如何找出Linux系统高IO的思路总结
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何找出Linux系统高IO的思路总结相关的知识,希望对你有一定的参考价值。
参考技术A 前言I/O Wait是一个需要使用高级的工具来debug问题原因,当然也有许多基本工具的高级用法。I/O wait的问题难以定位的原因是:因为我们有很多工具可以告诉你I/O 受限了,但是并没有告诉你具体是哪个进程引起的。
1. 如何确认,是否是I/O问题导致系统缓慢
确认是否是I/O导致的系统缓慢我们可以使用多个命令,但是,最简单的是unix的命令 top
# top
top - 14:31:20 up 35 min, 4 users, load average: 2.25, 1.74, 1.68
Tasks: 71 total, 1 running, 70 sleeping, 0 stopped, 0 zombie
Cpu(s): 2.3%us, 1.7%sy, 0.0%ni, 0.0%id, 96.0%wa, 0.0%hi, 0.0%si, 0.0%st
Mem: 245440k total, 241004k used, 4436k free, 496k buffers
Swap: 409596k total, 5436k used, 404160k free, 182812k cached
从CPU这行,可以发现CPU的io wait;这里是96.0%。越高就代表CPU用于io wait的资源越多。
2. 找出哪个磁盘正在被写入
上边的top命令从一个整体上说明了I/O wait,但是并没有说明是哪块磁盘影响的,想知道是哪块磁盘引发的问题,可以使用另外一个命令 iostat 命令
$ iostat -x 2 5
avg-cpu: %user %nice %system %iowait %steal %idle
3.66 0.00 47.64 48.69 0.00 0.00
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 44.50 39.27 117.28 29.32 11220.94 13126.70 332.17 65.77 462.79 9.80 2274.71 7.60 111.41
dm-0 0.00 0.00 83.25 9.95 10515.18 4295.29 317.84 57.01 648.54 16.73 5935.79 11.48 107.02
dm-1 0.00 0.00 57.07 40.84 228.27 163.35 8.00 93.84 979.61 13.94 2329.08 10.93 107.02
iostat 会每2秒更新一次,一共打印5次信息, -x 的选项是打印出扩展信息
第一个iostat 报告会打印出系统最后一次启动后的统计信息,这也就是说,在多数情况下,第一个打印出来的信息应该被忽略,剩下的报告,都是基于上一次间隔的时间。举例子来说,这个命令会打印5次,第二次的报告是从第一次报告出来一个后的统计信息,第三次是基于第二次 ,依次类推
所以,一定记住:第一个忽略!
在上面的例子中,sda的%utilized 是111.41%,这个很好的说明了有进程正在写入到sda磁盘中。
除了%utilized 外,我们可以从iostat得到更加丰富的资源信息,例如每毫秒读写请求(rrqm/s & wrqm/s)),每秒读写的((r/s & w/s)。在上边的例子中,我们的项目看起来正在读写非常多的信息。这个对我们查找相应的进程非常有用。
3. 找出导致高IO的进程
# iotop
Total DISK READ: 8.00 M/s | Total DISK WRITE: 20.36 M/s
TID PRIO USER DISK READ DISK WRITE SWAPIN IO> COMMAND
15758 be/4 root 7.99 M/s 8.01 M/s 0.00 % 61.97 % bonnie++ -n 0 -u 0 -r 239 -s 478 -f -b -d /tmp
最简单的方法就是用iotop找出哪个进程用了最多的存储资源,从上面可以看到是bonnie++。
iotop很好用,但是不是默认安装的。
如果没有iotop,下面的方式也可以让你有种方法缩小范围,尽快找到是哪个进程。
ps 命令对内存和CPU有一个统计,但是他没有对磁盘I/O的统计,虽然他没有显示磁盘I/O,但是它显示进行的状态,我们可以用来知道一个进程是否正在等待I/O
主要的进程状态有:
PROCESS STATE CODES
D uninterruptible sleep (usually IO)
R running or runnable (on run queue)
S interruptible sleep (waiting for an event to complete)
T stopped, either by a job control signal or because it is being traced.
W paging (not valid since the 2.6.xx kernel)
X dead (should never be seen)
Z defunct ("zombie") process, terminated but not reaped by its parent.
等待I/O的进程的状态一般是“uninterruptible sleep”,或者“D”,我们可以很容易的查找到正在等待I/O的进程
# for x in `seq 1 1 10`; do ps -eo state,pid,cmd | grep "^D"; echo "----"; sleep 5; done
D 248 [jbd2/dm-0-8]
D 16528 bonnie++ -n 0 -u 0 -r 239 -s 478 -f -b -d /tmp
----
D 22 [kswapd0]
D 16528 bonnie++ -n 0 -u 0 -r 239 -s 478 -f -b -d /tmp
----
D 22 [kswapd0]
D 16528 bonnie++ -n 0 -u 0 -r 239 -s 478 -f -b -d /tmp
----
D 22 [kswapd0]
D 16528 bonnie++ -n 0 -u 0 -r 239 -s 478 -f -b -d /tmp
----
D 16528 bonnie++ -n 0 -u 0 -r 239 -s 478 -f -b -d /tmp
上边的例子会循环的输出状态是D的进程,每5秒一次,一共10次
从输出我们可以知道 bonnie++ 的pid是16528 ,在waiting,bonnie++看起来就是我们想找到的进程,但是,只是从它的状态,我们没有办法证明就是bonnie++引起的I/O等待。
为了证明,我们可以可以查看/proc,每个进程目录下都有一个叫io的文件,里边保存这和iotop类似的信息。
# cat /proc/16528/io
rchar: 48752567
wchar: 549961789
syscr: 5967
syscw: 67138
read_bytes: 49020928
write_bytes: 549961728
cancelled_write_bytes: 0
read_bytes和write_bytes是这个进程从磁盘读写的字节,在这个例子中,bonnie++进程读取了46M的数据并且写入了524MB的数据到磁盘上。
4. 找出哪个文件正在被大量写入
lsof 命令可以展示一个进程打开的所有文件。从这个列表中,我们可以找到哪个文件被写入。
# lsof -p 16528
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
bonnie++ 16528 root cwd DIR 252,0 4096 130597 /tmp
<truncated>
bonnie++ 16528 root 8u REG 252,0 501219328 131869 /tmp/Bonnie.16528
bonnie++ 16528 root 9u REG 252,0 501219328 131869 /tmp/Bonnie.16528
bonnie++ 16528 root 10u REG 252,0 501219328 131869 /tmp/Bonnie.16528
bonnie++ 16528 root 11u REG 252,0 501219328 131869 /tmp/Bonnie.16528
bonnie++ 16528 root 12u REG 252,0 501219328 131869 <strong>/tmp/Bonnie.16528</strong>
# df /tmp
Filesystem 1K-blocks Used Available Use% Mounted on
/dev/mapper/workstation-root 7667140 2628608 4653920 37% /
# pvdisplay
--- Physical volume ---
PV Name /dev/sda5
VG Name workstation
PV Size 7.76 GiB / not usable 2.00 MiB
Allocatable yes
PE Size 4.00 MiB
Total PE 1986
Free PE 8
Allocated PE 1978
PV UUID CLbABb-GcLB-l5z3-TCj3-IOK3-SQ2p-RDPW5S
使用pvdisplay可以看到,pv设备就是/dev/sda5,正是我们前面找到的sda。
参考文档:http://bencane.com/2012/08/06/troubleshooting-high-io-wait-in-linux/
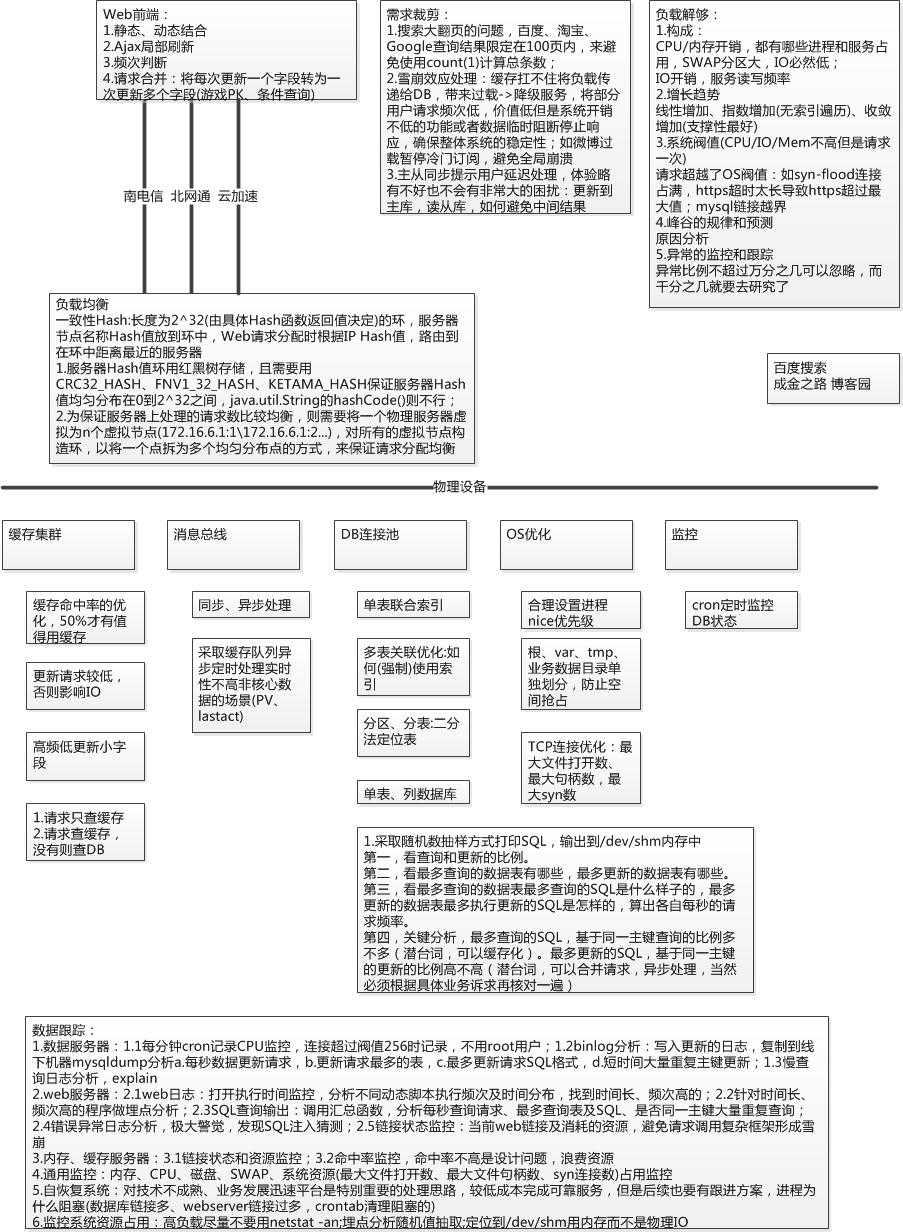
每一个程序员都应该知道的高并发处理技巧创业公司如何解决高并发问题互联网高并发问题解决思路caoz大神多年经验总结分享(转)
出处:http://www.cnblogs.com/uttu/p/6513918.html
本文来源于caoz梦呓公众号高并发专辑,以图形化、松耦合的方式,对互联网高并发问题做了详细解读与分析,“技术在短期内被高估,而在长期中又被低估”,而不同的场景和人员成本又导致了巨头的方案可能并不适合创业公司,那么如何保证高并发问题不成为创业路上的拦路虎,是每一个全栈工程师、资深系统工程师、有理想的程序员必备的技能,希望本文助您寻找属于自己的“成金之路”,发亮发光。
目录:
场景及解决方法解读
认识负载
数据跟踪
脑图、caoz大神公众号分享
参考资料
秉承知其然及其所以然的思路,以拨蝉拔丝的思维,一一解读各个技巧的使用场景:
a.网络通道+前台控制
原因:在当前浮躁社会的大前提下,用户点击一个按钮如果3s内没有反应,基本都会再次刷新,那么因为你网络通道不顺,原本可以正常得到数据,现在却因为延迟造成后台请求量倍增;而当用户因为没有数据而疯狂刷新时,你应该在前台有控制,比如“3秒间隔才能重新点击一个按钮、或者让用户可以疯狂点但是不发送请求(好像360曾经做过这个)”,控制用户不良操作。
方案:后台必须支持双网双通,保证南电信、北网通双边部署,玩过对战游戏的同学,应该都还记得,当初都是分电信专区和网通专区;同时在成本可以接受的范围内,尽量上CDN加速。
b.负载均衡
这个无须多说,但是科普下技术原理,主要难点是环上节点分布均衡与节点处理请求数均衡:
使用一致性Hash,全满状态时是长度为2^32(由Hash函数返回值类型决定)的环,服务器节点按名称Hash值放到环中,Web请求分配时根据IP Hash或者URL Hash值,路由到在环中距离最近的服务器上,进行请求应答。
1.服务器Hash值环用红黑树存储,且需要用CRC32_HASH、FNV1_32_HASH、KETAMA_HASH保证服务器Hash值均匀分布在0到2^32之间,java.util.String的hashCode()则不行;?
2.为保证单台服务器上处理请求数的均衡性,则需要将一个物理服务器虚拟为n个虚拟节点(172.16.6.1:1\\172.16.6.1:2...),对所有的虚拟节点构造环,以将一个实点拆为多个均匀分布代理点的方式,来保证请求分配的均衡性。
c.缓存、数据库、数据总线同步异步处理:
1.缓存
其起源于CPU与Memory Bank数据高速处理,将热数据保存进LRU队列中,提高CPU处理速度;
而此处的缓存则是对数据库中高频、小字段进行缓存,保证50%的命中率才值得缓存IO开销。
2.数据库
i.单表
查询慢时,基本由于过滤条件太多造成,使用联合索引加速过滤。索引使用树形结构,时间复杂度大概为lgN,log(10亿)=9,查询10亿数据只需9次单位操作时间,如果索引使用不上,则得先把所有数据查询出来,然后放到内存里,内存放不下,还得部分存储到磁盘里,最后再进行过滤。
另外,控制单次查询数据条数,从源头上进行流量控制,和地铁限流一个套路;另外,超级大的分页也不用考虑,Google、baidu、taobao搜索结果都没有超过100页的。
ii.多表关联表查询太慢
参见MySQL百万级、千万级数据多表关联SQL语句调优详细的对多表关联的索引使用进行了分析。
iii.海量数据
此业务逻辑只能用单表处理,比如用户表登陆状态表、游戏操作记录表。
另,还可进行分表、分库,这块比较复杂,请自行参考参考资料a。
3.数据总线同步、异步处理:
这里说数据总线,因为目前数据处理基本都是松耦合,以消息驱动,如京东用的kafka、超级灵活性的Rabbitmq、淘宝的metaq:
如果是非核心的非实时性业务,比如排名与PageView数、lastact,可以定时驱动更新缓存队列:对于排名与PageView数,,汇总队列中所有消息,统一更新处理;对于lastact,则取最新的状态,进行更新即可;
同步实时处理时,尽可能的合并操作逻辑,多个操作一条SQL更新(基于同一主键查询、更新的比例多)。
c.从需求层面裁剪
一款好的产品必定让一部分尖叫,另一部分离开的产品;那么在需求层面进行裁剪,以较低的成本满足绝大多数人的使用,是非常合适的。
1.搜索大翻页的问题,百度、淘宝、Google查询结果限定在100页内,来避免使用count(1)计算总条数;
2.雪崩效应处理:缓存扛不住将负载传递给DB,带来过载,可以降级服务,将部分用户请求频次低,价值低但是系统开销不低的功能或者数据临时阻断停止响应,确保整体系统的稳定性;如微博过载暂停冷门订阅,避免全局崩溃;
2.雪崩效应处理:缓存扛不住将负载传递给DB,带来过载,可以降级服务,将部分用户请求频次低,价值低但是系统开销不低的功能或者数据临时阻断停止响应,确保整体系统的稳定性;如微博过载暂停冷门订阅,避免全局崩溃;
3.主从同步提示用户延迟处理,体验略有不好也不会有非常大的困扰:更新到主库,读从库,如何避免中间结果。
解决高并发要有思维宽度,能功能、使用、设计、数据库、缓存、OS各个层面去思考及其解决方法,深入的剖析的各个场景;同时针对高并发也要有一定的技术深度,比如nio、epoll、java.util.concurrent包各类高效锁,具备解决高并发的技术深度;但是离“成金之路”还有两个重要的点——高负载怎么定义及跟踪
a.定义:
1.构成:?CPU/内存开销,都有哪些进程和服务占用,SWAP分区大,IO必然低;?IO开销,服务读写频率;
2.增长趋势?线性增加、指数增加(无索引遍历)、收敛增加(支撑性最好);
3.系统阀值(CPU/IO/Mem不高但是请求一次)请求超越了OS阀值:如syn-flood连接占满,https超时太长导致https超过最大值;mysql链接越界;
4.峰谷的规律和预测?原因分析;
5.异常的监控和跟踪?异常比例不超过万分之几可以忽略,而千分之几就要去研究了。
2.增长趋势?线性增加、指数增加(无索引遍历)、收敛增加(支撑性最好);
3.系统阀值(CPU/IO/Mem不高但是请求一次)请求超越了OS阀值:如syn-flood连接占满,https超时太长导致https超过最大值;mysql链接越界;
4.峰谷的规律和预测?原因分析;
5.异常的监控和跟踪?异常比例不超过万分之几可以忽略,而千分之几就要去研究了。
b.跟踪
1.数据服务器:
1.1每分钟cron记录CPU监控,连接超过阀值256时记录,不用root用户(root用户比普通用户多一个连接,连接占满时用此链接进行排错);
1.2binlog分析:写入更新的日志,复制到线下机器mysqldump分析:每秒数据更新请求、更新请求最多的表、最多更新请求SQL格式、短时间大量重复主键更新;
1.3慢查询日志分析,explain
2.web服务器:
2.1web日志:打开执行时间监控,分析不同动态脚本执行频次及时间分布,找到时间长、频次高的;
2.2针对时间长、频次高的程序做埋点分析;
2.3SQL查询输出:调用汇总函数,分析每秒查询请求、最多查询表及SQL、是否同一主键大量重复查询;
2.4错误异常日志分析,极大警觉,发现SQL注入猜测;
2.5链接状态监控:当前web链接及消耗的资源,避免请求调用复杂框架形成雪崩。
3.内存、缓存服务器:
3.1链接状态和资源监控;
3.2命中率监控,命中率不高是设计问题,浪费资源。
4.通用监控:内存、CPU、磁盘、SWAP、系统资源(最大文件打开数、最大文件句柄数、syn连接数)占用监控。
?5.自恢复系统:对技术不成熟、业务发展迅速平台是特别重要的处理思路,较低成本完成可靠服务,但是后续也要有跟进方案,进程为什么阻塞(数据库链接多、webserver链接过多,crontab清理阻塞的)。
?6.监控系统资源占用:高负载尽量不要用netstat -an;埋点分析随机值抽取;定位到/dev/shm用内存而不是物理IO。
附上总结图片,图形化知识点,加深理解,祝各位走上自己的"成金之路"。
以上是关于如何找出Linux系统高IO的思路总结的主要内容,如果未能解决你的问题,请参考以下文章