一短文带你快速入门Node.js 基础及内置模块
Posted 我是真的不会前端
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一短文带你快速入门Node.js 基础及内置模块相关的知识,希望对你有一定的参考价值。
1.什么是Node.js
Node.js 是一个开源与跨平台的javascript运行时环境。与2009年发布。它是在浏览器外运行,它是一个事件驱动异步I/O单进程的服务端JS环境,基于Google的V8引擎,V8引擎执行Javascript的速度非常快,性能非常好。
*一句话概括就是:用js这个语言写后端
相关网址
- https://nodejs.org/zh-cn/
- http://nodejs.cn/
注意:
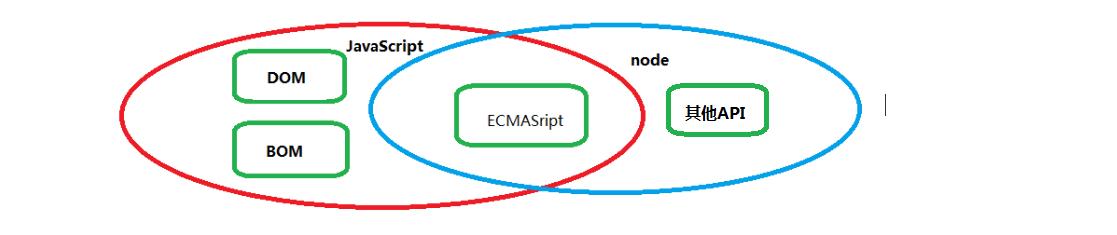
- nodejs实现了js代码在浏览器外执行,所以在nodejs中无法运行DOM和BOM的代码
- nodejs中除了ECMAScript代码外,还内置了很多其他API
- nodejs让js在写前端代码的基础上,可以写后端代码,因为nodejs可以构建服务器
原生js和node之间关系
模块化开发
nodejs开发基于CommonJS模块化开发规范,将一个js文件定义为一个模块。在项目开发中,能单独拆分的功能,就单独拆分成一个模块。
CommonJS模块化规范的导入导出:
// 导入
require(被导入的文件路径)
// 导出
module.exports = 数据
module.exports.键 = 值
exports.键 = 值
2.Node.js内置模块
os模块
os(operation system)模块提供了与操作系统相关的实用方法和属性。
const os = require(‘os’)
// 换行符
os.EOL //根据操作系统生成对应的换行符 window \\r\\n,linux下面 \\n
// cpu相关信息
os.cpus()
// 总内存大小 (单位 字节)
os.totalmem()
// 空余内存大小 (单位 字节)
os.freemem()
// 主机名
os.hostname()
// 系统类型
os.type()
path模块
path模块用于处理文件和目录(文件夹)的路径。
const path = require(‘path’)
获取路径最后一部内容,一般用它来获取文件名称
path.basename(‘c:/a/b/c/d.html’) // d.html
获取目录名,路径最后分隔符部分被忽略
path.dirname(‘c:/a/b/c/d.html’) // c:/a/b/c
获取路径中文件扩展名(后缀)
path.extname(‘c:/a/b/c/d.html’) // .html
给定的路径连接在一起
path.join(’/a’, ‘b’, ‘c’) // /a/b/c
resolve:模拟cd(切换目录)操作同时拼接路径
console.log(path.resolve(“a”, “b”, “c”));
console.log(path.resolve(“a”, “…/b”, “c”));
console.log(path.resolve("/a", “b”, “c”));
__dirname:是nodejs提供的一个内置变量,代表当前文件所在位置的绝对路径
斜杠和反斜杠:通常用来分割路径,"某个文件夹下"的意思,在windows系统中,斜杠和反斜杠的意义是一样的,但是建议大家写斜杠,反斜杠用在代码中,有特殊含义,转义的意思,在服务器系统中,默认路径就使用斜杠
补充:URL的概念
url的完整形态:
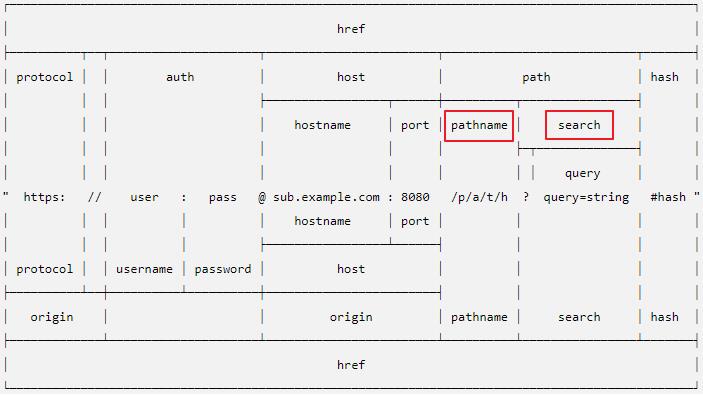
URL字符串是结构化的字符串,包含多个含义不同的组成部分。 解析字符串后返回的 URL 对象,每个属性对应字符串的各个组成部分。
完整形态的url:协议 + 用户名密码 + 主机名 + 端口号 + 请求路径 + 参数 + hash值(锚点)
协议默认会跟端口号相对应:
http - 80
https - 443
ftp - 21
sftp - 22
mysql - 3306
请求路径后的参数,参数和请求路径之间由 ? 隔开的 参数由键值对组成,键和值之间使用 = 隔开 键值对之间使用 & 隔开
const url = require('url');
const href = 'http://www.xxx.com:8080/pathname?id=100#bbb'
// 解析网址,返回Url对象
// 参2 如果为true 则 query获取得到的为对象形式
url.parse(href,true)
resolve
以一种 Web 浏览器解析超链接的方式把一个目标 URL 解析成相对于一个基础 URL。
以服务器路径的规则进行拼接
url.resolve('https://lynnn.cn/foo/bar',../'bar') // https://lynnn.cn/bar
parse()
解析url,返回的是一个对象。对象中包含url组成的每一部分
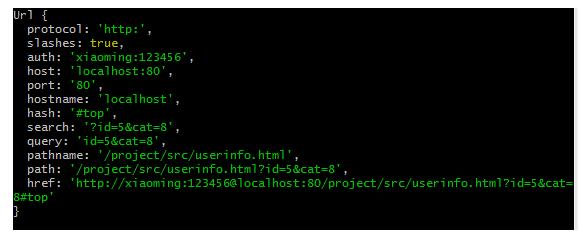
const url = require('url')
let href = "http://xiaoming:123456@localhost:80/project/src/userinfo.html?id=5&cat=8#top";
let obj = url.parse(href)
// obj.query是我们比较常用的,因为我们经常会解析路径中的数据
console.log(obj);
加第二个参数true:就能将url中的参数解析成对象
querystring
用于解析和格式化 URL 查询字符串(URL地址的get形式传参)的实用工具。
const querystring = require('querystring')
let href = "http://localhost/a/b/c.html?id=6&cat=8";
const url = require('url')
// 将href中的参数解析出来
let query = url.parse(href).query
console.log(query);
结果

query字符串转为对象
querystring.parse('foo=bar&abc=xyz')
querystring.decode('foo=bar&abc=xyz')
// 对象转为query字符串
querystring.stringify( foo: ‘bar’,abc: ‘xyz’)
querystring.encode( foo: ‘bar’,abc: ‘xyz’)
解析对象和字符串
parse()/decode()
const querystring = require('querystring')
let href = "http://localhost/a/b/c.html?id=6&cat=8";
const url = require('url')
let query = url.parse(href).query
let obj = querystring.decode(query) // 将字符串转为对象
console.log(obj);
结果

将字符串解析成对象
stringify()/encode()
let obj =
name:"张三",
age:20,
sex:"男"
// 将url中参数部分转换成一个对象
// // 可以将对象转成url的参数形式 - querystring paramters
let str = querystring.stringify(obj)
console.log(str);
结果

let str = querystring.encode(obj)
console.log(str);
结果
FileSystem
fs(file system)模块提供了用于与文件进行交互相关方法。
异步读取 readFile()
const fs = require('fs')
// 异步读取
fs.readFile('test.txt',(err,data)=>
if(err)
console.log("读取失败,错误:"+err);
return;
// console.log(data); // 默认读取出来的是buffer数据
console.log(data.toString());
)
同步读取 readFileSync()
同步 检查文件是否存在 返回true/false
async:异步
sync:同步
同步读取
let data = fs.readFileSync('test.txt')
console.log(data.toString());
console.log(123);
异步写入 writeFile()
// 异步写入
fs.writeFile('test.txt','abcdef',err=>
if(err)
console.log("写入失败,错误:"+err);
return
console.log("写入成功");
)
同步写入 writeFileSync()
fs.writeFileSync('test.txt','asdfasdf')
console.log("写入成功");
console.log(123);
appendFile()
上面的写入方式是覆盖写入,如果要追加而不覆盖 - appendFile
fs.appendFile('./test.txt','123456',err=>
if(err)
console.log("追加失败,错误是:"+err);
return
console.log("追加成功");
)
console.log(123);
同步追加
fs.appendFileSync('test.txt','abcdef')
console.log("追加成功");
console.log(123);
let bool = fs.existsSync('c.js') // 判断文件是否存在的 - 返回布尔值
console.log(bool);
stat()
fs.stat(文件,(err,stats) =>
stats.isDirectory() // 是否是目录
stats.isFile() // 是否为文件
stats.size // 文件大小(以字节为单位)
)
示例
fs.stat('test.txt',(err,info)=>
// err如果存在,就说明获取文件信息失败
if(err)
console.log("获取失败,错误是:"+err);
return
console.log(info); // info就是获取到的文件信息
console.log(info.isDirectory()); // 判断这是否是一个目录 - 返回布尔值
console.log( info.isFile() ); // 判断这是否是一个文件 - 返回布尔值
console.log(info.size); // 文件大小 - 字节数
)
文件删除(异步)
文件删除
fs.unlink('test.txt',err=>
if(err)
console.log("删除失败");
return
console.log("删除成功");
)
流形式:
流形式读取最大的好处就是异步的
流式写入,如果是大文件,内容较多,例如视频等就需要流式写入,防止内存卡死
var fs=require("fs");
// 读取流模式
var stream=fs.createReadStream("E:\\\\test\\\\test10\\\\server\\\\config.json");
var data="";
stream.on("data",function(_data)
data+=_data;
);
stream.on("end",function()
console.log(data);
)
var streamWriter = fs.createWriteStream('c:\\\\demo\\a.txt');
setInterval(function()
streamWriter.write(`$new Date\\n`, (error) =>
console.log(error);
);
,1000)
// 流形式读取并写入
const fs = require('fs')
const readstream = fs.createReadStream('./note.txt');
readstream.pipe(fs.createWriteStream('./note2.txt'));
监视文件变化
let num = 0
// 监视文件变化
fs.watch('test.txt',()=>
console.log(++num);
)
显示结果

一点一点输出buffer数据
什么是Buffer
buufer是处理二进制字节的一种方式,常用于TCP流、文件系统操作等场景。
解析excel
依赖插件:node-xlsx
安装: npm i node-xlsx -g
const nodeXlsx = require('node-xlsx')
console.log(nodeXlsx.default);
let de = nodeXlsx.default;
let data = de.parse("./test.xls") // 解析excel文件的方法 - 参数1是excel的文件路径
console.log(data);
console.log(data[0].data);
data是一个数组,默认是3个,分别代表sheet1 sheet2 sheet3
每个数组中都有一个对象:name每个sheet的名称,data是一个数组
data这个数组,代表表格中每一行数据
读取

结果
写入
let bu = nodeXlsx.build; // 这个方法是用来创建数据buffer的
let data = [
name:"语文成绩",
data:[
["","语文"],
['张三',20],
['李四',30]
]
,
name:"籍贯表",
data:[
["姓名","籍贯"],
['张三','扬州'],
['李四','南京']
]
,
name:"数学成几个",
data:[
["姓名","成绩"],
['王五',80],
['赵六',90]
]
];
let buffer = bu(data) // 得到buffer数据
require('fs').writeFileSync('aaa.xlsx',buffer)
crypto
/项目中,我们的密码是需要进行加密的 - md5加密是定向的,不可逆的,不能被解密的,但是容易被暴力破解 - 将一些常用字符的组合加密,做成一本字典,从中进行查询
const crypto = require('crypto')
查看所以的加密方式
console.log( crypto.getHashes() );
设置加密的hash方式
const md5 = crypto.createHash('md5')
加密
md5.update('123456')
输出加密结果 - 2进制、16进制
let result = md5.digest("hex")
let result = md5.digest("oct")
console.log(result);
http服务器
服务器介绍
Web服务器一般指的是网站服务器(服务器:给用户提供服务的机器就是服务器),是指驻留因特网上某一台或N台计算机的程序,可以处理浏览器等Web客户端的请求并返回相应响应,在服务器上还需要安装服务器软件,目前最主流的三个Web服务器软件是Apache、 Nginx 、IIS。
创建服务器
// 导入http模块
const http = require('http')
// 创建web服务对象实例
const server = http.createServer()
// 绑定监听客户端请求事件request
// on方法做事件监听
server.on('request', (request, response) => )
request: 接受客户端请求对象,它包含了与客户端相关的数据和属性
request.url // 客户端请求的uri地址
request.method //客户端请求的方式 get或post
request.headers // 客户端请求头信息(对象)
response:服务器对客户端的响应对象
设置响应头信息 ,用于响应时有中文时乱码解决处理
response.setHeader(‘content-type’, ‘text/html;charset=utf-8’)
设置状态码(常见的HTTP状态码有:200,404,301、302、304、403、401、405、500,502)
response.statusCode = 200(默认是200)
response.writeHead(statusCode, [reasonPhrase], [headers]))
statusCode:状态码
reasonPhrase:状态描述
headers:头信息
response.write(响应数据) 可调用多次,最终会将多次数据拼接在一起响应
向客户端发送响应数据,并结束本次请求的处理过程
response.end(‘hello world’)
启动服务
server.listen(8080, () =>
console.log('服务已启动')
)
监听服务器
server.listen(12345,()=>
console.log("服务器启动了,地址是:http://localhost:12345");
)
require('http').createServer((req,res)=>
res.end('ooookk')
).listen(3000)
静态资源服务器
const fs = require('fs')
require('http').createServer((req,res)=>
if(req.url === '/favicon.ico')
let data = fs.readFileSync('./favicon.ico')
res.end(data)
else
let data = fs.readFileSync('.'+req.url)
res.end(data)
为什么请求路径是 /XXX?因为请求路径其实是主机名后面到?前的这一段
协议://用户名:密码@主机名/路径?参数#hash
为什么下面读取的时候是 ./? 因为我们在找文件,需要使用相对路径
if(fs.existsSync('.'+req.url))
let data = fs.readFileSync('.'+req.url)
// 响应的时候,服务器设置一个默认的响应头 - 为了识别文件
res.end(data)
// if(req.url === '/src/html.html')
// fs.readFileSync('src/html.html')
// fs.readFileSync(req.url.slice(1)) // 也可以,不如拼接 . 方便
// fs.readFileSync('.'+req.url)
//
else
// 文件不存在
res.statusCode = 404
res.statusMessage = 'file is not found'
res.setHeader('content-type','text/html;charset=utf8')
let html = `
<h1>404页面</h1>
<p>页面不存在</p
res.end(html)
).listen(3000)
if(req.url === '/favicon.ico')
res.end()
else
// 对每个请求路径做判断
if(req.url === '/src/home.html')
// 读取对应的文件
let html = fs.readFileSync('./src/home.html')
// 为了让数据更好的显示 - 设置响应头 - 文件类型
res.setHeader('content-type',"text/html")
// 响应读取出来的buffer
res.end(html)
*
刚开始响应html的时候,浏览器会一直没有停止下来,因为html中使用过link标签、script标签、img标签,这些标签会
自动发送http请求 - 这些请求也需要处理,否则html页面就不完整
正常的css请求,看到响应是css代码,我们在处理这次请求的时候,也是将css文件读取出来并响应buffer即可
// 包含node_modules请求路径的请求,读取路径比请求路径多 .,一次性将带有node_modules的请求路径处理
/*else if(req.url.includes("/node_modules"))
let data = fs.readFileSync('.'+req.url)
res.end(data)
*/
css资源
else if(req.url.includes('/css'))
let css = fs.readFileSync('.'+req.url)
res.setHeader('content-type',"text/css")
res.end(css)
js资源
else if(req.url.includes('/js'))
let js = fs.readFileSync('.'+req.url)
res.setHeader('content-type',"application/javascript")
res.end(js)
图片请求,也是将图片读取出来并响应即可
/*else if(req.url.includes('/images'))
let img = fs.readFileSync('.'+req.url)
res.setHeader('content-type','image/jpeg')
res.end(img)
以上是关于一短文带你快速入门Node.js 基础及内置模块的主要内容,如果未能解决你的问题,请参考以下文章