数仓开发之DWD层
Posted 大数据阿嘉
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数仓开发之DWD层相关的知识,希望对你有一定的参考价值。
目录
三:流量域用户跳出事务事实表
3.1 主要任务
过滤用户跳出明细数据。
3.2 思路分析
1)筛选策略
跳出是指会话中只有一个页面的访问行为,如果能获取会话的所有页面,只要筛选页面数为 1 的会话即可获取跳出明细数据。
(1)离线数仓中我们可以获取一整天的数据,结合访问时间、page_id 和 last_page_id 字段对整体数据集做处理可以按照会话对页面日志进行划分,从而获得每个会话的页面数,只要筛选页面数为 1 的会话即可提取跳出明细数据;
(2)实时计算中无法考虑整体数据集,很难按照会话对页面访问记录进行划分。而本项目模拟生成的日志数据中没有 session_id(会话id)字段,也无法通过按照 session_id 分组的方式计算每个会话的页面数。
(3)因此,我们需要换一种解决思路。如果能判定首页日志之后没有同一会话的页面访问记录同样可以筛选跳出数据。如果日志数据完全有序,会话页面不存在交叉情况,则跳出页面的判定可以分为三种情况:
① 两条紧邻的首页日志进入算子,可以判定第一条首页日志所属会话为跳出会话;
② 第一条首页日志进入算子后,接收到的第二条日志为非首页日志,则第一条日志所属会话不是跳出会话;
③ 第一条首页日志进入算子后,没有收到第二条日志,此时无法得出结论,必须继续等待。但是无休止地等待显然是不现实的。因此,人为设定超时时间,超时时间内没有第二条数据就判定为跳出行为,这是一种近似处理,存在误差,但若能结合业务场景设置合理的超时时间,误差是可以接受的。本程序为了便于测试,设置超时时间为 10s,为了更快看到效果可以设置更小的超时时间,生产环境的设置结合业务需求确定。
由上述分析可知,情况 ① 的首页数据和情况 ③ 中的超时数据为跳出明细数据。
2)知识储备
(1)Flink CEP
跳出行为需要考虑会话中的两条页面日志数据(第一条为首页日志且超时时间内没有接收到第二条,或两条紧邻的首页日志到来可以判定第一条为跳出数据),要筛选的是组合事件,用 filter 无法实现这样的功能,由此引出 Flink CEP。
Flink CEP(Complex Event Processing 复杂事件处理)是在Flink上层实现的复杂事件处理库,可以在无界流中检测出特定的事件模型。用户定义复杂规则(Pattern),将其应用到流上,即可从流中提取满足 Pattern 的一个或多个简单事件构成的复杂事件。
(2)Flink CEP 定义的规则之间的连续策略
- 严格连续: 期望所有匹配的事件严格的一个接一个出现,中间没有任何不匹配的事件。对应方法为 next();
- 松散连续: 忽略匹配的事件之间的不匹配的事件。对应方法为followedBy();
- 不确定的松散连续: 更进一步的松散连续,允许忽略掉一些匹配事件的附加匹配。对应方法为followedByAny()。
3)实现步骤
(1)按照 mid 分组
不同访客的浏览记录互不干涉,跳出行为的分析应在相同 mid 下进行,首先按照 mid 分组。
(2)定义 CEP 匹配规则
①规则一
跳出行为对应的页面日志必然为某一会话的首页,因此第一个规则判定 last_page_id 是否为 null,是则返回 true,否则返回 false;
②规则二
规则二和规则一之间的策略采用严格连续,要求二者之间不能有其它事件。判断 last_page_id 是否为 null,在数据完整有序的前提下,如果不是 null 说明本条日志的页面不是首页,可以断定它与规则一匹配到的事件同属于一个会话,返回 false;如果是 null 则开启了一个新的会话,此时可以判定上一条页面日志所属会话为跳出会话,是我们需要的数据,返回 true;
③超时时间
超时时间内规则一被满足,未等到第二条数据则会被判定为超时数据。
(3)把匹配规则(Pattern)应用到流上
根据 Pattern 定义的规则对流中数据进行筛选。
(4)提取超时流
提取超时流,超时流中满足规则一的数据即为跳出明细数据,取出。
(5)合并主流和超时流,写入 Kafka 调出明细主题
(6)结果分析
理论上 Flink 可以通过设置水位线保证数据严格有序(超时时间足够大),在此前提下,同一 mid 的会话之间不会出现交叉。若假设日志数据没有丢失,按照上述匹配规则,我们可以获得两类明细数据
①两个规则都被满足,满足规则一的数据为跳出明细数据。在会话之间不会交叉且日志数据没有丢失的前提下,此时获取的跳出明细数据没有误差;
②第一条数据满足规则二,超时时间内没有接收到第二条数据,水位线达到超时时间,第一条数据被发送到超时侧输出流。即便在会话之间不交叉且日志数据不丢失的前提下,此时获取的跳出明细数据仍有误差,因为超时时间之后会话可能并未结束,如果此时访客在同一会话内跳转到了其它页面,就会导致会话页面数大于 1 的访问被判定为跳出行为,下游计算的跳出率偏大。误差大小和设置的超时时间呈负相关关系,超时时间越大,理论上误差越小。
3.3 图解
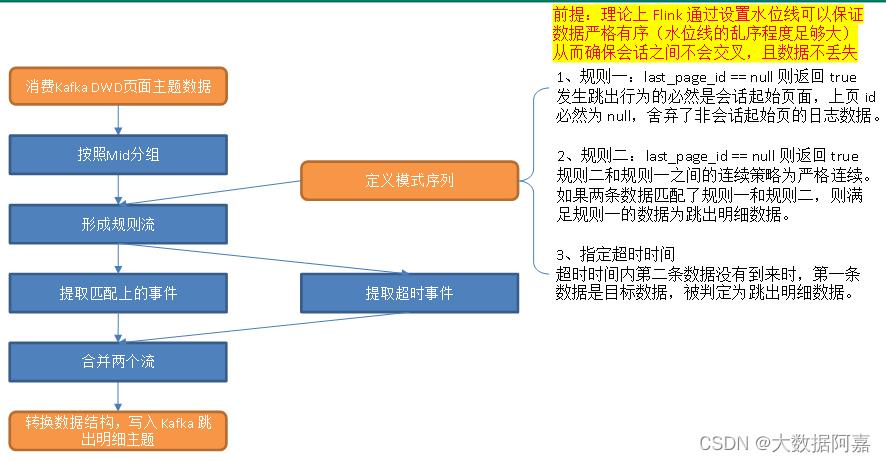
3.4 代码
1)添加 CEP 相关依赖
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-cep_$scala.version</artifactId>
<version>$flink.version</version>
</dependency>2)主程序
package com.atguigu.app.dwd;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONObject;
import com.atguigu.utils.MyKafkaUtil;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.cep.CEP;
import org.apache.flink.cep.PatternSelectFunction;
import org.apache.flink.cep.PatternStream;
import org.apache.flink.cep.PatternTimeoutFunction;
import org.apache.flink.cep.pattern.Pattern;
import org.apache.flink.cep.pattern.conditions.SimpleCondition;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.util.OutputTag;
import java.time.Duration;
import java.util.List;
import java.util.Map;
public class DwdTrafficUserJumpDetail
//数据源:web/app -> nginx -> 日志服务器(.log) -> flume ->Kafka (ODS) -> FlinkApp -> Kafka(DWD) -> Flink(App) -> Kafka(DWD)
//程 序:Mock(lg.sh) -> Kafka(ZK) -> BaseLogApp -> Kafka(ZK) -> DwdTrafficUniqueVisitorDetail ->Kafka(ZK)
public static void main(String[] args) throws Exception
//1.获取执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
/*
//1.1 开启CheckPoint
env.enableCheckpointing(5 *6000L , CheckpointingMode.EXACTLY_ONCE);
env.getCheckpointConfig().setCheckpointTimeout(10 *6000L);
env.getCheckpointConfig().setMaxConcurrentCheckpoints(2);
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(3,5000L));
//1.2 设置状态后端
env.setStateBackend(new HashMapStateBackend());
env.getCheckpointConfig().setCheckpointStorage("hdfs://hadoop107:8020/211126/ck");
System.setProperty("HADOOP_USER_NAME","atguigu");
*/
//2.读取kafka页面主题日志数据
String topic= "dwd_traffic_page_log";
// String topic= "topic_log";
String groupId= "dwd_traffic_user_jump_detail";
DataStreamSource<String> kafkaDS = env.addSource(MyKafkaUtil.getFlinkKafkaConsumer(topic, groupId));
//3.将每行数据转换为JSON对象
SingleOutputStreamOperator<JSONObject> jsonObjDS = kafkaDS.map(JSON::parseObject);
//4.按照Mid分组 & 提取事件时间
KeyedStream<JSONObject, String> keyedStream = jsonObjDS
//设置水位线(事件时间 )
.assignTimestampsAndWatermarks(WatermarkStrategy.<JSONObject>forBoundedOutOfOrderness(Duration.ofSeconds(2))
.withTimestampAssigner(new SerializableTimestampAssigner<JSONObject>()
@Override
public long extractTimestamp(JSONObject jsonObject, long l)
return jsonObject.getLong("ts");
))
.keyBy(json -> json.getJSONObject("common").getString("mid"));
//5.定义CEP的模式序列
/*5.1
Pattern<JSONObject, JSONObject> pattern = Pattern.<JSONObject>begin("start").where(new SimpleCondition<JSONObject>()
@Override
public boolean filter(JSONObject value) throws Exception
return value.getJSONObject("page").getString("last_page_id") == null;
).next("next").where(new SimpleCondition<JSONObject>()
@Override
public boolean filter(JSONObject value) throws Exception
return value.getJSONObject("page").getString("last_page_id") == null;
).within(Time.seconds(10));
*/
//5.2使用循环模式来编写模式序列
Pattern<JSONObject, JSONObject> pattern = Pattern.<JSONObject>begin("start").where(new SimpleCondition<JSONObject>()
@Override
public boolean filter(JSONObject value) throws Exception
return value.getJSONObject("page").getString("last_page_id") == null;
)
.times(2) // 默认是宽松近邻
.consecutive() // 严格近邻
.within(Time.seconds(10));
//6.将模式序列作用到流上
PatternStream<JSONObject> patternStream = CEP.pattern(keyedStream, pattern);
//7.提取时间(匹配上的事件 以及 超时事件)
//侧输出流:收集超时数据
OutputTag<String> timeOutTag = new OutputTag<String>("timeOut")
;
SingleOutputStreamOperator<String> selectDS = patternStream.select(timeOutTag,
new PatternTimeoutFunction<JSONObject, String>()
@Override
public String timeout(Map<String, List<JSONObject>> map, long l) throws Exception
return map.get("start").get(0).toJSONString();
, new PatternSelectFunction<JSONObject, String>()
@Override
public String select(Map<String, List<JSONObject>> map) throws Exception
return map.get("start").get(0).toJSONString();
);
DataStream<String> timeOutDS = selectDS.getSideOutput(timeOutTag);
//8.合并两种事件
DataStream<String> unionDS = selectDS.union(timeOutDS);
//9.将数据写出到kafka
selectDS.print("Select>>>>>");
timeOutDS.print("TimeOut>>>");
String targetTopic = "dwd_traffic_user_jump_detail";
unionDS.addSink(MyKafkaUtil.getFlinkKafkaProducer(targetTopic));
//10.启动任务
env.execute();
四:交易域加购事务事实表
4.1 主要任务
提取加购操作生成加购表,并将字典表中的相关维度退化到加购表中,写出到 Kafka 对应主题。
4.2 思路分析
1)维度关联(维度退化)实现策略分析
本章业务事实表的构建全部使用 FlinkSQL 实现,字典表数据存储在 MySQL 的业务数据库中,要做维度退化,就要将这些数据从 mysql 中提取出来封装成 FlinkSQL 表,Flink 的 JDBC SQL Connector 可以实现我们的需求。
2)知识储备
(1)JDBC SQL Connector
JDBC 连接器可以让 Flink 程序从拥有 JDBC 驱动的任意关系型数据库中读取数据或将数据写入数据库。
如果在 Flink SQL 表的 DDL 语句中定义了主键,则会以 upsert 模式将流中数据写入数据库,此时流中可以存在 UPDATE/DElETE(更新/删除)类型的数据。否则,会以 append 模式将数据写出到数据库,此时流中只能有 INSERT(插入)类型的数据。
DDL 用法实例如下。
CREATE TABLE MyUserTable (
id BIGINT,
name STRING,
age INT,
status BOOLEAN,
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://localhost:3306/mydatabase',
'table-name' = 'users'
);(2)Lookup Cache
JDBC 连接器可以作为时态表关联中的查询数据源(又称维表)。目前,仅支持同步查询模式。
默认情况下,查询缓存(Lookup Cache)未被启用,需要设置 lookup.cache.max-rows 和 lookup.cache.ttl 参数来启用此功能。
Lookup 缓存是用来提升有 JDBC 连接器参与的时态关联性能的。默认情况下,缓存未启用,所有的请求会被发送到外部数据库。当缓存启用时,每个进程(即 TaskManager)维护一份缓存。收到请求时,Flink 会先查询缓存,如果缓存未命中才会向外部数据库发送请求,并用查询结果更新缓存。如果缓存中的记录条数达到了 lookup.cache.max-rows 规定的最大行数时将清除存活时间最久的记录。如果缓存中的记录存活时间超过了 lookup.cache.ttl 规定的最大存活时间,同样会被清除。
缓存中的记录未必是最新的,可以将 lookup.cache.ttl 设置为一个更小的值来获得时效性更好的数据,但这样做会增加发送到数据库的请求数量。所以需要在吞吐量和正确性之间寻求平衡。
(3)Lookup Join
Lookup Join 通常在 Flink SQL 表和外部系统查询结果关联时使用。这种关联要求一张表(主表)有处理时间字段,而另一张表(维表)由 Lookup 连接器生成。
Lookup Join 做的是维度关联,而维度数据是有时效性的,那么我们就需要一个时间字段来对数据的版本进行标识。因此,Flink 要求我们提供处理时间用作版本字段。
此处选择调用 PROCTIME() 函数获取系统时间,将其作为处理时间字段。该函数调用示例如下
tableEnv.sqlQuery("select PROCTIME() proc_time")
.execute()
.print();
// 结果
+----+-------------------------+
| op | proc_time |
+----+-------------------------+
| +I | 2022-04-09 15:45:50.752 |
+----+-------------------------+
1 row in set(4)JDBC SQL Connector 参数解读
-
- connector:连接器类型,此处为 jdbc
- url:数据库 url
- table-name:数据库中表名
- lookup.cache.max-rows:lookup 缓存中的最大记录条数
- lookup.cache.ttl:lookup 缓存中每条记录的最大存活时间
- username:访问数据库的用户名
- password:访问数据库的密码
- driver:数据库驱动,注意:通常注册驱动可以省略,但是自动获取的驱动是 com.mysql.jdbc.Driver,Flink CDC 2.1.0 要求 mysql 驱动版本必须为 8 及以上,在 mysql-connector -8.x 中该驱动已过时,新的驱动为 com.mysql.cj.jdbc.Driver。省略该参数控制台打印的警告如下
Loading class `com.mysql.jdbc.Driver'. This is deprecated. The new driver class is
`com.mysql.cj.jdbc.Driver'. The driver is automatically registered via the SPI and manual
loading of the driver class is generally unnecessary.5)Kafka Connector
本节需要从 Kafka 读取数据封装为 Flink SQL 表,并将 Flink SQL 表的数据写入 Kafka,而整个过程的数据操作类型均为 INSERT,使用 Kafka Connector 即可。
Kafka Connector 参数如下
- connector:指定使用的连接器,对于 Kafka,只用 'kafka'
- topic:主题
- properties.bootstrap.servers:以逗号分隔的 Kafka broker 列表。注意:可以通过 properties.* 的方式指定配置项,*的位置用 Kafka 官方规定的配置项的 key 替代。并不是所有的配置都可以通过这种方式配置,因为 Flink 可能会将它们覆盖,如:'key.deserializer' 和 'value.deserializer'
- properties.group.id:消费者组 ID
- format:指定 Kafka 消息中 value 部分的序列化的反序列化方式,'format' 和 'value.format' 二者必有其一
- scan.startup.mode:Kafka 消费者启动模式,有四种取值
- 'earliest-offset':从偏移量最早的位置开始读取数据
- 'latest-offset':从偏移量最新的位置开始读取数据
- 'group-offsets':从 Zookeeper/Kafka broker 中维护的消费者组偏移量开始读取数据
- 'timestamp':从用户为每个分区提供的时间戳开始读取数据
- 'specific-offsets':从用户为每个分区提供的偏移量开始读取数据
默认值为 group-offsets。要注意:latest-offset 与 Kafka 官方提供的配置项 latest 不同, Flink 会将偏移量置为最新位置,覆盖掉 Zookeeper 或 Kafka 中维护的偏移量。与官方提供的 latest 相对应的是此处的 group-offsets。
3)执行步骤
(1)设置表状态的 ttl。
ttl(time-to-live)即存活时间。表之间做普通关联时,底层会将两张表的数据维护到状态中,默认情况下状态永远不会清空,这样会对内存造成极大的压力。表状态的 ttl 是 Idle(空闲,即状态未被更新)状态被保留的最短时间,假设 ttl 为 10s,若状态中的数据在 10s 内未被更新,则未来的某个时间会被清除(故而 ttl 是最短存活时间)。ttl 默认值为 0,表示永远不会清空状态。
字典表是作为维度表被 Flink 程序维护的,字典表与加购表不存在业务上的滞后关系,而 look up join 是由主表触发的,即主表数据到来后去 look up 表中查询对应的维度信息,如果缓存未命中就要从外部介质中获取数据,这就要求主表数据在状态中等待一段时间,此处将 ttl 设置为 5s,主表数据会在状态中保存至少 5s。而 look up 表的 cache 是由建表时指定的相关参数决定的,与此处的 ttl 无关。
(2)读取购物车表数据。
(3)建立 Mysql-LookUp 字典表。
(4)关联购物车表和字典表,维度退化。
4.3 图解

4.4 代码
1)补充 Flink SQL 相关依赖
要执行 Flink SQL 程序,补充相关依赖。JDBC SQL Connector 需要的依赖包含在 Flink CDC 需要的依赖中,不可重复引入。
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-blink_$scala.version</artifactId>
<version>$flink.version</version>
</dependency>2)在 KafkaUtil 中补充 getKafkaDDL 方法和 getKafkaSinkDDL 方法
/**
* Kafka-Source DDL 语句
*
* @param topic 数据源主题
* @param groupId 消费者组
* @return 拼接好的 Kafka 数据源 DDL 语句
*/
public static String getKafkaDDL(String topic, String groupId)
return " with ('connector' = 'kafka', " +
" 'topic' = '" + topic + "'," +
" 'properties.bootstrap.servers' = '" + BOOTSTRAP_SERVERS + "', " +
" 'properties.group.id' = '" + groupId + "', " +
" 'format' = 'json', " +
" 'scan.startup.mode' = 'group-offsets')";
/**
* Kafka-Sink DDL 语句
*
* @param topic 输出到 Kafka 的目标主题
* @return 拼接好的 Kafka-Sink DDL 语句
*/
public static String getKafkaSinkDDL(String topic)
return "WITH ( " +
" 'connector' = 'kafka', " +
" 'topic' = '" + topic + "', " +
" 'properties.bootstrap.servers' = '" + BOOTSTRAP_SERVERS + "', " +
" 'format' = 'json' " +
")";
3)创建 MysqlUtil 工具类
封装 mysqlLookUpTableDDL() 方法和 getBaesDicLookUpDDL() 方法,用于将 MySQL 数据库中的字典表读取为 Flink LookUp 表,以便维度退化。
package com.atguigu.gmall.realtime.util;
public class MysqlUtil
public static String getBaseDicLookUpDDL()
return "create table `base_dic`(\\n" +
"`dic_code` string,\\n" +
"`dic_name` string,\\n" +
"`parent_code` string,\\n" +
"`create_time` timestamp,\\n" +
"`operate_time` timestamp,\\n" +
"primary key(`dic_code`) not enforced\\n" +
")" + MysqlUtil.mysqlLookUpTableDDL("base_dic");
public static String mysqlLookUpTableDDL(String tableName)
String ddl = "WITH (\\n" +
"'connector' = 'jdbc',\\n" +
"'url' = 'jdbc:mysql://hadoop102:3306/gmall',\\n" +
"'table-name' = '" + tableName + "',\\n" +
"'lookup.cache.max-rows' = '10',\\n" +
"'lookup.cache.ttl' = '1 hour',\\n" +
"'username' = 'root',\\n" +
"'password' = '000000',\\n" +
"'driver' = 'com.mysql.cj.jdbc.Driver'\\n" +
")";
return ddl;
4)主程序
package com.atguigu.app.dwd;
import com.atguigu.utils.MyKafkaUtil;
import com.atguigu.utils.MysqlUtil;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
public class DwdTradeCartAdd
public static void main(String[] args) throws Exception
//1.获取执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
/*
//1.1 开启CheckPoint
env.enableCheckpointing(5 *6000L , CheckpointingMode.EXACTLY_ONCE);
env.getCheckpointConfig().setCheckpointTimeout(10 *6000L);
env.getCheckpointConfig().setMaxConcurrentCheckpoints(2);
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(3,5000L));
//1.2 设置状态后端
env.setStateBackend(new HashMapStateBackend());
env.getCheckpointConfig().setCheckpointStorage("hdfs://hadoop107:8020/211126/ck");
System.setProperty("HADOOP_USER_NAME","atguigu");
*/
//2.读取topic_db主题的数据创建表
tableEnv.executeSql(MyKafkaUtil.getTopicDb("Cart_Add"));
//3.过滤出加购数据
Table cartAddTable = tableEnv.sqlQuery(
"select " +
" `data`['id'] id, " +
" `data`['user_id'] user_id, " +
" `data`['sku_id'] sku_id, " +
" `data`['cart_price'] cart_price, " +
" if(`type`='insert',`data`['sku_num'],cast(cast(`data`['sku_num'] as int) - cast(`old`['sku_num'] as int) as string)) sku_num, " +
" `data`['sku_name'] sku_name, " +
" `data`['is_checked'] is_checked, " +
" `data`['create_time'] create_time, " +
" `data`['operate_time'] operate_time, " +
" `data`['is_ordered'] is_ordered, " +
" `data`['order_time'] order_time, " +
" `data`['source_type'] source_type, " +
" `data`['source_id'] source_id, " +
" pt " +
"from topic_db " +
"where `database` = 'gmall' " +
"and `table` = 'cart_info' " +
"and `type` = 'insert' " +
"or (`type` = 'update' " +
" and " +
" `old`['sku_num'] is not null " +
" and " +
" cast(`data`['sku_num'] as int) > cast(`old`['sku_num'] as int)) ");
//将加购表转换为流进行测试
// tableEnv.toAppendStream(cartAddTable, Row.class).print(">>>>>>");
tableEnv.createTemporaryView("cart_info_table",cartAddTable);
//4.读取Mysql 的 base_dic 表作为 LookUp 表
tableEnv.executeSql(MysqlUtil.getBaseDicLookUpDDL());
//5.关联两张表
Table cartAddWithDicTable = tableEnv.sqlQuery(
"select " +
" ci.id, " +
" ci.user_id, " +
" ci.sku_id, " +
" ci.cart_price, " +
" ci.sku_num, " +
" ci.sku_name, " +
" ci.is_checked, " +
" ci.create_time, " +
" ci.operate_time, " +
" ci.is_ordered, " +
" ci.order_time, " +
" ci.source_type source_type_id, " +
" dic.dic_name source_type_name, " +
" ci.source_id " +
"from cart_info_table ci " +
"join base_dic FOR SYSTEM_TIME AS OF ci.pt as dic " +
"on ci.source_type = dic.dic_code ");
tableEnv.createTemporaryView("cart_add_dic_table",cartAddWithDicTable);
//6.使用DDL的方式创建加购事实表
tableEnv.executeSql(
"create table dwd_cart_add( " +
" `id` STRING, " +
" `user_id` STRING, " +
" `sku_id` STRING, " +
" `cart_price` STRING, " +
" `sku_num` STRING, " +
" `sku_name` STRING, " +
" `is_checked` STRING, " +
" `create_time` STRING, " +
" `operate_time` STRING, " +
" `is_ordered` STRING, " +
" `order_time` STRING, " +
" `source_type_id` STRING, " +
" `source_type_name` STRING, " +
" `source_id` STRING " +
")" +MyKafkaUtil.getKafkaSinkDDL("dwd_trade_cart_add"));
//7.将数据写出
tableEnv.executeSql("insert into dwd_cart_add select * from cart_add_dic_table")
.print();
//tableEnv.executeSql("insert into dwd_cart_add select * from "+ cartAddWithDicTable);
//8.启动任务
env.execute("DwdTradeCartAdd");
以上是关于数仓开发之DWD层的主要内容,如果未能解决你的问题,请参考以下文章