聚类算法指标整理
Posted JasonLiu1919
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了聚类算法指标整理相关的知识,希望对你有一定的参考价值。
更多、更及时内容欢迎留意微信公众号: 小窗幽记机器学习
文章目录
前言
本文主要介绍聚类算法的一些常见评测指标。
假设某一种算法得到聚类结果为:
A = [ 1 2 1 1 1 1 1 2 2 2 2 3 1 1 3 3 3 ] \\mathrmA=\\left[\\beginarraylllllllll 1 & 2 & 1 & 1 & 1 & 1 & 1 & 2 & 2 & 2 & 2 & 3 & 1 & 1 & 3 & 3 & 3 \\endarray\\right] A=[12111112222311333]
标准的聚类结果为:
B
=
[
1
1
1
1
1
1
2
2
2
2
2
2
3
3
3
3
3
]
\\mathrmB=\\left[\\beginarrayllllllll 1 & 1 & 1 & 1 & 1 & 1 & 2 & 2 & 2 & 2 & 2 & 2 & 3 & 3 & 3 & 3 & 3 \\endarray\\right]
B=[11111122222233333]
那么如何评价该算法的聚类效果?
纯度(purity)
把每个簇中最多的类作为这个簇所代表的类,然后计算正确分配的类的数量,然后除以总数:
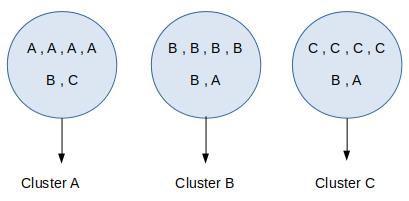
纯度计算如下:
purity = ( cluster A + cluster B + cluster C ) total = ( 4 + 5 + 4 ) 18 = 0.722 \\text purity =\\frac(\\text cluster A+\\text cluster B+\\text cluster C)\\text total =\\frac(4+5+4)18=0.722 purity = total ( cluster A+ cluster B+ cluster C)=18(4+5+4)=0.722
一般而言,纯度随着clusters数量的增加而增加。例如,将每个样本结果分为一个单独的簇,此时纯度为1。鉴于此,不能简单用纯度来衡量聚类质量与聚类数量之间的关系。
纯度的计算Python代码
def purity(result, label):
# 计算纯度
total_num = len(label)
cluster_counter = collections.Counter(result)
original_counter = collections.Counter(label)
t = []
for k in cluster_counter:
p_k = []
for j in original_counter:
count = 0
for i in range(len(result)):
if result[i] == k and label[i] == j: # 求交集
count += 1
p_k.append(count)
temp_t = max(p_k)
t.append(temp_t)
return sum(t)/total_num
标准互信息(NMI)
熵
标准互信息(Normalized mutual information, NMI)这个指标源自信息论,所以需要先了解熵(entropy)的概念。熵这个概念是用于量化不确定性,熵的定义如下:
H
(
p
)
=
−
∑
i
p
i
log
2
(
p
i
)
H(p)=-\\sum_i p_i \\log _2\\left(p_i\\right)
H(p)=−i∑pilog2(pi)
其中
P
i
P_i
Pi表示label为
i
i
i的概率。延续上述示例,可以计算其熵。
class A : 6 / 18
class B :7 / 18
class C :5 / 18
entropy
=
−
(
(
6
18
)
⋅
log
(
6
18
)
)
−
(
(
7
18
)
⋅
log
(
7
18
)
)
−
(
(
5
18
)
⋅
log
(
5
18
)
)
\\text entropy=-\\left(\\left(\\frac618\\right) \\cdot \\log \\left(\\frac618\\right)\\right)-\\left(\\left(\\frac718\\right) \\cdot \\log \\left(\\frac718\\right)\\right)-\\left(\\left(\\frac518\\right) \\cdot \\log \\left(\\frac518\\right)\\right)
entropy=−((186)⋅log(186))−((187)⋅log(187))−((185)⋅log(185))
其值为 1.089。需要注意的是:当类别或标签分布均匀时,熵值比较高。
熵随着不确定性的减小而减小。假设我们有两个类,其中类A中有9个数据点,类B中有1个数据点。在这种情况下,如果我们要预测一个随机选择的数据点的类别,我们会比之前的情况更确定。这是因为此时熵计算如下,结果值为0.325:
entropy
=
−
(
(
9
10
)
⋅
log
(
9
10
)
)
−
(
(
1
10
)
⋅
log
(
1
10
)
)
\\text entropy =-\\left(\\left(\\frac910\\right) \\cdot \\log \\left(\\frac910\\right)\\right)-\\left(\\left(\\frac110\\right) \\cdot \\log \\left(\\frac110\\right)\\right)
entropy =−((109)⋅log(109))−((101)⋅log(101))
以上即为熵的概念。
互信息
互信息是用以衡量数据分布之间的相关性。互信息越高,相关性也越高。两个离散随机变量 X X X 和 Y Y Y的互信息定义如下:
M
I
(
X
,
Y
)
=
∑
x
=
1
∣
X
∣
∑
y
=
1
∣
Y
∣
P
(
x
,
y
)
log
(
P
(
x
,
y
)
P
(
x
)
P
(
y
)
)
M I(X, Y)=\\sum_x=1^|X| \\sum_y=1^|Y| P(x, y) \\log \\left(\\fracP(x, y)P(x) P(y)\\right)
MI(X,Y)=x=1∑∣X∣y=1∑∣Y∣P(x,y)log(P(x)P(y)P(< 以上是关于聚类算法指标整理的主要内容,如果未能解决你的问题,请参考以下文章