NLP方向组会内容整理Pointer Network在文本摘要中的应用
Posted 梆子井欢喜坨
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了NLP方向组会内容整理Pointer Network在文本摘要中的应用相关的知识,希望对你有一定的参考价值。
目录
1. Pointer Network
Pointer Network(Ptr-Nets)是Seq2Seq 的一个变种,于2015年由论文[1]提出,使用注意力机制解决了可变大小输出字典的问题。
1.1 动机
下面由一个具体问题引入:
训练一个Seq2Seq结构计算凸包(Convex Hull),如下图所示:
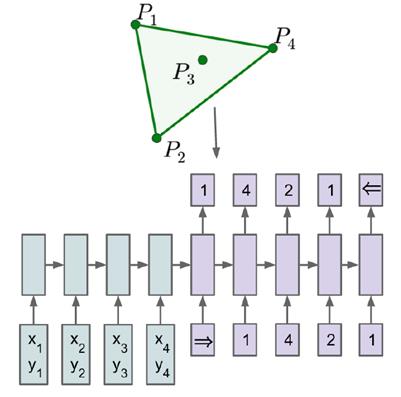
- Encoder输入:所有点的坐标序列
- Decoder输出:一个包围剩下点的组成边界的点序列。
假设下一个时刻的数据为:
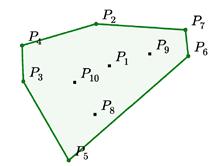
这个问题中,输出的每一步中目标类的数量取决于输入的长度,同时输入长度是可变的。
而原版Seq2Seq输出的概率分布的维度是固定的,因此不能直接将其应用于输出目标的大小取决于输入序列长度的组合问题。
1.2 模型结构
下面来看Pointer Network是如何解决这个问题的。
下面放一张自己做的PPT,文献[2]是最原始的添加了注意力机制的Seq2Seq模型。
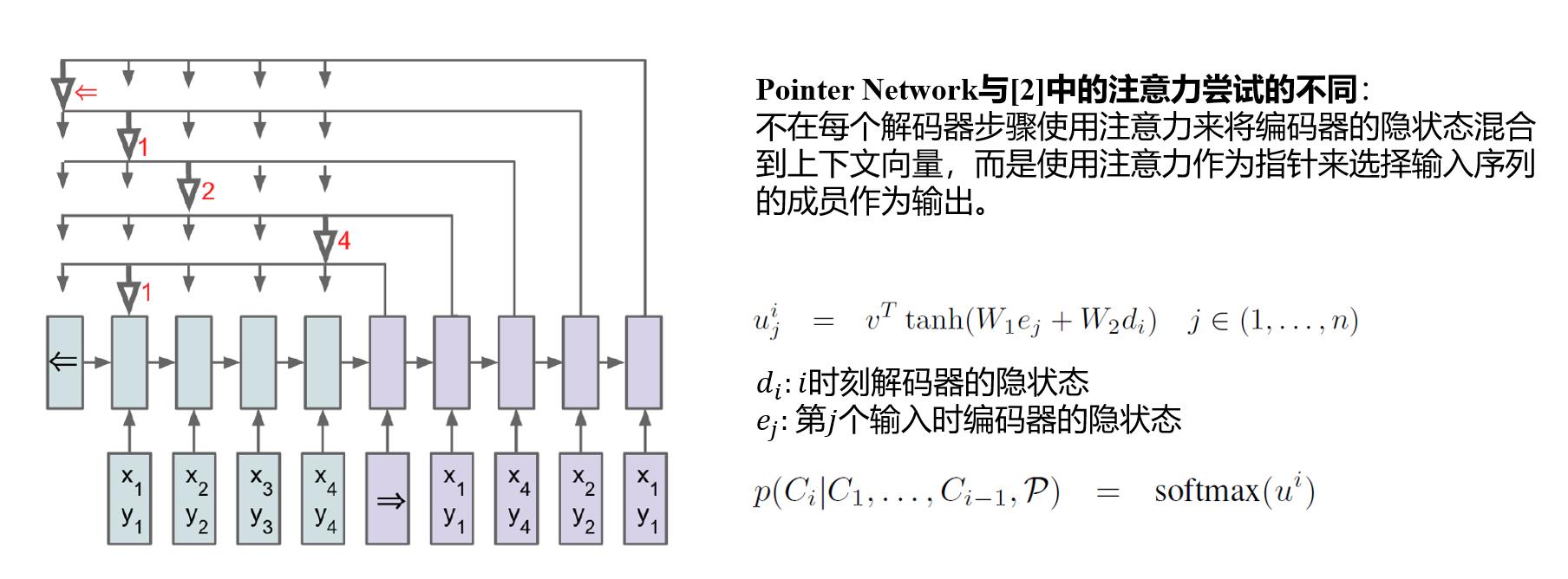
如此一来,输出的词典大小完全取决于输入元素的v数量。
1.3 基本应用
Ptr-Nets可以用来学习一些组合优化问题的近似解
下图中从左到右分别是:
- 寻找平面凸包
- 计算Delaunay三角剖分
- 旅行商问题
基于LSTM的Seq2Seq模型无法处理问题2和3。
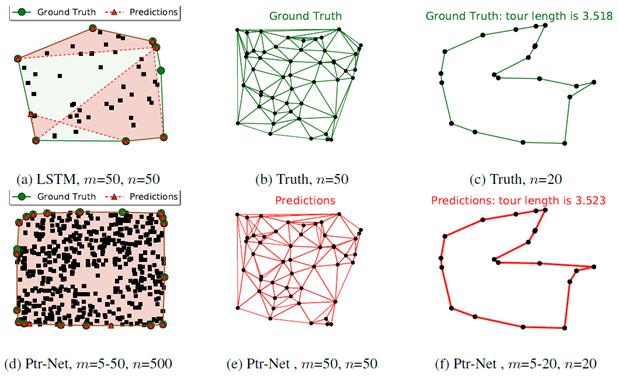
m: 训练集序列长度
n: 测试集序列长度
问题1,3 输入代表点集的序列P = P1, . . . , P10, 输出代表凸包或路径的序列CP= ⇒,2,4,3,5,6,7,2,⇐
问题2 输入代表点集的序列P = P1, . . . , P5, 输出三角形的顶点集合⇒,(1,2,4),(1,4,5),(1,3,5),(1,2,3),⇐
2. Pointer Network用于文本摘要任务
因为输出元素来自输入元素的特点,Pointer Networks适合用来直接复制输入序列中的某些元素给输出序列。

其模型特点适合做抽取式文本摘要。
仅使用 Seq2Seq 来完成生成式摘要存在如下问题:
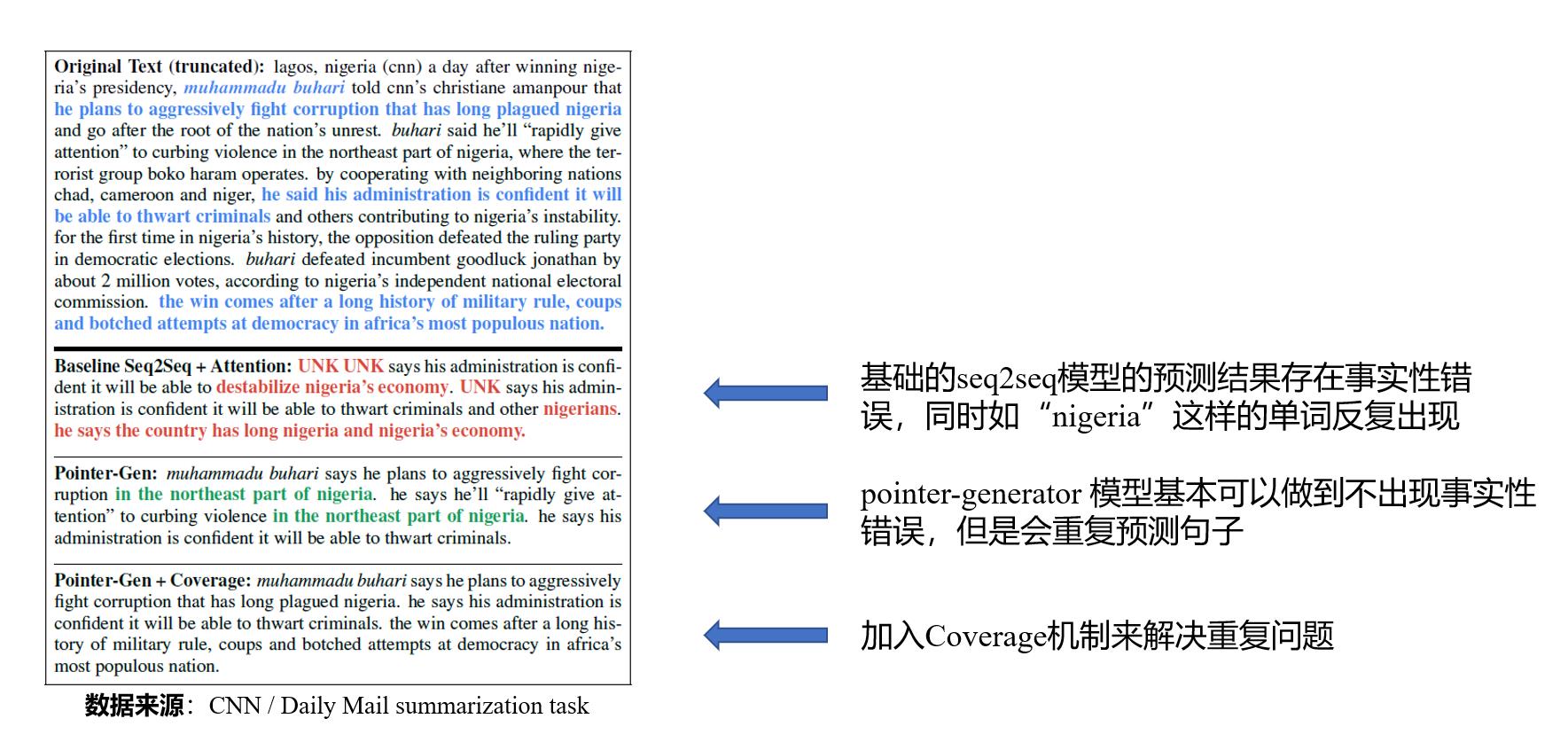
(1)存在事实性错误
(2)生成重复
(3)未登录词问题(OOV, Out Of Vocabulary)
2.1 Get To The Point: Summarization with Pointer-Generator Networks
2016年文献[3]提出的copy-net让模型对文本段中的oov不再束手无策。
2017年,在此基础上,google发布的pointer-generator[4]大大简化了copy机制的过程,同时提出了coverage机制应对生成重复问题。
源码:https://github.com/abisee/pointer-generator
博客:http://www.abigailsee.com/2017/04/16/taming-rnns-for-better-summarization.html
下图是论文给出的一个生成摘要的示例,对比Seq2Seq和论文提出的Pointer-Generator。
pointer-generator的模型结构如下:
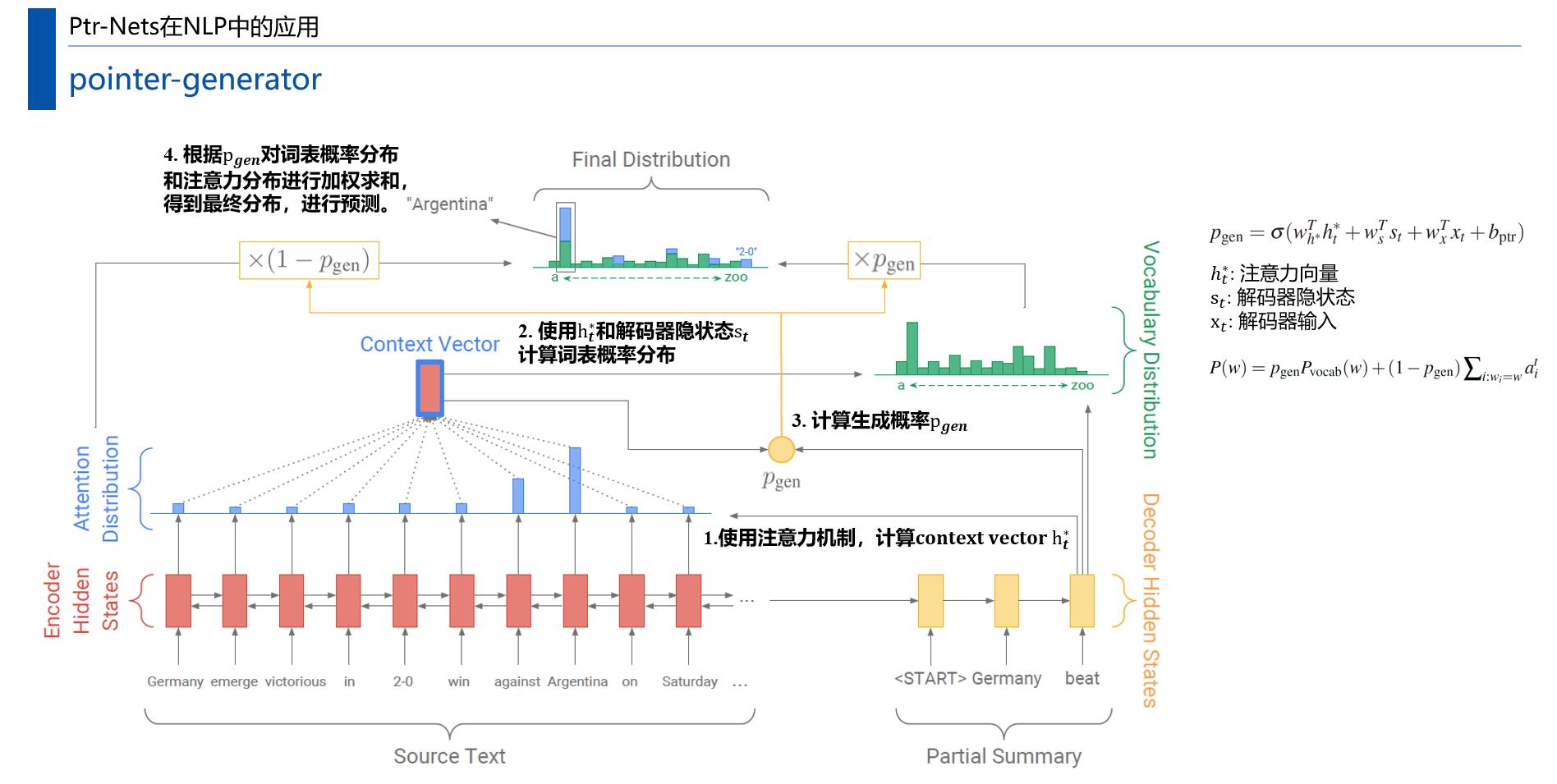
模型为一个标准的Encoder-Decoder结构,主体为基于注意力机制的 Seq2Seq 模型,只是在输出时做了一些文章。
输出概率分布是两个概率分布的叠加,其中用attention作为分布的方法,就源于2015年的pointer-network,此时生成结果必定出现在原文中。所以这种方法可以让模型生成原文中出现的OOV词,另外还可以强化部分词在分布中的概率。另一个概率分布为原版Seq2Seq with attention的输出概率分布。因此需要额外计算一个生成概率 P g e n P_gen Pgen来决定这两个概率分布的占比, P g e n P_gen Pgen越小,从原文中复制单词的概率就越大。
pointer-generator既允许通过指向复制单词(pointer),又允许从固定的词汇中生成单词(generator)。
注意图中的OOV词语 “2-0”也被引入最终分布,产生OOV单词的能力是pointer-generator的主要优势之一。
此外,本文所用的coverage机制指的是用covloss来惩罚重复现象,计算过程如下图所示:
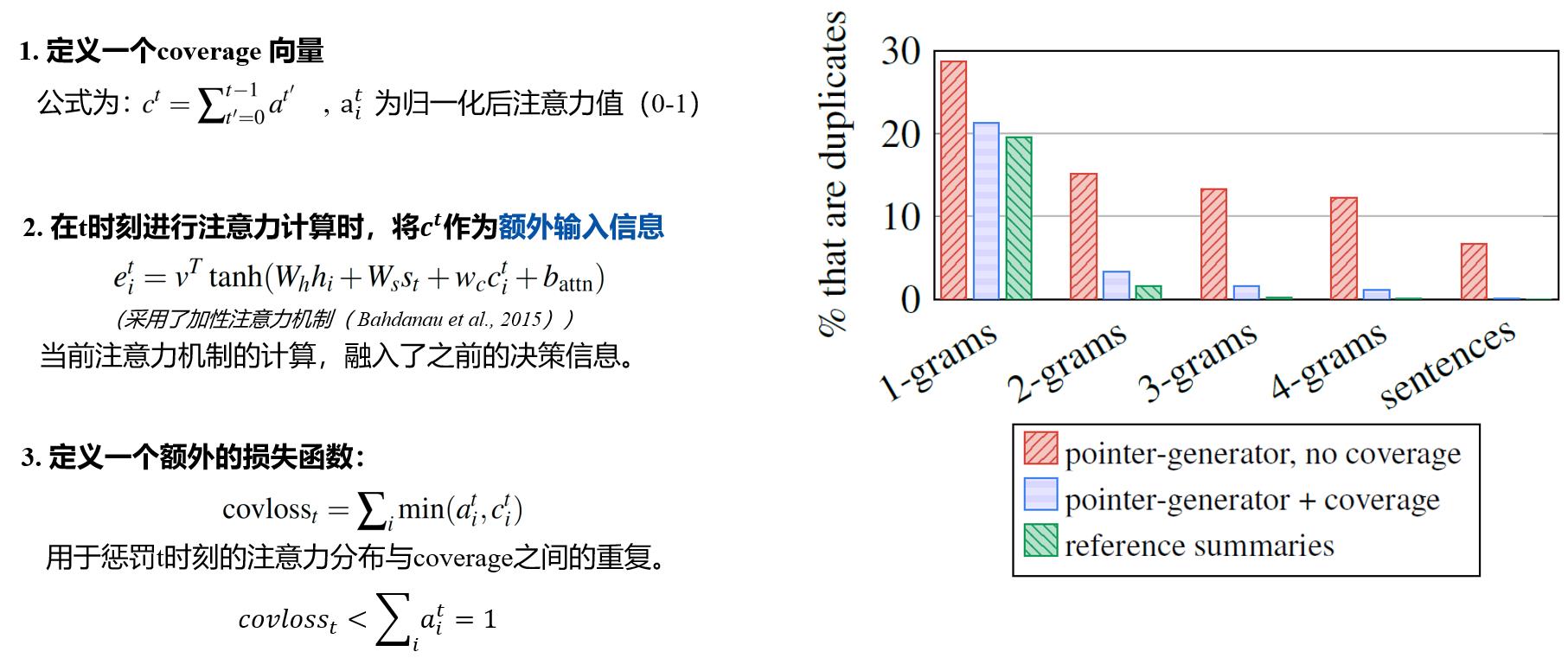
Coverage机制的思想为:
- 每次预测的时候我们都会得到概率分布,这个就反映了模型对源文本各个元素的注意程度(概率越高的部分被认为得到越多的注意力)
- 如果模型在预测时总是注意相同的部分,那么就很有可能会预测出相同的单词,为了防止这种情况发生,我们就强迫模型多去关注之前没被注意过的角落。
- 要让模型能够避免产生重复文本,首先要让它知道过去的信息,见上图中定义的 c t c^t ct。
- 当预测时刻 t t t的单词时,我们就要看在过往的 t − 1 t-1 t−1个时刻中,源文本被关注程度的分布情况如何见上图中计算步骤2。
- c t c^t ct就是之前attention分布的叠加,所以之前的重复位置 i i i会强化向量 c c c的第 i i i维,显然新的注意力分布 a i t a_i^t ait与 c i t c_i^t cit不相似时,covloss比较小,这样,covloss就起到了对重复词的惩罚作用。
数据量有限时,pointer-generator可能比复杂的baseline或开源项目更适合,在此基础上,融合实体知识有更多可以参考的工作,此外结合实体知识后分词和词典整理之类的细节不容忽视。
后续:
基于该框架可以做出一些改进,在 ICLR18 中,Paulus 等人[5],在该框架的基础上又使用解码器注意力机制结合强化学习来完成生成式摘要。
基于上述 Coverage 机制,在 EMNLP18 中,Li 等人[6]基于句子级别的注意力机制,使用句子级别的 Coverage 来使得不同的摘要句可以关注不同的原文,缓解了生成信息重复的问题。
2.2 Multi-source pointer network for product title summarization
对于很多垂直领域,专业知识带来的收益是很大的,模型准确生成一个领域实体词的价值远大于生成流畅的废话。
阿里于2018年发布的这篇论文[6]将Pointer Network用于生成商品描述。
论文信息:
论文来源:CIKM 2018
论文链接:https://dl.acm.org/doi/abs/10.1145/3269206.3271722
论文引用:Sun F, Jiang P, Sun H, et al. Multi-source pointer network for product title summarization[C]//Proceedings of the 27th ACM International Conference on Information and Knowledge Management. 2018: 7-16.
本文研究移动设备上显示的电商APP中的产品标题摘要(product title summarization)问题。
产品标题摘要有两个约束条件:
- 不引入无关信息
- 保留关键信息(如品牌名称和商品名称)

用户在移动设备上使用电子商务软件进行购物的时候,由于移动设备屏幕的限制,往往在列表页无法看到商品的完整名称,为了弄清楚这商品具体是什么不得不点开商品的详细信息页(即使用户还没有决定购买该商品),而这会有损用户体验(如图所示)。那么为了让用户在列表页就准确知道该商品的主要信息,就有必要对较长的商品标题做一个摘要,用短短几个词准确表达商品信息。与传统的句子摘要相比,产品标题摘要有一些额外的和必要的限制。如果短标题包含任何不正确的信息或丢失关键信息是不可容忍的,例如在产品“任天堂Switch”的短标题中产生错误的品牌“索尼”,这是完全不可接受的。
为了解决这些问题,本文提出了一种新的多源指针网络,为指针网络增加了一个新的知识编码器。
- 第一个约束由指针机制(pointer mechanism)处理,通过从源标题中复制单词来生成一个短标题。
- 第二个约束在soft gating 机制的帮助下,通过从知识编码器(knowledge encoder)复制单词来恢复关键信息。知识编码器是一个使用LSTM的RNN encoder,输入的序列为商品名和品牌名。
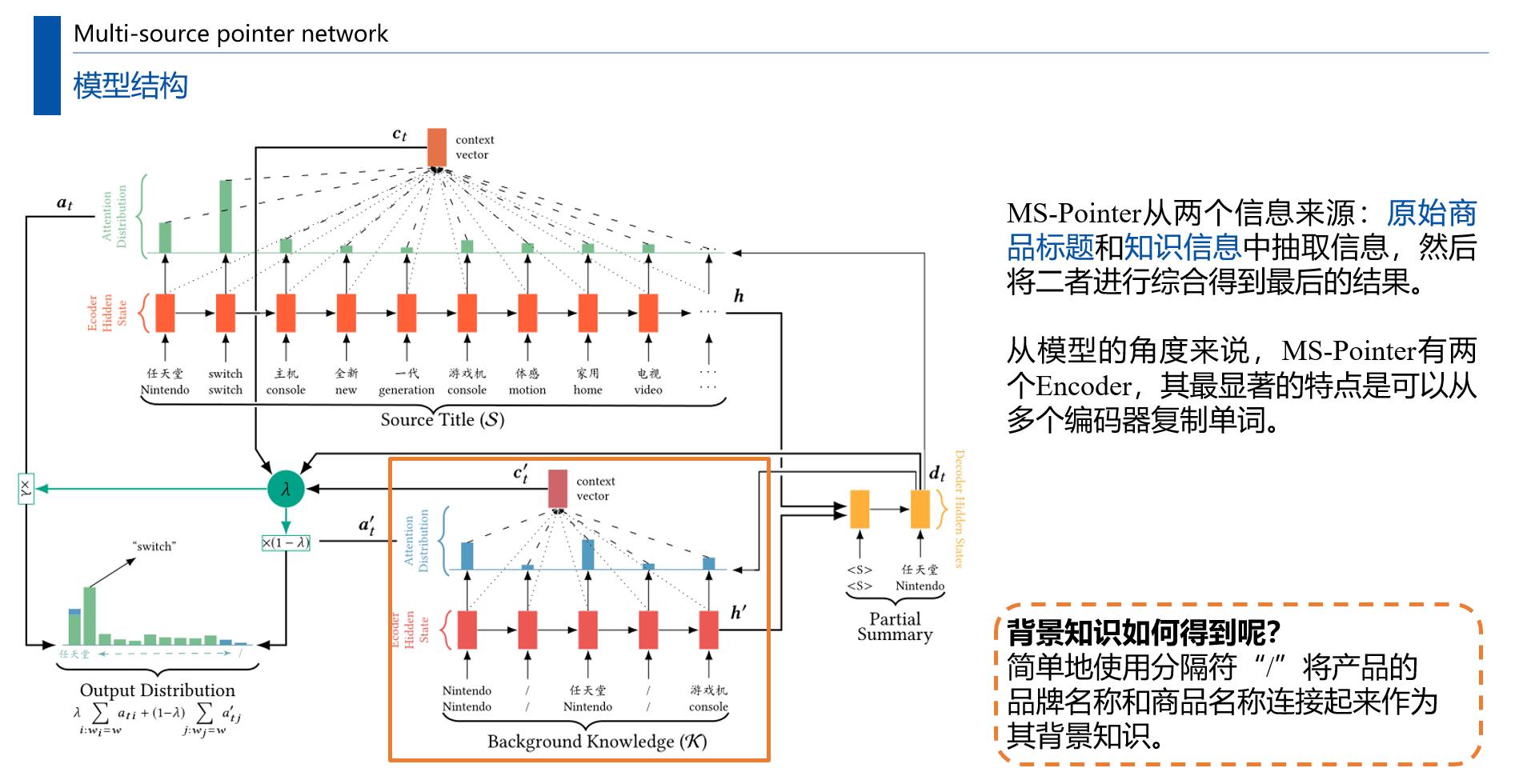
计算过程如下图所示:
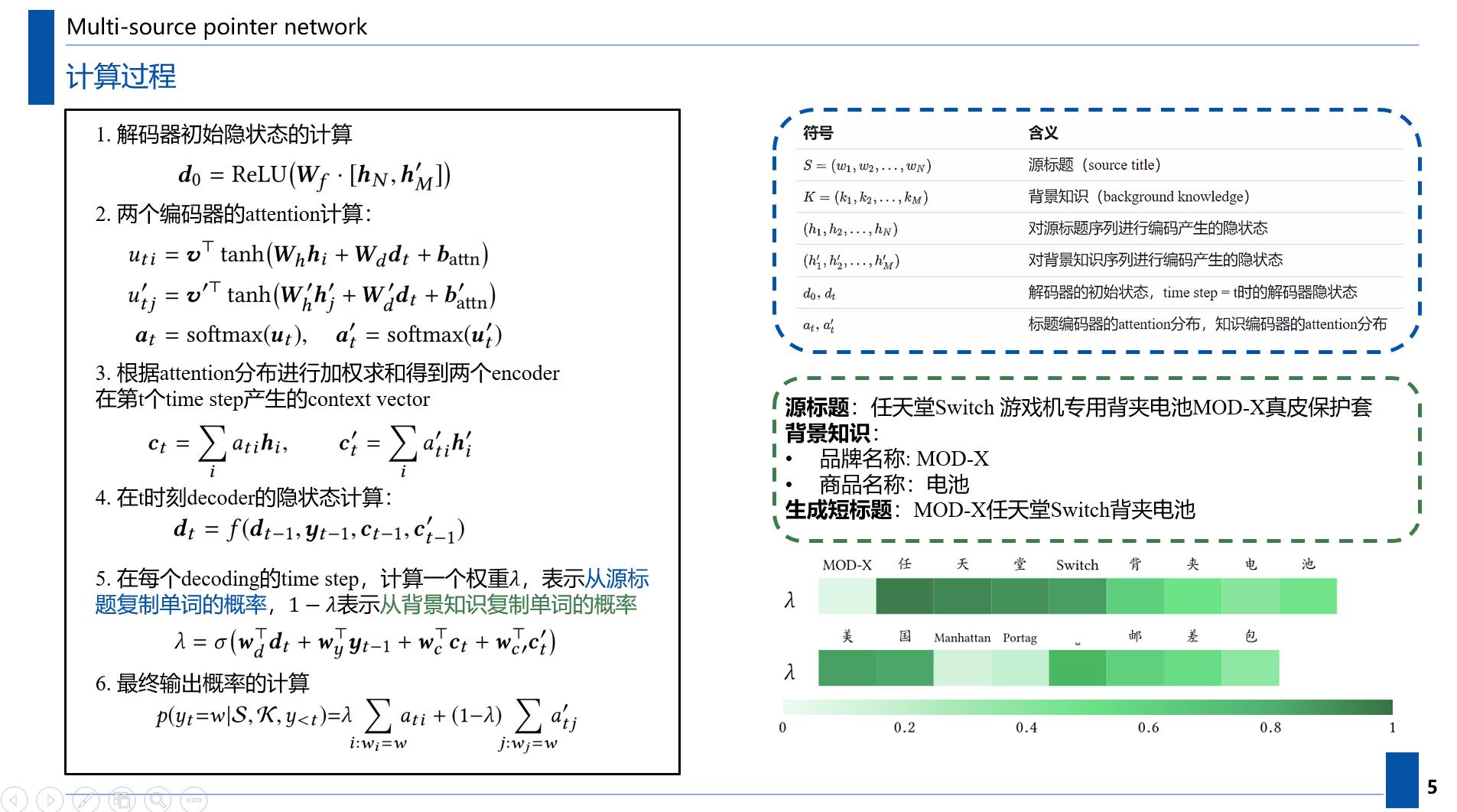
权重λ就像一个分类器,告诉解码器从相应的编码器中提取不同的信息。
- 在最初的几个步骤中,MS-Pointer通常会产生一个较小的λ。这样,我们的模型就可以很容易地从知识编码器中复制品牌名称(如任天堂)。
- 之后λ将变大,以推动模型从标题编码器复制其他(有助于改进标题质量)信息(例如,“运动”或“视频”)。
- 最后λ会再次变小,所以知识编码器可以帮助解码商品信息。
参考文献:
[1] Vinyals O , Fortunato M , Jaitly N . Pointer Networks[J]. Computer Science, 2015, 28.
[2] Bahdanau D , Cho K , Bengio Y . Neural Machine Translation by Jointly Learning to Align and Translate[J]. Computer Science, 2014.
[3] Gu J , Lu Z , Li H , et al. Incorporating Copying Mechanism in Sequence-to-Sequence Learning[C]// Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2016.
[4] See A , Liu P J , CD Manning. Get To The Point: Summarization with Pointer-Generator Networks[C]// Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2017.
[5] Romain Paulus, Caiming Xiong, and Richard Socher. A Deep Reinforced Model for Abstractive Summarization. CoRR, 2017.
[6] Wei Li, Xinyan Xiao, Yajuan Lyu, and Yuanzhuo Wang. Improving neural abstractive document summarization with structural regularization. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 4078–4087, 2018c.
[7] Sun F, Jiang P, Sun H, et al. Multi-source pointer network for product title summarization[C]//Proceedings of the 27th ACM International Conference on Information and Knowledge Management. 2018: 7-16.
参考教程:
塞尔原创|文本摘要综述
知识图谱如何助力文本摘要生成
推荐入门教程:
李宏毅机器学习2020:Pointer Network
视频地址
笔记
以上是关于NLP方向组会内容整理Pointer Network在文本摘要中的应用的主要内容,如果未能解决你的问题,请参考以下文章