Paddle入门实战系列:基于PaddleOCR的车牌识别
Posted GoAI
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Paddle入门实战系列:基于PaddleOCR的车牌识别相关的知识,希望对你有一定的参考价值。
✨写在前面:强烈推荐给大家一个优秀的人工智能学习网站,内容包括人工智能基础、机器学习、深度学习神经网络等,详细介绍各部分概念及实战教程,通俗易懂,非常适合人工智能领域初学者及研究者学习。➡️点击跳转到网站。
项目背景
- 车牌识别技术是智能交通的重要环节,目前已广泛应用于例如停车场、收费站等等交通设施中,提供高效便捷的车辆认证的服务,其中较为典型的应用场景为卡口系统。车牌识别即识别车牌上的文字信息,属于光学字符识别(OCR)的一项子任务。

项目流程
- 本项目基于Paddleocr完成深度学习车牌识别,项目可分为车牌检测与车牌识别两部分,主要流程为数据预处理、模型训练、导出推理模型、测试。
- 检测车牌所在图片位置
- 识别车牌图片具体内容
项目链接:基于Paddle的智慧交通预测系统 - 飞桨AI Studio
PaddleOCR介绍
主要由DB文本检测、检测框矫正和CRNN文本识别三部分组成。该系统从骨干网络选择和调整、预测头部的设计、数据增强、学习率变换策略、正则化参数选择、预训练模型使用以及模型自动裁剪量化8个方面,采用19个有效策略,对各个模块的模型进行效果调优和瘦身(如绿框所示),最终得到整体大小为3.5M的超轻量中英文OCR和2.8M的英文数字OCR。
数据集介绍
本项目数据集采用CCPD2019和CCPD02020车牌数据集,以CCPD02020演示车牌识别流程,其训练、验证、测试数据集已划分完毕,测试集包含5006张图片,大小共865.66M。本项目演示的CCPD20数据集的采集方式与CCPD19类似,其中均为新能源车辆的车牌,其命名为ccpd_green路径。
-
CCPD2020/ccpd_green/
--train
--val
--test

文件名即图片标注,具体含义可查看源网址,以下为数据集解读参考。
“025-95_113-154&383_386&473-386&473_177&454_154&383_363&402-0_0_22_27_27_33_16-37-15.jpg”.
数据集字段解释参考:
CCPD数据集没有专门的标注文件,每张图像的文件名就是对应的数据标注(label)
例如:025-95_113-154&383_386&473-386&473_177&454_154&383_363&402-0_0_22_27_27_33_16-37-15.jpg 由分隔符'-'分为几个部分:
- 025为区域
- 95_113 对应两个角度, 水平95°, 竖直113°
- 154&383_386&473对应边界框坐标:左上(154, 383), 右下(386, 473)
- 386&473_177&454_154&383_363&402对应四个角点坐标
- 0_0_22_27_27_33_16为车牌号码 映射关系如下: 第一个为省份0 对应省份字典皖, 后面的为字母和文字, 查看ads字典.如0为A, 22为Y....
安装PaddleOCR环境
#下载PaddleOCR
%cd ~/
!git clone -b release/2.1 https://github.com/PaddlePaddle/PaddleOCR.git#安装环境
%cd PaddleOCR
!pip install -r requirments.txt
!pip install --upgrade scipy
# !pip install -r requirements.txt -i https://mirror.baidu.com/pypi/simple数据预处理
字典内容:
车牌省份: provinces = [“皖”, “沪”, “津”, “渝”, “冀”, “晋”, “蒙”, “辽”, “吉”, “黑”, “苏”, “浙”, “京”, “闽”, “赣”, “鲁”, “豫”, “鄂”, “湘”, “粤”, “桂”, “琼”, “川”, “贵”, “云”, “藏”, “陕”, “甘”, “青”, “宁”, “新”, “警”, “学”, “O”]
alphabets = [‘A’, ‘B’, ‘C’, ‘D’, ‘E’, ‘F’, ‘G’, ‘H’, ‘J’, ‘K’, ‘L’, ‘M’, ‘N’, ‘P’, ‘Q’, ‘R’, ‘S’, ‘T’, ‘U’, ‘V’, ‘W’, ‘X’, ‘Y’, ‘Z’, ‘O’]
ads = [‘A’, ‘B’, ‘C’, ‘D’, ‘E’, ‘F’, ‘G’, ‘H’, ‘J’, ‘K’, ‘L’, ‘M’, ‘N’, ‘P’, ‘Q’, ‘R’, ‘S’, ‘T’, ‘U’, ‘V’, ‘W’, ‘X’, ‘Y’, ‘Z’, ‘0’, ‘1’, ‘2’, ‘3’, ‘4’, ‘5’, ‘6’, ‘7’, ‘8’, ‘9’, ‘O’]
!unzip -q data/data168819/CCPD2020.zip -d work/CCPD2020检测数据:转换成官方提供的icdar格式
格式如下:
transcription为具体内容,points存放检测车牌坐标
03706896551724138-90_263-185&516_545&610-543&607_194&610_185&518_545&516-0_0_3_29_27_33_24_33-59-41.jpg ["transcription": "皖AD53909", "points": [[185, 518], [545, 516], [543, 607], [194, 610]]] /034782088122605366-92_244-167&522_517&612-517&612_195&590_167&522_497&539-0_0_3_24_30_30_33_25-102-110.jpg ["transcription": "皖AD06691", "points": [[167, 522], [497, 539], [517, 612], [195, 590]]]
In [ ]
#转换检测数据,打开注释执行三次生成训练所需txt文件,分别为train、val、test。
%cd ~
import os, cv2
words_list = [
"A", "B", "C", "D", "E",
"F", "G", "H", "J", "K",
"L", "M", "N", "P", "Q",
"R", "S", "T", "U", "V",
"W", "X", "Y", "Z", "0",
"1", "2", "3", "4", "5",
"6", "7", "8", "9" ]
con_list = [
"皖", "沪", "津", "渝", "冀",
"晋", "蒙", "辽", "吉", "黑",
"苏", "浙", "京", "闽", "赣",
"鲁", "豫", "鄂", "湘", "粤",
"桂", "琼", "川", "贵", "云",
"西", "陕", "甘", "青", "宁",
"新"]
count = 0
# data = open('work/train_data_det.txt', 'w', encoding='UTF-8')
# data = open('work/val_data_det.txt', 'w', encoding='UTF-8')
data = open('work/test_data_det.txt', 'w', encoding='UTF-8')
# for item in os.listdir('work/CCPD2020/CCPD2020/ccpd_green/train'):
# for item in os.listdir('work/CCPD2020/CCPD2020/ccpd_green/val'):
for item in os.listdir('work/CCPD2020/CCPD2020/ccpd_green/test'):
# path = 'work/CCPD2020/CCPD2020/ccpd_green/train/'+item
# path = 'work/CCPD2020/CCPD2020/ccpd_green/val/'+item
path = 'work/CCPD2020/CCPD2020/ccpd_green/test/'+item
_, _, bbox, points, label, _, _ = item.split('-')
points = points.split('_')
points = [_.split('&') for _ in points]
tmp = points[-2:]+points[:2]
points = []
for point in tmp:
points.append([int(_) for _ in point])
label = label.split('_')
con = con_list[int(label[0])]
words = [words_list[int(_)] for _ in label[1:]]
label = con+''.join(words)
line = path+'\\t'+'["transcription": "%s", "points": %s]' % (label, str(points))
line = line[:]+'\\n'
data.write(line)
total = []
# with open('work/train_data_det.txt', 'r', encoding='UTF-8') as f:
# for line in f:
# total.append(line)
# with open('work/val_data_det.txt', 'r', encoding='UTF-8') as f:
# for line in f:
# total.append(line)
with open('work/test_data_det.txt', 'r', encoding='UTF-8') as f:
for line in f:
total.append(line)
# with open('work/train_det.txt', 'w', encoding='UTF-8') as f:
# for line in total[:-500]:
# f.write(line)
# with open('work/dev_det.txt', 'w', encoding='UTF-8') as f:
# for line in total[-500:]:
# f.write(line)/home/aistudio
In [ ]
#识别数据:转换成PaddleOCR使用的格式(图片名+内容),打开注释执行三次生成训练所需txt文件,分别为train、val、test。
%cd ~
import os, cv2
words_list = [
"A", "B", "C", "D", "E",
"F", "G", "H", "J", "K",
"L", "M", "N", "P", "Q",
"R", "S", "T", "U", "V",
"W", "X", "Y", "Z", "0",
"1", "2", "3", "4", "5",
"6", "7", "8", "9" ]
con_list = [
"皖", "沪", "津", "渝", "冀",
"晋", "蒙", "辽", "吉", "黑",
"苏", "浙", "京", "闽", "赣",
"鲁", "豫", "鄂", "湘", "粤",
"桂", "琼", "川", "贵", "云",
"西", "陕", "甘", "青", "宁",
"新"]
# if not os.path.exists('work/img'): #所有数据集都放入一个文件夹
# os.mkdir('work/img')
#训练、验证、测试集分开三个文件夹对应解开注释依次执行三次
# if not os.path.exists('work/train_rec_img'):
# os.mkdir('work/train_rec_img')
if not os.path.exists('work/val_rec_img'):
os.mkdir('work/val_rec_img')
# if not os.path.exists('work/test_rec_img'):
# os.mkdir('work/test_rec_img')
count = 0
# data = open('work/train_data_rec.txt', 'w', encoding='UTF-8')
data = open('work/val_data_rec.txt', 'w', encoding='UTF-8')
# data = open('work/test_data_rec.txt', 'w', encoding='UTF-8')
# for item in os.listdir('work/CCPD2020/CCPD2020/ccpd_green/train'):
for item in os.listdir('work/CCPD2020/CCPD2020/ccpd_green/val'):
# for item in os.listdir('work/CCPD2020/CCPD2020/ccpd_green/test'):
# path = 'work/CCPD2020/CCPD2020/ccpd_green/train/'+item
path = 'work/CCPD2020/CCPD2020/ccpd_green/val/'+item
# path = 'work/CCPD2020/CCPD2020/ccpd_green/test/'+item
#原来的 path = 'work/CCPD2020/ccpd_base/'+item
_, _, bbox, _, label, _, _ = item.split('-')
bbox = bbox.split('_')
x1, y1 = bbox[0].split('&')
x2, y2 = bbox[1].split('&')
label = label.split('_')
con = con_list[int(label[0])]
words = [words_list[int(_)] for _ in label[1:]]
label = con+''.join(words)
bbox = [int(_) for _ in [x1, y1, x2, y2]]
img = cv2.imread(path)
crop = img[bbox[1]:bbox[3], bbox[0]:bbox[2], :]
# cv2.imwrite('work/train_rec_img/%06d.jpg' % count, crop)
# data.write('work/train_rec_img/%06d.jpg\\t%s\\n' % (count, label))
cv2.imwrite('work/val_rec_img/%06d.jpg' % count, crop)
data.write('work/val_rec_img/%06d.jpg\\t%s\\n' % (count, label))
# cv2.imwrite('work/test_rec_img/%06d.jpg' % count, crop)
# data.write('work/test_rec_img/%06d.jpg\\t%s\\n' % (count, label))
count += 1
data.close()
with open('work/word_dict.txt', 'w', encoding='UTF-8') as f:
for line in words_list+con_list:
f.write(line+'\\n')
# total = []
# with open('work/train_data_rec.txt', 'r', encoding='UTF-8') as f:
# for line in f:
# total.append(line)
with open('work/val_data_rec.txt', 'r', encoding='UTF-8') as f:
for line in f:
total.append(line)
# with open('work/test_data_rec.txt', 'r', encoding='UTF-8') as f:
# for line in f:
# total.append(line)
/home/aistudio
最终文件生成效果:
- 注:”由于work文件较大,无法生成版本,读者可执行上述代码生成下述对应文件,也可以自行修改代码,放到其他路径。
- 下图为work目录下,其中CCPD为本项目CCPD2020数据(解压到work目录下),另三个rec_img文件夹为用于识别流程的图片,img为三个汇总,其余为用于检测det与识别rec生成的txt文本。
模型介绍
PaddleOCR提供的检测与识别模型如下:
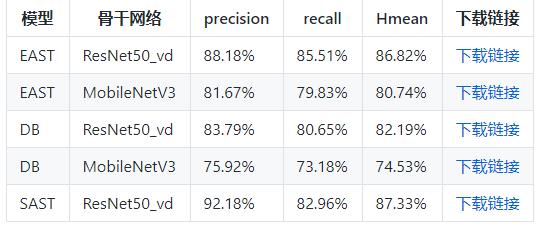
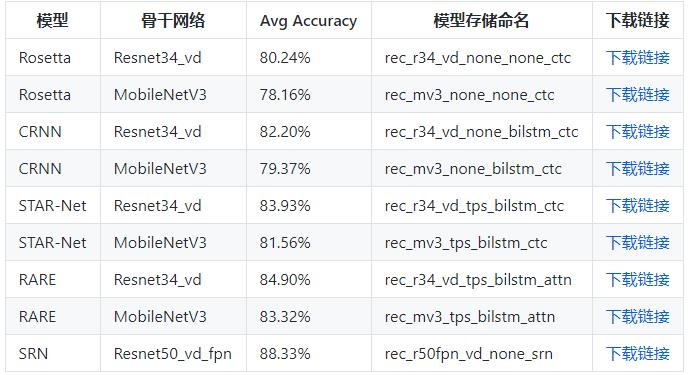
模型选择
Paddocr提供以下文件检测及识别模型,考虑车牌识别中字符数量较少,而且长度也固定,且为标准的印刷字体,所以无需使用过于复杂的模型。因此,参考其他开源资料,本项目选择经典的DBNet+RARE,两个模型均使用MobileNetV3作为其主干网络(Backbone)。
DBNet与RARE算法介绍可参考我的博客:OCR文字识别经典论文详解
DBNet
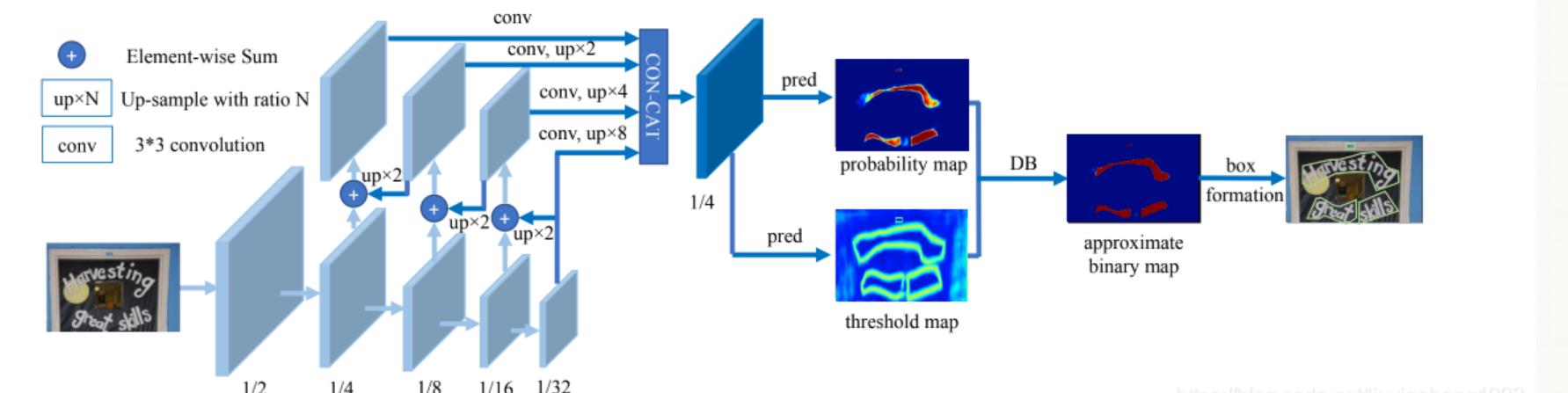
RARE

下载对应预训练模型
In [ ]
%cd ~/work/PaddleOCR
# 下载预训练模型
!wget -P ./pretrain_models/ https://paddleocr.bj.bcebos.com/ch_models/ch_det_mv3_db.tar
!wget -P ./pretrain_models/ https://paddleocr.bj.bcebos.com/rec_mv3_tps_bilstm_attn.tar
# 解压模型参数
%cd pretrain_models
!tar -xf ch_det_mv3_db.tar && rm -rf ch_det_mv3_db.tar
!tar -xf rec_mv3_tps_bilstm_attn.tar && rm -rf rec_mv3_tps_bilstm_attn.tar模型训练
1.检测模型训练
检测模版文件 configs/det/det_mv3_db.yml
Global:
algorithm: DB
use_gpu: true
epoch_num: 1200
log_smooth_window: 20
print_batch_step: 20
save_model_dir: ./myoutput/det_db/
save_epoch_step: 10
# evaluation is run every 5000 iterations after the 4000th iteration
eval_batch_step: [100, 500]
train_batch_size_per_card: 4
test_batch_size_per_card: 4
image_shape: [3, 640, 640]
reader_yml: ./configs/det/det_db_icdar15_reader.yml
pretrain_weights: ./pretrain_models/det_mv3_db/best_accuracy
checkpoints:
save_res_path: ./myoutput/det_db/predicts_db.txt
save_inference_dir:
Architecture:
function: ppocr.modeling.architectures.det_model,DetModel
Backbone:
function: ppocr.modeling.backbones.det_mobilenet_v3,MobileNetV3
scale: 0.5
model_name: large
Head:
function: ppocr.modeling.heads.det_db_head,DBHead
model_name: large
k: 50
inner_channels: 96
out_channels: 2
Loss:
function: ppocr.modeling.losses.det_db_loss,DBLoss
balance_loss: true
main_loss_type: DiceLoss
alpha: 5
beta: 10
ohem_ratio: 3
Optimizer:
function: ppocr.optimizer,AdamDecay
base_lr: 0.001
beta1: 0.9
beta2: 0.999
PostProcess:
function: ppocr.postprocess.db_postprocess,DBPostProcess
thresh: 0.3
box_thresh: 0.7
max_candidates: 1000
unclip_ratio: 2.0
In [ ]
%cd ~/PaddleOCR
# 设置PYTHONPATH路径
%env PYTHONPATH=$PYTHONPATH:.
# GPU单卡训练
%env CUDA_VISIBLE_DEVICES=0
!python3 tools/train.py -c configs/det/det_mv3_db.yml2.识别
主干网络为轻量级网络MobilenetV3,识别算法包括TPS校正+双向LSTM+Attention
Global:
algorithm: RARE
use_gpu: true
epoch_num: 200
log_smooth_window: 20
print_batch_step: 20
#save_model_dir: output/rec_RARE
save_model_dir: ./myoutput/rec_RARE_atten_new
save_epoch_step: 100
eval_batch_step: 500
train_batch_size_per_card: 256
test_batch_size_per_card: 256
image_shape: [3, 32, 320]
max_text_length: 8
character_type: ch
character_dict_path: ../word_dict.txt
loss_type: attention
tps: true
reader_yml: ./configs/rec/rec_chinese_reader.yml
pretrain_weights: ./pretrain_models/rec_mv3_tps_bilstm_attn/best_accuracy
# pretrain_weights:
checkpoints:
save_inference_dir: ./inference/newimg_rec_rare
infer_img:
Architecture:
function: ppocr.modeling.architectures.rec_model,RecModel
TPS:
function: ppocr.modeling.stns.tps,TPS
num_fiducial: 20
loc_lr: 0.1
model_name: small
Backbone:
function: ppocr.modeling.backbones.rec_mobilenet_v3,MobileNetV3
scale: 0.5
model_name: large
Head:
function: ppocr.modeling.heads.rec_attention_head,AttentionPredict
encoder_type: rnn
SeqRNN:
hidden_size: 96
Attention:
decoder_size: 96
word_vector_dim: 96
Loss:
function: ppocr.modeling.losses.rec_attention_loss,AttentionLoss
Optimizer:
function: ppocr.optimizer,AdamDecay
base_lr: 0.001
beta1: 0.9
beta2: 0.999
In [77]
%cd ~/PaddleOCR
# GPU单卡训练
%env CUDA_VISIBLE_DEVICES=0
!python3 tools/train.py -c configs/rec/rec_mv3_tps_bilstm_attn.yml/home/aistudio/work/PaddleOCR env: CUDA_VISIBLE_DEVICES=0 2022-09-15 16:06:31,610-INFO: 'Global': 'debug': False, 'algorithm': 'RARE', 'use_gpu': True, 'epoch_num': 200, 'log_smooth_window': 20, 'print_batch_step': 20, 'save_model_dir': './myoutput/rec_RARE_atten_new', 'save_epoch_step': 100, 'eval_batch_step': 500, 'train_batch_size_per_card': 256, 'test_batch_size_per_card': 256, 'image_shape': [3, 32, 320], 'max_text_length': 8, 'character_type': 'ch', 'character_dict_path': '../word_dict.txt', 'loss_type': 'attention', 'tps': True, 'reader_yml': './configs/rec/rec_chinese_reader.yml', 'pretrain_weights': './pretrain_models/rec_mv3_tps_bilstm_attn/best_accuracy', 'checkpoints': None, 'save_inference_dir': './inference/newimg_rec_rare', 'infer_img': None, 'Architecture': 'function': 'ppocr.modeling.architectures.rec_model,RecModel', 'TPS': 'function': 'ppocr.modeling.stns.tps,TPS', 'num_fiducial': 20, 'loc_lr': 0.1, 'model_name': 'small', 'Backbone': 'function': 'ppocr.modeling.backbones.rec_mobilenet_v3,MobileNetV3', 'scale': 0.5, 'model_name': 'large', 'Head': 'function': 'ppocr.modeling.heads.rec_attention_head,AttentionPredict', 'encoder_type': 'rnn', 'SeqRNN': 'hidden_size': 96, 'Attention': 'decoder_size': 96, 'word_vector_dim': 96, 'Loss': 'function': 'ppocr.modeling.losses.rec_attention_loss,AttentionLoss', 'Optimizer': 'function': 'ppocr.optimizer,AdamDecay', 'base_lr': 0.001, 'beta1': 0.9, 'beta2': 0.999, 'TrainReader': 'reader_function': 'ppocr.data.rec.dataset_traversal,SimpleReader', 'num_workers': 8, 'img_set_dir': '../..', 'label_file_path': '../train_data_rec.txt', 'EvalReader': 'reader_function': 'ppocr.data.rec.dataset_traversal,SimpleReader', 'num_workers': 8, 'img_set_dir': '../..', 'label_file_path': '../val_data_rec.txt', 'TestReader': 'reader_function': 'ppocr.data.rec.dataset_traversal,SimpleReader' 2022-09-15 16:06:32,400-INFO: If regularizer of a Parameter has been set by 'fluid.ParamAttr' or 'fluid.WeightNormParamAttr' already. The Regularization[L2Decay, regularization_coeff=0.000000] in Optimizer will not take effect, and it will only be applied to other Parameters! 2022-09-15 16:06:34,241-INFO: places would be ommited when DataLoader is not iterable W0915 16:06:34.303215 18580 device_context.cc:252] Please NOTE: device: 0, CUDA Capability: 70, Driver API Version: 11.2, Runtime API Version: 9.0 W0915 16:06:34.307891 18580 device_context.cc:260] device: 0, cuDNN Version: 7.6. 2022-09-15 16:06:36,359-INFO: Loading parameters from ./pretrain_models/rec_mv3_tps_bilstm_attn/best_accuracy... 2022-09-15 16:06:36,425-WARNING: variable embedding_0.w_0 not used 2022-09-15 16:06:36,425-WARNING: variable rnn_out_fc.w_0 not used 2022-09-15 16:06:36,425-WARNING: variable rnn_out_fc.b_0 not used 2022-09-15 16:06:36,470-INFO: Finish initing model from ./pretrain_models/rec_mv3_tps_bilstm_attn/best_accuracy 2022-09-15 16:06:47,710-INFO: epoch: 1, iter: 20, lr: 0.001000, 'loss': 4937.542, 'acc': 0.0, time: 0.387 2022-09-15 16:06:56,909-INFO: epoch: 2, iter: 40, lr: 0.001000, 'loss': 3201.4744, 'acc': 0.0, time: 0.373 2022-09-15 16:07:06,105-INFO: epoch: 3, iter: 60, lr: 0.001000, 'loss': 2400.3447, 'acc': 0.007812, time: 0.374 2022-09-15 16:07:16,551-INFO: epoch: 5, iter: 80, lr: 0.001000, 'loss': 1625.6213, 'acc': 0.146484, time: 1.787 2022-09-15 16:07:25,677-INFO: epoch: 6, iter: 100, lr: 0.001000, 'loss': 740.44006, 'acc': 0.769531, time: 0.376 2022-09-15 16:07:34,829-INFO: epoch: 7, iter: 120, lr: 0.001000, 'loss': 370.51062, 'acc': 0.902344, time: 0.374 2022-09-15 16:07:43,827-INFO: epoch: 8, iter: 140, lr: 0.001000, 'loss': 281.9944, 'acc': 0.929688, time: 0.374 2022-09-15 16:07:54,266-INFO: epoch: 10, iter: 160, lr: 0.001000, 'loss': 213.27815, 'acc': 0.933594, time: 1.769 2022-09-15 16:08:03,481-INFO: epoch: 11, iter: 180, lr: 0.001000, 'loss': 149.04875, 'acc': 0.949219, time: 0.403 2022-09-15 16:08:12,440-INFO: epoch: 12, iter: 200, lr: 0.001000, 'loss': 119.06343, 'acc': 0.951172, time: 0.374 2022-09-15 16:08:21,519-INFO: epoch: 13, iter: 220, lr: 0.001000, 'loss': 100.26872, 'acc': 0.949219, time: 0.373 2022-09-15 16:08:32,031-INFO: epoch: 15, iter: 240, lr: 0.001000, 'loss': 84.79035, 'acc': 0.970703, time: 1.806 2022-09-15 16:08:41,146-INFO: epoch: 16, iter: 260, lr: 0.001000, 'loss': 79.10332, 'acc': 0.966797, time: 0.409 2022-09-15 16:08:50,249-INFO: epoch: 17, iter: 280, lr: 0.001000, 'loss': 97.50918, 'acc': 0.955078, time: 0.373 2022-09-15 16:08:59,211-INFO: epoch: 18, iter: 300, lr: 0.001000, 'loss': 81.51908, 'acc': 0.960938, time: 0.373 2022-09-15 16:09:09,670-INFO: epoch: 20, iter: 320, lr: 0.001000, 'loss': 153.25719, 'acc': 0.935547, time: 1.713 2022-09-15 16:09:18,849-INFO: epoch: 21, iter: 340, lr: 0.001000, 'loss': 122.89736, 'acc': 0.949219, time: 0.399 2022-09-15 16:09:28,010-INFO: epoch: 22, iter: 360, lr: 0.001000, 'loss': 78.92976, 'acc': 0.958984, time: 0.373 2022-09-15 16:09:37,014-INFO: epoch: 23, iter: 380, lr: 0.001000, 'loss': 53.346596, 'acc': 0.972656, time: 0.373 2022-09-15 16:09:47,468-INFO: epoch: 25, iter: 400, lr: 0.001000, 'loss': 52.11016, 'acc': 0.972656, time: 1.756 2022-09-15 16:09:56,459-INFO: epoch: 26, iter: 420, lr: 0.001000, 'loss': 43.66102, 'acc': 0.972656, time: 0.374 2022-09-15 16:10:05,548-INFO: epoch: 27, iter: 440, lr: 0.001000, 'loss': 38.42436, 'acc': 0.980469, time: 0.373 2022-09-15 16:10:14,536-INFO: epoch: 28, iter: 460, lr: 0.001000, 'loss': 45.512665, 'acc': 0.978516, time: 0.373 2022-09-15 16:10:25,020-INFO: epoch: 30, iter: 480, lr: 0.001000, 'loss': 40.709595, 'acc': 0.976562, time: 1.789 2022-09-15 16:10:34,337-INFO: epoch: 31, iter: 500, lr: 0.001000, 'loss': 39.14653, 'acc': 0.974609, time: 0.412 2022-09-15 16:10:36,277-INFO: Already save model in ./myoutput/rec_RARE_atten_new/best_accuracy 2022-09-15 16:10:36,277-INFO: Test iter: 500, acc:0.777223, best_acc:0.777223, best_epoch:31, best_batch_id:500, eval_sample_num:1001 2022-09-15 16:10:45,402-INFO: epoch: 32, iter: 520, lr: 0.001000, 'loss': 33.690575, 'acc': 0.984375, time: 0.377 2022-09-15 16:10:54,503-INFO: epoch: 33, iter: 540, lr: 0.001000, 'loss': 29.822884, 'acc': 0.982422, time: 0.374 2022-09-15 16:11:05,027-INFO: epoch: 35, iter: 560, lr: 0.001000, 'loss': 33.394993, 'acc': 0.980469, time: 1.868 2022-09-15 16:11:14,148-INFO: epoch: 36, iter: 580, lr: 0.001000, 'loss': 29.375713, 'acc': 0.980469, time: 0.419 2022-09-15 16:11:23,142-INFO: epoch: 37, iter: 600, lr: 0.001000, 'loss': 44.640976, 'acc': 0.976562, time: 0.374 2022-09-15 16:11:32,155-INFO: epoch: 38, iter: 620, lr: 0.001000, 'loss': 32.55059, 'acc': 0.988281, time: 0.373 2022-09-15 16:11:42,665-INFO: epoch: 40, iter: 640, lr: 0.001000, 'loss': 24.32478, 'acc': 0.988281, time: 1.872 2022-09-15 16:11:51,777-INFO: epoch: 41, iter: 660, lr: 0.001000, 'loss': 23.933027, 'acc': 0.986328, time: 0.375 2022-09-15 16:12:00,873-INFO: epoch: 42, iter: 680, lr: 0.001000, 'loss': 24.20562, 'acc': 0.990234, time: 0.376 2022-09-15 16:12:09,940-INFO: epoch: 43, iter: 700, lr: 0.001000, 'loss': 20.969837, 'acc': 0.988281, time: 0.374 2022-09-15 16:12:20,566-INFO: epoch: 45, iter: 720, lr: 0.001000, 'loss': 21.603209, 'acc': 0.988281, time: 1.798 2022-09-15 16:12:29,785-INFO: epoch: 46, iter: 740, lr: 0.001000, 'loss': 14.918937, 'acc': 0.992188, time: 0.380 2022-09-15 16:12:38,854-INFO: epoch: 47, iter: 760, lr: 0.001000, 'loss': 16.47085, 'acc': 0.992188, time: 0.373 2022-09-15 16:12:47,954-INFO: epoch: 48, iter: 780, lr: 0.001000, 'loss': 13.787853, 'acc': 0.992188, time: 0.373 2022-09-15 16:12:58,526-INFO: epoch: 50, iter: 800, lr: 0.001000, 'loss': 20.16197, 'acc': 0.990234, time: 1.886 2022-09-15 16:13:07,622-INFO: epoch: 51, iter: 820, lr: 0.001000, 'loss': 15.042562, 'acc': 0.992188, time: 0.413 2022-09-15 16:13:16,744-INFO: epoch: 52, iter: 840, lr: 0.001000, 'loss': 30.320072, 'acc': 0.980469, time: 0.374 2022-09-15 16:13:25,803-INFO: epoch: 53, iter: 860, lr: 0.001000, 'loss': 27.366596, 'acc': 0.984375, time: 0.373 2022-09-15 16:13:36,263-INFO: epoch: 55, iter: 880, lr: 0.001000, 'loss': 107.29559, 'acc': 0.964844, time: 1.804 2022-09-15 16:13:45,315-INFO: epoch: 56, iter: 900, lr: 0.001000, 'loss': 112.5357, 'acc': 0.9375, time: 0.377 2022-09-15 16:13:54,380-INFO: epoch: 57, iter: 920, lr: 0.001000, 'loss': 80.11721, 'acc': 0.951172, time: 0.375 2022-09-15 16:14:03,521-INFO: epoch: 58, iter: 940, lr: 0.001000, 'loss': 173.3816, 'acc': 0.896484, time: 0.375 2022-09-15 16:14:14,176-INFO: epoch: 60, iter: 960, lr: 0.001000, 'loss': 111.91419, 'acc': 0.943359, time: 1.820 2022-09-15 16:14:23,354-INFO: epoch: 61, iter: 980, lr: 0.001000, 'loss': 67.807884, 'acc': 0.964844, time: 0.418 2022-09-15 16:14:32,359-INFO: epoch: 62, iter: 1000, lr: 0.001000, 'loss': 49.46469, 'acc': 0.972656, time: 0.382 2022-09-15 16:14:34,236-INFO: Already save model in ./myoutput/rec_RARE_atten_new/best_accuracy 2022-09-15 16:14:34,237-INFO: Test iter: 1000, acc:0.782218, best_acc:0.782218, best_epoch:62, best_batch_id:1000, eval_sample_num:1001 2022-09-15 16:14:43,256-INFO: epoch: 63, iter: 1020, lr: 0.001000, 'loss': 43.5632, 'acc': 0.972656, time: 0.373 2022-09-15 16:14:53,769-INFO: epoch: 65, iter: 1040, lr: 0.001000, 'loss': 31.788738, 'acc': 0.984375, time: 1.797 2022-09-15 16:15:02,909-INFO: epoch: 66, iter: 1060, lr: 0.001000, 'loss': 24.396, 'acc': 0.984375, time: 0.411 2022-09-15 16:15:12,029-INFO: epoch: 67, iter: 1080, lr: 0.001000, 'loss': 21.756264, 'acc': 0.992188, time: 0.374 2022-09-15 16:15:21,012-INFO: epoch: 68, iter: 1100, lr: 0.001000, 'loss': 18.515491, 'acc': 0.988281, time: 0.379 2022-09-15 16:15:31,652-INFO: epoch: 70, iter: 1120, lr: 0.001000, 'loss': 28.279198, 'acc': 0.980469, time: 1.828 2022-09-15 16:15:40,799-INFO: epoch: 71, iter: 1140, lr: 0.001000, 'loss': 23.729788, 'acc': 0.988281, time: 0.374 2022-09-15 16:15:49,867-INFO: epoch: 72, iter: 1160, lr: 0.001000, 'loss': 19.145424, 'acc': 0.988281, time: 0.374 2022-09-15 16:15:58,914-INFO: epoch: 73, iter: 1180, lr: 0.001000, 'loss': 16.507511, 'acc': 0.992188, time: 0.374 2022-09-15 16:16:09,365-INFO: epoch: 75, iter: 1200, lr: 0.001000, 'loss': 19.851065, 'acc': 0.988281, time: 1.786 2022-09-15 16:16:18,561-INFO: epoch: 76, iter: 1220, lr: 0.001000, 'loss': 33.03997, 'acc': 0.980469, time: 0.404 2022-09-15 16:16:27,601-INFO: epoch: 77, iter: 1240, lr: 0.001000, 'loss': 43.73796, 'acc': 0.974609, time: 0.373 2022-09-15 16:16:36,731-INFO: epoch: 78, iter: 1260, lr: 0.001000, 'loss': 25.171104, 'acc': 0.984375, time: 0.374 2022-09-15 16:16:47,318-INFO: epoch: 80, iter: 1280, lr: 0.001000, 'loss': 19.046516, 'acc': 0.988281, time: 1.838 2022-09-15 16:16:56,417-INFO: epoch: 81, iter: 1300, lr: 0.001000, 'loss': 17.294367, 'acc': 0.988281, time: 0.399 2022-09-15 16:17:05,547-INFO: epoch: 82, iter: 1320, lr: 0.001000, 'loss': 17.236929, 'acc': 0.992188, time: 0.373 2022-09-15 16:17:14,582-INFO: epoch: 83, iter: 1340, lr: 0.001000, 'loss': 15.577, 'acc': 0.988281, time: 0.373 2022-09-15 16:17:25,033-INFO: epoch: 85, iter: 1360, lr: 0.001000, 'loss': 15.052889, 'acc': 0.990234, time: 1.760 2022-09-15 16:17:34,349-INFO: epoch: 86, iter: 1380, lr: 0.001000, 'loss': 17.350527, 'acc': 0.988281, time: 0.413 2022-09-15 16:17:43,599-INFO: epoch: 87, iter: 1400, lr: 0.001000, 'loss': 14.587466, 'acc': 0.990234, time: 0.374 2022-09-15 16:17:52,589-INFO: epoch: 88, iter: 1420, lr: 0.001000, 'loss': 14.150236, 'acc': 0.992188, time: 0.373 2022-09-15 16:18:02,967-INFO: epoch: 90, iter: 1440, lr: 0.001000, 'loss': 12.714052, 'acc': 0.988281, time: 1.742 2022-09-15 16:18:12,164-INFO: epoch: 91, iter: 1460, lr: 0.001000, 'loss': 10.972769, 'acc': 0.992188, time: 0.402 2022-09-15 16:18:21,412-INFO: epoch: 92, iter: 1480, lr: 0.001000, 'loss': 14.171873, 'acc': 0.992188, time: 0.374 2022-09-15 16:18:30,446-INFO: epoch: 93, iter: 1500, lr: 0.001000, 'loss': 10.255694, 'acc': 0.992188, time: 0.374 2022-09-15 16:18:32,318-INFO: Already save model in ./myoutput/rec_RARE_atten_new/best_accuracy 2022-09-15 16:18:32,319-INFO: Test iter: 1500, acc:0.823177, best_acc:0.823177, best_epoch:93, best_batch_id:1500, eval_sample_num:1001 2022-09-15 16:18:43,055-INFO: epoch: 95, iter: 1520, lr: 0.001000, 'loss': 9.569214, 'acc': 0.996094, time: 1.995 2022-09-15 16:18:52,264-INFO: epoch: 96, iter: 1540, lr: 0.001000, 'loss': 9.96125, 'acc': 0.992188, time: 0.414 2022-09-15 16:19:01,514-INFO: epoch: 97, iter: 1560, lr: 0.001000, 'loss': 8.359654, 'acc': 0.996094, time: 0.374 2022-09-15 16:19:10,616-INFO: epoch: 98, iter: 1580, lr: 0.001000, 'loss': 6.192225, 'acc': 0.998047, time: 0.373 2022-09-15 16:19:21,189-INFO: epoch: 100, iter: 1600, lr: 0.001000, 'loss': 5.406765, 'acc': 0.996094, time: 1.799 2022-09-15 16:19:27,310-INFO: Already save model in ./myoutput/rec_RARE_atten_new/iter_epoch_100 2022-09-15 16:19:30,699-INFO: epoch: 101, iter: 1620, lr: 0.001000, 'loss': 5.483102, 'acc': 0.996094, time: 0.381 2022-09-15 16:19:39,779-INFO: epoch: 102, iter: 1640, lr: 0.001000, 'loss': 9.586991, 'acc': 0.996094, time: 0.374 2022-09-15 16:19:48,841-INFO: epoch: 103, iter: 1660, lr: 0.001000, 'loss': 5.63769, 'acc': 0.996094, time: 0.374 2022-09-15 16:19:59,323-INFO: epoch: 105, iter: 1680, lr: 0.001000, 'loss': 11.556911, 'acc': 0.996094, time: 1.855 2022-09-15 16:20:08,442-INFO: epoch: 106, iter: 1700, lr: 0.001000, 'loss': 8.392323, 'acc': 0.996094, time: 0.420 2022-09-15 16:20:17,532-INFO: epoch: 107, iter: 1720, lr: 0.001000, 'loss': 4.550391, 'acc': 0.996094, time: 0.374 2022-09-15 16:20:26,593-INFO: epoch: 108, iter: 1740, lr: 0.001000, 'loss': 5.61542, 'acc': 0.996094, time: 0.373 2022-09-15 16:20:37,160-INFO: epoch: 110, iter: 1760, lr: 0.001000, 'loss': 9.220263, 'acc': 0.996094, time: 1.810 2022-09-15 16:20:46,332-INFO: epoch: 111, iter: 1780, lr: 0.001000, 'loss': 4.136215, 'acc': 0.998047, time: 0.422 2022-09-15 16:20:55,467-INFO: epoch: 112, iter: 1800, lr: 0.001000, 'loss': 5.135178, 'acc': 0.996094, time: 0.373 2022-09-15 16:21:04,534-INFO: epoch: 113, iter: 1820, lr: 0.001000, 'loss': 5.234288, 'acc': 0.996094, time: 0.374 2022-09-15 16:21:15,182-INFO: epoch: 115, iter: 1840, lr: 0.001000, 'loss': 4.517134, 'acc': 0.996094, time: 1.924 2022-09-15 16:21:24,325-INFO: epoch: 116, iter: 1860, lr: 0.001000, 'loss': 3.831606, 'acc': 1.0, time: 0.387 2022-09-15 16:21:33,438-INFO: epoch: 117, iter: 1880, lr: 0.001000, 'loss': 3.111336, 'acc': 0.996094, time: 0.373 2022-09-15 16:21:42,490-INFO: epoch: 118, iter: 1900, lr: 0.001000, 'loss': 3.794124, 'acc': 0.996094, time: 0.374 2022-09-15 16:21:53,098-INFO: epoch: 120, iter: 1920, lr: 0.001000, 'loss': 3.929718, 'acc': 0.998047, time: 1.913 2022-09-15 16:22:02,185-INFO: epoch: 121, iter: 1940, lr: 0.001000, 'loss': 4.611428, 'acc': 0.996094, time: 0.375 2022-09-15 16:22:11,267-INFO: epoch: 122, iter: 1960, lr: 0.001000, 'loss': 2.685765, 'acc': 1.0, time: 0.374 2022-09-15 16:22:20,275-INFO: epoch: 123, iter: 1980, lr: 0.001000, 'loss': 2.870256, 'acc': 1.0, time: 0.373 2022-09-15 16:22:30,732-INFO: epoch: 125, iter: 2000, lr: 0.001000, 'loss': 4.04394, 'acc': 0.998047, time: 1.891 2022-09-15 16:22:33,935-INFO: Already save model in ./myoutput/rec_RARE_atten_new/best_accuracy 2022-09-15 16:22:33,935-INFO: Test iter: 2000, acc:0.829171, best_acc:0.829171, best_epoch:125, best_batch_id:2000, eval_sample_num:1001 2022-09-15 16:22:42,925-INFO: epoch: 126, iter: 2020, lr: 0.001000, 'loss': 3.729886, 'acc': 0.996094, time: 0.384 2022-09-15 16:22:51,976-INFO: epoch: 127, iter: 2040, lr: 0.001000, 'loss': 3.797183, 'acc': 0.996094, time: 0.377 2022-09-15 16:23:01,064-INFO: epoch: 128, iter: 2060, lr: 0.001000, 'loss': 3.841343, 'acc': 1.0, time: 0.374 2022-09-15 16:23:11,632-INFO: epoch: 130, iter: 2080, lr: 0.001000, 'loss': 2.5157, 'acc': 1.0, time: 1.818 2022-09-15 16:23:20,885-INFO: epoch: 131, iter: 2100, lr: 0.001000, 'loss': 2.793916, 'acc': 1.0, time: 0.382 2022-09-15 16:23:29,893-INFO: epoch: 132, iter: 2120, lr: 0.001000, 'loss': 2.068662, 'acc': 1.0, time: 0.373 2022-09-15 16:23:38,892-INFO: epoch: 133, iter: 2140, lr: 0.001000, 'loss': 1.963152, 'acc': 1.0, time: 0.374 2022-09-15 16:23:49,438-INFO: epoch: 135, iter: 2160, lr: 0.001000, 'loss': 1.785324, 'acc': 1.0, time: 1.811 2022-09-15 16:23:58,622-INFO: epoch: 136, iter: 2180, lr: 0.001000, 'loss': 1.794544, 'acc': 1.0, time: 0.388 2022-09-15 16:24:07,731-INFO: epoch: 137, iter: 2200, lr: 0.001000, 'loss': 1.725564, 'acc': 1.0, time: 0.381 2022-09-15 16:24:16,818-INFO: epoch: 138, iter: 2220, lr: 0.001000, 'loss': 1.576424, 'acc': 1.0, time: 0.373 2022-09-15 16:24:27,274-INFO: epoch: 140, iter: 2240, lr: 0.001000, 'loss': 1.49527, 'acc': 1.0, time: 1.773 2022-09-15 16:24:36,422-INFO: epoch: 141, iter: 2260, lr: 0.001000, 'loss': 1.492407, 'acc': 1.0, time: 0.374 2022-09-15 16:24:45,728-INFO: epoch: 142, iter: 2280, lr: 0.001000, 'loss': 1.456, 'acc': 1.0, time: 0.374 2022-09-15 16:24:54,789-INFO: epoch: 143, iter: 2300, lr: 0.001000, 'loss': 1.191148, 'acc': 1.0, time: 0.373 2022-09-15 16:25:05,522-INFO: epoch: 145, iter: 2320, lr: 0.001000, 'loss': 1.210015, 'acc': 1.0, time: 1.863 2022-09-15 16:25:14,468-INFO: epoch: 146, iter: 2340, lr: 0.001000, 'loss': 1.281136, 'acc': 1.0, time: 0.375 2022-09-15 16:25:23,566-INFO: epoch: 147, iter: 2360, lr: 0.001000, 'loss': 1.303462, 'acc': 1.0, time: 0.374 2022-09-15 16:25:32,584-INFO: epoch: 148, iter: 2380, lr: 0.001000, 'loss': 1.070822, 'acc': 1.0, time: 0.375 2022-09-15 16:25:42,999-INFO: epoch: 150, iter: 2400, lr: 0.001000, 'loss': 1.107232, 'acc': 1.0, time: 1.789 2022-09-15 16:25:52,155-INFO: epoch: 151, iter: 2420, lr: 0.001000, 'loss': 1.304622, 'acc': 1.0, time: 0.411 2022-09-15 16:26:01,268-INFO: epoch: 152, iter: 2440, lr: 0.001000, 'loss': 1.403758, 'acc': 1.0, time: 0.374 2022-09-15 16:26:10,305-INFO: epoch: 153, iter: 2460, lr: 0.001000, 'loss': 1.210189, 'acc': 1.0, time: 0.373 2022-09-15 16:26:20,865-INFO: epoch: 155, iter: 2480, lr: 0.001000, 'loss': 1.069858, 'acc': 1.0, time: 1.815 2022-09-15 16:26:30,007-INFO: epoch: 156, iter: 2500, lr: 0.001000, 'loss': 1.320687, 'acc': 1.0, time: 0.375 2022-09-15 16:26:32,067-INFO: Already save model in ./myoutput/rec_RARE_atten_new/best_accuracy 2022-09-15 16:26:32,067-INFO: Test iter: 2500, acc:0.831169, best_acc:0.831169, best_epoch:156, best_batch_id:2500, eval_sample_num:1001 2022-09-15 16:26:41,097-INFO: epoch: 157, iter: 2520, lr: 0.001000, 'loss': 1.170897, 'acc': 1.0, time: 0.374 2022-09-15 16:26:50,126-INFO: epoch: 158, iter: 2540, lr: 0.001000, 'loss': 1.209216, 'acc': 1.0, time: 0.373 2022-09-15 16:27:00,639-INFO: epoch: 160, iter: 2560, lr: 0.001000, 'loss': 1.066662, 'acc': 1.0, time: 1.871 2022-09-15 16:27:09,739-INFO: epoch: 161, iter: 2580, lr: 0.001000, 'loss': 0.858585, 'acc': 1.0, time: 0.378 2022-09-15 16:27:18,841-INFO: epoch: 162, iter: 2600, lr: 0.001000, 'loss': 0.789717, 'acc': 1.0, time: 0.373 2022-09-15 16:27:27,905-INFO: epoch: 163, iter: 2620, lr: 0.001000, 'loss': 0.861278, 'acc': 1.0, time: 0.373 2022-09-15 16:27:38,476-INFO: epoch: 165, iter: 2640, lr: 0.001000, 'loss': 0.891585, 'acc': 1.0, time: 1.823 2022-09-15 16:27:47,624-INFO: epoch: 166, iter: 2660, lr: 0.001000, 'loss': 0.919595, 'acc': 1.0, time: 0.383 2022-09-15 16:27:56,740-INFO: epoch: 167, iter: 2680, lr: 0.001000, 'loss': 0.757441, 'acc': 1.0, time: 0.374 2022-09-15 16:28:05,765-INFO: epoch: 168, iter: 2700, lr: 0.001000, 'loss': 0.720211, 'acc': 1.0, time: 0.374 2022-09-15 16:28:16,255-INFO: epoch: 170, iter: 2720, lr: 0.001000, 'loss': 0.76394, 'acc': 1.0, time: 1.810 2022-09-15 16:28:25,394-INFO: epoch: 171, iter: 2740, lr: 0.001000, 'loss': 0.70124, 'acc': 1.0, time: 0.375 2022-09-15 16:28:34,568-INFO: epoch: 172, iter: 2760, lr: 0.001000, 'loss': 0.681117, 'acc': 1.0, time: 0.373 2022-09-15 16:28:43,565-INFO: epoch: 173, iter: 2780, lr: 0.001000, 'loss': 0.71791, 'acc': 1.0, time: 0.375 2022-09-15 16:28:54,132-INFO: epoch: 175, iter: 2800, lr: 0.001000, 'loss': 0.726069, 'acc': 1.0, time: 1.846 2022-09-15 16:29:03,266-INFO: epoch: 176, iter: 2820, lr: 0.001000, 'loss': 0.662951, 'acc': 1.0, time: 0.435 2022-09-15 16:29:12,259-INFO: epoch: 177, iter: 2840, lr: 0.001000, 'loss': 0.770077, 'acc': 1.0, time: 0.374 2022-09-15 16:29:21,314-INFO: epoch: 178, iter: 2860, lr: 0.001000, 'loss': 0.70409, 'acc': 1.0, time: 0.374 2022-09-15 16:29:31,740-INFO: epoch: 180, iter: 2880, lr: 0.001000, 'loss': 0.75167, 'acc': 1.0, time: 1.781 2022-09-15 16:29:40,952-INFO: epoch: 181, iter: 2900, lr: 0.001000, 'loss': 0.595518, 'acc': 1.0, time: 0.384 2022-09-15 16:29:50,018-INFO: epoch: 182, iter: 2920, lr: 0.001000, 'loss': 0.678415, 'acc': 1.0, time: 0.374 2022-09-15 16:29:59,274-INFO: epoch: 183, iter: 2940, lr: 0.001000, 'loss': 0.602751, 'acc': 1.0, time: 0.373 2022-09-15 16:30:09,946-INFO: epoch: 185, iter: 2960, lr: 0.001000, 'loss': 0.568185, 'acc': 1.0, time: 2.010 2022-09-15 16:30:19,154-INFO: epoch: 186, iter: 2980, lr: 0.001000, 'loss': 0.56914, 'acc': 1.0, time: 0.397 2022-09-15 16:30:28,234-INFO: epoch: 187, iter: 3000, lr: 0.001000, 'loss': 0.570147, 'acc': 1.0, time: 0.373 2022-09-15 16:30:29,647-INFO: Test iter: 3000, acc:0.831169, best_acc:0.831169, best_epoch:156, best_batch_id:2500, eval_sample_num:1001 2022-09-15 16:30:38,718-INFO: epoch: 188, iter: 3020, lr: 0.001000, 'loss': 0.556909, 'acc': 1.0, time: 0.373 2022-09-15 16:30:49,241-INFO: epoch: 190, iter: 3040, lr: 0.001000, 'loss': 0.522148, 'acc': 1.0, time: 1.889 2022-09-15 16:30:58,437-INFO: epoch: 191, iter: 3060, lr: 0.001000, 'loss': 0.498712, 'acc': 1.0, time: 0.404 2022-09-15 16:31:07,491-INFO: epoch: 192, iter: 3080, lr: 0.001000, 'loss': 0.428753, 'acc': 1.0, time: 0.373 2022-09-15 16:31:16,654-INFO: epoch: 193, iter: 3100, lr: 0.001000, 'loss': 0.434947, 'acc': 1.0, time: 0.374 2022-09-15 16:31:27,201-INFO: epoch: 195, iter: 3120, lr: 0.001000, 'loss': 0.485586, 'acc': 1.0, time: 1.832 2022-09-15 16:31:36,403-INFO: epoch: 196, iter: 3140, lr: 0.001000, 'loss': 0.46684, 'acc': 1.0, time: 0.392 2022-09-15 16:31:45,477-INFO: epoch: 197, iter: 3160, lr: 0.001000, 'loss': 0.513497, 'acc': 1.0, time: 0.374 2022-09-15 16:31:54,520-INFO: epoch: 198, iter: 3180, lr: 0.001000, 'loss': 0.657723, 'acc': 1.0, time: 0.374
导出推理模型
In [78]
%cd ~/PaddleOCR
# 导出检测模型
!python3 tools/export_model.py \\
-c configs/det/det_mv3_db.yml \\
-o Global.checkpoints=./myoutput/det_db/best_accuracy \\
Global.save_inference_dir=./inference/mydet_db
# 导出识别模型
!python3 tools/export_model.py \\
-c configs/rec/rec_mv3_tps_bilstm_attn.yml \\
-o Global.checkpoints=./myoutput/rec_RARE_atten_new/best_accuracy \\
Global.save_inference_dir=./inference/myrec_rare/home/aistudio/work/PaddleOCR 2022-09-15 16:37:11,326-INFO: 'Global': 'debug': False, 'algorithm': 'DB', 'use_gpu': True, 'epoch_num': 1200, 'log_smooth_window': 20, 'print_batch_step': 20, 'save_model_dir': './myoutput/det_db/', 'save_epoch_step': 10, 'eval_batch_step': [100, 500], 'train_batch_size_per_card': 4, 'test_batch_size_per_card': 4, 'image_shape': [3, 640, 640], 'reader_yml': './configs/det/det_db_icdar15_reader.yml', 'pretrain_weights': './pretrain_models/det_mv3_db/best_accuracy', 'checkpoints': './myoutput/det_db/best_accuracy', 'save_res_path': './myoutput/det_db/predicts_db.txt', 'save_inference_dir': './inference/mydet_db', 'Architecture': 'function': 'ppocr.modeling.architectures.det_model,DetModel', 'Backbone': 'function': 'ppocr.modeling.backbones.det_mobilenet_v3,MobileNetV3', 'scale': 0.5, 'model_name': 'large', 'Head': 'function': 'ppocr.modeling.heads.det_db_head,DBHead', 'model_name': 'large', 'k': 50, 'inner_channels': 96, 'out_channels': 2, 'Loss': 'function': 'ppocr.modeling.losses.det_db_loss,DBLoss', 'balance_loss': True, 'main_loss_type': 'DiceLoss', 'alpha': 5, 'beta': 10, 'ohem_ratio': 3, 'Optimizer': 'function': 'ppocr.optimizer,AdamDecay', 'base_lr': 0.001, 'beta1': 0.9, 'beta2': 0.999, 'PostProcess': 'function': 'ppocr.postprocess.db_postprocess,DBPostProcess', 'thresh': 0.3, 'box_thresh': 0.7, 'max_candidates': 1000, 'unclip_ratio': 2.0, 'TrainReader': 'reader_function': 'ppocr.data.det.dataset_traversal,TrainReader', 'process_function': 'ppocr.data.det.db_process,DBProcessTrain', 'num_workers': 1, 'img_set_dir': '../../', 'label_file_path': '../train_data_det.txt', 'EvalReader': 'reader_function': 'ppocr.data.det.dataset_traversal,EvalTestReader', 'process_function': 'ppocr.data.det.db_process,DBProcessTest', 'img_set_dir': '../../', 'label_file_path': '../val_data_det.txt', 'test_image_shape': [736, 1280], 'TestReader': 'reader_function': 'ppocr.data.det.dataset_traversal,EvalTestReader', 'process_function': 'ppocr.data.det.db_process,DBProcessTest', 'infer_img': None, 'img_set_dir': '../../', 'label_file_path': '../test_data_det.txt', 'test_image_shape': [736, 1280], 'do_eval': True 3 640 640 W0915 16:37:11.688948 25074 device_context.cc:252] Please NOTE: device: 0, CUDA Capability: 70, Driver API Version: 11.2, Runtime API Version: 9.0 W0915 16:37:11.693445 25074 device_context.cc:260] device: 0, cuDNN Version: 7.6. 2022-09-15 16:37:13,747-INFO: Finish initing model from ./myoutput/det_db/best_accuracy inference model saved in ./inference/mydet_db/model and ./inference/mydet_db/params save success, output_name_list: ['maps'] 2022-09-15 16:37:16,325-INFO: 'Global': 'debug': False, 'algorithm': 'RARE', 'use_gpu': True, 'epoch_num': 200, 'log_smooth_window': 20, 'print_batch_step': 20, 'save_model_dir': './myoutput/rec_RARE_atten_new', 'save_epoch_step': 100, 'eval_batch_step': 500, 'train_batch_size_per_card': 256, 'test_batch_size_per_card': 256, 'image_shape': [3, 32, 320], 'max_text_length': 8, 'character_type': 'ch', 'character_dict_path': '../word_dict.txt', 'loss_type': 'attention', 'tps': True, 'reader_yml': './configs/rec/rec_chinese_reader.yml', 'pretrain_weights': './pretrain_models/rec_mv3_tps_bilstm_attn/best_accuracy', 'checkpoints': './myoutput/rec_RARE_atten_new/best_accuracy', 'save_inference_dir': './inference/myrec_rare', 'infer_img': None, 'Architecture': 'function': 'ppocr.modeling.architectures.rec_model,RecModel', 'TPS': 'function': 'ppocr.modeling.stns.tps,TPS', 'num_fiducial': 20, 'loc_lr': 0.1, 'model_name': 'small', 'Backbone': 'function': 'ppocr.modeling.backbones.rec_mobilenet_v3,MobileNetV3', 'scale': 0.5, 'model_name': 'large', 'Head': 'function': 'ppocr.modeling.heads.rec_attention_head,AttentionPredict', 'encoder_type': 'rnn', 'SeqRNN': 'hidden_size': 96, 'Attention': 'decoder_size': 96, 'word_vector_dim': 96, 'Loss': 'function': 'ppocr.modeling.losses.rec_attention_loss,AttentionLoss', 'Optimizer': 'function': 'ppocr.optimizer,AdamDecay', 'base_lr': 0.001, 'beta1': 0.9, 'beta2': 0.999, 'TrainReader': 'reader_function': 'ppocr.data.rec.dataset_traversal,SimpleReader', 'num_workers': 8, 'img_set_dir': '../..', 'label_file_path': '../train_data_rec.txt', 'EvalReader': 'reader_function': 'ppocr.data.rec.dataset_traversal,SimpleReader', 'num_workers': 8, 'img_set_dir': '../..', 'label_file_path': '../val_data_rec.txt', 'TestReader': 'reader_function': 'ppocr.data.rec.dataset_traversal,SimpleReader' W0915 16:37:16.958099 25152 device_context.cc:252] Please NOTE: device: 0, CUDA Capability: 70, Driver API Version: 11.2, Runtime API Version: 9.0 W0915 16:37:16.962687 25152 device_context.cc:260] device: 0, cuDNN Version: 7.6. 2022-09-15 16:37:19,039-INFO: Finish initing model from ./myoutput/rec_RARE_atten_new/best_accuracy inference model saved in ./inference/myrec_rare/model and ./inference/myrec_rare/params save success, output_name_list: ['decoded_out', 'predicts']
模型测试
In [79]
%cd ~/PaddleOCR
!python3 tools/infer/predict_system.py \\
--image_dir="../../imgtest" \\
--det_model_dir="./inference/mydet_db" \\
--rec_model_dir="./inference/myrec_rare" \\
--rec_image_shape="3, 32, 320" \\
--rec_char_type="ch" \\
--rec_algorithm="RARE" \\
--use_space_char False \\
--max_text_length 8 \\
--rec_char_dict_path="../word_dict.txt" \\
--use_gpu False /home/aistudio/work/PaddleOCR dt_boxes num : 1, elapse : 0.9093203544616699 rec_res num : 1, elapse : 0.051482200622558594 Predict time of ../../imgtest/0425-88_255-205&515_553&627-528&596_205&627_224&532_553&515-0_0_3_25_27_30_33_33-72-8.jpg: 0.981s 皖AD13699, 1.000 The visualized image saved in ./inference_results/0425-88_255-205&515_553&627-528&596_205&627_224&532_553&515-0_0_3_25_27_30_33_33-72-8.jpg dt_boxes num : 1, elapse : 0.6962370872497559 rec_res num : 1, elapse : 0.046535491943359375 Predict time of ../../imgtest/04-90_267-207&511_555&616-550&605_211&616_207&515_555&511-0_0_3_1_26_30_31_30-68-81.jpg: 0.754s 皖AD82676, 0.995 The visualized image saved in ./inference_results/04-90_267-207&511_555&616-550&605_211&616_207&515_555&511-0_0_3_1_26_30_31_30-68-81.jpg dt_boxes num : 1, elapse : 0.6199753284454346 rec_res num : 1, elapse : 0.08345222473144531 Predict time of ../../imgtest/0375-92_263-192&480_552&575-536&575_198&560_192&480_552&495-0_0_5_24_29_33_24_24-133-69.jpg: 0.746s 皖AF05900, 1.000 The visualized image saved in ./inference_results/0375-92_263-192&480_552&575-536&575_198&560_192&480_552&495-0_0_5_24_29_33_24_24-133-69.jpg dt_boxes num : 1, elapse : 0.6378555297851562 rec_res num : 1, elapse : 0.08243370056152344 Predict time of ../../imgtest/0475-68_277-140&493_368&683-368&570_162&683_140&590_350&493-0_0_5_25_29_32_32_30-170-444.jpg: 0.733s 皖AF15886, 0.999 The visualized image saved in ./inference_results/0475-68_277-140&493_368&683-368&570_162&683_140&590_350&493-0_0_5_25_29_32_32_30-170-444.jpg dt_boxes num : 1, elapse : 0.6511027812957764 rec_res num : 1, elapse : 0.04664444923400879 Predict time of ../../imgtest/05-90_257-137&507_572&612-567&611_158&612_137&507_572&512-0_0_3_28_32_25_24_32-144-135.jpg: 0.709s 皖AD48108, 0.999 The visualized image saved in ./inference_results/05-90_257-137&507_572&612-567&611_158&612_137&507_572&512-0_0_3_28_32_25_24_32-144-135.jpg dt_boxes num : 1, elapse : 0.6640639305114746 rec_res num : 1, elapse : 0.08099365234375 Predict time of ../../imgtest/03-103_253-267&425_483&565-483&565_271&497_267&425_480&483-0_0_3_25_25_33_25_25-110-47.jpg: 0.756s 皖AD11911, 1.000 The visualized image saved in ./inference_results/03-103_253-267&425_483&565-483&565_271&497_267&425_480&483-0_0_3_25_25_33_25_25-110-47.jpg dt_boxes num : 1, elapse : 0.6204874515533447 rec_res num : 1, elapse : 0.08555459976196289 Predict time of ../../imgtest/0375-90_256-181&548_541&643-541&643_200&633_181&548_529&553-0_0_3_2_29_33_33_26-176-389.jpg: 0.717s 皖AD05992, 0.919 The visualized image saved in ./inference_results/0375-90_256-181&548_541&643-541&643_200&633_181&548_529&553-0_0_3_2_29_33_33_26-176-389.jpg dt_boxes num : 1, elapse : 0.613457441329956 rec_res num : 1, elapse : 0.08662247657775879 Predict time of ../../imgtest/0475-90_238-143&505_599&600-599&600_186&586_143&509_577&505-0_0_3_30_25_27_27_32-60-74.jpg: 0.711s 皖AD61338, 0.999 The visualized image saved in ./inference_results/0475-90_238-143&505_599&600-599&600_186&586_143&509_577&505-0_0_3_30_25_27_27_32-60-74.jpg dt_boxes num : 1, elapse : 0.6121721267700195 rec_res num : 1, elapse : 0.08241701126098633 Predict time of ../../imgtest/01-90_265-231&522_405&574-405&571_235&574_231&523_403&522-0_0_3_1_28_29_30_30-134-56.jpg: 0.705s 皖AD84566, 0.996 The visualized image saved in ./inference_results/01-90_265-231&522_405&574-405&571_235&574_231&523_403&522-0_0_3_1_28_29_30_30-134-56.jpg dt_boxes num : 1, elapse : 0.6165649890899658 rec_res num : 1, elapse : 0.0794670581817627 Predict time of ../../imgtest/04-91_254-145&472_529&567-529&567_164&552_145&472_529&485-0_0_3_25_24_24_24_29-148-355.jpg: 0.707s 皖AD10005, 1.000 The visualized image saved in ./inference_results/04-91_254-145&472_529&567-529&567_164&552_145&472_529&485-0_0_3_25_24_24_24_29-148-355.jpg
In [80]
!python tools/eval.py -c configs/rec/rec_mv3_tps_bilstm_attn.yml \\
-o Global.checkpoints=./myoutput/rec_RARE_atten_new/best_accuracy2022-09-15 16:39:43,444-INFO: 'Global': 'debug': False, 'algorithm': 'RARE', 'use_gpu': True, 'epoch_num': 200, 'log_smooth_window': 20, 'print_batch_step': 20, 'save_model_dir': './myoutput/rec_RARE_atten_new', 'save_epoch_step': 100, 'eval_batch_step': 500, 'train_batch_size_per_card': 256, 'test_batch_size_per_card': 256, 'image_shape': [3, 32, 320], 'max_text_length': 8, 'character_type': 'ch', 'character_dict_path': '../word_dict.txt', 'loss_type': 'attention', 'tps': True, 'reader_yml': './configs/rec/rec_chinese_reader.yml', 'pretrain_weights': './pretrain_models/rec_mv3_tps_bilstm_attn/best_accuracy', 'checkpoints': './myoutput/rec_RARE_atten_new/best_accuracy', 'save_inference_dir': './inference/newimg_rec_rare', 'infer_img': None, 'Architecture': 'function': 'ppocr.modeling.architectures.rec_model,RecModel', 'TPS': 'function': 'ppocr.modeling.stns.tps,TPS', 'num_fiducial': 20, 'loc_lr': 0.1, 'model_name': 'small', 'Backbone': 'function': 'ppocr.modeling.backbones.rec_mobilenet_v3,MobileNetV3', 'scale': 0.5, 'model_name': 'large', 'Head': 'function': 'ppocr.modeling.heads.rec_attention_head,AttentionPredict', 'encoder_type': 'rnn', 'SeqRNN': 'hidden_size': 96, 'Attention': 'decoder_size': 96, 'word_vector_dim': 96, 'Loss': 'function': 'ppocr.modeling.losses.rec_attention_loss,AttentionLoss', 'Optimizer': 'function': 'ppocr.optimizer,AdamDecay', 'base_lr': 0.001, 'beta1': 0.9, 'beta2': 0.999, 'TrainReader': 'reader_function': 'ppocr.data.rec.dataset_traversal,SimpleReader', 'num_workers': 8, 'img_set_dir': '../..', 'label_file_path': '../train_data_rec.txt', 'EvalReader': 'reader_function': 'ppocr.data.rec.dataset_traversal,SimpleReader', 'num_workers': 8, 'img_set_dir': '../..', 'label_file_path': '../val_data_rec.txt', 'TestReader': 'reader_function': 'ppocr.data.rec.dataset_traversal,SimpleReader' W0915 16:39:44.065701 25553 device_context.cc:252] Please NOTE: device: 0, CUDA Capability: 70, Driver API Version: 11.2, Runtime API Version: 9.0 W0915 16:39:44.070394 25553 device_context.cc:260] device: 0, cuDNN Version: 7.6. 2022-09-15 16:39:46,158-INFO: Finish initing model from ./myoutput/rec_RARE_atten_new/best_accuracy 2022-09-15 16:39:47,598-INFO: Eval result: 'avg_acc': 0.8311688311688312, 'total_acc_num': 832, 'total_sample_num': 1001
测试集部分识别结果展示


总结:
本项目基于Paddleocr完成深度学习车牌识别,项目分为车牌检测与车牌识别两部分,最终完整实现车牌识别目的,可以识别大部分车牌结果。针对本项目的识别准确度,后续优化可以增加数据增强方面内容、更换其他主干网络及对应参数调优,大家可以在此项目基础上进行扩充,欢迎评论区一起讨论!
作者博客:CSDN主页 (专注大数据与人工智能知识分享,欢迎关注!)
以上是关于Paddle入门实战系列:基于PaddleOCR的车牌识别的主要内容,如果未能解决你的问题,请参考以下文章