数据结构——链表
Posted ITRenj
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据结构——链表相关的知识,希望对你有一定的参考价值。
链表基础
链表
链表是由一组不必相连【不必相连:可以连续也可以不连续】的内存结构,按特定的顺序链接在一起的抽象数据类型。是一种线性表,但是并不会按线性的顺序存储数据,而是在由一个个节点组成,节点一般包含存放数据的数据域和存放指针的指针域。
补充:
抽象数据类型(Abstract Data Type [ADT]):表示数学中抽象出来的一些操作的集合。
内存结构:内存中的结构,如:struct、特殊内存块...等等之类;
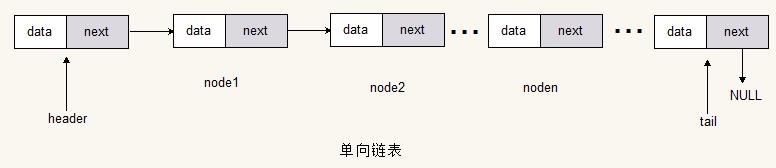
下图就是一种简单的链表
对比数组
数组是在相连的内存空间,由相同数据类型的元素组成的集合。

相同点
-
都是用来存储和操作数据的
-
都是数据结构中的线性结构
不同点
-
数组是顺序的存储结构,也就是连续的内存空间;链表是链式的存储结构,内存空间离散排列的(当然也可以是连续的)
-
链表通过指针来连接元素与元素,数组则是把所有元素按次序依次存储。
-
链表的插入删除元素相对数组较为简单,不需要移动元素,且较为容易实现长度扩充,但是寻找某个元素较为困难
-
数组寻找某个元素较为简单,但插入与删除比较复杂,由于最大长度需要再申请内存空间时指定,所以扩容不如链表方便
分类
一般来说,链表常用的有 3 类: 单向链表、双向链表、循环链表(单链循环,双链循环)。
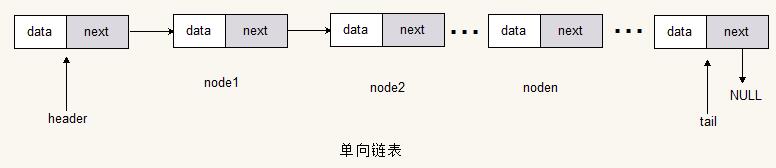
单向链表
单向链表的节点由一个具体的数据域和指向下一个节点的指针域组成。所以单链表只能单向读取、查找和遍历。
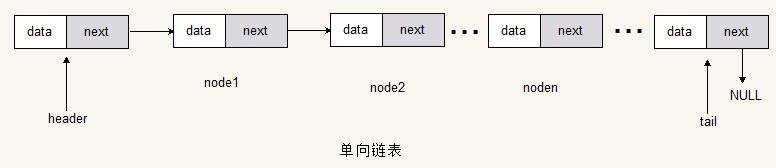
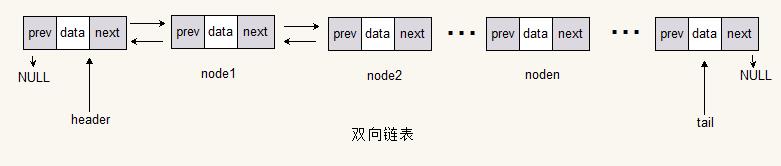
双向链表
双向链表的节点由一个具体的数据域和指向上一个节点以及指向下一个节点的指针域组成。所以双向链表可以双向读取、查找和遍历。
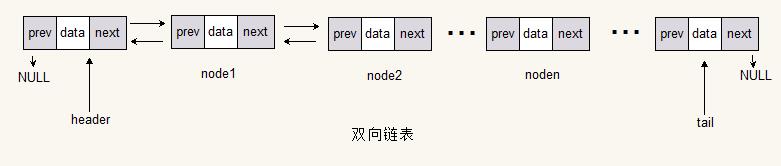
循环链表
单向循环链表
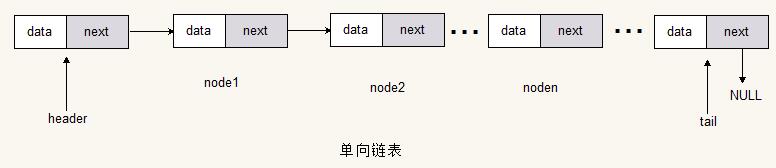
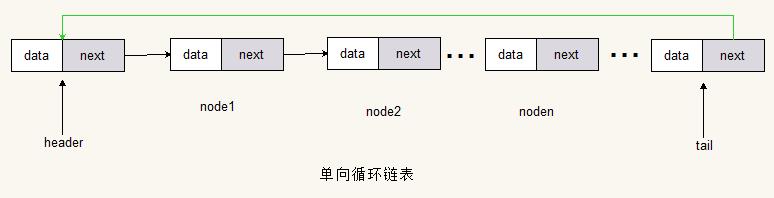
单向循环链表和单向链表只有一个差别,就是在普通单向链表中,尾节点(最后一个节点)的next指向的是NULL;而在单向循环链表中尾节点(最后一个节点)的next指向的是头结点(第一个节点)。
双向循环链表
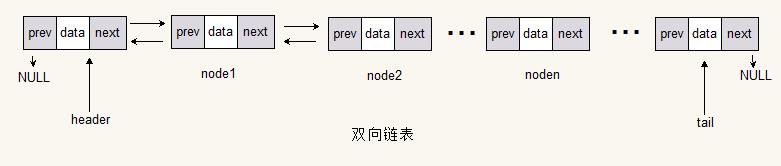
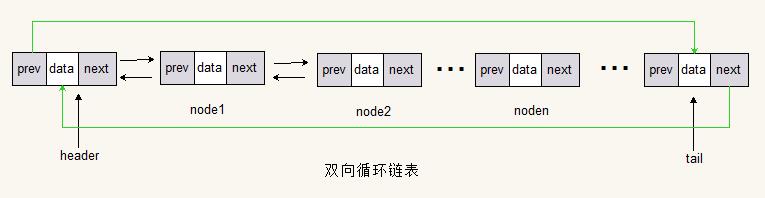
双向循环链表和双向链表的区别与单向链表和单向循环链表的区别类似,就是在普通双向链表中,头节点(第一个节点)的prev和尾节点(最后一个节点)的next都是指向NULL;而在双向循环链表中头节点(第一个节点)的prev指向的是尾节点(最后一个节点),尾节点(最后一个节点)的next指向的是头节点(第一个节点)。
注意:链表是可以有头结点(header)和尾节点(tial),或者没有;或者只有头节点(header),以下操作都是基于有header和tail节点的链表。
单链表操作原理以及核心代码
带头节点和尾节点的单链表
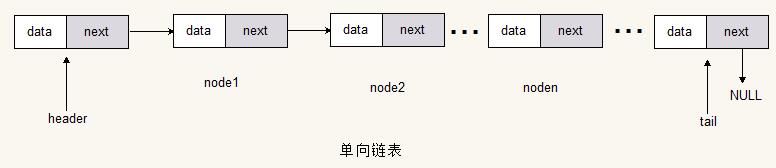
定义单链表节点Node
class Node<E>
E value;
Node<E> next;
public Node(E value)
this.value = value;
添加节点
表头添加
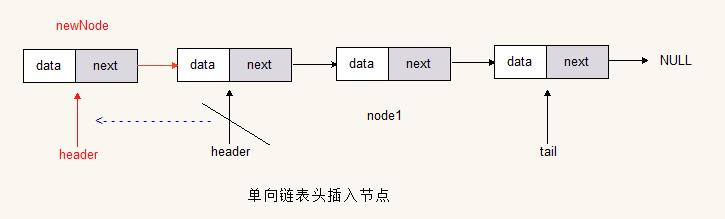
final Node<T> newNode = new Node<>(value);
if (header != null)
newNode.next = header;
header = newNode;
if (tail == null)
tail = header;
header.next = tail;
// tail.next = null; // 不组成循环
tail.next = header; // 组成循环
表尾添加
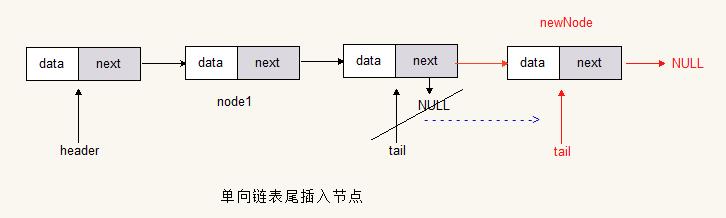
final Node<T> newNode = new Node<>(value);
final Node<T> temp = tail;
temp.next = newNode;
tail = newNode;
// tail.next = null; // 不组成循环
tail.next = header; // 组成循环
中间添加
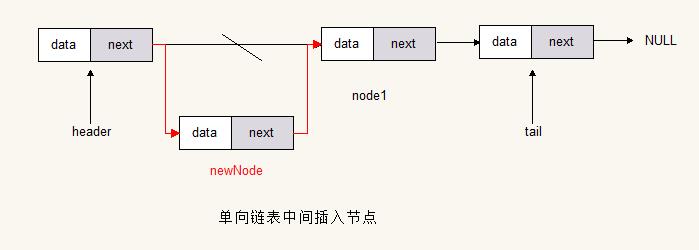
final Node<T> newNode = new Node<>(value);
final Node<T> nodeByIndex = getNodeByIndex(index - 1);
newNode.next = nodeByIndex.next;
nodeByIndex.next = newNode;
移除节点
移除表头
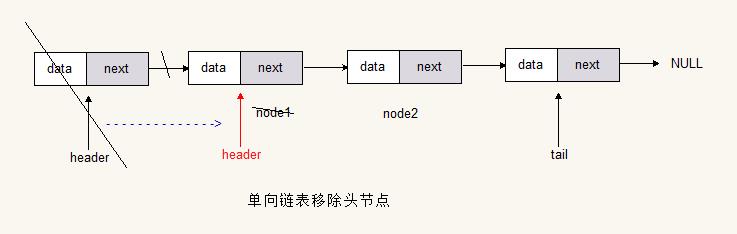
header = header.next;
// tail.next = null; // 不组成循环
tail.next = header; // 组成循环
移除表尾
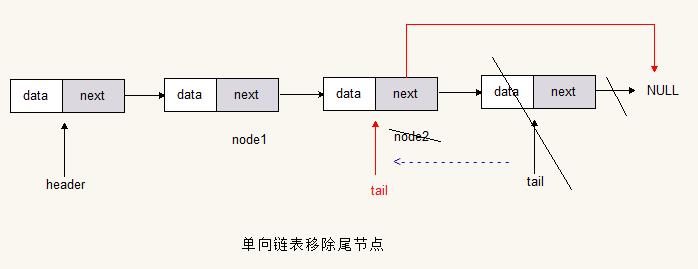
Node<T> nodeByIndex = getNodeByIndex(size - 2);
Node<T> removeNode = nodeByIndex.next;
// nodeByIndex.next = null; // 不组成循环
nodeByIndex.next = header; // 组成循环
移除中间
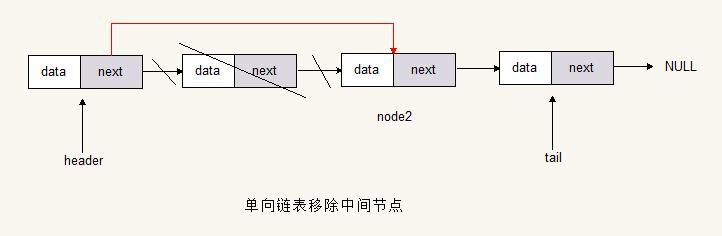
Node<T> removeNode = getNodeByIndex(index);
Node<T> removePre = getNodeByIndex(index - 1);
removePre.next = removeNode.next;
根据位置查询数据(节点)
参数index:需要查找的位置
private Node<T> getNodeByIndex(int index)
Node<T> node = header;
for (int i = 0; i < index; i++)
node = node.next;
return node;
遍历
这里通过指针移动来直接打印节点数据
public void println()
System.out.println("----------------- 打印链表 ----------------- ");
System.out.println("linked size: " + size);
Node<T> node = header;
for (int i = 0; i < size; i++)
System.out.println(node);
node = node.next;
size:表示链表的大小
双向链表操作原理以及核心代码
带头节点和尾节点的双向链表
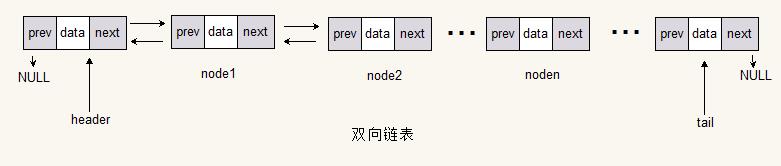
定义单链表节点Node
class Node<E>
E value;
Node<E> prev;
Node<E> next;
public Node(E value)
this.value = value;
添加节点
表头添加
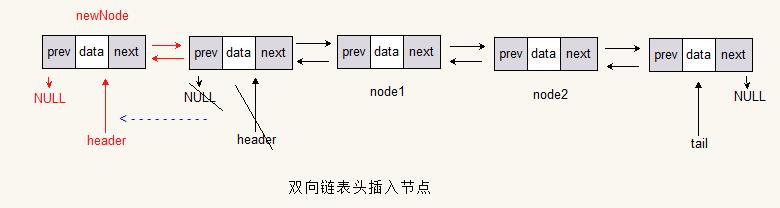
Node<T> newNode = new Node<>(value);
if (header != null)
newNode.next = header;
header.prev = newNode;
header = newNode;
if (tail == null)
tail = header;
tail.prev = header;
header.next = tail;
// 不组成循环
// header.prev = null;
// tail.next = null;
// 组成循环
header.prev = tail;
tail.next = header;
表尾添加
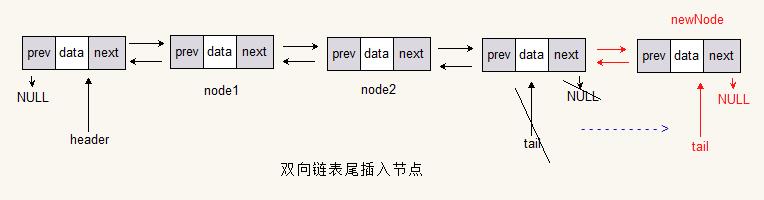
final Node<T> newNode = new Node<>(value);
final Node<T> temp = tail;
tail = newNode;
newNode.prev = temp;
temp.next = newNode;
// 不组成循环
// header.prev = null;
// tail.next = null;
// 组成循环
header.prev = tail;
tail.next = header;
中间添加
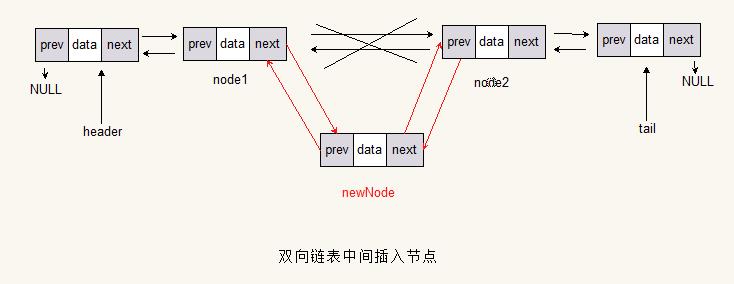
Node<T> nodeByIndex = getNodeByIndex(index);
newNode.prev = nodeByIndex.prev;
newNode.next = nodeByIndex;
nodeByIndex.prev.next = newNode;
nodeByIndex.prev = newNode;
移除节点
移除表头
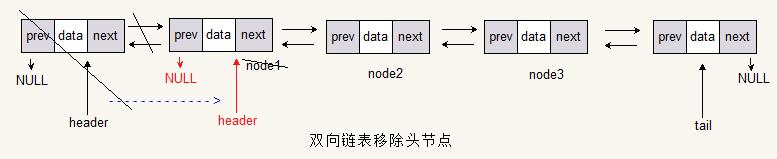
final Node<T> temp = header;
header = header.next;
if (header != null)
// 不组成循环
// header.prev = null;
// tail.next = null;
// 组成循环
header.prev = tail;
tail.next = header;
移除表尾
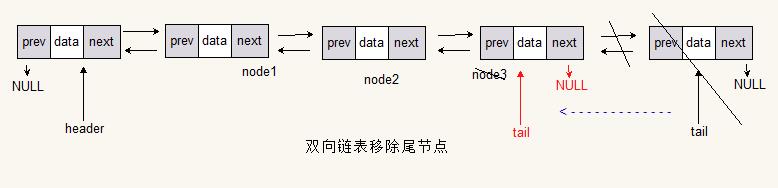
final Node<T> temp = tail;
tail = tail.prev;
if (tail != null)
// 不组成循环
// header.prev = null;
// tail.next = null;
// 组成循环
header.prev = tail;
tail.next = header;
移除中间
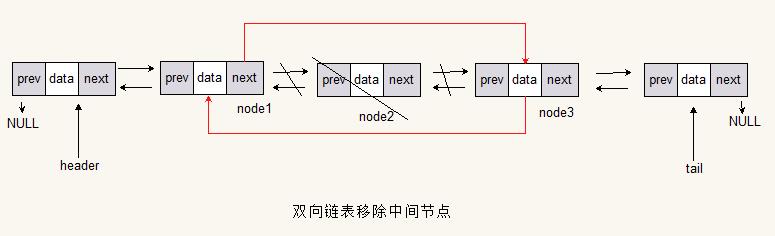
Node<T> nodeByIndex = getNodeByIndex(index);
nodeByIndex.prev.next = nodeByIndex.next;
nodeByIndex.next.prev = nodeByIndex.prev;
根据位置查询数据(节点)
参数index:需要查找的位置
size:表示链表的大小
private Node<T> getNodeByIndex(int index)
if (index < (size >> 1))
Node<T> node = header;
for (int i = 0; i < index; i++)
node = node.next;
return node;
else
Node<T> node = tail;
for (int i = size - 1; i > index; i--)
node = node.prev;
return node;
遍历
这里通过指针移动来直接打印节点数据
public void println()
System.out.println("----------------- 打印链表 ----------------- ");
System.out.println("linked size: " + size);
Node<T> node = header;
for (int i = 0; i < size; i++)
System.out.println(node);
node = node.next;
size:表示链表的大小
单向链表和双向链表的对比
-
删除单链表中的某个结点时,一定要得到待删除结点的前驱,得到该前驱有两种方法,第一种方法是在定位待删除结点的同时一路保存当前结点的前驱。第二种方法是在定位到待删除结点之后,重新从单链表表头开始来定位前驱。但其实这两种方法的效率是一样的,指针的总的移动操作都会有2*i次。而如果用双向链表,则不需要定位前驱结点。因此指针总的移动操作为i次。
-
查找时也一样,我们可以借用二分法的思路,从head(首节点)向后查找操作和last(尾节点)向前查找操作同步进行,这样双链表的效率可以提高一倍。
-
从存储结构来看,每个双链表的节点要比单链表的节点多一个指针,而长度为n就需要 n*length(length表示指针所需要的内存空间大小) 的空间。
完整代码实现及测试(java)
单向链表实现:SingleLinkedList.java
双向链表实现:DoubleLinkedList.java
测试代码:LikedListTest.java
以上是关于数据结构——链表的主要内容,如果未能解决你的问题,请参考以下文章