(2021-3-13)ElasticSearch学习之基本原理概述
Posted Mr. Dreamer Z
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了(2021-3-13)ElasticSearch学习之基本原理概述相关的知识,希望对你有一定的参考价值。
Elastic search概念详解
这段时间学习了ES,准备开始搞一下系统的学习一些中间件以及数据库和系统方面的知识。自己租了一个服务器,从ES开始系统的学习。ok,话不多说,开始今天的正题。
elastic search简称ES,很多小伙伴都不会陌生。但是由于可能只有特定的系统才会使用到。所以大家只是有一个简单的印象,不是很详细的了解它。这段时间,就让我们一起来学习ES。在今天的文章中,我们会简单的对es进行一个介绍,包括它是什么,它的结构,以及它的工作原理
1.什么是ES
ES是一个分布式的索引引擎。通常用关系型数据库mysql或者oracle由于数据量庞大无法满足高效率的搜索条件时,通常都会将数据存入ES来进行高效的搜索。
1.1 ES的优点
1.1.1 接近实时
ES是一个近乎于实时的搜索平台
1.1.2 高度的可伸缩性
可以搭建大型的分布式集群,处理PB级的数据服务于大公司,也可以运行在单机上,服务于小公司
1.1.3 开箱即用、搭建简单
搭建一个ES环境很简单,简单的配置就可以进行使用了
1.1.4 和数据库互补
数据库的功能面对很多领域是不够用的(事务,还有各种联机事务型的操作);特殊的功能,比如全文检索,同义词处理等。这些都是ES可以支持的。
1.2 ES中数据的结构
ES其实就是一个索引库。在这里举一个不恰当的例子,来让大家能够快速的理解。但是注意,是不恰当的,出去面试的时候介绍的时候,一定要加上不恰当这三个字。
在介绍之前,我想先给大家说一下对应版本的改动。现目前6版本应该是大家使用的比较多的。
在面试的时候,有的面试官问的ES的时候会问:5版本之前和之后的区别是什么?
注意:在5版本及之前,一个索引中可以定义多个类型。6版本也可以使用,但是不推荐。在7-8版本中会彻底删除一个索引可以创建多个类型的规则。
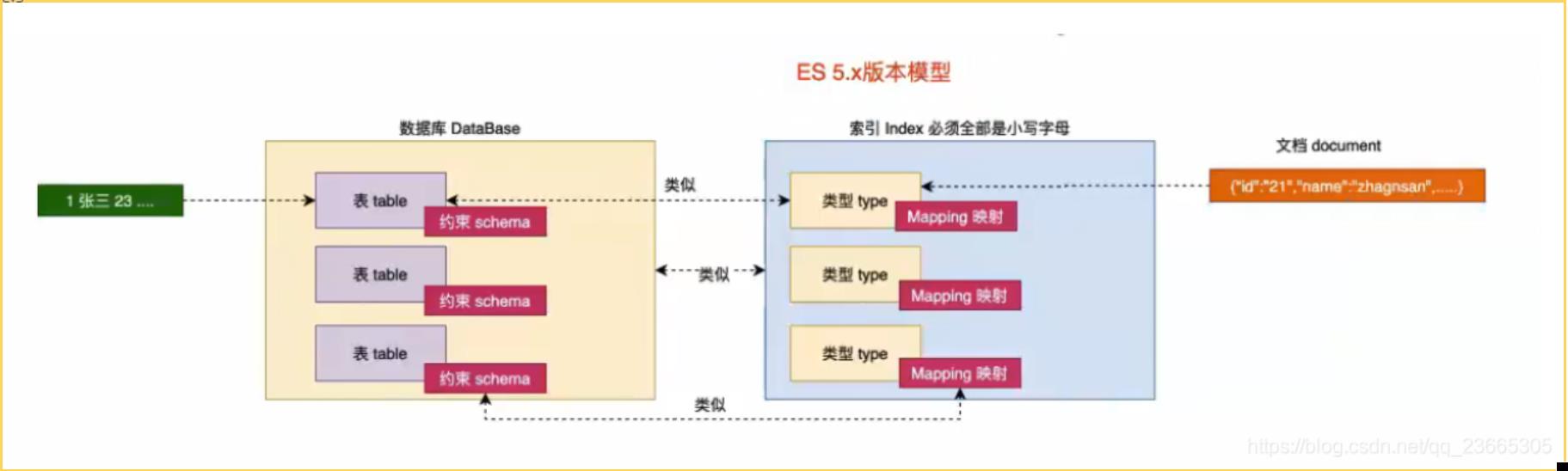
1.2.1 索引 index
一个拥有几分相似特征的文档集合,命名必须是小写且唯一。类似于关系型数据库的database
1.2.2 类型 type
类似于关系型数据库中table,一个索引可以有多个类型(5版本)

1.2.3 映射 mapping
mapping是es中一个很重要的内容,它类似于传统的关系型数据中的table中的字段(schema),用于定义一个索引(index)中的类型(type)的数据的结构。mapping主要包括字段名,字段数据类型和字段索引类型
1.2.4 文档 document
一个文档是一个可被索引的基础信息单元,类似于表中的一条记录。是一个json
1.3 ES索引的组成
先上图
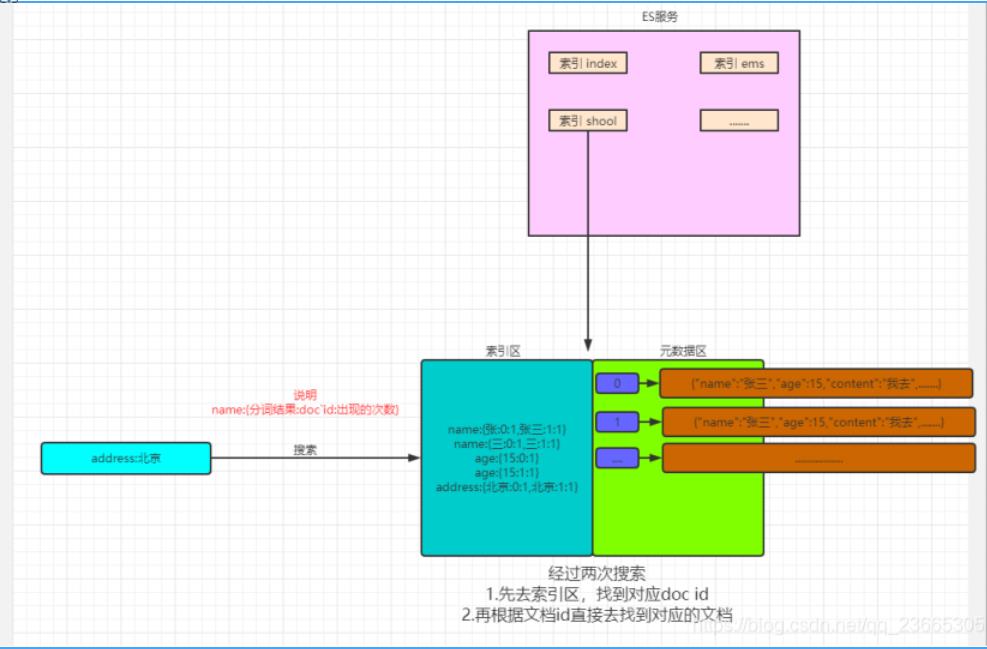
ES的索引的数据结构是由索引区和元数据区组成
1.3.1 索引区
在这里先介绍一下ES默认的标准分词器strandard。
简单介绍一下ES的数据类型:keyword,date,integer,long,double,boolean,text. 在这些数据类型中,只有text会进行分词。刚才我们也说了ES默认的标准分词器,它会把英文的单词作为基础进行分词,比如:content:redis is good --> redis 和 is 和 good 都会变成单个的词汇进行存放。但是它对于中文就是不友好的了,比如:content:redis是很好 --> redis 和 【是】 和【很】 和 【好】 都会变成单个词汇进行存放。这就会导致你在搜索的时候,只能通过单个汉字进行搜素,进行组合汉字词汇就搜不到(很好—ES就找不到)。 当然,今天只是暂时提一句,后面的博客我会详细的进行说明!!!!
回到正题:
比如说你创建了一个json存放入es,如上图:“name”:“张三”,“age”:15,“content”:“我去”,…。它会先将该数据放入元数据区,然后会生成一个唯一的文档id和这个条数据进行关联。然后进行分词,这里name的类型是text的。所以,会在索引区,将name属性的相关信息存入。
name:“分词之后的数据”:该条数据对应的文档id:在name中出现的次数—这个地方可能需要多看几遍,先记下来,后面再通过理解加深印象然后掌握。
ES进行查找操作:
搜索address属性值为“北京”的记录。
流程:
1.现在索引区找到对应的文档id
2.然后再通过文档id在元数据区找到对应的数据。
3.找到之后进行匹配度计算然后返回
2.倒排索引
在聊到ES的时候,不可避免的会提及倒排索引这一词汇。那什么是倒排索引呢?
众所周知的是,索引的初衷都是为了快速检索到你要的数据。
既然有倒排索引,那么肯定就有正排索引。
2.1 什么是正排索引
正排索引(正向索引),简而言之,就是用key查询val的过程。
比如:在两个网页中,有很多关键词。如果是正向索引那么可能是这样的情况
doc1: hello world you and me
doc2: hi, world, how are you
由此可见,它组成的索引结构。文档和单词的关系。
如果此时你又要通过关键词去搜索的话,并且关键词有成千上万个。那么就会造成大量的资源浪费。那么此时想通过文档id去搜索就是无稽之谈,通通需要走一遍全片搜索。效率可想而知,此时就是推出了倒排索引。
2.2 什么是倒排索引
刚刚我们了解了一下正排索引,现在进入正题。
既然正排索引是通过key去找val,那么倒排索引自然是通过val去找key了。
word doc1 doc2
hello 1,2 4
world 3 7,8
...........................................
单词和文档的关系。
如上图展示,我们在索引海量数据时,很大程度上会通过关键词搜索。比如:搜索 “我要挣钱”。有人这时候可能会问了,那么我用mysql等关系型数据库,然后加索引不是一样的吗? 请仔细想想,如果搜索姓名,且你知道完整姓名时,索引自然会生效。但是如果你只知道姓名的后两位亦或是你搜索的关键词只是在这个字段中的一部分
name content
张二狗 我要挣钱,我不服输
那么由于mysql的一些查询原则和规范,极有可能导致索引失效,从而进行全文检索。
这时候,倒排索引的优点就显示出来了。分词之后,建立单词和文档的关联关系。通过搜索单词,得到对应的文档id,然后得到文档内容。就如同上面我们讲的es索引的结构一样。
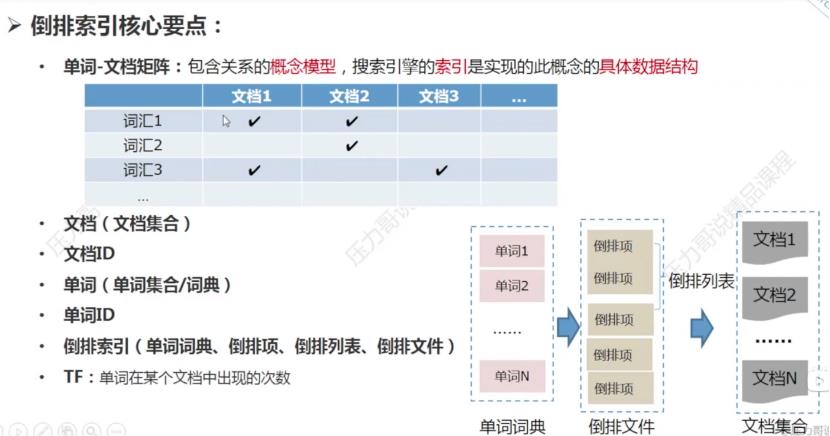
如上图所示,倒排索引的核心就是:单词-文档矩阵(这是一个概念模型)。拆分来说,它就是单词词典+倒排项组成。
倒排项中有【文档id,出现位置,出现次数】这类信息。
多个单词组成单词词典,多个倒排项组成倒排文件,多个倒排文件组成倒排列表,组成文档集合。
以上是关于(2021-3-13)ElasticSearch学习之基本原理概述的主要内容,如果未能解决你的问题,请参考以下文章