GoogLeNet(Inception v1-v4)
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了GoogLeNet(Inception v1-v4)相关的知识,希望对你有一定的参考价值。
参考技术A 论文:
GoogLeNet/Inception-v1: Going Deeper with Convolutions
BN-Inception/Inception-v2: Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
Inception-v3: Rethinking the Inception Architecture for Computer Vision
Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning
从上图可看到VGG继承了LeNet以及AlexNet的一些框架结构,而GoogLeNet则做了更加大胆的网络结构尝试,虽然深度只有22层,但大小却比AlexNet和VGG小很多,GoogleNet参数为500万个,AlexNet参数个数是GoogleNet的12倍,VGGNet参数又是AlexNet的3倍,因此在内存或计算资源有限时,GoogleNet是比较好的选择;从模型结果来看,GoogLeNet的性能却更加优越。
一般来说, 提升网络性能 最直接的办法就是 增加网络深度和宽度 ,深度指网络层次数量、宽度指神经元数量。但这种方式存在以下问题:
(1)参数太多,如果训练数据集有限,很容易产生过拟合;
(2)网络越大、参数越多,计算复杂度越大,难以应用;
(3)网络越深,容易出现梯度弥散问题(梯度越往后穿越容易消失),难以优化模型。
解决这些问题的方法是在增加网络深度和宽度的同时减少参数,为了减少参数,自然就想到将全连接变成稀疏连接。但是在实现上,全连接变成稀疏连接后实际计算量并不会有质的提升,因为大部分硬件是针对密集矩阵计算优化的,稀疏矩阵虽然数据量少,但是计算所消耗的时间却很难减少。
大量的文献表明可以将稀疏矩阵聚类为较为密集的子矩阵来提高计算性能,就如人类的大脑是可以看做是神经元的重复堆积,因此,GoogLeNet团队提出了Inception网络结构,就是构造一种“基础神经元”结构,来搭建一个稀疏性、高计算性能的网络结构。
当不知道在卷积神经网络中该使用1 * 1卷积还是3 * 3的卷积还是5 * 5的卷积或者是否需要进行pooling操作的时候,我们就可以通过inception模块来将所有的操作都做一遍,然后将得到的结果直接concat到一起, 由神经网络来决定是使用哪种方式处理 。
通过设计一个稀疏网络结构,但是能够产生稠密的数据,既能增加神经网络表现,又能保证计算资源的使用效率。谷歌提出了最原始Inception的基本结构:
该结构将CNN中常用的卷积(1x1,3x3,5x5)、池化操作(3x3)堆叠在一起(卷积、池化后的尺寸相同,将通道相加),一方面增加了 网络的宽度 ,另一方面也增加了网络 对尺度的适应性 。
网络卷积层中的网络能够提取输入的每一个细节信息,同时5x5的滤波器也能够覆盖大部分接受层的的输入。还可以进行一个池化操作,以减少空间大小,降低过度拟合。在这些层之上,在每一个卷积层后都要做一个ReLU操作,以增加网络的非线性特征。
然而这个Inception原始版本,所有的卷积核都在上一层的所有输出上来做,而那个5x5的卷积核所需的 计算量就太大 了,造成了特征图的厚度很大,为了避免这种情况,在3x3前、5x5前、max pooling后分别加上了1x1的卷积核,以起到了降低特征图厚度的作用,这也就形成了Inception v1的网络结构,如下图所示:
基于Inception构建了GoogLeNet的网络结构如下(共22层):
对上图说明如下:
(1)GoogLeNet采用了模块化的结构(Inception结构),方便增添和修改;
(2)网络最后采用了average pooling(平均池化)来代替全连接层,该想法来自NIN(Network in Network),事实证明这样可以将准确率提高0.6%。但是,实际在最后还是加了一个全连接层,主要是为了方便对输出进行灵活调整;
(3)虽然移除了全连接,但是网络中依然使用了Dropout ;
(4)为了避免梯度消失,网络额外增加了2个 辅助的Loss 用于向前传导梯度(辅助分类器,实际上是 “深度监督” 的策略。)。辅助分类器是将中间某一层的输出用作分类,并按一个较小的权重(0.3)加到最终分类结果中,这样相当于做了模型融合,同时给网络增加了反向传播的梯度信号,也提供了额外的正则化,对于整个网络的训练很有裨益。而在实际测试的时候,这两个额外的softmax会被去掉。
GoogLeNet的网络结构图细节如下:
注:上表中的“#3x3 reduce”,“#5x5 reduce”表示在3x3,5x5卷积操作之前使用了1x1卷积的数量。
在V1的基础上做了两点改进:
Inception V2网络结构图细节如下:
与Inception V1有以下几点改变
[1] - 5x5 卷积层被替换为两个连续的 3x3 卷积层. 网络的最大深度增加 9 个权重层. 参数量增加了大约 25%,计算量增加了大约 30%.
[2] - 28x28 的 Inception 模块的数量由 2 增加到了 3.
[3] - Inception 模块,Ave 和 Max Pooling 层均有用到. 参考表格.
[4] - 两个 Inception 模块间不再使用 pooling 层;而在模块 3c 和 4e 中的 concatenation 前采用了 stride-2 conv/pooling 层.
[5] - 网络结构的第一个卷积层采用了深度乘子为 8 的可分离卷积(separable convolution with depth multiplier 8),减少了计算量,但训练时增加了内存消耗.
V2 V3实际上被作者放在了一篇paper里所以也没必要分得特别细。
1. 分解卷积核尺寸
分解为对称的小的卷积核
2个3*3代替1个5*5 减少28%的计算量。
第一个3*3后接线性激活会不会比ReLU更好?(因为5*5是线性操作,而2个3*3去代替的话全程应当是线性操作)
实验结果表明relu更优,作者猜测是因为网络能够学习这种空间变化的增强(实验证明这是数据增强)
分解为不对称的卷积核
3 3卷积分解2个2 2节省11%计算量,而分解成1 3和3 1节省33%
理论上,任何卷积都能分解成不对称卷积,但实验发现,在低层次效果不好,在12到20层加较好。
2. 辅助分类器
在第一篇论文的时候作者认为使用2个 辅助分类器,可以:
Lee等人 认为辅助分类器有助于更稳定的训练和better收敛。
但是在V3里作者又重新探讨了辅助分类器的作用:
作者认为辅助分类器的作用是正则化。作者假设:如果辅助分类器进行BN或Dropout,网络的主分类器的性能会更好。
3. 改变降低特征图尺寸的方式
一般情况下,如果想让图像缩小,可以有如下两种方式:
先池化再作Inception卷积,或者先作Inception卷积再作池化。但是方法一(左图)先作pooling(池化)会导致特征表示遇到瓶颈(特征缺失),方法二(右图)是正常的缩小,但计算量很大。为了同时保持特征表示且降低计算量,将网络结构改为下图,使用两个并行化的模块来降低计算量(卷积、池化并行执行,再进行合并)
注:上表中的Figure 5指没有进化的Inception,Figure 6是指小卷积版的Inception(用3x3卷积核代替5x5卷积核),Figure 7是指不对称版的Inception(用1xn、nx1卷积核代替nxn卷积核)。
组合3个改进的Inception模块,最终的Inception-v3网络如下图12所示,较早的层采用模块A,中间层采用模块B,而后面层采用模块C
Inception-v3也像GoogLeNet那样使用了深度监督,即中间层引入loss。另外一点是Inception-v3采用了一种Label Smoothing技术来正则化模型,提升泛化能力。其主要理念是防止最大的logit远大于其它logits,因为可能会导致过拟合。
Inception-v4是对原来的版本进行了梳理。
此篇文章还提出了Inception-ResNet(在Inception模块中引入ResNet的残差结构,它共有两个版本),Inception-ResNet-v1对标Inception-v3,两者计算复杂度类似,而Inception-ResNet-v2对标Inception-v4,两者计算复杂度类似。
我认为Inception-ResNet的模块太复杂(多样化)了,没必要看的很细,这里就只贴结构图了。
Inception-ResNet-v1的Inception模块如图16所示,与原始Inception模块对比,增加shortcut结构,而且在add之前使用了线性的1x1卷积对齐维度。对于Inception-ResNet-v2模型,与v1比较类似,只是参数设置不同
小结
从最初的GoogLeNet,到最新的Inception-ResNet,Inception网络在不断的迭代中越来越好,相比其它模型,Inception网络相对来说更复杂一些,主要在于模块比较复杂,而且采用的模块也是多样化。未来的话,可能需要AutoML来设计更好的模块结构。
参考链接:
大话CNN经典模型:GoogLeNet(从Inception v1到v4的演进)
深入浅出——网络模型中Inceptionv1到 v4 的作用与结构全解析
[论文笔记] Inception V1-V4 系列以及 Xception
网络结构之 Inception V2
水果数据集(Fruit-Dataset )+水果分类识别训练代码(支持googlenet, resnet, inception_v3, mobilenet_v2)
水果数据集(Fruit-Dataset )+水果分类识别训练代码(支持googlenet, resnet, inception_v3, mobilenet_v2)
目录
Fruit-Dataset水果数据集+水果分类识别训练代码(支持googlenet, resnet, inception_v3, mobilenet_v2)
1. 前言
本项目将采用深度学习的方法,搭建一个水果分类识别的训练和测试系统,实现一个简单的水果图像分类识别系统。目前,基于ResNet18的水果分类识别,支持262种水果分类识别,在水果数据集Fruit-Dataset上,训练集的Accuracy在95%左右,测试集的Accuracy在83%左右,骨干网络,可支持googlenet, resnet[18,34,50], inception_v3,mobilenet_v2等常用模型。如果想进一步提高准确率,可以尝试:

- 最重要的: 清洗数据集,水果数据集Fruits-Dataset,部分数据是通过网上爬取的,存在部分错误的图片,尽管鄙人已经清洗一部分了,但还是建议你,训练前,再次清洗数据集,不然会影响模型的识别的准确率。
- 减少种类:Fruit-Dataset共有262种类水果,可以剔除部分不常见的水果
- 使用不同backbone模型,比如resnet50或者更深的模型
- 增加数据增强: 已经支持: 随机裁剪,随机翻转,随机旋转,颜色变换等数据增强方式,可以尝试诸如mixup,CutMix等更复杂的数据增强方式
- 样本均衡: 建议进行样本均衡处理
- 调超参: 比如学习率调整策略,优化器(SGD,Adam等)
- 损失函数: 目前训练代码已经支持:交叉熵,LabelSmoothing,可以尝试FocalLoss等损失函数
【源码下载】Fruit-Dataset水果数据集+水果分类识别训练代码
【尊重原创,转载请注明出处】https://panjinquan.blog.csdn.net/article/details/126411788
2. Fruit-Dataset水果数据集
(1)Fruit-Dataset
这里分享一个水果数据集Fruit -Dataset,该数据集包含 262 种不同种类的水果,包含常见的苹果(apple ),香蕉(banana )等种类,总共有225,640 张水果图像,可满足深度学习水果种类分类识别的需求。 |  |
 | 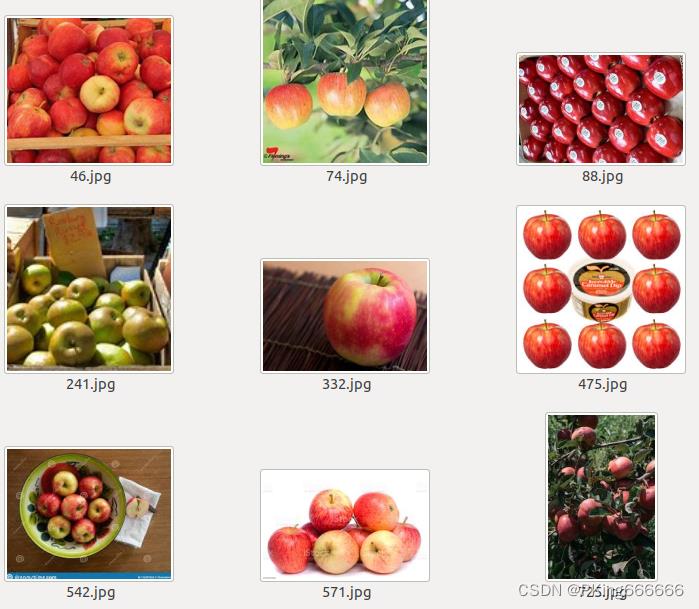 |
Fruit-Dataset包含的262种水果,分别是:
abiu, acai, acerola, ackee, alligator apple, ambarella, apple, apricot, araza, avocado, bael, banana, barbadine, barberry, bayberry, beach plum, bearberry, bell pepper, betel nut, bignay, bilimbi, bitter gourd, black berry, black cherry, black currant, black mullberry, black sapote, blueberry, bolwarra, bottle gourd, brazil nut, bread fruit, buddha s hand, buffaloberry, burdekin plum, burmese grape, caimito, camu camu, canistel, cantaloupe, cape gooseberry, carambola, cardon, cashew, cedar bay cherry, cempedak, ceylon gooseberry, che, chenet, cherimoya, cherry, chico, chokeberry, clementine, cloudberry, cluster fig, cocoa bean, coconut, coffee, common buckthorn, corn kernel, cornelian cherry, crab apple, cranberry, crowberry, cupuacu, custard apple, damson, date, desert fig, desert lime, dewberry, dragonfruit, durian, eggplant, elderberry, elephant apple, emblic, entawak, etrog, feijoa, fibrous satinash, fig, finger lime, galia melon, gandaria, genipap, goji, gooseberry, goumi, grape, grapefruit, greengage, grenadilla, guanabana, guarana, guava, guavaberry, hackberry, hard kiwi, hawthorn, hog plum, honeyberry, honeysuckle, horned melon, illawarra plum, indian almond, indian strawberry, ita palm, jaboticaba, jackfruit, jalapeno, jamaica cherry, jambul, japanese raisin, jasmine, jatoba, jocote, jostaberry, jujube, juniper berry, kaffir lime, kahikatea, kakadu plum, keppel, kiwi, kumquat, kundong, kutjera, lablab, langsat, lapsi, lemon, lemon aspen, leucaena, lillipilli, lime, lingonberry, loganberry, longan, loquat, lucuma, lulo, lychee, mabolo, macadamia, malay apple, mamey apple, mandarine, mango, mangosteen, manila tamarind, marang, mayhaw, maypop, medlar, melinjo, melon pear, midyim, miracle fruit, mock strawberry, monkfruit, monstera deliciosa, morinda, mountain papaya, mountain soursop, mundu, muskmelon, myrtle, nance, nannyberry, naranjilla, native cherry, native gooseberry, nectarine, neem, nungu, nutmeg, oil palm, old world sycomore, olive, orange, oregon grape, otaheite apple, papaya, passion fruit, pawpaw, pea, peanut, pear, pequi, persimmon, pigeon plum, pigface, pili nut, pineapple, pineberry, pitomba, plumcot, podocarpus, pomegranate, pomelo, prikly pear, pulasan, pumpkin, pupunha, purple apple berry, quandong, quince, rambutan, rangpur, raspberry, red mulberry, redcurrant, riberry, ridged gourd, rimu, rose hip, rose myrtle, rose-leaf bramble, saguaro, salak, salal, salmonberry, sandpaper fig, santol, sapodilla, saskatoon, sea buckthorn, sea grape, snowberry, soncoya, strawberry, strawberry guava, sugar apple, surinam cherry, sycamore fig, tamarillo, tangelo, tanjong, taxus baccata, tayberry, texas persimmon, thimbleberry, tomato, toyon, ugli fruit, vanilla, velvet tamarind, watermelon, wax gourd, white aspen, white currant, white mulberry, white sapote, wineberry, wongi, yali pear, yellow plum, yuzu, zigzag vine, zucchiniFruit-Dataset数据说明:
- 一个目录名代表一个标签,每个目录中该标签下的所有图像数据(图像有编号,但可能缺少数字。
- 同一种水果的不同品种一般存放在同一个目录下(例如:青苹果、黄苹果和红苹果)。
- 数据集中存在的水果图像可以包含水果在其生命的所有阶段,也可以包含水果切片。
- 图像包含至少 50% 的水果信息。
- 图像的背景可以是任何东西:单色背景、人手、水果的自然栖息地、树叶等。
- 没有重复的图像,但有一些图像(具有相同标签)具有高度相似性。
- 图像可能包含小水印。
- 部分不常见的水果,数据较难采集,只有 50~100 张图像,实际工程中,可以丢弃以获得更好的平衡和更少的种类。
水果数据集Fruit-Dataset,水果数据集Fruit-Dataset,部分数据是通过网上爬取的,存在部分错误的图片,尽管鄙人已经清洗一部分了,但还是建议你,训练前,再次清洗数据集,不然会影响模型的识别的准确率。
(2)Fruits 360蔬果数据集
Fruits 360蔬果数据集包含131种不同的水果和蔬菜,共含有90483张图片,其中
- 训练集⼤⼩:67692张图像(每张图像⼀个⽔果),
- 测试集⼤⼩:22688张图像(每张图像⼀个⽔果)
- ⽂件名格式:图像索引_100.jpg(例如32_100.jpg)或r_图像索引_100.jpg(例如r_32_100.jpg)或r2_图像索引_100.jpg或r3_图像索引_100.jpg。“ r”代表旋转的⽔果。“ r2”表⽰⽔果绕第三轴旋转。“100”来⾃图像尺⼨(100x100像素)。同⼀⽔果(例如苹果)的不同品种被存储为属于不同类别。


具体有以下种类:
Apples (different varieties: Crimson Snow, Golden, Golden-Red, Granny Smith, Pink Lady, Red, Red Delicious), Apricot, Avocado, Avocado ripe, Banana (Yellow, Red, Lady Finger), Beetroot Red, Blueberry, Cactus fruit, Cantaloupe (2 varieties), Carambula, Cauliflower, Cherry (different varieties, Rainier), Cherry Wax (Yellow, Red, Black), Chestnut, Clementine, Cocos, Dates, Eggplant, Ginger Root, Granadilla, Grape (Blue, Pink, White (different varieties)), Grapefruit (Pink, White), Guava, Hazelnut, Huckleberry, Kiwi, Kaki, Kohlrabi, Kumsquats, Lemon (normal, Meyer), Lime, Lychee, Mandarine, Mango (Green, Red), Mangostan, Maracuja, Melon Piel de Sapo, Mulberry, Nectarine (Regular, Flat), Nut (Forest, Pecan), Onion (Red, White), Orange, Papaya, Passion fruit, Peach (different varieties), Pepino, Pear (different varieties, Abate, Forelle, Kaiser, Monster, Red, Williams), Pepper (Red, Green, Yellow), Physalis (normal, with Husk), Pineapple (normal, Mini), Pitahaya Red, Plum (different varieties), Pomegranate, Pomelo Sweetie, Potato (Red, Sweet, White), Quince, Rambutan, Raspberry, Redcurrant, Salak, Strawberry (normal, Wedge), Tamarillo, Tangelo, Tomato (different varieties, Maroon, Cherry Red, Yellow), Walnut.
Fruits 360蔬果数据集的图片质量特别高,很干净,几乎每张图片的水果背景都是白色的(可能是被抠出背景了),而且存在很多旋转拍照角度的高度相似的图片。因此这种水果数据集,不太符合实际业务需求,毕竟实际应用中,我们不太可能将图片抠除背景再进行水果识别,这识别成本太高了。
(3)自定义数据集
如果需要新增类别数据,或者需要自定数据集进行训练,可以如下进行处理:
- Train和Test数据集,要求相同类别的图片,放在同一个文件夹下;且子目录文件夹命名为类别名称,如

- 类别文件:一行一个列表: class_name.txt
(最后一行,请多回车一行)
A
B
C
D
- 修改配置文件的数据路径:config.yaml
train_data: # 可添加多个数据集
- 'data/dataset/train1'
- 'data/dataset/train2'
test_data: 'data/dataset/test'
class_name: 'data/dataset/class_name.txt'
...
...3. 水果分类识别模型训练
考虑到Fruits 360蔬果数据集比较简单,且不合适用于实际应用中,因此本项目以Fruit-Dataset水果数据集为训练样本。
(1)项目框架说明
整套工程基本框架结构如下:
.
├── classifier # 训练模型相关工具
├── configs # 训练配置文件
├── data # 训练数据
├── libs
├── demo.py # 模型推理demo
├── README.md # 项目工程说明文档
├── requirements.txt # 项目相关依赖包
└── train.py # 训练文件(2)准备Train和Test数据
下载水果分类数据集,Train和Test数据集,要求相同类别的图片,放在同一个文件夹下;且子目录文件夹命名为类别名称。
数据增强方式主要采用: 随机裁剪,随机翻转,随机旋转,颜色变换等处理方式
import numbers
import random
import PIL.Image as Image
import numpy as np
from torchvision import transforms
def image_transform(input_size, rgb_mean=[0.5, 0.5, 0.5], rgb_std=[0.5, 0.5, 0.5], trans_type="train"):
"""
不推荐使用:RandomResizedCrop(input_size), # bug:目标容易被crop掉
:param input_size: [w,h]
:param rgb_mean:
:param rgb_std:
:param trans_type:
:return::
"""
if trans_type == "train":
transform = transforms.Compose([
transforms.Resize([int(128 * input_size[1] / 112), int(128 * input_size[0] / 112)]),
transforms.RandomHorizontalFlip(), # 随机左右翻转
# transforms.RandomVerticalFlip(), # 随机上下翻转
transforms.ColorJitter(brightness=0.5, contrast=0.5, saturation=0.5, hue=0.1),
transforms.RandomRotation(degrees=5),
transforms.RandomCrop([input_size[1], input_size[0]]),
transforms.ToTensor(),
transforms.Normalize(mean=rgb_mean, std=rgb_std),
])
elif trans_type == "val" or trans_type == "test":
transform = transforms.Compose([
transforms.Resize([input_size[1], input_size[0]]),
# transforms.CenterCrop([input_size[1], input_size[0]]),
# transforms.Resize(input_size),
transforms.ToTensor(),
transforms.Normalize(mean=rgb_mean, std=rgb_std),
])
else:
raise Exception("transform_type ERROR:".format(trans_type))
return transform修改配置文件数据路径:config.yaml
# 训练数据集,可支持多个数据集
train_data:
- '/path/to/Fruit-Dataset/train'
# 测试数据集
test_data: '/path/to/Fruit-Dataset/test'
# 类别文件
class_name: '/path/to/Fruit-Dataset/class_name.txt'(3)配置文件:config.yaml
- 目前支持的backbone有:googlenet,resnet[18,34,50],inception_v3,mobilenet_v2等, 其他backbone可以自定义添加
- 训练参数可以通过(configs/config.yaml)配置文件进行设置
配置文件:config.yaml说明如下:
# 训练数据集,可支持多个数据集
train_data:
- '/path/to/Fruit-Dataset/train'
# 测试数据集
test_data: '/path/to/Fruit-Dataset/test'
# 类别文件
class_name: '/path/to/Fruit-Dataset/class_name.txt'
train_transform: "train" # 训练使用的数据增强方法
test_transform: "val" # 测试使用的数据增强方法
work_dir: "work_space/" # 保存输出模型的目录
net_type: "resnet18" # 骨干网络,支持:resnet18/50,mobilenet_v2,googlenet,inception_v3
width_mult: 1.0
input_size: [ 224,224 ] # 模型输入大小
rgb_mean: [ 0.5, 0.5, 0.5 ] # for normalize inputs to [-1, 1],Sequence of means for each channel.
rgb_std: [ 0.5, 0.5, 0.5 ] # for normalize,Sequence of standard deviations for each channel.
batch_size: 32
lr: 0.01 # 初始学习率
optim_type: "SGD" # 选择优化器,SGD,Adam
loss_type: "CrossEntropyLoss" # 选择损失函数:支持CrossEntropyLoss,LabelSmoothing
momentum: 0.9 # SGD momentum
num_epochs: 100 # 训练循环次数
num_warn_up: 3 # warn-up次数
num_workers: 8 # 加载数据工作进程数
weight_decay: 0.0005 # weight_decay,默认5e-4
scheduler: "multi-step" # 学习率调整策略
milestones: [ 20,50,80 ] # 下调学习率方式
gpu_id: [ 0 ] # GPU ID
log_freq: 50 # LOG打印频率
progress: True # 是否显示进度条
pretrained: False # 是否使用pretrained模型
finetune: False # 是否进行finetune| 参数 | 类型 | 参考值 | 说明 |
|---|---|---|---|
| train_data | str, list | - | 训练数据文件,可支持多个文件 |
| test_data | str, list | - | 测试数据文件,可支持多个文件 |
| class_name | str | - | 类别文件 |
| work_dir | str | work_space | 训练输出工作空间 |
| net_type | str | resnet18 | backbone类型,resnet18/50,mobilenet_v2,googlenet,inception_v3 |
| input_size | list | [128,128] | 模型输入大小[W,H] |
| batch_size | int | 32 | batch size |
| lr | float | 0.1 | 初始学习率大小 |
| optim_type | str | SGD | 优化器,SGD,Adam |
| loss_type | str | CELoss | 损失函数 |
| scheduler | str | multi-step | 学习率调整策略,multi-step,cosine |
| milestones | list | [30,80,100] | 降低学习率的节点,仅仅scheduler=multi-step有效 |
| momentum | float | 0.9 | SGD动量因子 |
| num_epochs | int | 120 | 循环训练的次数 |
| num_warn_up | int | 3 | warn_up的次数 |
| num_workers | int | 12 | DataLoader开启线程数 |
| weight_decay | float | 5e-4 | 权重衰减系数 |
| gpu_id | list | [ 0 ] | 指定训练的GPU卡号,可指定多个 |
| log_freq | in | 20 | 显示LOG信息的频率 |
| finetune | str | model.pth | finetune的模型 |
| progress | bool | True | 是否显示进度条 |
| distributed | bool | False | 是否使用分布式训练 |
(4)开始训练
整套训练代码非常简单操作,用户只需要将相同类别的数据放在同一个目录下,并填写好对应的数据路径,即可开始训练了。
python train.py -c configs/config.yaml
(5)可视化训练过程
训练过程可视化工具是使用Tensorboard,使用方法:
# 基本方法
tensorboard --logdir=path/to/log/
# 例如
tensorboard --logdir=work_space/mobilenet_v2_1.0_CrossEntropyLoss/log
可视化效果
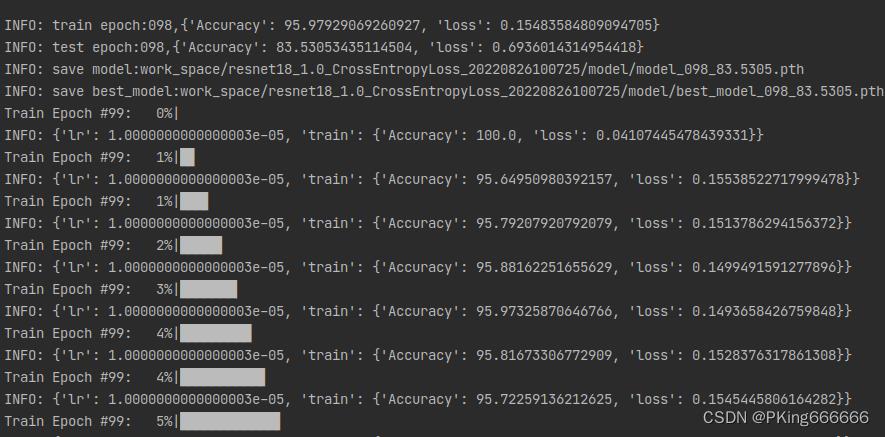 |  |
 |  |
 |  |
(6)一些优化建议
训练完成后,在水果数据集Fruit-Dataset上,训练集的Accuracy在95%左右,测试集的Accuracy在83%左右,骨干网络,可支持googlenet, resnet[18,34,50], inception_v3,mobilenet_v2等常用模型。如果想进一步提高准确率,可以尝试:
- 最重要的: 清洗数据集,水果数据集Fruit-Dataset,部分数据是通过网上爬取的,存在部分错误的图片,尽管鄙人已经清洗一部分了,但还是建议你,训练前,再次清洗数据集,不然会影响模型的识别的准确率。
- 使用不同backbone模型,比如resnet50或者更深的模型
- 增加数据增强: 已经支持: 随机裁剪,随机翻转,随机旋转,颜色变换等数据增强方式,可以尝试诸如mixup,CutMix等更复杂的数据增强方式
- 样本均衡: 建议进行样本均衡处理
- 调超参: 比如学习率调整策略,优化器(SGD,Adam等)
- 损失函数: 目前训练代码已经支持:交叉熵,LabelSmoothing,可以尝试FocalLoss等损失函数
4. 水果分类识别模型测试效果
demo.py文件用于推理和测试模型的效果,填写好配置文件,模型文件以及测试图片即可运行测试了
def get_parser():
# 配置文件
config_file = "data/pretrained/resnet18_1.0_CrossEntropyLoss_20220826100725/config.yaml"
# 模型文件
model_file = "data/pretrained/resnet18_1.0_CrossEntropyLoss_20220826100725/model/best_model_098_83.5305.pth"
# 待测试图片目录
image_dir = "data/test_images/fruit"
parser = argparse.ArgumentParser(description="Inference Argument")
parser.add_argument("-c", "--config_file", help="configs file", default=config_file, type=str)
parser.add_argument("-m", "--model_file", help="model_file", default=model_file, type=str)
parser.add_argument("--device", help="cuda device id", default="cuda:0", type=str)
parser.add_argument("--image_dir", help="image file or directory", default=image_dir, type=str)
return parser
#!/usr/bin/env bash
# Usage:
# python demo.py -c "path/to/config.yaml" -m "path/to/model.pth" --image_dir "path/to/image_dir"
python demo.py \\
-c "data/pretrained/resnet18_1.0_CrossEntropyLoss_20220826100725/config.yaml" \\
-m "data/pretrained/resnet18_1.0_CrossEntropyLoss_20220826100725/model/best_model_098_83.5305.pth" \\
--image_dir "data/test_images/fruit"运行测试结果:
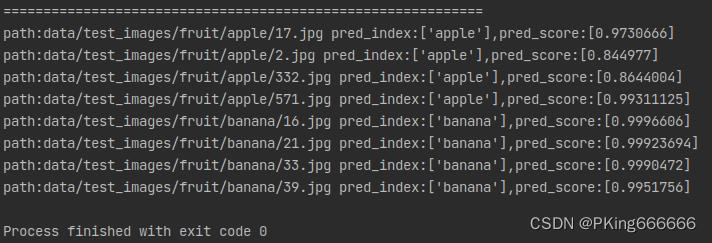
|
pred_index:['apple'],pred_score:[0.9730666] |
pred_index:['apple'],pred_score:[0.8644004] |
|
pred_index:['banana'],pred_score:[0.9996606] |
pred_index:['banana'],pred_score:[0.99923694] |




5.项目源码下载
整套项目源码内容包含:Fruit-Dataset水果数据集+水果分类识别训练代码
- Fruit-Dataset水果数据集: 该数据集包含 262 种不同种类的水果,包含常见的苹果(apple),香蕉(banana)等种类,总共有225,640 张水果图像,可满足深度学习水果种类分类识别的需求
- Fruits 360蔬果数据集: 包含131种不同的水果和蔬菜,共含有90483张图片
- 支持自定义数据集训练
- 整套水果分类训练代码和测试代码(Pytorch版本), 支持的backbone骨干网络模型有:googlenet,resnet[18,34,50],inception_v3,mobilenet_v2等, 其他backbone可以自定义添加
【源码下载】Fruit-Dataset水果数据集+水果分类识别训练代码
以上是关于GoogLeNet(Inception v1-v4)的主要内容,如果未能解决你的问题,请参考以下文章