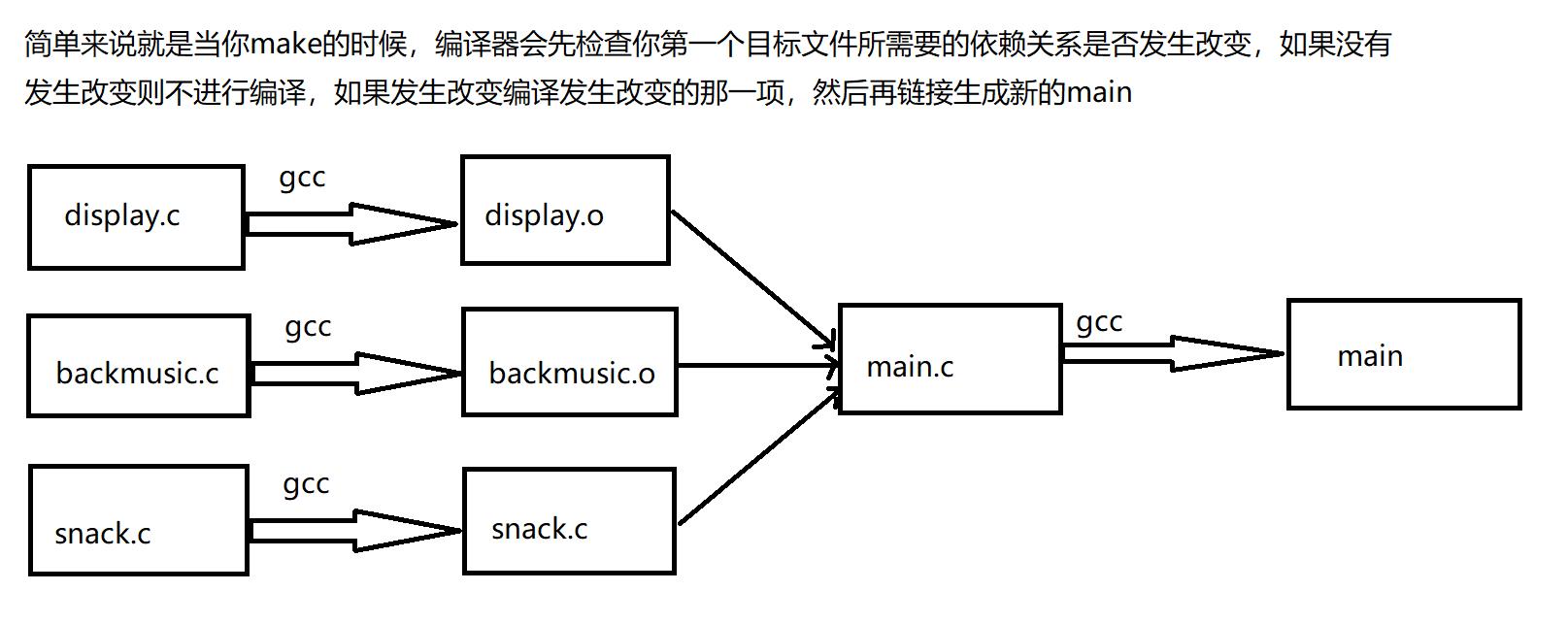
- 如果找到,它会找文件中的第一个目标文件(target),在上面的例子中,他会找到“hello”这个文件,
并把这个文件作为最终的目标文件。- 如果hello文件不存在,或是hello所依赖的后面的hello.o文件的文件修改时间要比hello这个文件新(可
以用 touch 测试),那么,他就会执行后面所定义的命令来生成hello这个文件。- 如果hello所依赖的hello.o文件不存在,那么make会在当前文件中找目标为hello.o文件的依赖性,如果
找到则再根据那一个规则生成hello.o文件。(这有点像一个堆栈的过程)- 当然,你的C文件和H文件是存在的啦,于是make会生成 hello.o 文件,然后再用 hello.o 文件声明
make的终极任务,也就是执行文件hello了。- 这就是整个make的依赖性,make会一层又一层地去找文件的依赖关系,直到最终编译出第一个目标文
件。- 在找寻的过程中,如果出现错误,比如最后被依赖的文件找不到,那么make就会直接退出,并报错,
而对于所定义的命令的错误,或是编译不成功,make根本不理。- make只管文件的依赖性,即,如果在我找了依赖关系之后,冒号后面的文件还是不在,那么对不起,我就不工作啦。
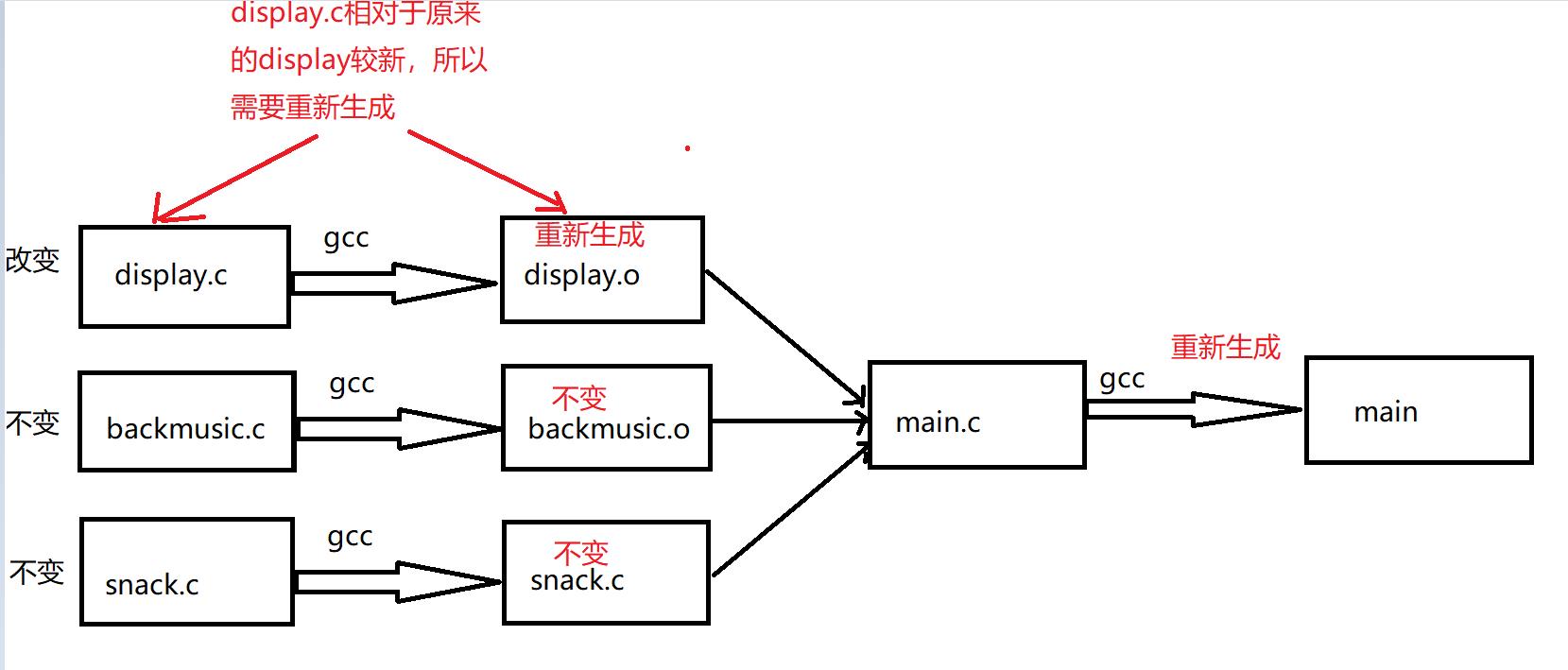
当display发生改变时。
03 项目清理
- 工程是需要被清理的。
- 像clean这种,没有被第一个目标文件直接或间接关联,那么它后面所定义的命令将不会被自动执行,不过,我们可以显示要make执行。即命令——“make clean”,以此来清除所有的目标文件,以便重编译。
- 但是一般我们这种clean的目标文件,我们将它设置为伪目标,用 .PHONY 修饰,伪目标的特性是,总是被执行的。
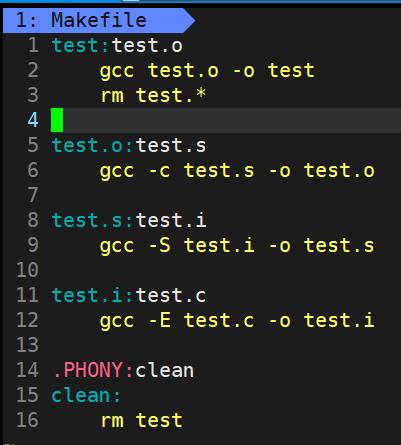
- 可以将我们的 hello目标文件声明成伪目标,测试一下

以上就是这篇文章的所有内容啦,感谢老铁有耐心看完。有啥错误请多多指正哈!码字不易,希望大佬们点个赞
以上是关于《Linux从0到99》四 Linux编译器(gcc/g++)和调试器(gdb)的主要内容,如果未能解决你的问题,请参考以下文章