对于 Linux/Unix 系统管理员非常有用的并且最常用的20个命令行系统监视工具。这些命令可以在所有版本的 Linux 下使用去监控和查找系统性能的实际原因。这些监控命令足够你选择适合你的监控场景。
1.top — Linux 系统进程监控
top 命令是性能监控程序,它可以在很多 Linux/Unix 版本下使用,并且它也是 Linux 系统管理员经常使用的监控系统性能的工具。Top 命令可以定期显示所有正在运行和实际运行并且更新到列表中,它显示出 CPU 的使用、内存的使用、交换内存、缓存大小、缓冲区大小、过程控制、用户和更多命令。它也会显示内存和 CPU 使用率过高的正在运行的进程。当我们对 Linux 系统需要去监控和采取正确的行动时,top 命令对于系统管理员是非常有用的。让我们看下 top 命令的实际操作。
- # top

2.vmstat — 虚拟内存统计
vmstat 命令是用于显示虚拟内存、内核线程、磁盘、系统进程、I/O 模块、中断、CPU 活跃状态等更多信息。在默认的情况下,Linux 系统是没有 vmstat 这个命令的,如果你要使用它,必须安装一个包名叫 sysstat 的程序包。命令格式常用用法如下:
- # vmstat
- procs ———–memory———- —swap– —–io—- –system– —–cpu—–
- r b swpd free inact active si so bi bo in cs us sy id wa st
- 1 0 0 810420 97380 70628 0 0 115 4 89 79 1 6 90 3 0
3.lsof — 打开文件列表
lsof 命令对于很多 Linux/Unix 系统都可以使用,主要以列表的形式显示打开的文件和进程。
打开的文件主要包括磁盘文件、网络套接字、管道、设备和进程。使用这个命令的主要原因是一个一个盘不能卸载并且显示文件正在使用或者打开的错误信息。这个命令很容易看出哪些文件正在使用。这个命令最常用的格式:
- # lsof
- COMMAND PID USER FD TYPE DEVICE SIZE NODE NAME
- init 1 root cwd DIR 104,2 4096 2 /
- init 1 root rtd DIR 104,2 4096 2 /
- init 1 root txt REG 104,2 38652 17710339 /sbin/init
- init 1 root mem REG 104,2 129900 196453 /lib/ld-2.5.so
- init 1 root mem REG 104,2 1693812 196454 /lib/libc-2.5.so
- init 1 root mem REG 104,2 20668 196479 /lib/libdl-2.5.so
- init 1 root mem REG 104,2 245376 196419 /lib/libsepol.so.1
- init 1 root mem REG 104,2 93508 196431 /lib/libselinux.so.1
- init 1 root 10u FIFO 0,17 953 /dev/initctl
4.tcpdump — 网络数据包分析器
tcpdump 是一种使用最广泛的命令行网络数据包分析器或数据包嗅探程序,主要用于捕获和过滤 TCP/IP 包收到或者转移在一个网络的特定借口信息。它也提供了一个选项参数去保存将捕获的包在一个文件中用于以后分析使用,tcpdump 几乎在所有的 Linux 版本中都是可用的。
- # tcpdump -i eth0
- tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
- listening on eth0, link-type EN10MB (Ethernet), capture size 96 bytes
- 22:08:59.617628 IP tecmint.com.ssh > 115.113.134.3.static-mumbai.vsnl.net.in.28472: P 2532133365:2532133481(116) ack 3561562349 win 9648
- 22:09:07.653466 IP tecmint.com.ssh > 115.113.134.3.static-mumbai.vsnl.net.in.28472: P 116:232(116) ack 1 win 9648
- 22:08:59.617916 IP 115.113.134.3.static-mumbai.vsnl.net.in.28472 > tecmint.com.ssh: . ack 116 win 64347
5.netstat — 网络统计
netstat 命令是一个监控网络数据包传入和传出的统计界面的命令行工具。它对于许多系统管理员去监控网络性能和解决网络相关问题是一个非常有用的工具。
- # tcpdump -i eth0
- tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
- listening on eth0, link-type EN10MB (Ethernet), capture size 96 bytes
- 22:08:59.617628 IP tecmint.com.ssh > 115.113.134.3.static-mumbai.vsnl.net.in.28472: P 2532133365:2532133481(116) ack 3561562349 win 9648
- 22:09:07.653466 IP tecmint.com.ssh > 115.113.134.3.static-mumbai.vsnl.net.in.28472: P 116:232(116) ack 1 win 9648
- 22:08:59.617916 IP 115.113.134.3.static-mumbai.vsnl.net.in.28472 > tecmint.com.ssh: . ack 116 win 64347
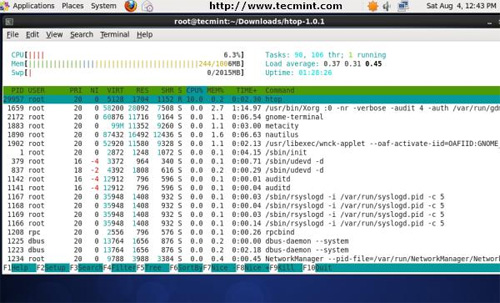
6.htop — 进程监控
htop 是一个更加先进的交互式的实时监控工具。htop 与 top 命令非常相似,但是他有一些非常丰富的功能,如用户友好界面管理进程、快捷键、横向和纵向进程等更多的。htop 是一个第三方工具并不包括在 Linux 系统中,你需要使用包管理工具进行安装。
- # htop
7.iotop — 监控 Linux 磁盘 I/O
iotop 也是和 top 和 htop 命令相似,但是它会有一个报告功能去监控和显示实时的磁盘 I/O 输入和输出的程序进程。这个工具对于查找精确的高的磁盘读/写过程是非常有用的。
- # htop

8.iostat — 输入/输出统计
iostat 是收集和展示系统输入和输出存储设备统计的简单工具。这个工具通常用于查找存储设备性能问题,包括设备、本地磁盘、例如 NFS 远程磁盘。
- # iostat
- Linux 2.6.18-238.9.1.el5 (tecmint.com) 09/13/2012
- avg-cpu: %user %nice %system %iowait %steal %idle
- 2.60 3.65 1.04 4.29 0.00 88.42
- Device: tps Blk_read/s Blk_wrtn/s Blk_read Blk_wrtn
- cciss/c0d0 17.79 545.80 256.52 855159769 401914750
- cciss/c0d0p1 0.00 0.00 0.00 5459 3518
- cciss/c0d0p2 16.45 533.97 245.18 836631746 384153384
- cciss/c0d0p3 0.63 5.58 3.97 8737650 6215544
- cciss/c0d0p4 0.00 0.00 0.00 8 0
- cciss/c0d0p5 0.63 3.79 5.03 5936778 7882528
- cciss/c0d0p6 0.08 2.46 2.34 3847771 3659776
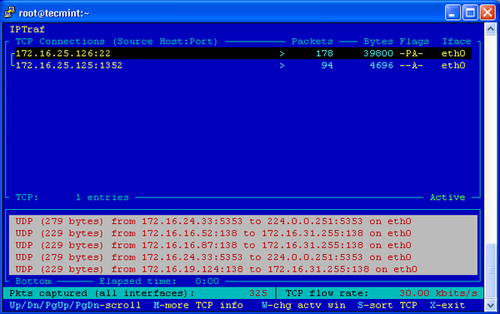
9.IPTraf —实时IP局域网监控
IPTraf 是一个基于开源的 Linux 系统实时网络(IP 网络)监测的工具。它能收集到各种各样的信息,如通过网络对 IP 流量监测,包括 TCP 标志信息、ICMP 详细细节、TCP/UDP 流量故障、TCP 连接的数据包和拜恩计数。并且它还收集 TCP,UDP,ICMP,IP,非 IP,IP 校验错误,界面活性等一般信息和详细信息的接口统计数据。
10.Psacct 或者 Acct — 监视用户活动
Psacct 或者 Acct 是用于监测每个用户对系统的活跃状态的一个非常有用的工具。在后台有两个守护进程在运行,一个是密切关注系统上每个用户的整体活动,另一个进程关注有哪些资源被它们消耗。
这个工具对于系统管理员是非常有用的去跟踪每个用户的活动,可以知道用户正在做什么,发出了什么样的命令,占用了多少资源,多长时间活跃在系统上。
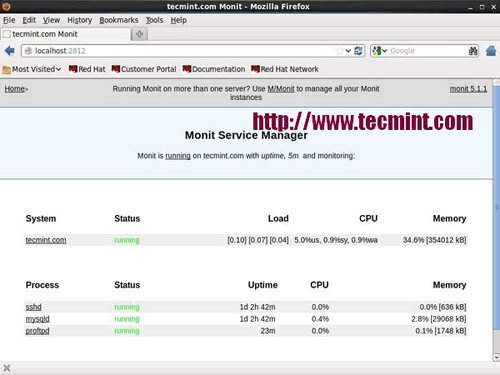
11.Monit — 程序和服务监测
这是一个免费的开源的基于 Web 程序的自动监控和管理系统进程、程序、文件、目录、权限、校验文件系统。它监控的服务包括 Apache、MYSQL、Mail、FTP、Nginx 等等。系统状态是可以从命令行或者自己的网络接口来查看。
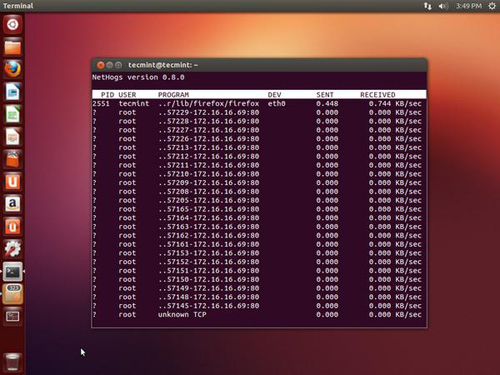
12.NetHogs — 监视每个进程的网络带宽
NetHogs 是一个开源的漂亮的小程序(类似于 Linux 上面的 top 命令),在您的系统上保持每个进程的网络活动状态。它也保持了一个程序或者应用实时的网络流量带宽使用情况。
13.iftop — 网络带宽监控
iftop 是另一个基于终端的开源的系统监测工具,主要功能是通过你自己系统上的网络接口显示一个经常更新的网络带宽利用率的列表(即源主机和目的主机)。iftop监控的是网络的使用情况,而 top 监控的是 CPU 的使用情况。iftop 监视一个选定的接口并且显示两台主机之间当前宽带的使用情况。

14.Monitorix — 系统和网络监控
Monitorix 是一个尽可能多的在 Linux/Unix 上一个轻量级监控工具,主要设计是监控正在运行的系统和网络资源。它有一个内置的 HTTP web 服务去定期收集系统和网络信息并显示成图片。它可以监视系统的平均负载使用、内存的分配、磁盘驱动器、系统服务、网络端口、邮件统计(Sendmail、Postfix、Dovecot 等等)、MYSQL 数据库等等更多的服务。它的主要目的是监控整个系统的性能,并且有助于监测故障、瓶颈、异常活动等状况。

15.Arpwatch — 以太网活动监控器
Arpwatch是一种用来监视 Linux 网络的以太网的网络流量的地址解析(网络地址转换)的一个程序。它一直随着网络时间戳的变化监视以太网流量和产生日志的 IP 和 MAC 地址对。当一个 IP 地址或 MAC 地址对发生变化的时候,它会发送电子邮件通知管理员。
并且,它在检测 ARP 攻击是非常有用的。
16.Suricata — 网络安全监控
Suricata 是一个高性能的开源的网络安全与入侵检测与预防 Linux、FreeBSD、Windows 等操作系统的监控工具。它是一个非营利基金 OISF(Open Information Security Foundation)拥有的。
17.VnStat PHP — 监测网络带宽
VnStat PHP 是一个 Web 前端应用最流行的社交工具叫“vnstat”。 VnStat PHP 使用了很好的图形模式监控网络流量的使用情况。它显示了每时、每天、每月的总结报告中的网络流量使用情况。
18.Nagios — 网络/服务器监控
Nagios 是一个领先的开源的强大的监控系统,网络/系统管理员在他们影响主要业务流程之前识别和解决服务器相关的问题。Nagios 可以监控远程 Linux、Windows、开关、单窗口的路由器和打印机。它能显示你的网络和服务器关键的告警,有利于在错误反生之前帮助你解决问题。
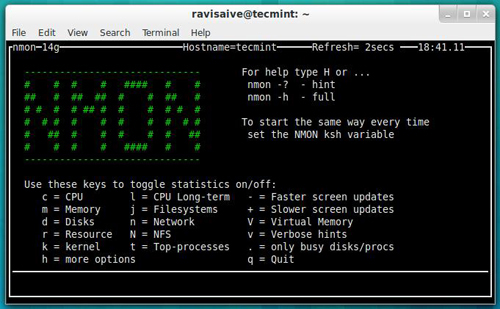
19.Nmon — 监控Linux系统性能
Nmon(即奈吉尔性能监视器)工具用来监视 Linux 系统的所有资源包括:CPU、内存、磁盘使用率、网络上的进程、NFS、内核等等。这个工具有两个模式:即在线模式和捕捉模式。在线模式适用于实时监控,捕捉模式用于存储输出为 CSV 格式后的处理。
20.Collectl — 一体化性能检测工具
Collectl 是另一个功能强大的基于命令行的监控工具,它可用于收集有关系统资源的信息,包括 CPU 使用率、内存、网络、节点、进程、NFS、TCP 套接等等。

我们想知道你使用什么样的监控程序来监控你的服务器性能?如果我们错过你想要的任何工具,请通过评论告知我们,并且不要忘记分享他。
如需转载请注明: 转载自26点的博客
本文链接地址: 20个常用Linux性能监控工具/命令