Impala合并小文件
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Impala合并小文件相关的知识,希望对你有一定的参考价值。
参考技术A set compression_codec=snappy;set parquet_file_size=512M;
create table if not exists xx.xxx_tmp like xx.xxx;
insert overwrite xx.xxx_tmp partition(etl_dt)
select * from xx.xxx where substring(etl_dt,1,7)='2020-02';
--删除指定月的分区数
alter table xx.xxx drop partition(substring(etl_dt,1,7)='2020-02');
--将备份分区数据重新插入
insert into xx.xxx partition(etl_dt)
select * from xx.xxx_tmp;
drop table if exists xx.xxx_tmp;
set parquet_file_size=256M;
https://www.pianshen.com/article/466643134/
如何使用Impala合并小文件
温馨提示:如果使用电脑查看图片不清晰,可以使用手机打开文章单击文中的图片放大查看高清原图。
Fayson的github:
https://github.com/fayson/cdhproject
提示:代码块部分可以左右滑动查看噢
1.文档编写目的
Fayson在前面的文章《》里面介绍了多种处理方式。在Impala表中使用小文件也会降低Impala和HDFS的性能,本篇文章Fayson主要介绍如何使用Impala合并小文件。
内容概述
1.环境准备
2.Impala合并小文件实现
3.验证小文件是否合并
测试环境说明
1.CM5.15.0和CDH5.14.2
2.环境准备
在这里测试Fayson准备了4张表,两个有数据的表ods_user和ods_user_256表,ods_user表的数据量大于Impala默认的Block(256MB)大小,ods_user_256表的数据量小于Impala默认的Block大小。
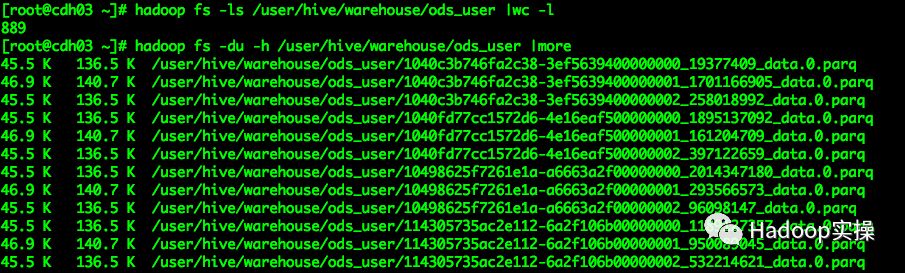
1.准备一个测试表ods_user,该表中有888个小文件,如下截图所示
命令行查看该表下的数据文件:
[root@cdh03 ~]# hadoop fs -ls /user/hive/warehouse/ods_user |wc -l
[root@cdh03 ~]# hadoop fs -du -h /user/hive/warehouse/ods_user |more
(可左右滑动)
2. 准备测试表ods_user_256,该表有7个小文件,如下截图所示:

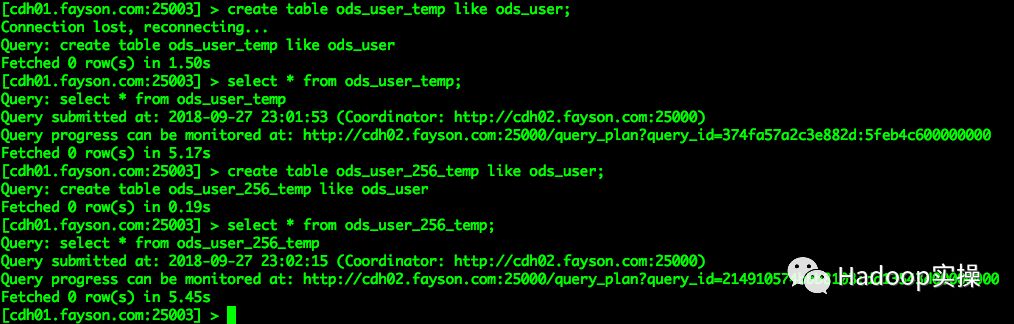
3.使用建表语句创建2个与ods_user表结构一致的表ods_user_temp和ods_user_256_temp
[cdh01.fayson.com:25003] > create table ods_user_temp like ods_user;
[cdh01.fayson.com:25003] > select * from ods_user_temp;
[cdh01.fayson.com:25003] > create table ods_user_256_temp like ods_user;
[cdh01.fayson.com:25003] > select * from ods_user_256_temp;
(可左右滑动)
3.Impala合并小于Impala Block的小文件
1.执行如下脚本将ods_user_256表中的数据写入到ods_user_256_temp表中
[cdh01.fayson.com:25003] > insert overwrite table ods_user_256_temp select * from ods_user_256;
(可左右滑动)

查看ods_user_256_temp表数据文件数量
[root@cdh03 ~]# hadoop fs -du -h /user/hive/warehouse/ods_user_256_temp
(可左右滑动)

上图可以看到文件数量由原表的7个减少到3个但还是生成了多个小文件,这里应该跟Impala节点数有关。
2.将ods_user_256_temp表中的数据再写回ods_user_256表中,注意在这一步Fayson会进行小文件合并操作,具体执行命令如下
[cdh01.fayson.com:25003] > set NUM_NODES=1;
[cdh01.fayson.com:25003] > insert overwrite table ods_user_256 select * from ods_user_256_temp;
(可左右滑动)

在命令行查看ods_user_256表数据文件数量
[root@cdh03 ~]# hadoop fs -du -h /user/hive/warehouse/ods_user_256
(可左右滑动)

由上图可以看到ods_user_256表的文件数量被合并为1个了。
4.Impala合并大于Impala Block的小文件
1.执行如下脚本将ods_user表中的数据写入到ods_user_temp表中
[cdh01.fayson.com:25003] > insert overwrite table ods_user_temp select * from ods_user;
(可左右滑动)

查看ods_user_temp表数据文件数量
[root@cdh03 ~]# hadoop fs -du -h /user/hive/warehouse/ods_user_temp
(可左右滑动)

2.将ods_user_temp表中的数据再写回ods_user表中,注意在这一步Fayson会进行小文件合并操作,具体执行命令如下
[cdh01.fayson.com:25003] > set NUM_NODES=1;
[cdh01.fayson.com:25003] > insert overwrite table ods_user select * from ods_user_temp;
(可左右滑动)

在命令行查看ods_user表数据文件数量
[root@cdh03 ~]# hadoop fs -du -h /user/hive/warehouse/ods_user
(可左右滑动)
由上图可以看到ods_user表生成了多个文件,但每个文件的大小在Impala默认的block大小范围内。
5.总结
1.在设置了NUM_NODES=1后,如果合并的数据量超过Impala默认的Parquet Block Size(256MB)大小时会生成多个文件,每个文件的大小在256MB左右,如果合并的数据量小于256MB则最终只会生成一个文件。
2.通过设置NUM_NODES=1强制Impala使用一个节点Daemon来处理整个Query,因此最终只会输出一个文件到HDFS。
3.在使用该配置项时会引起单个主机的资源利用率增加,导致SQL运行缓慢,超出内存限制或查询挂起等。
4.该参数没办法设置超过1,即无论你有多少台机器,多大数据量,想使用该方法,也只能设置为1,让一台机器来慢慢帮你合并文件,所以该方法不是太实用,仅供参考。
6.备注:NUM_NODES参数说明
该参数用来限制执行查询作业的节点数,常见的场景是用于调试/debug查询的时候。它是一个数值类型,但只有两个值,默认是0即使用所有节点来执行查询,也可以设置为1即所有的查询子任务都会在coordinator节点上个执行。
如果你在调试某个查询作业,怀疑是因为分布式计算才导致的执行时间较长,可以将NUM_NODES设置为1,从而可以校验同样的作业在单个节点上执行时是否问题依旧存在。当然也可以在执行INSERT或者CREATE TABLE AS SELECT加上这个参数的设置来解决小文件的问题,也即是本篇文章正文所分析的内容。
注意:设置该参数会导致单台节点资源使用增加,从而影响集群上别的查询作业比如导致执行缓慢,hang住或者OOM。所以建议在开发/测试环境中使用,或者如果你的生产系统不是太繁忙的时候使用。
提示:代码块部分可以左右滑动查看噢
为天地立心,为生民立命,为往圣继绝学,为万世开太平。
温馨提示:如果使用电脑查看图片不清晰,可以使用手机打开文章单击文中的图片放大查看高清原图。
推荐关注Hadoop实操,第一时间,分享更多Hadoop干货,欢迎转发和分享。
以上是关于Impala合并小文件的主要内容,如果未能解决你的问题,请参考以下文章