pytorch(网络模型训练)
Posted 月屯
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了pytorch(网络模型训练)相关的知识,希望对你有一定的参考价值。
目录标题
网络模型训练
小插曲
区别
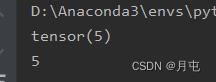
import torch
a=torch.tensor(5)
print(a)
print(a.item())
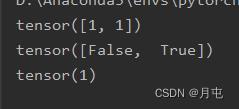
import torch
output=torch.tensor([[0.1,0.2],[0.05,0.4]])
print(output.argmax(1))# 为1选取每一行最大值的索引,为0选取每一列最大值的索引
preds=output.argmax(1)
target=torch.tensor([0,1])
print(preds==target)
print((preds==target).sum())
训练模型
import torch
from torch import nn
from torch.nn import Sequential, Conv2d, MaxPool2d, Linear, Flatten
# 搭建神经网络
class Dun(nn.Module):
def __init__(self):
super().__init__()
# 2.
self.model1 = Sequential(Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10))
def forward(self,x):
x=self.model1(x)
return x
if __name__=='__main__':
dun=Dun()
input=torch.ones((64,3,32,32))
print(dun(input).shape)
数据训练
import torchvision
# 准备数据集
from torch.utils.tensorboard import SummaryWriter
from model import *
from torch.utils.data import DataLoader
train_data=torchvision.datasets.CIFAR10(root="./data_set_train",train=True,transform=torchvision.transforms.ToTensor(),download=True)
test_data=torchvision.datasets.CIFAR10(root="./data_set_test",train=False,transform=torchvision.transforms.ToTensor(),download=True)
#长度
train_data_size=len(train_data)
test_data_size=len(test_data)
print("train_data_size:",format(train_data_size))
print("test_data_size:",format(test_data_size))
# 加载数据集
train_dataloader=DataLoader(train_data,batch_size=64)
test_dataloder=DataLoader(test_data,batch_size=64)
#创建网络模型
dun=Dun()
#损失函数
loss_fn=nn.CrossEntropyLoss()
# 优化器
learning_rate=1e-2
optimizerr=torch.optim.SGD(dun.parameters(),lr=learning_rate)
#设置训练网络参数
# 记录训练次数
total_train_step=0
# 记录测试次数
total_test_step=0
#训练次数
epoch=10
# 追加tensorboard
writer=SummaryWriter("./logs")
for i in range(epoch):
print("----------第轮训练------".format(i+1))
# 训练开始
dun.train()# 网络模型中,对dropout、BatchNorm层等起作用,进入训练状态
for data in train_dataloader:
img,target=data
output=dun(img)
loss=loss_fn(output,target)
#优化器优化
optimizerr.zero_grad()
loss.backward()
optimizerr.step()
total_train_step+=1
print("训练次数:,loss:".format(total_train_step,loss.item()))
writer.add_scalar("train_loss",loss.item(),total_train_step)
# 测试步骤
total_test_loss=0
# 使用正确率判断模型的好坏
total_accuracy=0
dun.eval()# 网络模型中,对dropout、BatchNorm层等起作用,进入验证状态
with torch.no_grad():
for data in test_dataloder:
img,target=data
output=dun(img)
total_test_loss+=loss_fn(output,target).item()
accuracy=(output.argmax(1)==target).sum()
total_accuracy+=accuracy
print("整体测试集上的Loss:".format(total_test_loss))
writer.add_scalar("test_loss",total_test_loss,total_test_step)
print("整体测试集上的正确率:".format(total_accuracy/test_data_size))
writer.add_scalar("test_accuracy",total_accuracy/test_data_size,total_test_step)
total_test_step+=1
#保存模型
torch.save(dun,"dun.pth".format(i))
print("保存模型")
writer.close()
GPU 训练
第一种方式

将以上的三部分调用cuda方法,以上面训练数据的代码为例
# 模型
if torch.cuda.is_available():# 判断是否可以使用gpu
dun=dun.cuda()
#损失函数
if torch.cuda.is_available():
loss_fn=loss_fn.cuda()
# 数据(包含训练和测试的)
if torch.cuda.is_available():
img = img.cuda()
target = target.cuda()
方式二:
# 定义训练的设备
device=torch.device("cuda" if torch.cuda.is_available() else "cpu")# 参数分为cpu和cuda,当显卡多个时cuda:0
将方式一的代码换成
dun=dun.to(device)
# 其他数据、loss类似
查看GPU信息
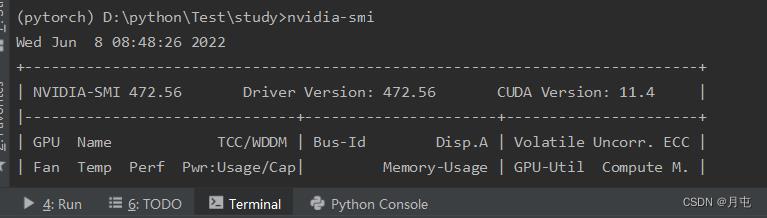
完整模型验证
查看数据集CIFAR10的类别
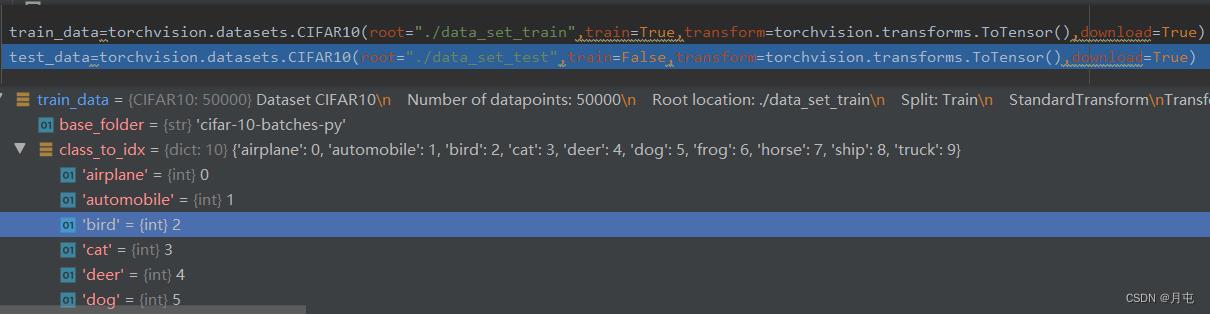
import torchvision
from PIL import Image
import torch
from torch import nn
from torch.nn import Sequential, Conv2d, MaxPool2d, Linear, Flatten
# 搭建神经网络
class Dun(nn.Module):
def __init__(self):
super().__init__()
# 2.
self.model1 = Sequential(Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10))
def forward(self,x):
x=self.model1(x)
return x
image_path="./img/1.png"
image=Image.open(image_path)
print(image)
# 类型转换
transform=torchvision.transforms.Compose([torchvision.transforms.Resize((32,32)),torchvision.transforms.ToTensor()])
image=transform(image)
print(image.shape)
# 加载网络模型注意加载的模型和现在验证的要么使用cpu要么gpu一致,否则需要map——location映射本地的cpu
model=torch.load("dun0.pth",map_location=torch.device("cpu"))
print(model)
# 类型转换
image=torch.reshape(image,(1,3,32,32))
model.eval()# 模型转换测试类型
# 执行模型
with torch.no_grad():
output=model(image)
print(output)
print(output.argmax(1))
以上是关于pytorch(网络模型训练)的主要内容,如果未能解决你的问题,请参考以下文章