数据结构与算法:树 赫夫曼树
Posted 史大拿
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据结构与算法:树 赫夫曼树相关的知识,希望对你有一定的参考价值。
Tips: 采用java语言,关注博主,底部附有完整代码
工具:IDEA
本系列介绍的是数据结构: 树
这是第7篇目前计划一共有11篇:
- 二叉树入门
- 顺序二叉树
- 线索化二叉树
- 堆排序
- 赫夫曼树(一)
- 赫夫曼树(二)
- 赫夫曼树(三) 本篇
- 二叉排序树(BST)
- 平衡二叉排序树AVL
- 2-3树,2-3-4树,B树 B+树 B*树 了解
- 数据结构与算法:树 红黑树 (十一)
敬请期待吧~~
回顾与分析
前两篇:
都是说如何生成一颗赫夫曼树,那么本篇是赫夫曼树的最后一篇,来说说赫夫曼树给文件的加密与解密!
既然涉及到文件加密解密,那么一定会涉及到以下知识点
- 二进制
- 流
如果不太清晰的同学不用担心,本篇会讲的详详细细,保证你看完醍醐灌顶!
既然说到文件的加密解密,那么先想想一般的文件是如何加密解密的
通常的流程都是
-
先自定义一串密钥
-
读取需要加密的文件,在读取过程中 将密钥添加到这个文件中,然后生成一个新的加密后的文件
-
这个加密后的文件是打不开的,因为已经被加密(破坏)了
-
解密的时候道理类似, 先读取加密后的文件,在通过密钥来修改这个文件,生成一个新的解谜后文件
很早之前写过一个C加密与解密,大家可以参考一下~
加密
文件都是byte组成的,读取过程中,生成赫夫曼树,为了好区分,以后叫赫夫曼对照表
在次读取文件, 根据赫夫曼对照表,生成一串新的二进制文件,因为二进制文件太长,所以需要每8位来存储一个字节
通过
- 赫夫曼对照表
- 加密后的字节
- 原始二进制长度
组成一个新的文件,这就是加密后的文件
解密
解密就是通过赫夫曼对照表,来将加密后二进制文件还原成原始文件即可
如果这段文字有所看不懂,那么不要紧,一步一步来~
文字编码(加密)
搞文件加密解密之前,先来弄弄文字加密尝尝鲜
在第二篇赫夫曼树中用到了一串文字
String str = "i like like like java do you like a java";
对应的赫夫曼树为:
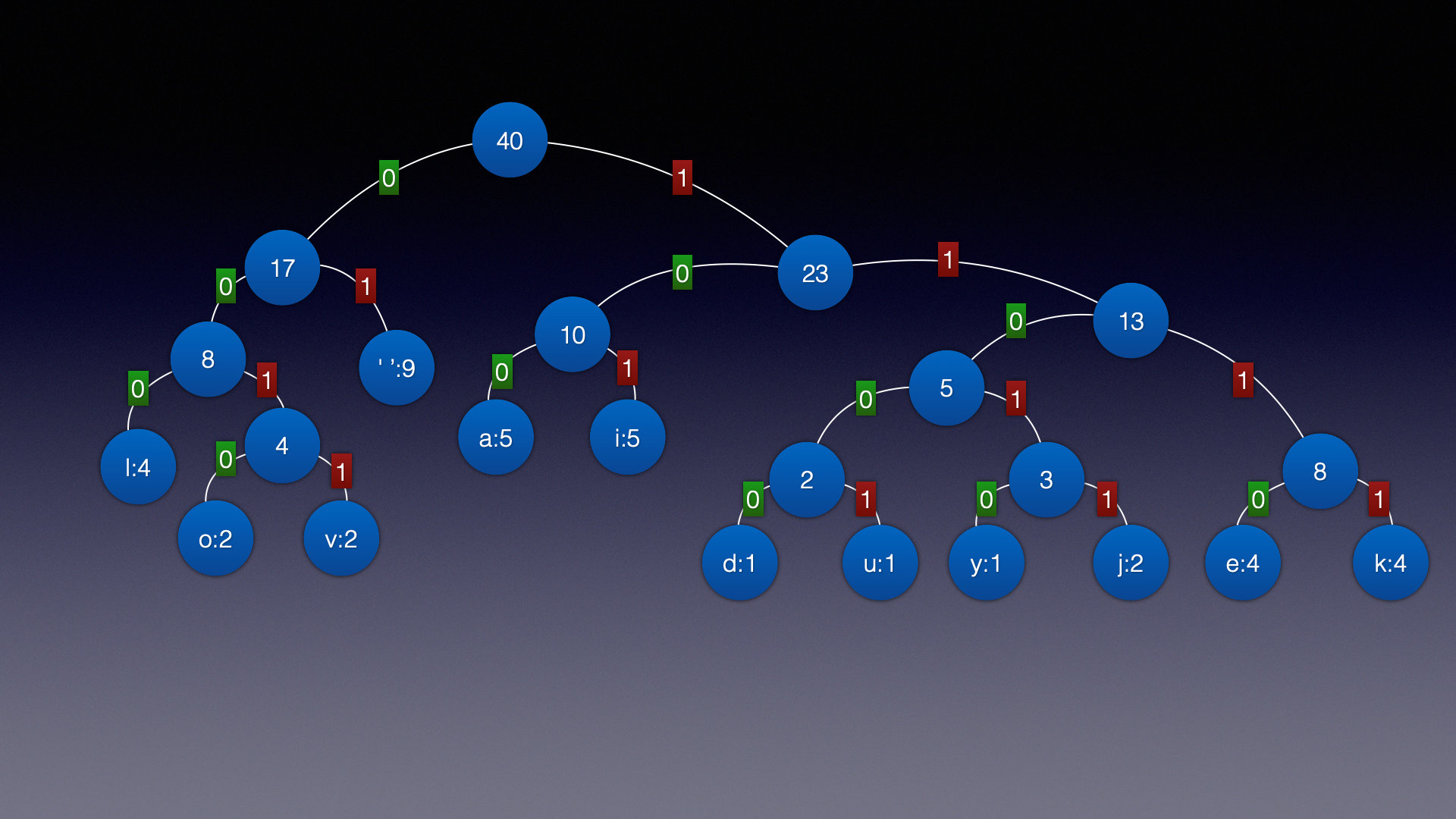
赫夫曼对照表为:
- 原始数据: 32=01, 97=100, 100=11000, 117=11001, 101=1110, 118=11011, 105=101, 121=11010, 106=0010, 107=1111, 108=000, 111=0011
- 翻译ASICC数据: 空格=01, a=100, d=11000, u=11001, e=1110, v=11011, i=101, y=11010, j=0010, k=1111, l=000, o=0011
tips: 以后全用原始数据,这里翻译ASICC只是方便理解!
首先将原始字节 通过赫夫曼树转变成二进制数据
public static void main(String[] args)
System.out.println("赫夫曼编码..");
String str = "i like like like java do you like a java";
// 生成赫夫曼对照表
...
// 通过赫夫曼树转变成二进制数据
String result = byteToBinary(codingMap, str.getBytes());
public static String byteToBinary(HashMap<Byte, String> codingMap, byte[] b)
// 用来存储编码过后的值!
StringBuilder stringBuilder = new StringBuilder();
// 通过赫夫曼对照表 依次转变为二进制数据
for (byte value : b)
stringBuilder.append(codingMap.get(value));
// stringBuilder.append("\\n");
String huffmanResult = stringBuilder.toString();
System.out.println("二进制数据为:" + huffmanResult + "\\nlength = " + huffmanResult.length());
return huffmanResult;
根据赫夫曼树编码后的数据为:
二进制数据为1010100010111111110010001011111111001000101111111100100101001101110001110000011011101000111100101000101111111100110001001010011011100
length = 133
到此时肯定还是不能进行传递的
因为原先数据:
String str = “i like like like java do you like a java”;
长度为40,如果传递二进制数据的话长度为133, 不仅没有起到任何优化作用,而且数据还变大了 300% 肯定是不合适的
那么则需要将二进制数据转变成字节
众所周知,每1个字节可以存储8位
那么只需要吧编码后的二进制每8位切割保存即可
代码如下:
public static byte[] binarySave8(String binary)
// 获取到最终的二进制数据
byte[] bytes = binary.getBytes();
int length;
// 一个字节可以存放8个元素,记录存放长度
if (bytes.length % 8 == 0)
length = bytes.length / 8;
else
length = bytes.length / 8 + 1;
// 存储最终byte结果
byte[] huffManBytes = new byte[length];
// 记录 huffManBytes 下标
int index = 0;
String sub;
// 一个byte存储8位,所以这里步长位8
for (int i = 0; i < binary.length(); i += 8)
// 为了保证最后 8个字节下标不越界
if (i + 8 > binary.length())
sub = binary.substring(i);
else
sub = binary.substring(i, i + 8);
// 将二进制转换为十进制存储
huffManBytes[index++] = (byte) Integer.parseInt(sub, 2);
return huffManBytes;
转换后的结果为:
[-88, -65, -56, -65, -56, -65, -55, 77, -57, 6, -24, -14, -117, -4, -60, -90, 28] 长度 = 17
可以看出,长度缩小了50% (原先长度40)
此时原先文字通过赫夫曼树 就加密成了
[-88, -65, -56, -65, -56, -65, -55, 77, -57, 6, -24, -14, -117, -4, -60, -90, 28]
文字解码(解密)
要解码的话一定得只要解码的前置条件:
-
赫夫曼对照表: 32=01, 97=111, 100=10000, 117=10001, 101=1001, 118=1010, 121=0000, 105=001, 106=1011, 107=1100, 108=1101, 111=0001
-
加密后的数据: [-88, -65, -56, -65, -56, -65, -55, 77, -57, 6, -24, -14, -117, -4, -60, -90, 28]
-
原始二进制长度: 133
思路
- 先将加密后的十进制数据转变成二进制数据
- 通过赫夫曼对照表依次找到对应的二进制数据即可
将加密后的十进制数据转变成二进制数据:
/*
* @author: android 超级兵
* @create: 2022/6/17 09:57
* TODO 解码
* @param huffManChart: 对照表
* @param result: 转码后的二进制数据
* @param huffManLength: 原始二进制长度
*/
public static ArrayList<Byte> deZip(HashMap<Byte, String> huffManChart, byte[] result, int huffManLength)
// 用来存储 解码后的二进制数据
StringBuilder sb = new StringBuilder();
System.out.println("原始二进制长度为:" + huffManLength);
for (int i = 0; i < result.length; i++)
byte element = result[i];
// 如果是最后一位,需要判断是否满8位
if (i == result.length - 1)
// 最后一位 不需要补高位
sb.append(byteToBitString(false, element, huffManLength));
else
// 不是最后一位
sb.append(byteToBitString(true, element, huffManLength));
System.out.println("转为二进制数据 = " + sb + "\\nlength = " + sb.length());
/*
* @author: android 超级兵
* @param flag: 是否需要补高位 【true不是最后一位】【false是最后一位】
* @param b: 对应的二进制字符串
* @param length: 原始数据长度
*/
private static String byteToBitString(boolean flag, byte b, int length)
int temp = b;
// 需要补高位
if (flag)
// | 两个位有一个为1 结果为1 否则为0
// tips: temp 必须是正数
temp |= 256;// 256 二进制为 1 0000 0000
// 10进制转二进制
String str = Integer.toBinaryString(temp);
// flag = true 表示不是最后一位
// temp < 0 表示当前是负数,需要截取8位
if (flag || temp < 0)
// 需要补高位
return str.substring(str.length() - 8);
else
// 说明是最后一位 截取最后几位
// 判断最后一个字节长度
int lastByteLength = length % 8;
// 如果长度刚好是8的倍数,并且倒数第8位刚好是0,那么就让最后一位 = 8 来计算长度
if (lastByteLength == 0)
lastByteLength = 8;
// 如果原始最后一个字节长度 > 当前解析的长度 说明需要补0
if (lastByteLength > str.length())
// 需要补多少个0
int t = lastByteLength - str.length();
// System.out.printf("需要补%d个\\n", t);
return String.format("%s%s", create0(t), str);
else
// 如果最后一个字节长度和截取的长度一致,说明不用补0
return str;
这段代码就是将加密后的数据转变成原始二进制数据
但是这段代码并不好理解…
加密后的数据转变成原始二进制数据
首先十进制转二进制有2种情况
- 正数
- 负数
以88 和 -28来举例
正数
int tempBin = 88;
tempBin |= 256;
System.out.println("256二进制为 = " + Integer.toBinaryString(256));
String bin = Integer.toBinaryString(tempBin);
System.out.println("二进制为 = " + bin);
结果:
256二进制为 = 100000000
二进制为 = 101011000
这里的重点就是 |=256
256 对应的二进制数据是 1 0000 0000
而|= 的特性是: 两位有1位为1结果为1,否则为0
用到这里恰好起到了补0的作用
如果这里看的有点懵,可以多看看java 原码,反码,补码,位运算 的基础!
负数
int tempBin = -28;
tempBin |= 256;
System.out.println("256二进制为 = " + Integer.toBinaryString(256));
String bin = Integer.toBinaryString(tempBin);
System.out.println("二进制为 = " + bin);
结果:
256二进制为 = 100000000
二进制为 = 11111111111111111111111111100100
负数的话直接截取后8位即可
此时解析后的数据为:
10111111
11001000
10111111
11001000
10111111
11001001
01001101
11000111
00000110
11101000
11110010
10001011
11111100
11000100
10100110
11100
假如最后一位不是11100,则是 01100的话,通过|= 256 也没有办法吧第一位的0补上
所以需要通过原始数据长度 % 8 和现在数据长度 % 8 来做比较,判断是否需要再次补0
这里 %8 是因为1byte = 8bit
这段代码只能自己细品,我研究了好久!! 越说越乱,自己走一遍流程就清晰了!
现在已经将加密后的数据转变成了原始二进制数据,那么只需要将原始二进制数据通过赫夫曼对照表转变成原始数据即可!
二进制数据通过赫夫曼对照表转变成原始数据
在转变之前赫夫曼对照表中key是字母 , value是二进制数据
在这里应该是通过value寻找key,很显然不符合Map的规范,所以需要将Map反转一下
吧key变成value , value变成key
public static HashMap<String, Byte> reverseMap(HashMap<Byte, String> map)
HashMap<String, Byte> hashMap = new HashMap<>();
// 遍历
map.forEach((key, value) -> hashMap.put(value, key));
return hashMap;
然后通过key循环依次寻找即可
/// 解析
// return 原始数据
public static ArrayList<Byte> deZip(HashMap<Byte, String> huffManChart, byte[] result, int huffManLength)
// 用来存储 解码后的二进制数据
StringBuilder sb = new StringBuilder();
System.out.println("原始二进制长度为:" + huffManLength);
for (int i = 0; i < result.length; i++)
byte element = result[i];
// 如果是最后一位,需要判断是否满8位
if (i == result.length - 1)
// 最后一位 不需要补高位
sb.append(byteToBitString(false, element, huffManLength));
else
// 不是最后一位
sb.append(byteToBitString(true, element, huffManLength));
sb.append("\\n");
System.out.println("转为二进制数据 = " + sb + "\\nlength = " + sb.length());
// 反转赫夫曼对照表 K = V,V = K
HashMap<String, Byte> huffManMap = reverseMap(huffManChart);
System.out.println("反转后的赫夫曼对照表为:" + huffManMap);
int len = huffManLength / 8;
if (huffManLength % 8 != 0)
len += 1;
// 用来保存数据
ArrayList<Byte> list = new ArrayList<>();
// 用来截取字符串
StringBuilder temp = new StringBuilder();
// 循环解析后的二进制数据
for (int i = 0; i < sb.toString().length(); i++)
char ch = sb.charAt(i);
// 一直添加到temp中
temp.append(ch);
// 判断赫夫曼对照表中是否包含数据
if (huffManMap.containsKey(temp.toString()))
// 找到了
Byte by = huffManMap.get(temp.toString());
// 存储找到的值
list.add(by);
// 清空当前存储数据,开始找下一个
temp = new StringBuilder();
return list;
最后将Array 转变成String即可!
public static String byteToString(ArrayList<Byte> list)
StringBuilder builder = new StringBuilder();
for (Byte element : list)
builder.append((char) (int) element);
return builder.toString();
调用:
// 解码
ArrayList<Byte> resultStr = deZip(huffManChart, result, huffmanResult.length());
String finalResult = byteToString(resultStr);
System.out.println("\\n最终解码结果为 = " + finalResult);
这里部分代码省略, 可以翻到底部查看完整代码!
流
为了防止有同学流的内容有点忘记,回顾一下简单的流操作
FileInputStream 与 FileOutputStream
// 文件读取地址
private static final String FILE_READ_PATH = "src/a20220606树/e赫夫曼树/zip/鲨鱼.jpeg";
// 写入文件路径
private static final String FILE_WRITE_PATH = "src/a20220606树/e赫夫曼树/zip/鲨鱼(write).jpeg";
public static void testFileStream() throws IOException
// 文件输入流
FileInputStream input = null;
// 文件输出流
FileOutputStream output = null;
try
// ================== 文件输入流(读取文件) ==================
input = new FileInputStream(FILE_READ_PATH);
// input.available() 获取文件总长度
byte[] readByte = new byte[input.available()];
// 文件读取
input.read(readByte);
// ================== 文件输出流(写出文件) ==================
output = new FileOutputStream(FILE_WRITE_PATH);
// 写入文件
output.write(readByte);
catch (Exception e)
e.printStackTrace();
finally
if (input != null)
input.close();
if (output != null)
output.close();
System.out.println("操作成功,并且关流");
代码很简单,应该看看就能看懂!
ObjectOutputStream 与 ObjectInputStream
主要用来存储序列化对象:
public static void testObjectStream() throws IOException, ClassNotFoundException
System.out.println();
System.out.println();
System.out.println("ObjectOutputStream 与 ObjectInputStream~");
System.out.println();
System.out.println();
// 对象输出流
ObjectOutputStream objectOutputStream = null;
// 对象输入流
ObjectInputStream objectInputStream = null;
try
objectOutputStream = new ObjectOutputStream(new FileOutputStream(FILE_OBJECT_PATH));
// 写入对象
objectOutputStream.writeObject(new TestFileBean("张三", 11));
objectOutputStream.writeObject(new TestFileBean("李四", 15));
// 读取对象
objectInputStream = new ObjectInputStream(new FileInputStream(FILE_OBJECT_PATH));
TestFileBean bean1 = (以上是关于数据结构与算法:树 赫夫曼树的主要内容,如果未能解决你的问题,请参考以下文章