AI遮天传 ML/DL-感知机
Posted 老师我作业忘带了
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了AI遮天传 ML/DL-感知机相关的知识,希望对你有一定的参考价值。
感知机的出现是人工智能发展史一大重要里程碑,其后才诞生了:多层感知机、卷积神经网络等一系列的经典网络模型。
在我看来,它虽然是深度学习领域的一大开端,但本身解决的只是线性二分类问题,它本身与机器学习经典模型线性SVM有着一些相似度。又如Logistic sigmoid函数,也可以解决二分类问题,且这时我们接触了非线性函数,后面所接触的激活函数如Softmax又可以看作logistic是它的一种特殊情况。

因此,我打算按这种顺序重新整理一下:
- 感知机->Logistic回归分类->多层感知机->...
- 线性SVM->核SVM
一、阈值逻辑单元(Threshold Logic Unit, TLU)

如上图是一个神经元,我们可以看到它的胞体、轴突、树突。
我们高中的时候学过一种东西叫做神经递质,分为抑制性神经递质和兴奋性神经递质,以及一些关于兴奋和抑制相关的知识;
我们把这些递质看作神经元的输入,则可模仿神经元建立以下模型(M-P unit):
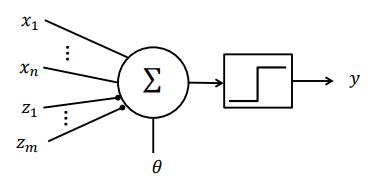
其中:
那个方块中的符号代表阶跃函数
兴奋性输入
抑制性输入
二元化输出
- 输入与输出都是二进制的
阈值
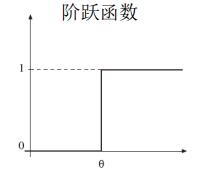
解释如下:
- M-P单元可以被单个抑制性信号所抑制,就像真实的神经元一样。
- 如果, , . . . , 至少有一个为 1, 则该单元被抑制且 𝑦 = 0
- 否则将计算总激活值 并与阈值 𝜃 相比较 (如果𝑛 = 0 则 𝑥 = 0)
- 如果𝑇 ≥ 𝜃 则发放值为1,表示兴奋。
- 如果𝑇 < 𝜃 结果为0,表示非兴奋。
我们还可以用该模型实现布尔函数:
比如一组数据 0 0 1 0,合取为0,析取为1,我们只需分别把阈值设置为4和1即可:
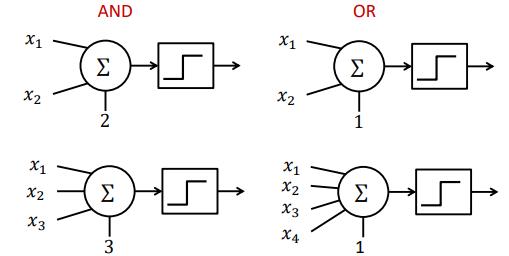
当然 若是想实现取反操作,则可以加上抑制性输入或使用非门。

命题1:不受限制的McCulloch–Pitts(M-P)单元只能实现单调逻辑函数。
命题2:任何逻辑函数 𝐹 ∶
→ 0, 1 都能由一个两层的M-P网络计算得到。
命题3:所有的逻辑函数都能被包含与、或、非功能的网络所实现。
链接:AI遮天传 DL-多层感知机_老师我作业忘带了的博客-CSDN博客
二、感知机 (Perceptron)
2.1. 介绍
1958 年,美国心理学家 Frank Rosenblatt 就提出了第一个可以自动学习权重的神经元模型,称为感知机。
之前我们输入的都是逻辑单元01,这次x可以为实数,对x进行加权(w),求和,与阈值(b)进行比较,同样大于的取1,不大于的取0或者-1。
在感知机学习算法中,激活函数的形式非常简单,仅仅是一个单位阶跃函数(也被称为 Heaviside阶跃函数)(这也是最早的激活函数):

为了推导简单,我们可以将阈值b挪到等式左边并且额外定义一个权重参数 , 这样我们可以对给出更加紧凑的公式: 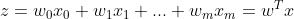 ,此时:
,此时:
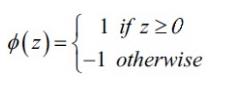
当然,这个比较操也可以,仅仅作通过移项可以写成公式  ,即不对b分配参数。(w和x为行或列数为1的矩阵,相乘结果为实数。)
,即不对b分配参数。(w和x为行或列数为1的矩阵,相乘结果为实数。)
下面左图描述了感知机的激活函数怎样将网络输入 压缩到二元输出(-1,1),右图描述 了感知机如何区分两个线性可分的类别。
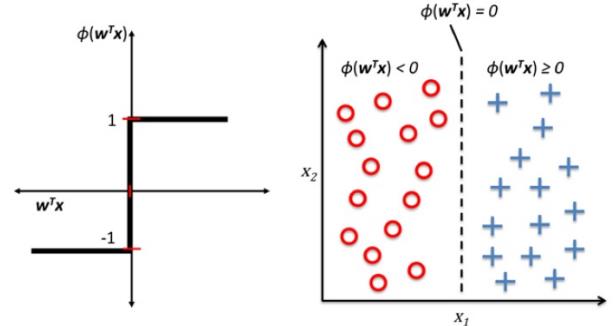
注意,横坐标是 , 是一个整体,许多个x和其权重w相乘的结果。
, 是一个整体,许多个x和其权重w相乘的结果。
2.2. 工作(分类)原理
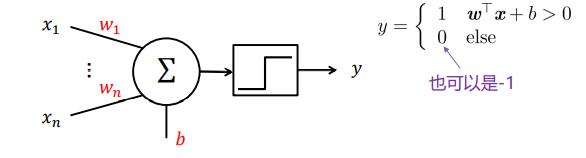
在M-P单元的实数输入连接上加上权重;
提出监督学习:
- 将权重参数初始化为0或者很小的随机数
- 对于每个数据点
及对应的标签
, 计算输出
- 更新参数:
;
决策表边界是一个超平面
其中𝜂为学习率且 𝜂 > 0
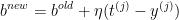
如果感知机预测的类别正确,那么和 相等,更新参数时相减为0,
相等,更新参数时相减为0,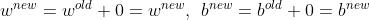
当预测结果不正确时,权重会朝着正确类别方向更新(如果正确类别是1,权重参数会增大;如果正确类别是-1,权重参数会减小):
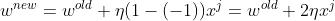

假设其中有一个: x=0.5,t=1,学习率 ,此时的
,此时的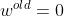 ,预测结果y=-1,则
,预测结果y=-1,则

下一次在对样本i计 算输出值时,有更大的可能输出1。
参数更新和样本成正比。比如,如果我们有另一个样本 x=2 被误分类为-1,在更新时会朝着正确方法更新更多(相比较 x=0.5的情况):
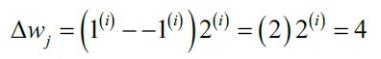
感知机算法仅在两个类别确实线性可分并且学习率充分小的情况下才能保证收敛。
如果两个类别不能被一个线性决策界分开,我们可以设置最大训练集迭代次数(epoch)或者可容忍的错误分类样本数来停止算法的学习过程。

2.3. 初步总结

感知机接收一个样本输入X,然后将其和权重W结合,计算网络输入Z。Z接着被传递给激活函数(此时还是简单的跃迁函数),产生一个二分类输出-1或1作为预测的样本类别。在整个学习阶段,输出用于计算预测错误率和更新权重参数。
更新参数的过程类似于梯度下降,不过对于t和y它们是离散的,但在有限距离内依旧可以收敛到正确解上:
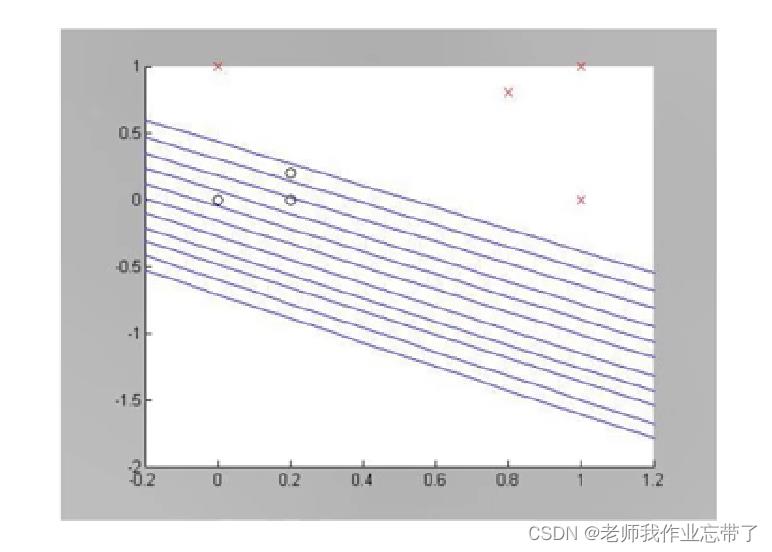
如果训练数据集线性可分,则感知机必定能收敛。并且训练中需要迭代的次数存在一个上限。
2.4. 使用Python实现感知机算法
根据2.2.感知机原理,我们实现如下感知机代码:
class Perceptron(object):
def __init__(self, eta=0.01, n_iter=10):
self.eta = eta
self.n_iter = n_iter
def fit(self, X, y):
self.w_ = np.zeros(1 + X.shape[1])
self.errors_ = []
for _ in range(self.n_iter):
errors = 0
for xi, target in zip(X, y):
update = self.eta * (target - self.predict(xi))
self.w_[1:] += update * xi
self.w_[0] += update
errors += int(update != 0.0)
self.errors_.append(errors)
return self
def net_input(self, X):
return np.dot(X, self.w_[1:]) + self.w_[0]
def predict(self, X):
return np.where(self.net_input(X) >= 0.0, 1, -1)其中,eta为学习率,n_iter为迭代次数(即更新权重的次数)。w_为权重,第一个元素是给偏置b准备的,后面是真正的w。此外使用errors记录误分类。
2.5. 代码测试
二分类任务,我们不妨使用水仙花数据集中的两类花:
from sklearn import datasets
iris = datasets.load_iris()
iris
这里有4列,4个特征,
feature_names': ['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)'],
3个标签,
'target_names': array(['setosa', 'versicolor', 'virginica'], dtype='<U10'),
共计150条数据,每个标签50条,且是按顺序的:
'target': array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2]),
我们取前100条数据,也就是'setosa', 'versicolor'这两类(二分类),观察它们的petal length和sepal length(选两个特征,二维平面观察方便),也就是第0列和第2列。
因此变量X,y为:
X = iris.data[:100,[0,2]]
y = iris.target[:100]
y = np.where(y==0,-1,1) # 把标签设置成 -1 和 1则有:
import matplotlib.pyplot as plt
plt.scatter(X[:50,0],X[:50,1],color='red',marker='o',label='setosa')
plt.scatter(X[50:100,0],X[50:100,1],color='blue',marker='x',label='versicolor')
plt.xlabel('petal length')
plt.ylabel('sepal length')
plt.legend(loc='upper left')
plt.show()
ppn = Perceptron(eta=0.1, n_iter=10)
ppn.fit(X,y)plt.plot(range(1,len(ppn.errors_)+1),ppn.errors_,marker='o')
plt.xlabel('Epoches')
plt.ylabel('Number of misclassifications')
plt.show()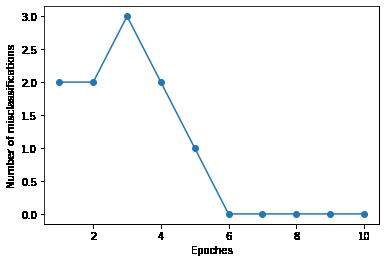
可以看到,第6次迭代时,感知机算法已经收敛了,对训练集的预测准群率是 100%。接下来我们将分界线画出来:
from mlxtend.plotting import plot_decision_regions
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号
plt.figure(figsize=(8,6))
plot_decision_regions(X,y,ppn) # 绘制分类器的决策区域
plt.xlabel('萼片长度')
plt.ylabel('花瓣长度')
plt.title(' 绘制分类器的决策区域')
plt.legend(loc='upper left') # 标签位置设置
plt.show()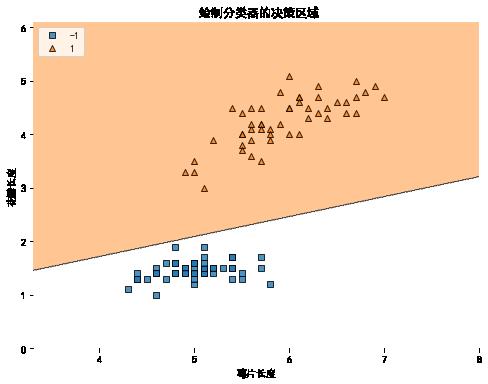
虽然对于Iris数据集,感知机算法表现的很完美,但是"收敛"一直是感知机算法中的一大问题。Frank Rosenblatt从数学上证明了只要两个类别能够被一个现行超平面分开,则感知机算 法一定能够收敛。然而,如果数据并非线性可分,感知计算法则会一直运行下去,除非我们 人为设置最大迭代次数n_iter。
2.6. 缺点及发展
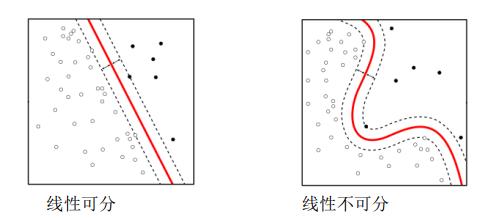
决策边界通常与样本点距离很近, 因此对噪声敏感。
对于图右侧,无法寻找一个线性超平面将其分解,这也使得神经网络进入第一次低潮。
同一层内多个感知机
当多个感知机被组合起来时, 输出神经元之间是互相独立的; 因此多个感知机的学习过程可以看成是相互独立的。
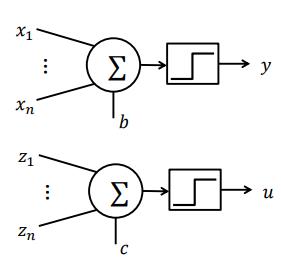
三、自适应线性神经网络(ADALINE)及收敛问题
3.1. 介绍
我们来学习另一种单层神经网络:自适应线性神经元(ADAptive LInear NEuron, 简称 Adaline)。在Frank Rosenblatt提出感知计算法不久,Bernard Widrow和他的博士生Tedd Hoff 提出了Adaline算法作为感知机的改进算法。
相对于感知机,Adaline算法有趣的多,因为在学习Adaline的过程中涉及到机器学习中一个重要的概念:定义、最小化损失函数。学习Adaline为以后学习更复杂高端的算法(比如logistic回归、SVM等)起到抛砖引玉的作用。
3.2. 工作原理
其结构与感知机一致,训练算法不同。
Adaline和感知机的一个重要区别是Adaline算法中权重参数更新按照线性激活函数而不是单位阶跃函数。当然,Adaline中激活函数也简单的很:

用
而不是用𝑦来更新参数
- 最小化均方误差
.
- 学习算法:
,
决策表边界是一个超平面
或
𝜂为学习率且𝜂 > 0
别名: LMS规则,Delta规则,Widrow-Hoff 规则,实际上是SGD。


另一视角:
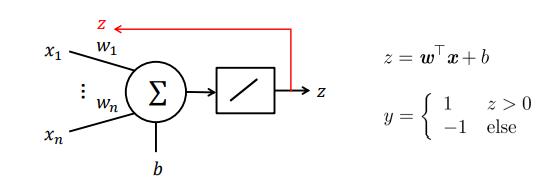
- 对变量 𝑧 的线性激活函数 (这也是名字中(Adaptive Linear Neuron)线性的由来)
- 阶跃函数只作用于输出𝑦 并且输出不参与学习过程.
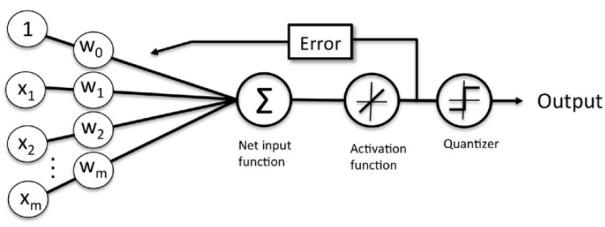
虽然Adaline中参数更新不是使用阶跃函数,但是在对测试集样本输出预测类别时还是使用阶跃函数,毕竟要输出离散值-1,1。
3.3. 使用梯度下降算法最小化损失函数
Q:为什么没有写在上面感知机更新参数那一步呢?
A:感知机更新参数的过程类似于梯度下降,不过对于t和y它们是离散的,但在有限距离内依旧可以收敛到正确解上。且那个时候反向传播算法还未出现,即便是想到使用梯度下降算法,那时候使用的激活函数(跃迁函数,符号函数),在x为0处不连续,且其他位置梯度为0,这就使得无法使用梯度下降算法优化参数。(梯度为0,梯度下降算法也就无效了,梯度弥散)
我们上面学的感知机,用的是跃迁函数,即非连续函数,在0处有跃迁,结果即要么是数字-1,要么是数字1,这使得我们无法对其进行求导。而Adaline用 接收了结果,z自己本身就是线性的了,也是连续的,且后面的跃迁函数又不参与学习(参数更新)过程,因此求导时不会出错。
接收了结果,z自己本身就是线性的了,也是连续的,且后面的跃迁函数又不参与学习(参数更新)过程,因此求导时不会出错。
感知机模型的不可导特性严重限制的它的潜力,使得它只能解决极其简单的任务。所以现代深度学习,在感知机的基础上,将不连续的阶跃激活函数换成了其它平滑连续激活函数,使得模型具有可导性。实际上,现代大规模深度学习的核心结构与感知机并没有多大差别,只是通过堆叠多层网络层来增强网络的表达能力。
在监督机器学习算法中,一个重要的概念就是定义目标函数(objective function),而目标函数就是机器学习算法的学习过程中要优化的目标,目标函数我们常称为损失函数(cost function),在算法学习(即,参数更新)的过程中就是要最小化损失函数。
对于Adaline算法,我们定义损失函数为样本真实值和预测值之间的误差平方和(Sum of Squared Erros, SSE):

上式中右上角的系数2完全是为了求导数方便而添加的,没有特殊的物理含义。
- 相对于感知机中的单位阶跃函数,使用连续现行激活函数的一大优点是Adaline的损失函数是可导的。
- 另一个很好的特性是Adaline的损失函数是凸函数,因为,我们可以使用简单而有效的优化算法:梯度下降(gradient descent)来找到使损失函数取值最小的权重参数。
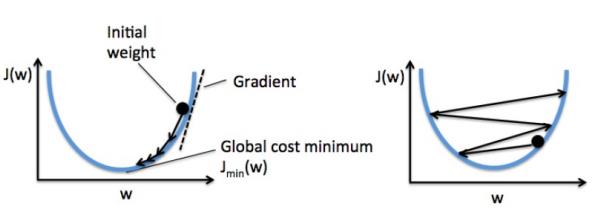
如下图所示,我们可以把梯度下降算法看做"下山",直到遇到局部最小点或者全局最小点才会 停止计算。在每一次迭代过程中,我们沿着梯度下降方向迈出一步,而步伐的大小由学习率 和梯度大小共同决定。

在计算权重更新的过程中:Adaline需要用到所有训练集样本才能一次性更新所有的w, 而感知机则是每次用一个训练集样本更新所有权重参数。所以梯度下降法常被称为批量梯度下降 ("batch" gradient descent)。
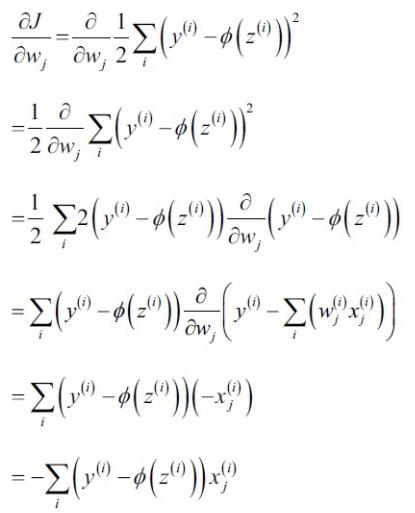
关于详细的梯度下降文章及其相关衍生算法后续文章会进行更新。
3.4. Python实现自适应线性神经元
既然感知机和Adaline的学习规则非常相似,所以在实现Adaline的时候我们不需要完全重写, 而是在感知机代码基础上进行修改得到Adaline,具体地,我们需要修改fit方法,实现梯度下降算法:
class AdalineGD(object):
def __init__(self, eta=0.01, n_iter=10):
self.eta = eta
self.n_iter = n_iter
def fit(self, X, y):
self.w_ = np.zeros(1 + X.shape[1])
self.cost_ = []
for i in range(self.n_iter):
output = self.net_input(X)
errors = (y - output)
self.w_[1:] += self.eta * X.T.dot(errors)
self.w_[0] += self.eta * errors.sum()
cost = (errors ** 2).sum() / 2.0
self.cost_.append(cost)
return self
def net_input(self, X):
return np.dot(X, self.w_[1:]) + self.w_[0]
def activation(self, X):
return self.net_input(X)
def predict(self, X):
return np.where(self.net_input(X) >= 0.0, 1, -1)观察学习率:
fig,ax = plt.subplots(nrows=1,ncols=2,figsize=(8,4))
adal = AdalineGD(n_iter=10,eta=0.01).fit(X,y)
ax[0].plot(range(1,len(adal.cost_)+1),np.log10(adal.cost_),marker='o')
ax[0].set_xlabel('Epochs')
ax[0].set_ylabel('log(Sum-squared-error)')
ax[0].set_title('Adalie - Learning rat 0.01')
adal = AdalineGD(n_iter=10,eta=0.0001).fit(X,y)
ax[1].plot(range(1,len(adal.cost_)+1),np.log10(adal.cost_),marker='o')
ax[1].set_xlabel('Epochs')
ax[1].set_ylabel('log(Sum-squared-error)')
ax[1].set_title('Adalie - Learning rat 0.0001')
分析上面两幅图各自的问题,左图根本不是在最小化损失函数,反而在每一轮迭代过程中, 损失函数值不断在增大!这说明取值过大的学习率不但对算法毫无益处反而危害大大滴。右 图虽然能够在每一轮迭代过程中一直在减小损失函数的值,但是减小的幅度太小了,估计至 少上百轮迭代才能收敛,而这个时间我们是耗不起的,所以学习率值过小就会导致算法收敛 的时间巨长,使得算法根本不能应用于实际问题。
下面左图展示了权重再更新过程中如何得到损失函数 J(w) 最小值的。右图展示了学习率过大时权重更新,每次都跳过了最小损失函数对应的权重值。
许多机器学习算法都要求先对特征进行某种缩放操作,比如标准化(standardization)和归一化 (normalization)。而缩放后的特征通常更有助于算法收敛,实际上,对特征缩放后在运用梯度 下降算法往往会有更好的学习效果。
标准化:
X_std = np.copy(X)
X_std[:,0] = (X[:,0] - X[:,0].mean())/X[:,0].std()
X_std[:,1] = (X[:,1] - X[:,1].mean())/X[:,1].std()标准化后,我们用Adaline算法来训练模型,看看如何收敛的(学习率为0.01):
ada = AdalineGD(n_iter=15,eta=0.01)
ada.fit(X_std,y)plot_decision_regions(X_std,y,ada)
plt.title('Adaline - Gradient Descent')
plt.xlabel('sepal length [standardized]')
plt.ylabel('petal length [standardized]')
plt.legend(loc='upper left')
plt.show()
plt.plot(range(1,len(adal.cost_)+1),adal.cost_,marker='o')
ax[1].set_xlabel('Epochs')
ax[1].set_ylabel('Sum-squared-error')
plt.show()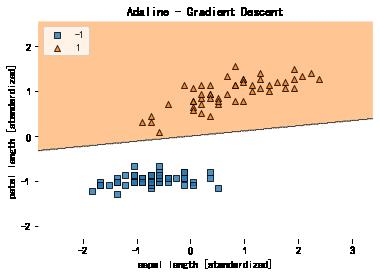
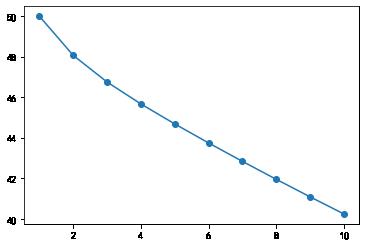
标准化后的数据再使用梯度下降Adaline算法竟然收敛了! 注意看Sum-squared-error(即, )最后并没有等于0,即使所有样本都正确分类。
)最后并没有等于0,即使所有样本都正确分类。
四、MADALINE模型
- MADALINE: 多个ADALINE模型。
- 用于分类的三层(输入层, 隐含层, 输出层)全连接前馈网络,将 ADALINE作为其隐含层和输出层单元。
- 三种不同的MADALINE训练算法:
- 最早追溯到1962年并且不能用于更新隐含层和输出层的连接权重。
- 1988年提出了改进训练算法。
- 第三个算法应用于改进后的网络,将阶跃函数替换成 sigmoid激活函数; 后来被证明与反向传播等价。
就先写这些吧~ 想起什么来后面再补充~
以上是关于AI遮天传 ML/DL-感知机的主要内容,如果未能解决你的问题,请参考以下文章