云原生训练营模块五 Kubernetes 控制平面组件:etcd
Posted 果子哥丶
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了云原生训练营模块五 Kubernetes 控制平面组件:etcd相关的知识,希望对你有一定的参考价值。
etcd
- ----------Part1----------
- etcd概述
- etcd功能与场景
- 服务注册与发现,消息发布与订阅
- Etcd的安装
- etcd工具练习
- Raft协议
- ❤etcd基于Raft的一致性
- ----------Part2----------
- etcd v3 存储,Watch以及过期机制
- 灾备
- Alarm & Disarm Alarm
- 碎片整理
- 课后练习
- 高可用etcd解决方案
- K8s如何使用etcd
- etcd备份
- etcd优化 与 etcd常见问题
----------Part1----------
etcd概述
Etcd是CoreOS基于Raft开发的分布式key-value存储,可用于服务发现、共享配置以及一致性保障(如数据库选主、分布式锁等)。
在分布式系统中,如何管理节点间的状态一直是一个难题,etcd像是专门为集群环境的服务发现和注册而设计,它提供了数据TTL失效、数据改变监视、多值、目录监听、分布式锁原子操作等功能,可以方便的跟踪并管理集群节点的状态。
- 键值对存储:将数据存储在分层组织的目录中,如同在标准文件系统中
- 监测变更:监测特定的键或目录以进行更改,并对值的更改做出反应
- 简单: curl可访问的用户的API(HTTP+JSON)
- 安全: 可选的SSL客户端证书认证
- 快速: 单实例每秒1000次写操作,2000+次读操作
- 可靠: 使用Raft算法保证一致性
etcd功能与场景
功能
- 基本的key-value存储
- 监听机制
- key的过期及续约机制,用于监控和服务发现
- 原子Compare And Swap和Compare And Delete,用于分布式锁和leader选举
使用场景
- 可以用于键值对存储,应用程序可以读取和写入 etcd 中的数据
- etcd 比较多的应用场景是用于服务注册与发现
- 基于监听机制的分布式异步系统
键值对存储
etcd 是一个键值存储的组件,其他的应用都是基于其键值存储的功能展开。
- 采用kv型数据存储,一般情况下比关系型数据库快。
- 支持动态存储(内存)以及静态存储(磁盘)。
- 分布式存储,可集成为多节点集群。
- 存储方式,采用类似目录结构。(B+tree)
- 只有叶子节点才能真正存储数据,相当于文件。
- 叶子节点的父节点一定是目录,目录不能存储数据。
服务注册与发现,消息发布与订阅
服务注册与发现
- 强一致性、高可用的服务存储目录。
- 基于 Raft 算法的 etcd 天生就是这样一个强一致性、高可用的服务存储目录。
- 一种注册服务和服务健康状况的机制。
- 用户可以在 etcd 中注册服务,并且对注册的服务配置 key TTL,定时保持服务的心跳以达
到监控健康状态的效果。
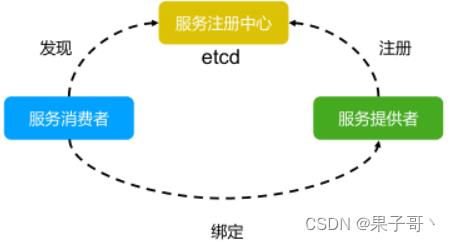
- 用户可以在 etcd 中注册服务,并且对注册的服务配置 key TTL,定时保持服务的心跳以达
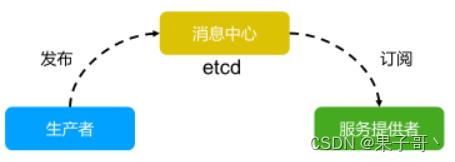
消息发布与订阅
- 在分布式系统中,最适用的一种组件间通信方式就是消息发布与订阅。
- 即构建一个配置共享中心,数据提供者在这个配置中心发布消息,而消息使用者则订阅他们关心的主题,一旦主题有消息发布,就会实时通知订阅者。
- 通过这种方式可以做到分布式系统配置的集中式管理与动态更新。
- 应用中用到的一些配置信息放到etcd上进行集中管理。
- 应用在启动的时候主动从etcd获取一次配置信息,同时,在etcd节点上注册一个Watcher并等待,以后每次配置有更新的时候,etcd都会实时通知订阅者,以此达到获取最新配置信息的目的。
Etcd的安装
下载安装包, 参考 https://github.com/etcd-io/etcd/releases
ETCD_VER=v3.4.17
DOWNLOAD_URL=https://github.com/etcd-io/etcd/releases/download
rm -f /tmp/etcd-$ETCD_VER-linux-amd64.tar.gz
rm -rf /tmp/etcd-download-test && mkdir -p /tmp/etcd-download-test
curl -L $DOWNLOAD_URL/$ETCD_VER/etcd-$ETCD_VER-linux-amd64.tar.gz -o /tmp/etcd-$ETCD_VER-
linux-amd64.tar.gz
tar xzvf /tmp/etcd-$ETCD_VER-linux-amd64.tar.gz -C /tmp/etcd-download-test --strip-components=1
rm -f /tmp/etcd-$ETCD_VER-linux-amd64.tar.gz
更多信息
https://github.com/cncamp/101/blob/master/module5/1.etcd-member-list.MD
etcd工具练习
目前有很多支持etcd的库和客户端工具
- 命令行客户端工具etcdctl
- Go客户端go-etcd
- Java客户端jetcd
- Python客户端python-etcd
查看集群成员状态
etcdctl member list --write-out=table
基本的数据读写数据
- 写入数据
etcdctl --endpoints=localhost:12379 put /a b - 读取数据
etcdctl --endpoints=localhost:12379 get /a - 按key的前缀查询数据
etcdctl --endpoints=localhost:12379 get --prefix / - 只显示键值
etcdctl --endpoints=localhost:12379 get --prefix / --keys-only --debug
TTL(time to live) 指的是给一个key设置一个有效期,到期后这个key就会被自动删掉,这在很多分布式锁的实现上都会用到,可以保证锁的实时有效性。
Atomic Compare-and-Swap(CAS) 指的是在对key进行赋值的时候,客户端需要提供一些条件,当这些条件满足后,才能赋值成功。这些条件包括:
- prevExist:key当前赋值前是否存在
- prevValue:key当前赋值前的值
- prevIndex:key当前赋值前的Index
这样的话,key的设置是有前提的,需要知道这个key当前的具体情况才可以对其设置。
Raft协议
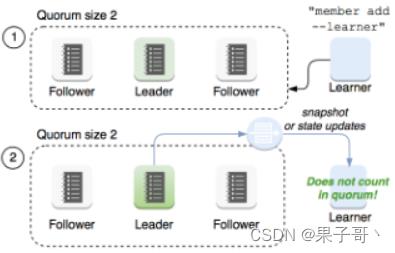
Raft协议基于quorum机制,即大多数同意原则,任何的变更都需超过半数的成员确认

learner(只接收数据,不参与投票,当数据同步的时候会成为flower,现在默认新节点加入的其实就是learner)
- 当出现一个etcd集群需要增加节点时,新节点与Leader的数据差异较大,需要较多数据同步才能跟上leader的最新的数据。
- 此时Leader的网络带宽很可能被用尽,进而使得
leader无法正常保持心跳。 - 进而导致follower重新发起投票。
- 进而可能引发etcd集群不可用。
因此有了Learner
Learner角色只接收数据而不参与投票,因此增加learner节点时,集群的quorum不变。
❤etcd基于Raft的一致性
选举方法
- 初始启动时,节点处于follower状态并被设定一个election timeout,如果在这一时间周期内没有收到来自 leader 的 heartbeat,节点将发起选举:将自己切换为 candidate 之后,向集群中其它 follower节点发送请求,询问其是否选举自己成为 leader。
- 当收到来自集群中过半数节点的接受投票后,节点即成为 leader,开始接收保存 client 的数据并向其它的 follower 节点同步日志。如果没有达成一致,则candidate随机选择一个等待间隔(150ms ~ 300ms)再次发起投票,得到集群中半数以上follower接受的candidate将成为leader
- leader节点依靠定时向 follower 发送heartbeat来保持其地位。
- 任何时候如果其它 follower 在 election timeout 期间都没有收到来自 leader 的 heartbeat,同样会将自己的状态切换为 candidate 并发起选举。每成功选举一次,新 leader 的任期(Term)都会比之前leader 的任期大1
日志复制
当接Leader收到客户端的日志(事务请求)后先把该日志追加到本地的Log中,然后通过heartbeat把该Entry同步给其他Follower,Follower接收到日志后记录日志然后向Leader发送ACK,当Leader收到大多数(n/2+1)Follower的ACK信息后将该日志设置为已提交并追加到本地磁盘中,通知客户端并在下heartbeat中Leader将通知所有的Follower将该日志存储在自己的本地磁盘中。
安全性
- 安全性是用于保证每个节点都执行相同序列的安全机制,如当某个Follower在当前Leader commit Log时变得不可用了,稍后可能该Follower又会被选举为Leader,这时新Leader可能会用新的Log覆盖先前已committed的Log,这就是导致节点执行不同序列;Safety就是用于保证选举出来的Leader一定包含先前 committed Log的机制;
- 选举安全性(Election Safety):每个任期(Term)只能选举出一个Leader
- Leader完整性(Leader Completeness):指Leader日志的完整性,当Log在任期Term1被Commit后,那么以后任期Term2、Term3…等的Leader必须包含该Log;Raft在选举阶段就使用Term的判断用于保证完整性:当请求投票的该Candidate的Term较大或Term相同Index更大则投票,否则拒绝该请求。
失效处理
- Leader失效:其他没有收到heartbeat的节点会发起新的选举,而当Leader恢复后由于步进
数小会自动成为follower(日志也会被新leader的日志覆盖)
2)follower节点不可用:follower 节点不可用的情况相对容易解决。因为集群中的日志内容始
终是从 leader 节点同步的,只要这一节点再次加入集群时重新从 leader 节点处复制日志即可。
3)多个candidate:冲突后candidate将随机选择一个等待间隔(150ms ~ 300ms)再次发起
投票,得到集群中半数以上follower接受的candidate将成为leader
wal日志
wal日志是二进制的,解析出来后是以上数据结构LogEntry。
- 第一个字段type,主要有两种,一种是0表示Normal,1表示ConfChange(ConfChange表示 Etcd 本身的配置变更同步,比如有新的节点加入等)。
- 第二个字段是term,每个term代表一个主节点的任期,每次主节点变更term就会变化。
- 第三个字段是index,这个序号是严格有序递增的,代表变更序号。
- 第四个字段是二进制的data,将raft request对象的pb结构整个保存下。etcd 源码下有个tools/etcd-
dump-logs,可以将wal日志dump成文本查看,可以协助分析Raft协议。
Raft协议本身不关心应用数据,也就是data中的部分,一致性都通过同步wal日志来实现,每个节点将从主节点收到的data apply到本地的存储,Raft只关心日志的同步状态,如果本地存储实现的有bug,比如没有正确的将data apply到本地,也可能会导致数据不一致。

----------Part2----------
etcd v3 存储,Watch以及过期机制
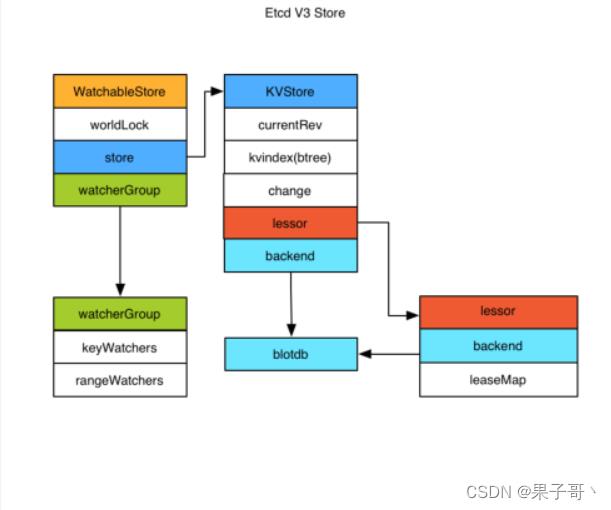
存储机制
etcd v3 store 分为两部分,一部分是内存中的索引,kvindex,是基于Google开源的一个Golang的btree实现的,另外一部分是后端存储。按照它的设计,backend可以对接多种存储,当前使用的boltdb。boltdb是一个单机的支持事务的kv存储,etcd 的事务是基于boltdb的事务实现的。etcd 在boltdb中存储的key是reversion版本号信息,value是 etcd 自己的key-value组合,也就是说 etcd 会在boltdb中把每个版本都保存下,从而实现了多版本机制。
reversion主要由两部分组成,第一部分main rev,每次事务进行加一,第二部分sub rev,同一个事务中的每次操作加一。
etcd 提供了命令和设置选项来控制compact,同时支持put操作的参数来精确控制某个key的历史版本数。
内存kvindex保存的就是key和reversion之间的映射关系,用来加速查询。
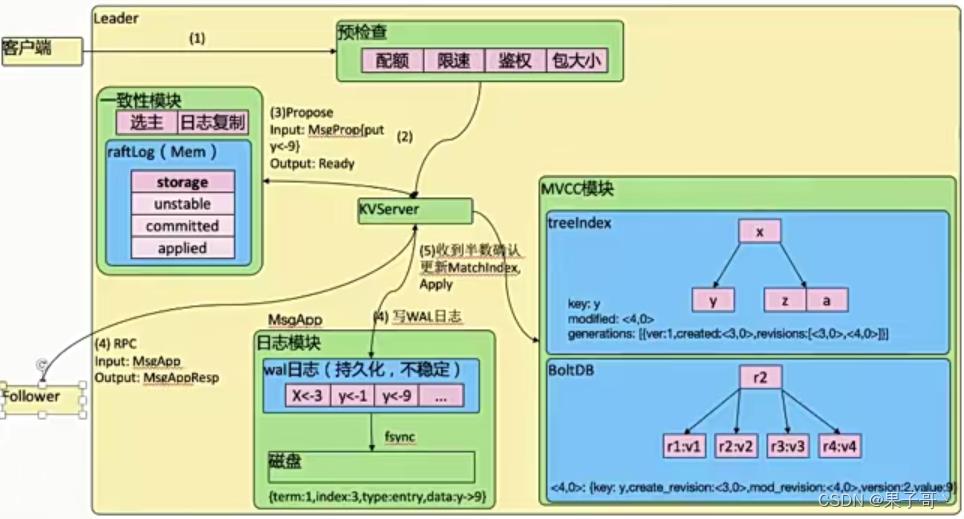
- commit操作是在第五步。
- 超过半树写好walog日志持久化后,就会把raftLog状态从unstable些到committed,会发起状态机写入,确认appl最终态。
- MVCC模块中的treeindex存在于内存和boltDB存在于磁盘。
Watch机制
根据数据结构划分:
etcd v3 的watch机制支持watch某个固定的key,也支持watch一个范围(可以用于模拟目录的结构的watch),所以 watchGroup 包含两种watcher,一种是 key watchers,数据结构是每个key对应一组watcher,另外一种是 range watchers, 数据结构是一个IntervalTree,方便通过区间查找到对应的watcher。
根据数据是否同步:
同时,每个 WatchableStore 包含两种 watcherGroup(根据数据是否同步分为两种),一种是synced,一种是unsynced,前者表示该group的watcher数据都已经同步完毕,在等待新的变更,后者表示该group的watcher数据同步落后于当前最新变更,还在追赶。
当 etcd 收到客户端的watch请求,如果请求携带了revision参数,则比较请求的revision和store当前的revision,如果大于当前revision,则放入synced组中,否则放入unsynced组。同时 etcd 会启动一个后台的goroutine持续同步unsynced的watcher,然后将其迁移到synced组。也就是这种机制下,etcd v3 支持从任意版本开始watch,没有v2的1000条历史event表限制的问题(当然这是指没有compact的情况下)
etcd练习
查看集群成员状态
etcdctl member list --write-out=table
启动新etcd集群
docker run -d registry.aliyuncs.com/google_containers/etcd:3.5.0-0 /usr/local/bin/etcd
进入etcd容器
docker ps|grep etcd
docker exec –it <containerid> sh
存入数据
etcdctl put x 0
读取数据
etcdctl get x -w=json
"header":"cluster_id":14841639068965178418,"member_id":10276657743932975437,"revision":2,"raft_term":2,"kvs":["key":"eA==","create_revision":2,"mod_revision":2,"version":1,"value":"MA=="],"count":1
修改值
etcdctl put x 1
查询最新值
etcdctl get x
x
1
查询历史版本值
etcdctl get x --rev=2
x
0
etcd重要参数
etcd 成员重要参数
成员相关参数
--name 'default'
Human-readable name for this member.
--data-dir '$name.etcd'
Path to the data directory.
--listen-peer-urls 'http://localhost:2380'
List of URLs to listen on for peer traffic.
--listen-client-urls 'http://localhost:2379'
List of URLs to listen on for client traffic.
etcd集群重要参数
集群相关参数
--initial-advertise-peer-urls 'http://localhost:2380'
List of this member's peer URLs to advertise to the rest of the cluster.
--initial-cluster 'default=http://localhost:2380'
Initial cluster configuration for bootstrapping.
--initial-cluster-state 'new'
Initial cluster state ('new' or 'existing').
--initial-cluster-token 'etcd-cluster'
Initial cluster token for the etcd cluster during bootstrap.
--advertise-client-urls 'http://localhost:2379'
List of this member's client URLs to advertise to the public.
etcd安全相关参数
--cert-file ''
Path to the client server TLS cert file.
--key-file ''
Path to the client server TLS key file.
--client-crl-file ''
Path to the client certificate revocation list file.
--trusted-ca-file ''
Path to the client server TLS trusted CA cert file.
--peer-cert-file ''
Path to the peer server TLS cert file.
--peer-key-file ''
Path to the peer server TLS key file.
--peer-trusted-ca-file ''
Path to the peer server TLS trusted CA file.
灾备
创建Snapshot
etcdctl --endpoints https://127.0.0.1:3379 --cert /tmp/etcd-certs/certs/127.0.0.1.pem --
key /tmp/etcd-certs/certs/127.0.0.1-key.pem --cacert /tmp/etcd-certs/certs/ca.pem
snapshot save snapshot.db
恢复数据
etcdctl snapshot restore snapshot.db \\
--name infra2 \\
--data-dir=/tmp/etcd/infra2 \\
--initial-cluster
infra0=http://127.0.0.1:3380,infra1=http://127.0.0.1:4380,infra2=http://127.0.0.1:5380 \\
--initial-cluster-token etcd-cluster-1 \\
--initial-advertise-peer-urls http://127.0.0.1:5380
Alarm & Disarm Alarm
设置etcd存储大小
$ etcd --quota-backend-bytes=$((16*1024*1024))
写爆磁盘
$ while [ 1 ]; do dd if=/dev/urandom bs=1024 count=1024 | ETCDCTL_API=3 etcdctl put key
|| break; done
查看endpoint状态
$ ETCDCTL_API=3 etcdctl --write-out=table endpoint status
查看alarm
$ ETCDCTL_API=3 etcdctl alarm list
清理碎片
$ ETCDCTL_API=3 etcdctl defrag
清理alarm
$ ETCDCTL_API=3 etcdctl alarm disarm
碎片整理
# keep one hour of history
$ etcd --auto-compaction-retention=1
# compact up to revision 3
$ etcdctl compact 3
$ etcdctl defrag
Finished defragmenting etcd member[127.0.0.1:2379]
课后练习
- 在本地构建一个单节点的基于HTTPS的etcd集群
- 写一条数据 put
- 查看数据细节 get
- 删除数据 del
高可用etcd解决方案
etcd-operator: coreos开源的,基于kubernetes CRD完成etcd集群配置。Archived
https://github.com/coreos/etcd-operator

基于 Bitnami 安装etcd高可用集群
安装helm
https://github.com/helm/helm/releases
通过helm安装etcd
helm repo add bitnami https://charts.bitnami.com/bitnami
helm install my-release bitnami/etcd
通过客户端与serve交互
kubectl run my-release-etcd-client --restart='Never' --image
docker.io/bitnami/etcd:3.5.0-debian-10-r94 --env ROOT_PASSWORD=$(kubectl get
secret --namespace default my-release-etcd -o jsonpath=".data.etcd-root-password" |
base64 --decode) --env ETCDCTL_ENDPOINTS="my-release-
etcd.default.svc.cluster.local:2379" --namespace default --command -- sleep infinity
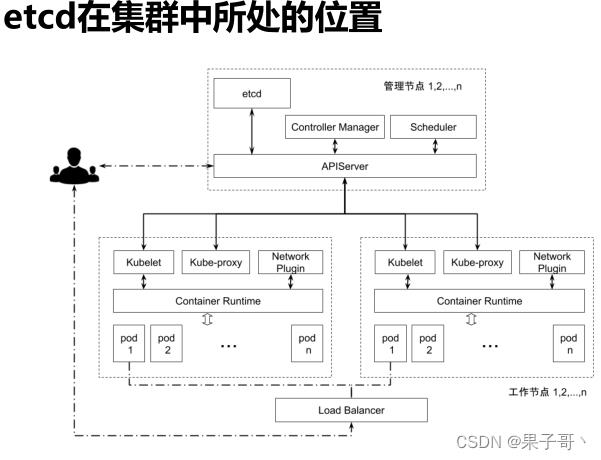
K8s如何使用etcd
etcd是kubernetes的后端存储
对于每一个kubernetes Object,都有对应的storage.go 负责对象的存储操作
- pkg/registry/core/pod/storage/storage.go
API server 启动脚本中指定etcd servers集群
spec:
containers:
- command:
- kube-apiserver
- --advertise-address=192.168.34.2
- --enable-bootstrap-token-auth=true
- --etcd-cafile=/etc/kubernetes/pki/etcd/ca.crt
- --etcd-certfile=/etc/kubernetes/pki/apiserver-etcd-client.crt
- --etcd-keyfile=/etc/kubernetes/pki/apiserver-etcd-client.key
- --etcd-servers=https://127.0.0.1:2379
早期API server 对etcd做简单的Ping check,现在已经改为真实的etcd api call
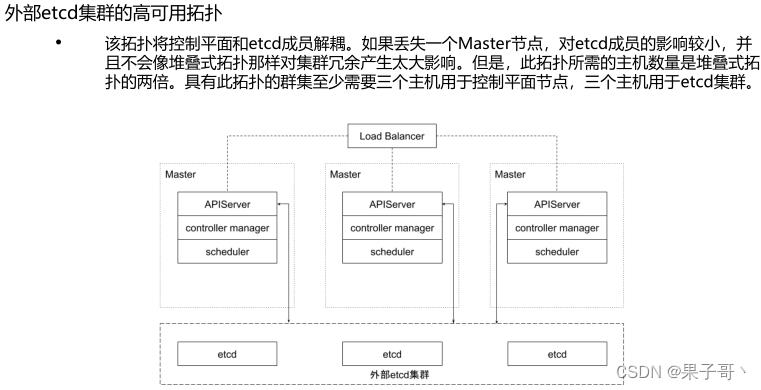
堆叠式:

外部etcd:
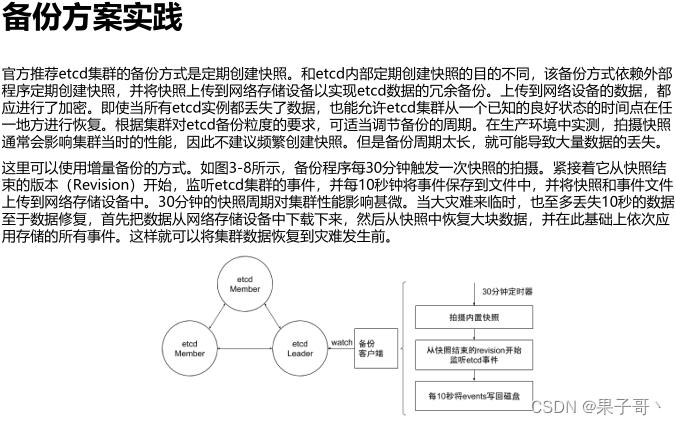
etcd备份
etcd的默认工作目录下会生成两个子目录:wal和snap。wal是用于存放预写式日志,其最大的作用是记录整个数据变化的全部历程。所有数据的修改在提交前,都要先写入wal中。
snap是用于存放快照数据。为防止wal文件过多,etcd会定期(当wal中数据超过10000条记录时,由参数“–snapshot-count”设置)创建快照。当快照生成后,wal中数据就可以被删除了。
如果数据遭到破坏或错误修改需要回滚到之前某个状态时,方法就有两个:一是从快照中恢复数据主体,但是未被拍入快照的数据会丢失;二是执行所有WAL中记录的修改操作,从最原始的数据恢复到数据损坏之前的状态,但恢复的时间较长。
etcd优化 与 etcd常见问题
链接:https://pan.baidu.com/s/1Ph2-CD4qIbczLvNyT-KSrg
提取码:eehj
以上是关于云原生训练营模块五 Kubernetes 控制平面组件:etcd的主要内容,如果未能解决你的问题,请参考以下文章