如何用Python一门语言通吃高性能并发,GPU计算和深度学习
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何用Python一门语言通吃高性能并发,GPU计算和深度学习相关的知识,希望对你有一定的参考价值。
第一个就是并发本身所带来的开销即新开处理线程、关闭处理线程、多个处理线程时间片轮转所带来的开销。实际上对于一些逻辑不那么复杂的场景来说这些开销甚至比真正的处理逻辑部分代码的开销更大。所以我们决定采用基于协程的并发方式,即服务进程只有一个(单cpu)所有的请求数据都由这个服务进程内部来维护,同时服务进程自行调度不同请求的处理顺序,这样避免了传统多线程并发方式新建、销毁以及系统调度处理线程的开销。基于这样的考虑我们选择了基于Tornado框架实现api服务的开发。Tornado的实现非常简洁明了,使用python的生成器作为协程,利用IOLoop实现了调度队列。
第二个问题是数据库的性能,这里说的数据库包括MongoDB和Redis,我这里分开讲。
先讲MongoDB的问题,MongoDB主要存储不同的用户对于验证的不同设置,比如该显示什么样的图片。
一开始每次验证请求都会查询MongoDB,当时我们的MongoDB是纯内存的,同时三台机器组成一个复制集,这样的组合大概能稳定承载八九千的qps,后来随着我们验证量越来越大,这个承载能力逐渐就成为了我们的瓶颈。
为了彻底搞定这个问题,我们提出了最极端的解决方案,干脆直接把数据库中的数据完全缓存到服务进程里定期批量更新,这样查询的开销将大大降低。但是因为我们用的是Python,由于GIL的存在,在8核服务器上会fork出来8个服务进程,进程之间不像线程那么方便,所以我们基于mmap自己写了一套伙伴算法构建了一个跨进程共享缓存。自从这套缓存上线之后,Mongodb的负载几乎变成了零。
说完了MongoDB再说Redis的问题,Redis代码简洁、数据结构丰富、性能强大,唯一的问题是作为一个单进程程序,终究性能是有上限的。
虽然今年Redis发布了官方的集群版本,但是经过我们的测试,认为这套分布式方案的故障恢复时间不够优秀并且运维成本较高。在Redis官方集群方案面世之前,开源世界有不少proxy方案,比如Twtter的TwemProxy和豌豆荚的Codis。这两种方案测试完之后给我们的感觉TwemProxy运维还是比较麻烦,Codis使用起来让人非常心旷神怡,无论是修改配置还是扩容都可以在配置页面上完成,并且性能也还算不错,但无奈当时Codis还有比较严重的BUG只能放弃之。
几乎尝试过各种方案之后,我们还是下决心自己实现一套分布式方案,目的是高度贴合我们的需求并且运维成本要低、扩容要方便、故障切换要快最重要的是数据冗余一定要做好。
基于上面的考虑,我们确定基于客户端的分布式方案,通过zookeeper来同步状态保证高可用。具体来说,我们修改Redis源码,使其向zookeeper注册,客户端由zookeeper上获取Redis服务器集群信息并根据统一的一致性哈希算法来计算数据应该存储在哪台Redis上,并在哈希环的下一台Redis上写入一份冗余数据,当读取原始数据失败时可以立即尝试读取冗余数据而不会造成服务中断。 参考技术A python本来就不具备高并发性,想要性能好就用java和C++吧。没有看不起python的意思
如何用Python进行数据分析?

本文为CDA数据分析研究院原创作品,转载需授权
1.为什么选择Python进行数据分析?
Python是一门动态的、面向对象的脚本语言,同时也是一门简约,通俗易懂的编程语言。Python入门简单,代码可读性强,一段好的Python代码,阅读起来像是在读一篇外语文章。Python这种特性称为“伪代码”,它可以使你只关心完成什么样的工作任务,而不是纠结于Python的语法。
另外,Python是开源的,它拥有非常多优秀的库,可以用于数据分析及其他领域。更重要的是,Python与最受欢迎的开源大数据平台Hadoop具有很好的兼容性。因此,学习Python对于有志于向大数据分析岗位发展的数据分析师来说,是一件非常节省学习成本的事。
Python的众多优点让它成为最受欢迎的程序设计语言之一,国内外许多公司也已经在使用Python,例YouTube,Google,阿里云等等。
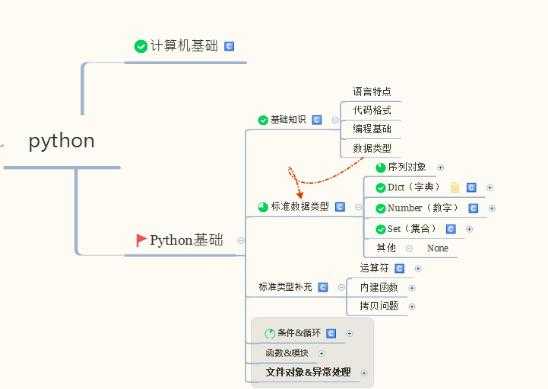
2.编程基础
要学习如何用Python进行数据分析, CDA数据分析师建议第一步是要了解一些Python的编程基础,知道Python的数据结构,什么是向量、列表、数组、字典等等;了解Python的各种函数及模块。下图整理了这一阶段要掌握的知识点:
3.数据分析流程
Python是数据分析利器,掌握了Python的编程基础后,就可以逐渐进入数据分析的奇妙世界。CDA数据分析师认为一个完整的数据分析项目大致可分为以下五个流程:

1)数据获取
一般有数据分析师岗位需求的公司都会有自己的数据库,数据分析师可以通过SQL查询语句来获取数据库中想要数据。Python已经具有连接sql server、mysql、orcale等主流数据库的接口包,比如pymssql、pymysql、cx_Oracle等。
而获取外部数据主要有两种获取方式,一种是获取国内一些网站上公开的数据资料,例如国家统计局;一种是通过编写爬虫代码自动爬取数据。如果希望使用Python爬虫来获取数据,我们可以使用以下Python工具:
Requests-主要用于爬取数据时发出请求操作。
BeautifulSoup-用于爬取数据时读取XML和HTML类型的数据,解析为对象进而处理。
Scapy-一个处理交互式数据的包,可以解码大部分网络协议的数据包
2)数据存储
对于数据量不大的项目,可以使用excel来进行存储和处理,但对于数据量过万的项目,使用数据库来存储与管理会更高效便捷。
3)数据预处理
数据预处理也称数据清洗。大多数情况下,我们拿到手的数据是格式不一致,存在异常值、缺失值等问题的,而不同项目数据预处理步骤的方法也不一样。CDA数据分析师认为数据分析有80%的工作都在处理数据。如果选择Python作为数据清洗的工具的话,我们可以使用Numpy和Pandas这两个工具库:
Numpy - 用于Python中的科学计算。它非常适用于与线性代数,傅里叶变换和随机数相关的运算。它可以很好地处理多维数据,并兼容各种数据库。
Pandas –Pandas是基于Numpy扩展而来的,可以提供一系列函数来处理数据结构和运算,如时间序列等。
4)建模与分析
这一阶段首先要清楚数据的结构,结合项目需求来选取模型。
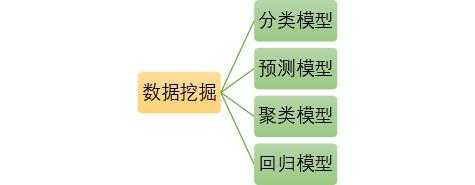
常见的数据挖掘模型有:
在这一阶段,Python也具有很好的工具库支持我们的建模工作:
scikit-learn-适用Python实现的机器学习算法库。scikit-learn可以实现数据预处理、分类、回归、降维、模型选择等常用的机器学习算法。
Tensorflow-适用于深度学习且数据处理需求不高的项目。这类项目往往数据量较大,且最终需要的精度更高。
5)可视化分析
数据分析最后一步是撰写数据分析报告,这也是数据可视化的一个过程。在数据可视化方面,Python目前主流的可视化工具有:
Matplotlib-主要用于二维绘图,它能让使用者很轻松地将数据图形化,并且提供多样化的输出格式。
Seaborn-是基于matplotlib产生的一个模块,专攻于统计可视化,可以和Pandas进行无缝链接。
按照这个流程,每个阶段所涉及的知识点可以细分如下:
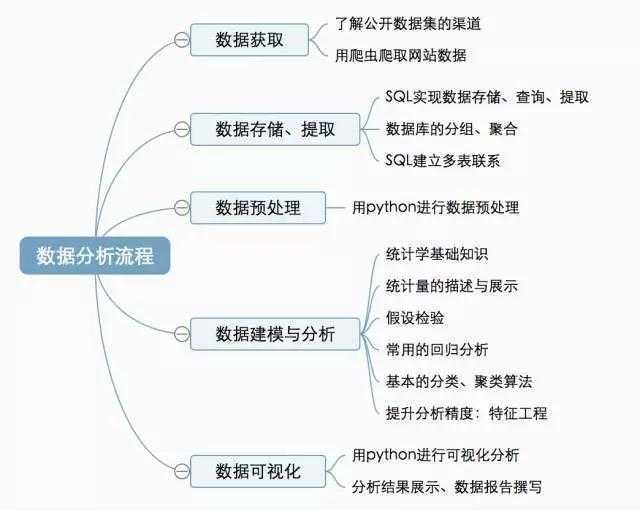
从上图我们也可以得知,在整个数据分析流程,无论是数据提取、数据预处理、数据建模和分析,还是数据可视化,Python目前已经可以很好地支持我们的数据分析工作。
以上是关于如何用Python一门语言通吃高性能并发,GPU计算和深度学习的主要内容,如果未能解决你的问题,请参考以下文章