大数据技术之Flume
Posted Red-P
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据技术之Flume相关的知识,希望对你有一定的参考价值。
文章目录
第 1 章 Flume 概述
1.1 Flume 定义
Flume 是 Cloudera 提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传
输的系统。Flume 基于流式架构,灵活简单。
为什么选用Flume?

因为flume 实时,动态的 ,如果读的是前一天的数据 完全 可以用 -put上传
Flume最主要的作用就是,实时读取服务器本地磁盘的数据,将数据写入到HDFS。
1.2 Flume 基础架构
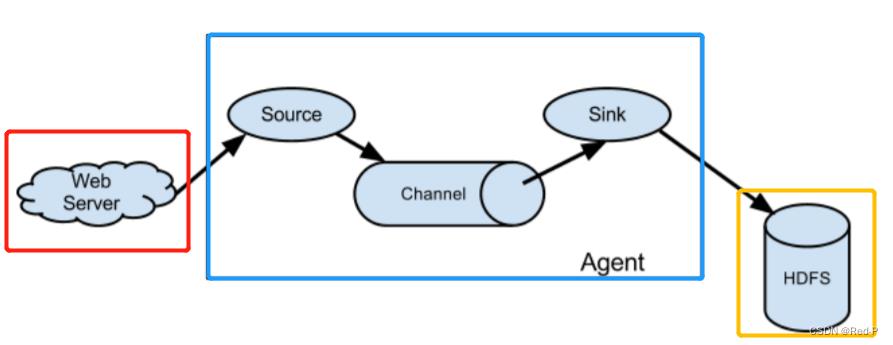
红色代表 数据源
蓝色代表 Flume
黄色代表 数据目的地
这个图就是从官网上扣下来的。
1.2.1 Agent
Agent 是一个 JVM 进程,它以事件的形式将数据从源头送至目的。
Agent 主要有 3 个部分组成,Source、Channel、Sink。
1.2.2 Source
Source 是负责接收数据到 Flume Agent 的组件。Source 组件可以处理各种类型、各种格式的日志数据,
1.2.3 Sink
Sink 不断地轮询 Channel 中的事件且批量地移除它们,并将这些事件批量写入到存储或索引系统、或者被发送到另一个 Flume Agent。
1.2.4 Channel
Channel 是位于 Source 和 Sink 之间的缓冲区。因此,Channel 允许 Source 和 Sink 运作在不同的速率上。Channel 是线程安全的,可以同时处理几个 Source 的写入操作和几个Sink 的读取操作。
Flume 自带两种 Channel:Memory Channel 和 File Channel。
Memory Channel 是内存中的队列。Memory Channel 在不需要关心数据丢失的情景下适用。如果需要关心数据丢失,那么 Memory Channel 就不应该使用,因为程序死亡、机器宕机或者重启都会导致数据丢失。
File Channel 将所有事件写到磁盘。因此在程序关闭或机器宕机的情况下不会丢失数据。
1.2.5 Event
传输单元,Flume 数据传输的基本单元,以 Event 的形式将数据从源头送至目的地。
Event 由 Header 和 Body 两部分组成,Header用来存放该 event 的一些属性,为 K-V 结构,Body 用来存放该条数据,形式为字节数组。

第 2 章 Flume 入门
2.1 案例1

最基础的 监听端口 案例
2.1.1判断 44444 端口是否被占用
1、sudo netstat -nlp | grep 44444
2.1.2在 flume 目录下创建 job 文件夹并且创建flume文件。
2.1.3使用 netcat 工具向本机的 44444 端口发送内容
nc localhost 44444
hello
详细讲一个配置文件
添加内容如下:
# Name the components on this agent a1:表示agent的名称
a1.sources = r1 r1:表示a1的Source的名称
a1.sinks = k1 k1:表示a1的Sink的名称
a1.channels = c1 c1:表示a1的Channel的名称
# Describe/configure the source
a1.sources.r1.type = netcat 表示a1的输入源类型为netcat端口类型
a1.sources.r1.bind = localhost 表示a1的监听的主机
a1.sources.r1.port = 44444 表示a1的监听的端口号
# Describe the sink
a1.sinks.k1.type = logger 表示a1的输出目的地是控制台logger类型
# Use a channel which buffers events in memory
a1.channels.c1.type = memory 表示a1的channel类型是memory内存型
a1.channels.c1.capacity = 1000 表示a1的channel总容量1000个event
a1.channels.c1.transactionCapacity = 100
表示a1的channel传输时收集到了100条event以后再去提交事务
# Bind the source and sink to the channel
a1.sources.r1.channels = c1 表示将r1和c1连接起来
a1.sinks.k1.channel = c1 表示将k1和c1连接起来
写法1
bin/flume-ng agent --conf conf/ --name a1
--conf-file job/flume-netcat-logger.conf
-Dflume.root.logger=INFO,console
第二种写法:
bin/flume-ng agent -c conf/ -n a1
-f job/flume-netcat-logger.conf
-Dflume.root.logger=INFO,console
–conf/-c:表示配置文件存储在 conf/目录
–name/-n:表示给 agent 起名为 a1
–conf-file/-f:flume 本次启动读取的配置文件是在 job 文件夹下的 flume-telnet.conf
文件。
-Dflume.root.logger=INFO,console :-D 表示 flume 运行时动态修改 flume.root.logger
参数属性值,并将控制台日志打印级别设置为 INFO 级别。日志级别包括:log、info、warn、error。
注:配置文件来源于官方手册Flume官方文档
2.2 案例2
1)案例需求:实时监控 Hive 日志,并上传到 HDFS 中
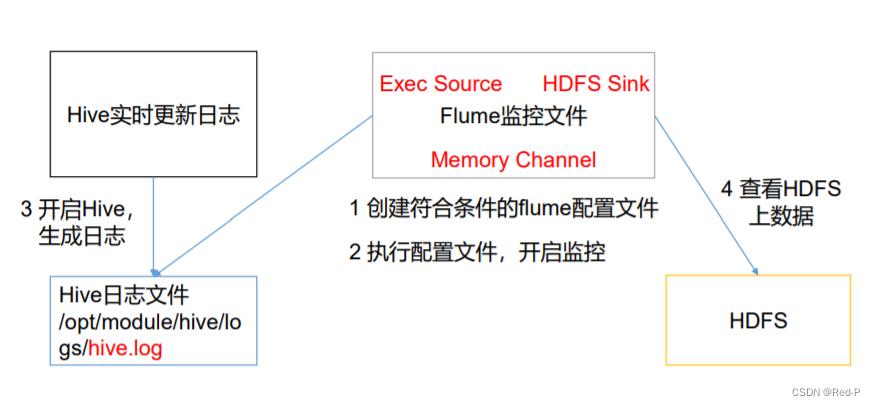
2)创建flume文件
# Name the components on this agent
a2.sources = r2 # 定义source
a2.sinks = k2 #定义sink
a2.channels = c2 #定义channe
# Describe/configure the source
a2.sources.r2.type = exec #定义source类型为exec可执行命令的
a2.sources.r2.command = tail -F /opt/module/hive/logs/hive.log
# Describe the sink
a2.sinks.k2.type = hdfs
a2.sinks.k2.hdfs.path = hdfs://hadoop102:9820/flume/%Y%m%d/%H
#上传文件的前缀
a2.sinks.k2.hdfs.filePrefix = logs-
#是否按照时间滚动文件夹
a2.sinks.k2.hdfs.round = true
#多少时间单位创建一个新的文件夹
a2.sinks.k2.hdfs.roundValue = 1
#重新定义时间单位
a2.sinks.k2.hdfs.roundUnit = hour
#是否使用本地时间戳
a2.sinks.k2.hdfs.useLocalTimeStamp = true
#积攒多少个 Event 才 flush 到 HDFS 一次
a2.sinks.k2.hdfs.batchSize = 100
#设置文件类型,可支持压缩
a2.sinks.k2.hdfs.fileType = DataStream
#多久生成一个新的文件
a2.sinks.k2.hdfs.rollInterval = 60
#设置每个文件的滚动大小
a2.sinks.k2.hdfs.rollSize = 134217700
#文件的滚动与 Event 数量无关
a2.sinks.k2.hdfs.rollCount = 0
# Use a channel which buffers events in memory
a2.channels.c2.type = memory
a2.channels.c2.capacity = 1000
a2.channels.c2.transactionCapacity = 100
# Bind the source and sink to the channel
a2.sources.r2.channels = c2
a2.sinks.k2.channel = c2
2.3 案例3
2.3.1案例需求:使用 Flume 监听整个目录的实时追加文件,并上传至 HDFS
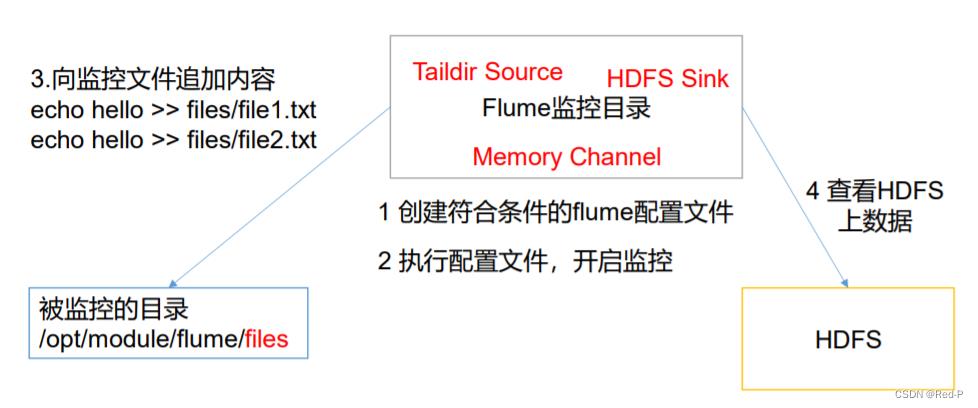
a3.sources = r3
a3.sinks = k3
a3.channels = c3
# Describe/configure the source #定义source类型
a3.sources.r3.type = TAILDIR
a3.sources.r3.positionFile = /opt/module/flume/tail_dir.json
a3.sources.r3.filegroups = f1 f2 #指定position_file位置
#定义监控目录文件
a3.sources.r3.filegroups.f1 = /opt/module/flume/files/.*file.*
a3.sources.r3.filegroups.f2 = /opt/module/flume/files2/.*log.*
# Describe the sink
a3.sinks.k3.type = hdfs #sink类型为hdfs
a3.sinks.k3.hdfs.path =hdfs://hadoop102:9820/flume/upload2/%Y%m%d/%H
#上传文件的前缀
a3.sinks.k3.hdfs.filePrefix = upload-
#是否按照时间滚动文件夹
a3.sinks.k3.hdfs.round = true
#多少时间单位创建一个新的文件夹
a3.sinks.k3.hdfs.roundValue = 1
#重新定义时间单位
a3.sinks.k3.hdfs.roundUnit = hour
#是否使用本地时间戳
a3.sinks.k3.hdfs.useLocalTimeStamp = true
#积攒多少个 Event 才 flush 到 HDFS 一次
a3.sinks.k3.hdfs.batchSize = 100
#设置文件类型,可支持压缩
a3.sinks.k3.hdfs.fileType = DataStream
#多久生成一个新的文件
a3.sinks.k3.hdfs.rollInterval = 60
#设置每个文件的滚动大小大概是 128M
a3.sinks.k3.hdfs.rollSize = 134217700
#文件的滚动与 Event 数量无关
a3.sinks.k3.hdfs.rollCount = 0
# Use a channel which buffers events in memory
a3.channels.c3.type = memory
a3.channels.c3.capacity = 1000
a3.channels.c3.transactionCapacity = 100
# Bind the source and sink to the channel
a3.sources.r3.channels = c3
a3.sinks.k3.channel = c3
Taildir 说明:
Taildir Source 维护了一个 json 格式的 position File,其会定期的往 position File
中更新每个文件读取到的最新的位置,因此能够实现断点续传。Position File 的格式如下:
"inode":2496272,"pos":12,"file":"/opt/module/flume/files/file1.t
xt"
"inode":2496275,"pos":12,"file":"/opt/module/flume/files/file2.t
xt"
根据 inode + file 名字 来确定pos 容易因为更名 而导致 文件重复生成 ,方法一不改文件名
方法二 修改源码1只有 inode 确定
注:Linux 中储存文件元数据的区域就叫做 inode,每个 inode 都有一个号码,操作系统用 inode 号码来识别不同的文件,Unix/Linux 系统内部不使用文件名,而使用 inode 号码来识别文件.
以上三个案例够入门Flume了
第 3 章 Flume 进阶
3.1 事务
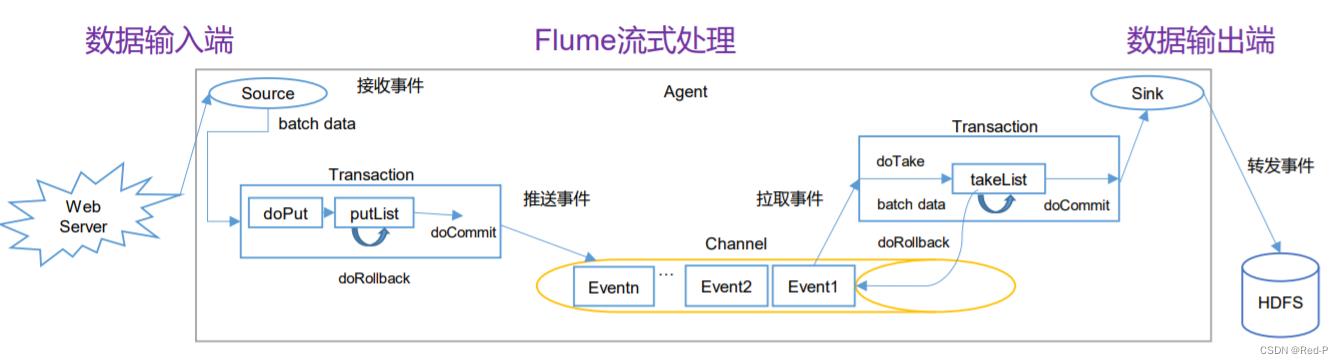
Put事务流程(Source -> Channel)
•doCommit:检查channel内存队列是否足够合并。
•doRollback:channel内存队列空间不足,回滚数据
Take事务
•doTake:将数据取到临时缓冲区takeList,并将数据发送到HDFS
•doCommit:如果数据全部发送成功,则清除临时缓冲区takeList
•doRollback:数据发送过程中如果出现异常,rollback将临时缓冲区takeList中的数据归还给channel内存队列。
3.2 Flume Agent 内部原理(架构)
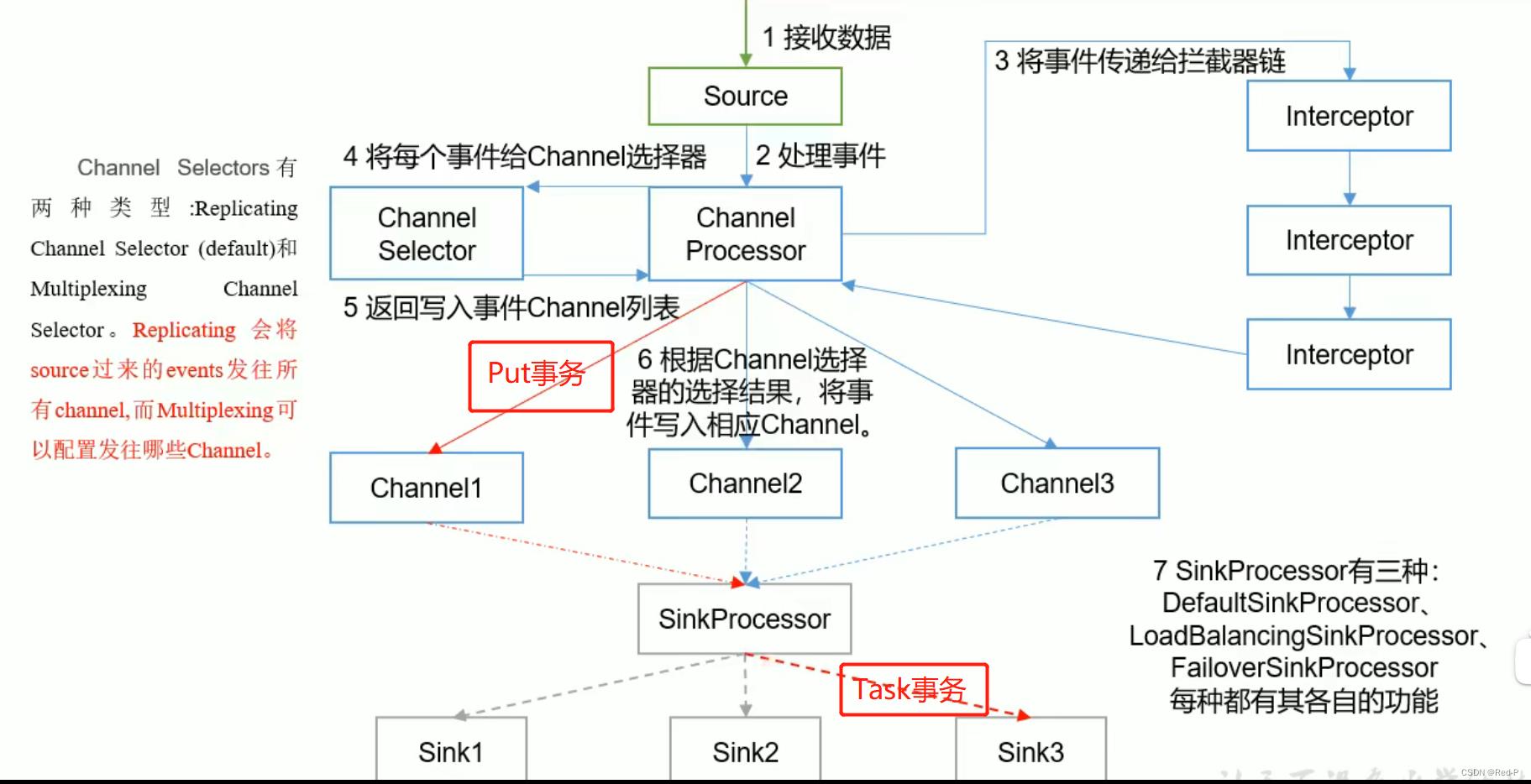
1)ChannelSelector
ChannelSelector 的作用就是选出 Event 将要被发往哪个 Channel。其共有两种类型,分别是 Replicating(复制)(默认)和 Multiplexing(多路复用)。
第六步才是开启事务
一个Sink只能有一个 Channel ,一个Channel 可以有多个Sink
7 SinkProcessor有三种:
DefaultSinkProcessor(一个Channel 绑定一个Sink)、
LoadBalancingSinkProcessor(负载均衡):
Sink组以轮询方式去Channel 拉取数据 ,Channel 是源源不断来的数据 实时
FailoverSinkProcessor (高可用) (故障转移) (先一个人,如果坏了,换下一个人)
3.3 Flume 拓扑结构
3.3.1 简单串联

(avro)数据序列化的系统 是一个基于二进制数据传输高性能的中间件,是一个轻量级 RPC数据框架
这种模式是将多个 flume 顺序连接起来了,从最初的 source 开始到最终 sink 传送的目的存储系统。此模式不建议桥接过多的 flume 数量, flume 数量过多不仅会影响传输速率,而且一旦传输过程中某个节点 flume 宕机,会影响整个传输系统。
3.3.2 复制和多路复用
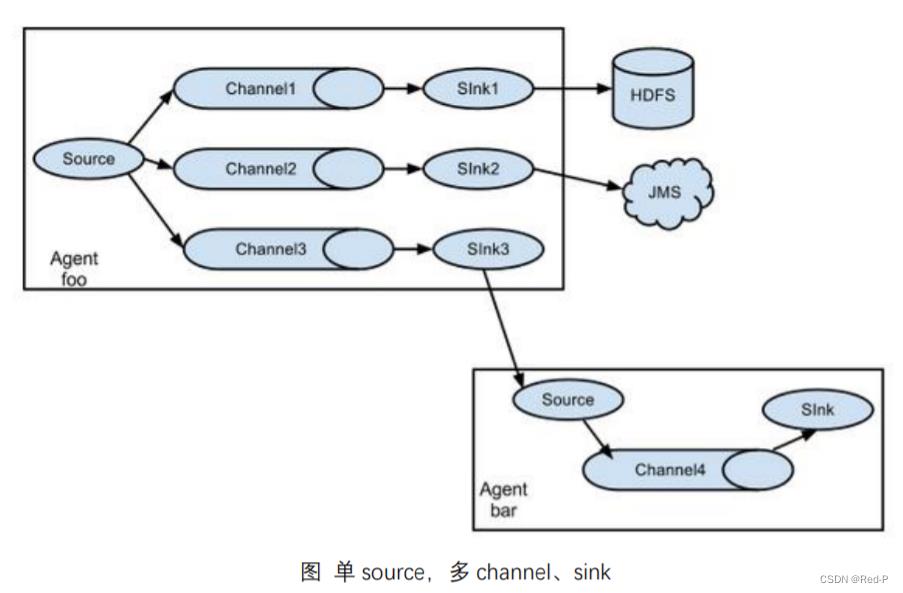 Flume 支持将事件流向一个或者多个目的地。这种模式可以将相同数据复制到多个channel 中,或者将不同数据分发到不同的 channel 中,sink 可以选择传送到不同的目的地。
Flume 支持将事件流向一个或者多个目的地。这种模式可以将相同数据复制到多个channel 中,或者将不同数据分发到不同的 channel 中,sink 可以选择传送到不同的目的地。
3.3.3 负载均衡和故障转移

Flume支持使用将多个sink逻辑上分到一个sink组,sink组配合不同的SinkProcessor可以实现负载均衡和错误恢复的功能。
3.3.4 聚合

这种模式是我们最常见的,也非常实用,日常 web 应用通常分布在上百个服务器,大者甚至上千个、上万个服务器。产生的日志,处理起来也非常麻烦。用 flume 的这种组合方式能很好的解决这一问题,每台服务器部署一个 flume 采集日志,传送到一个集中收集日志的flume,再由此 flume 上传到 hdfs、hive、hbase 等,进行日志分析
3.4 Flume 企业开发案例
3.4.1 复制 案例
1)案例需求
使用 Flume-1 监控文件变动,Flume-1 将变动内容传递给 Flume-2,Flume-2 负责存储到 HDFS。同时 Flume-1 将变动内容传递给 Flume-3,Flume-3 负责输出到 Local FileSystem。

配置 1 个接收日志文件的 source 和两个 channel、两个 sink,分别输送给 flume-flume-hdfs 和 flume-flume-dir。
接收日志的 source
# Name the components on this agent
a1.sources = r1
a1.sinks = k1 k2
a1.channels = c1 c2
# 将数据流复制给所有 channel
a1.sources.r1.selector.type = replicating #默认副本机制
# Describe/configure the source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /opt/module/hive/logs/hive.log
a1.sources.r1.shell = /bin/bash -c
# Describe the sink
# sink 端的 avro 是一个数据发送者 一个sink绑定1个source
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = hadoop102 #服务端的 服务器
a1.sinks.k1.port = 4141
a1.sinks.k2.type = avro
a1.sinks.k2.hostname = hadoop102 #服务端的 服务器
a1.sinks.k2.port = 4142
# Describe the channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
a1.channels.c2.type = memory
a1.channels.c2.capacity = 1000
a1.channels.c2.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1 c2 # 一个source绑定 2 个 channel
a1.sinks.k1.channel = c1 # 2个sink对应2 个source
a1.sinks.k2.channel = c2
服务端flume到hdfs
# Name the components on this agent
a2.sources = r1
a2.sinks = k1
a2.channels = c1
# Describe/configure the source
# source 端的 avro 是一个数据接收服务
a2.sources.r1.type = avro
a2.sources.r1.bind = hadoop102
a2.sources.r1.port = 4141
# Describe the sink
a2.sinks.k1.type = hdfs
a2.sinks.k1.hdfs.path = hdfs://hadoop102:9820/flume2/%Y%m%d/%H
#上传文件的前缀
a2.sinks.k1.hdfs.filePrefix = flume2-
#是否按照时间滚动文件夹
a2.sinks.k1.hdfs.round = true
#多少时间单位创建一个新的文件夹
a2.sinks.k1.hdfs.roundValue = 1
#重新定义时间单位
a2.sinks.k1.hdfs.roundUnit = hour
#是否使用本地时间戳
a2.sinks.k1.hdfs.useLocalTimeStamp = true
#积攒多少个 Event 才 flush 到 HDFS 一次
a2.sinks.k1.hdfs.batchSize = 100
#设置文件类型,可支持压缩
a2.sinks.k1.hdfs.fileType = DataStream
#多久生成一个新的文件
a2.sinks.k1.hdfs.rollInterval = 30
#设置每个文件的滚动大小大概是 128M
a2.sinks.k1.hdfs.rollSize = 134217700
#文件的滚动与 Event 数量无关
a2.sinks.k1.hdfs.rollCount = 0
# Describe the channel
a2.channels.c1.type = memory
a2.channels.c1.capacity = 1000
a2.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a2.sources.r1.channels = c1
a2.sinks.k1.channel = c1
服务端flume到本地
# Name the components on this agent
a3.sources = r1
a3.sinks = k1
a3.channels = c2
# Describe/configure the source
a3.sources.r1.type = avro
a3.sources.r1.bind = hadoop102
a3.sources.r1.port = 4142
# Describe the sink
a3.sinks.k1.type = file_roll
a3.sinks.k1.sink.directory = /opt/module/data/flume3
# Describe the channel
a3.channels.c2.type = memory
a3.channels.c2.capacity = 1000
a3.channels.c2.transactionCapacity = 100
# Bind the source and sink to the channel
a3.sources.r1.channels = c2
a3.sinks.k1.channel = c2
3.4.2 聚合
1)案例需求:
hadoop102 上的 Flume-1 监控文件/opt/module/group.log,
hadoop103 上的 Flume-2 监控某一个端口的数据流,
Flume-1 与 Flume-2 将数据发送给 hadoop104 上的 Flume-3,Flume-3 将最终数据打印到控制台。
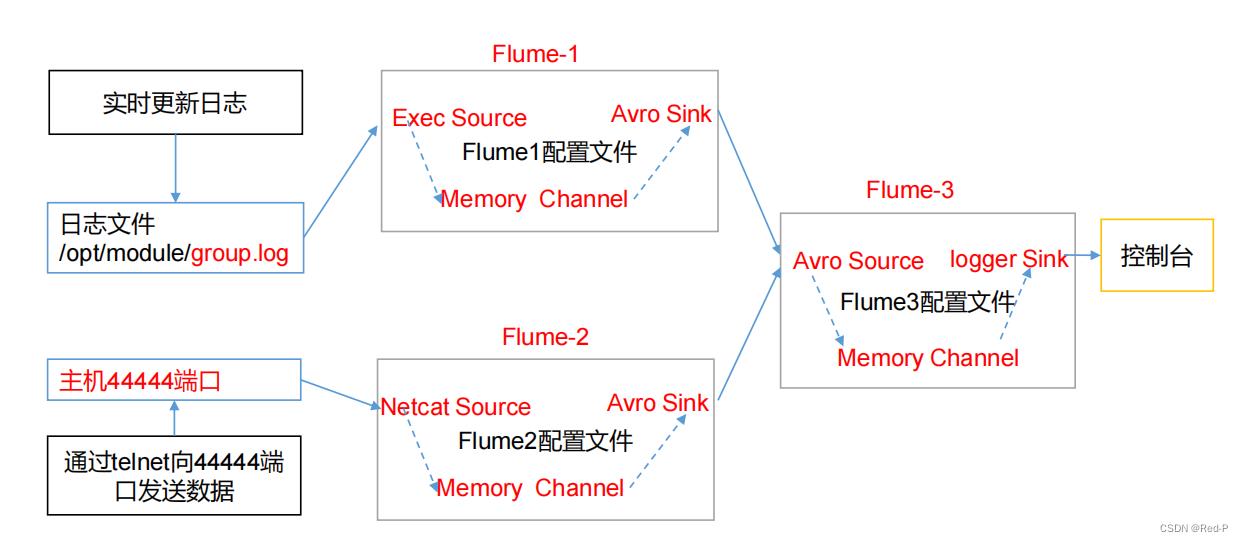
配置 Source 用于监控 hive.log 文件,配置 Sink 输出数据到下一级 Flume。
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /opt/module/group.log
a1.sources.r1.shell = /bin/bash -c
# Describe the sink
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = hadoop104
a1.sinks.k1.port = 4141
# Describe the channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
配置 Source 监控端口 44444 数据流,配置 Sink 数据到下一级 Flume:
# Name the components on this agent
a2.sources = r1
a2.sinks = k1
a2.channels = c1
# Describe/configure the source
a2.sources.r1.type = netcat
a2.sources.r1.bind = hadoop103
a2.sources.r1.port = 44444
# Describe the sink
a2.sinks.k1.type = avro
a2.sinks.k1.hostname = hadoop104
a2.sinks.k1.port = 4141
# Use a channel which buffers events in memory
a2.channels.c1.type = memory
a2.channels.c1.capacity = 1000
a2.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a2.sources.r1.channels = c1
a2.sinks.k1.channel = c1
配置 source 用于接收 flume1 与 flume2 发送过来的数据流,最终合并后 sink 到控制台。
# Name the components on this agent
a3.sources = r1
a3.sinks = k1
a3.channels = c1
# Describe/configure the source
a3.sources.r1.type = avro
a3.sources.r1.bind = hadoop104
a3.sources.r1.port = 4141
# Describe the sink
a3.sinks.k1.type = logger
# Describe the channel
a3.channels.c1.type = memory
a3.channels.c1.capacity = 1000
a3.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a3.sources.r1.channels = c1
a3.sinks.k1.channel = c1
这就已经非常全了,除了几个自定义的,我觉得那个对初学者不太友好,所以没有加进来 。
以上是关于大数据技术之Flume的主要内容,如果未能解决你的问题,请参考以下文章