结合论文看Youtube推荐系统中召回和排序的演进之路(中)篇
Posted 搜索与推荐Wiki
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了结合论文看Youtube推荐系统中召回和排序的演进之路(中)篇相关的知识,希望对你有一定的参考价值。
上一篇(结合论文看Youtube推荐系统中召回和排序的演进之路(上)篇)主要介绍的是Youtube发表的三篇论文,但主要集中在机器学习方向,接下来会用几篇论文说明一下Youtube在深度学习推荐系统方向做的工作。
在介绍Youtube的DNN之前,先介绍一篇Google的非常经典的深度学习推荐算法Wide & Deep,虽然Youtube 也属于Google,这里之所以先介绍Wide & Deep,因为我个人觉得这应该是深度学习应用在推荐系统排序上的「基石」之作,而且其提出的框架也是非常的经典。
2016年-Google Wide & Deep
Wide & Deep的论文全称为:《Wide & Deep Learning for Recommender Systems》,其首次发表应该是在2015年末,然后2016年的时候中了ACM的Deep Learning for Recommender Systems Workshop。
背景
该论文提出了一种深度学习排序模型的框架,主要是联合线性模型和深度学习模型一起训练的新的框架下的模型。
Wide 部分是一个广义线性模型,因为具有非线性特征变换功能,而广泛应用在分类和回归上。通过特征之间的组合来对用户的兴趣进行排序是十分有效和可解释的,然后依赖大量的特征工程。相对于线性模型而言,DNN不强依赖人工特征,但可能由于高维稀疏的特征而产生过拟合。
推荐系统的一个挑战是同时满足对历史行为的总结和扩展,即Memorizaton 和 Generalization,其具体含义如下:
- Memorization:近似的被定义为学习物品或特征的共性,探索用户历史行为数据中的相关性。
- Generalization:基于相关性的传递,探索在历史行为中很少或者没有出现过的新特征组合情况。
这篇论文的主要贡献分为以下三点:
- Wide & Deep联合训练具有嵌入的前馈神经网络和具有特征变换的线性模型,用于具有稀疏输入的通用推荐系统
- WD在google应用商店上进行了线上测试和评估
- 在TensorFlow API中贡献了源码,方便调用
算法
Wide & Deep算法的原理可以使用下面的一张图表示:
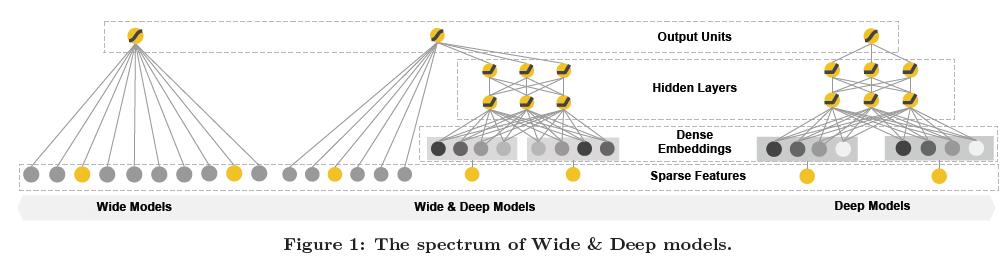
a)Wide部分
wide部分对应上图中的左侧部分,通常是一个广义线性模型: y = w ∗ x + b y=w*x + b y=w∗x+b。
- y y y:是要预测的结果
- x x x:是一组特征向量
- w w w:模型的参数
- b b b:偏置量
特征集合包含的是原始输入和他们对应的特征转换,其中一个比较重要的转换是:cross-product transformation,其对应的公式如下:
ϕ
k
(
x
)
=
∏
i
=
1
d
x
i
c
k
i
\\phi k(x)=\\prod_i=1^d x_i^c_ki
ϕk(x)=i=1∏dxicki
c
k
i
c_ki
cki 属于
0
,
1
0,1
0,1
上边的公式实现的其实就是one-hot编码,比如当gender=female,language=en时为1,其他为0。
b)Deep部分
deep部分对应上图中的右侧部分,是一个前馈神经网络。对于分类特征,原始输入是字符串(比如language=en)。这些稀疏、高维的分类特征第一步是转化为低维、密集的向量。这些向量通常在10-100维之间,一般采用随机的方法进行初始化,在训练过过程中通过最小化损失函数来优化模型。这些低维的向量传到神经网络的隐层中去。
每个隐层的计算方式如下:
a
(
l
+
1
)
=
f
(
W
l
a
l
+
b
l
)
a^(l+1) = f(W^la^l + b^l)
a(l+1)=f(Wlal+bl)
其中:
- l l l:神经网络的层数
- f f f:激活函数(通常是relus)
- a l a^l al:第l层的输出值
- b l b^l bl:第l层的偏置
- W l W^l Wl:第l层的权重
c)联合训练
wide部分和deep部分使用输出结果的对数几率加权和作为预测值,然后将其输入到一个逻辑回归函数用来联合训练。论文中强调了联合训练(Join training)和整体训练(ensemble)的区别。
- Ensemble:两个模型分别独立训练,只在最终预测的时候才将两个模型结合计算;单个模型需要更大(比如进行特征转换)来保证结合后的准确率
- Join trainging:在训练时,同时考虑wide部分和deep部分以及两个模型拼接起来的权重来同时优化所有的参数;wide部分可以通过少量的特征交叉来弥补deep部分的弱势
wide & deep的join training采用的是下批量梯度下降算法(min-batch stochastic optimization)进行优化的。在实验中,wide部分采用的是FTRL+L1,deep部分采用的是Adag。
对于LR,模型的预测结果如下:
P
(
Y
=
1
∣
x
)
=
σ
(
w
w
i
d
e
T
[
x
,
ϕ
x
]
+
W
d
e
e
p
T
a
(
l
f
)
+
b
)
P(Y=1|x)=\\sigma (w^T_wide[x,\\phi x] + W^T_deepa^(l_f)+b)
P(Y=1∣x)=σ(wwideT[x,ϕx]+WdeepTa(lf)+b)
其中:
- Y Y Y:label
- σ ( . ) \\sigma (.) σ(.):表示sigmoid函数
- ϕ ( x ) \\phi (x) ϕ(x):原始特征x的交叉转换
- b b b:偏置
- w w i d e w_wide wwide:wide模型的权重
- w d e e p w_deep wdeep: a ( l f ) a^(l_f) a(lf)的权重
系统实现
Google的团队主要是再APP商店上进行了算法的实验,并取得了不粗的效果,APP商店的架构图如下:

上图主要包含了两部分,一部分是检索系统,一部分是排序系统。当用户进入app store时,被视作是一次query查询,伴随着的是用户维度和上下文维度的特征,检索系统会根据这些信息通过模型或者人工制定的规则匹配到一些用可能点击或者购买的APP。同时,这一次的请求行为会记录在日志中作为训练数据使用。
数据库中包含了百万级别的app,每次查询推荐系统不可能对所有的app进行排序,因此第一步是挑选候选集,然后在使用排序系统对候选集中的每个APP进行打分,计算出来的分数为P(y|x),即通过特征x计算出来的用户行为y的可能性。这些特征包括:
- 用户维度的特征(城市,年龄,人口统计学特征等)
- 上下文特征(设备,几点请求,周几请求)
- APP维度特征(app上线时长,app的历史统计信息)
app推荐系统实现如下图所示,主要包含:数据准备,模型训练,模型服务。

a)数据准备
用户和app的展示数据用来生成训练数据,每次展示对应一条样本,label是用户是否安装推荐的app,安装的话为1,否则为0。
分类特征映射成ID编码类数据,连续型特征先映射到CDF(累积分布函数),再离散化到0-1,其离散化的方式如下:
x
=
i
−
1
n
−
1
x = \\fraci-1n-1
x=n−1i−1
含义:首先将数据分为n份,落入第i份的数据离散化后为
x
x
x
b)模型训练

训练的模型结构图如上所示,wide部分的包含了用户安装app和展示app的交叉特征,deep部分每个分类特征生成32维的特征向量,连接所有的特征向量作为低维密集的特征,大约1200维。
论文中提到了一个注意点:如果每一次都重新训练的话,将会花费大量的时间和精力,为了解决这个问题,采取的方案时热启动,即每次新产生训练数据的时候,从之前的模型中读取embedding和线性模型的权重来初始化新模型,在接入实时流之前使用之前的模型进行校验,保证不出问题。
c)模型服务
为了保证每个请求都可以在 10 ms 内返回结果,我们通过多线程并行运行来优化性能,而不是单个 batch 内对所有候选集的 score 进行计算。
总结
Memorization(记忆) and generalization(泛化)对于推荐系统而言很重,线性模型能够有效的记录特征之间的交互,神经网络模型能够低维的嵌入特征泛化到可能的特征交叉组合。目前wide & deep一般是企业进行深度学习推荐系统尝试的首选,而且在企业应用也十分广泛。
同时由于Wide & Deep算法的左右部分很容易被替换,因此也开辟了很多尝试和实验的可能性。
2016年-Youtube 深度学习推荐系统
这篇论文是Youtube2016年发表在RecSys上的,16年之前Youtube关于推荐系统的优化主要集中在机器学习方向(一般会再往前推1到2年,一般方案成熟时才会公布出来),自此开启了深度学习与推荐系统的主要工作,下面我们来看看这一篇论文介绍的内容。
论文详细介绍了Youtube是如何基于深度学习构建推荐系统的,包括召回部分和排序部分,下面的内容将会分为三部分进行介绍:
- Youtube 深度推荐系统概述
- 基于深度学习做召回
- 基于深度学习做排序
- 实践经验和见解
Youtube 深度推荐系统概述
整个推荐系统的架构如下图所示,其中candidate generation为生成候选池的神经网络,主要负责从大量的内容中产出少量的用户感兴趣的候选集合,ranking为排序的神经网络,最终推荐少量用户感兴趣的内容给用户。
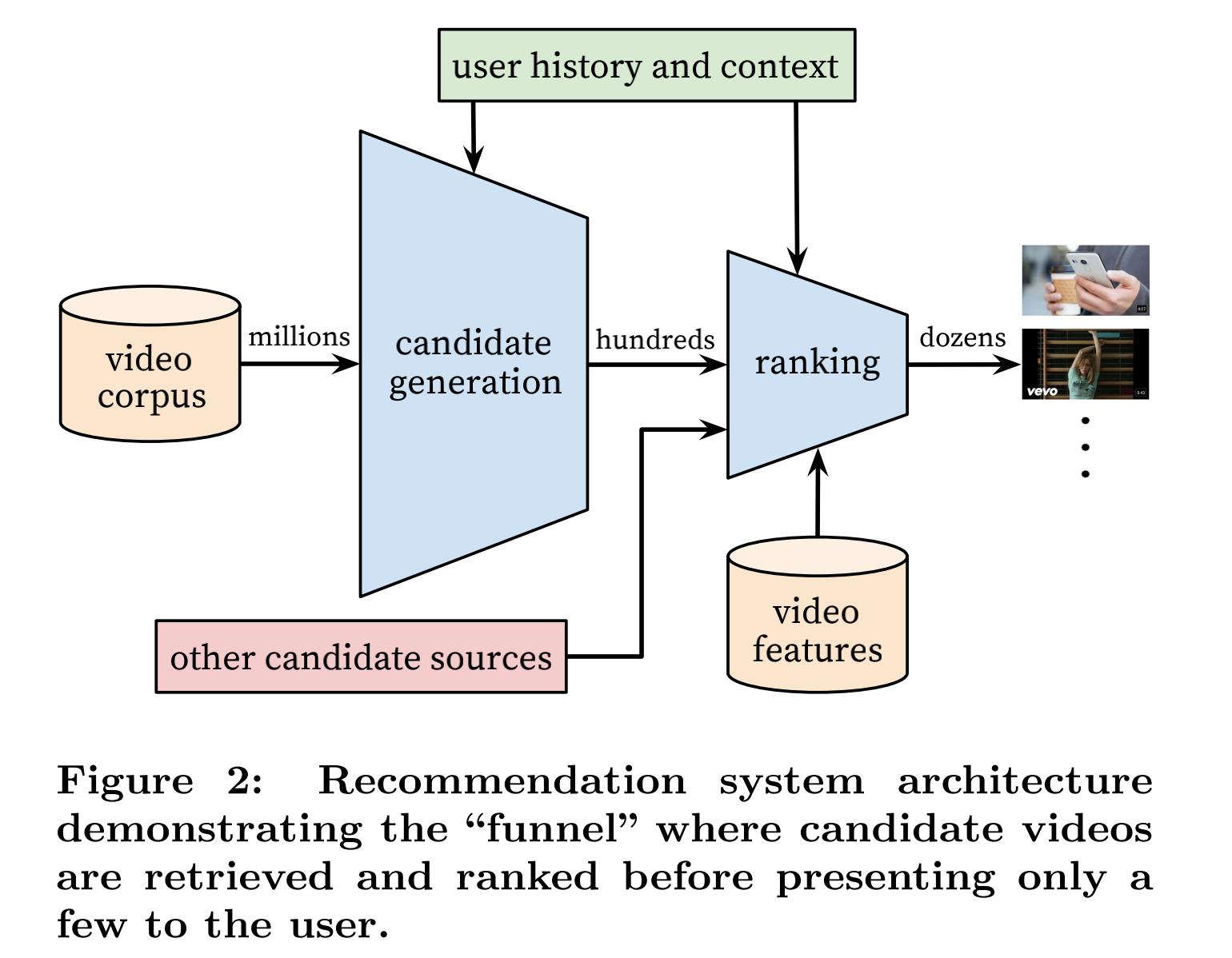
两阶段推荐方法允许我们从大量视频中进行推荐,同时确保设备上出现的少量视频是个性化的,并且适合用户。此外,这种设计允许混合由其他来源生成的候选源。
论文中在验证推荐系统的好坏时,离线主要参考:精确率(precision,准确率是Accuracy)、召回率、loss值,线上主要通过ABTest来进行相关指标的验证,比如点击率、观看时长等。
基于深度学习的召回
a)网络结构
深度学习召回模型的网络结构如下图所示:
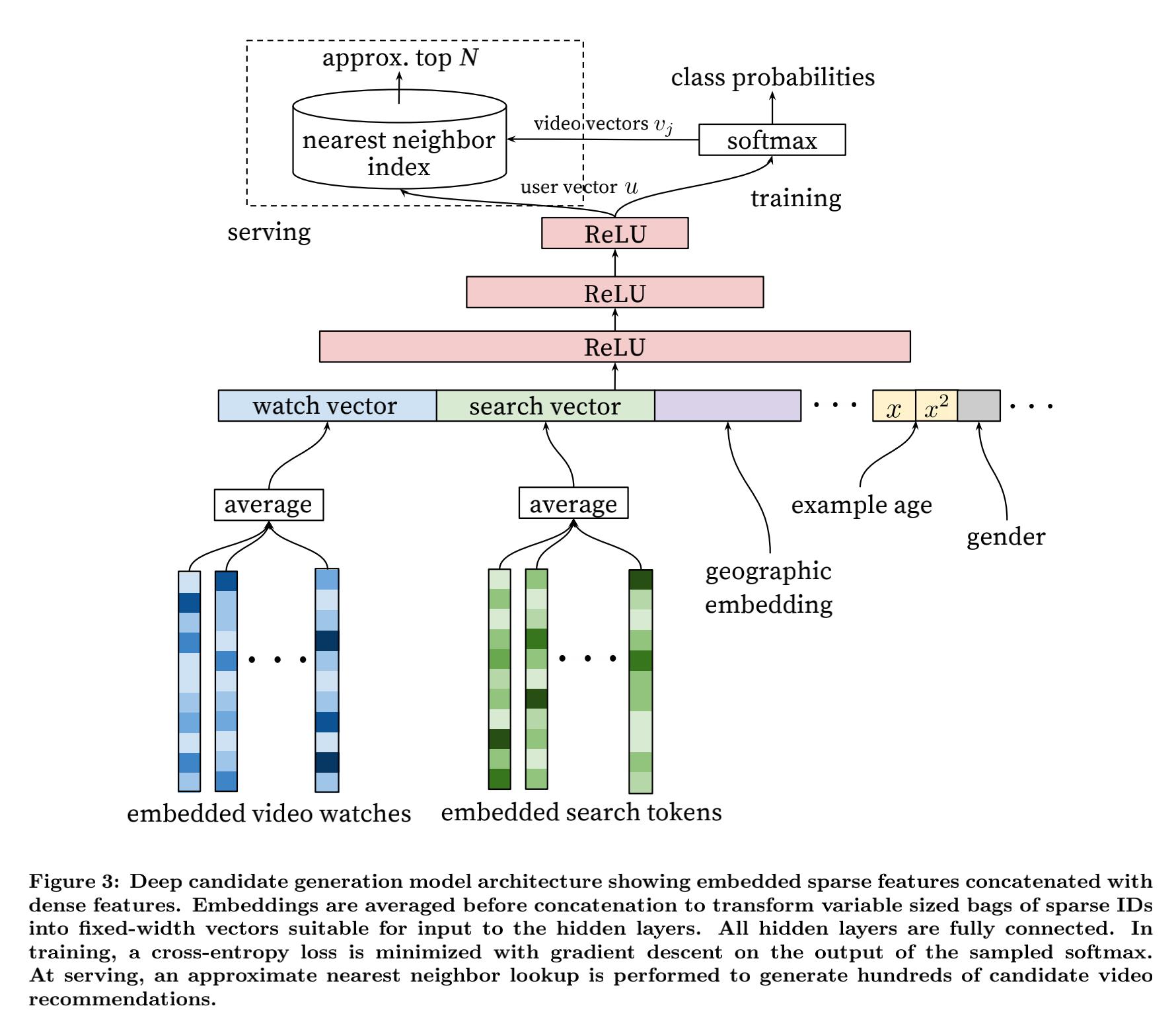
使用到的特征包括:
- 观看序列视频的平均embedding、搜索关键词的平均embedding、其他序列embedding
- 用户的地理位置信息、设备信息(embedding编码之后的)
- 人口统计学特征(年龄、性别、登录状态等,并将其进行归一化到[0,1])
然后将所有特征进行拼接,得到网络的原始输入特征。
这里需要注意的是,论文中将推荐问题看成了多分类问题来进行模型的训练,如下面公式所示:
P
(
w
t
=
i
∣
U
,
C
)
=
e
v
i
u
∑
j
∈
V
e
v
j
u
P(w_t = i| U,C) = \\frac e^v_i u \\sum_j \\in V e^v_j u
P(wt=i∣U,C)=∑j∈Vevjueviu
其中:
- U U U 表示 u s e r user user
- C C C 表示上下文
- w t w_t wt 表示 t t t时刻看到的视频
- u u u 表示 u s e r user user的embedding编码
- v v v 表示 v i d e o video video的embedding编码
b)召回模型中注意的点
论文中提到使用深度学习构建模型的好处是可以很轻松的添加连续、类别特征,在构建模型的过程中有几个需要注意的点:
- 1、虽然Youtube平台上包括显式反馈数据,但是构建数据集的时候采用的是隐式反馈,即用户观看了一个视频,则视为一条正样本
- 2、因为作为分类来进行模型的训练,负样本规模巨大,所以采用随机负采样的方法构建负样本
- 3、使用word2vec等方法产出基础的video embedding,并随着模型的训练和其他参数一起更新
- 4、论文中特意提到了一个特征:Age,视频的年龄特征,因为用户上传的视频随着时间的变化,其流行度是极其不平稳的,如果忽略了这个特征,会引起一定的偏差,因此定义了视频年龄这个特征,对于新上传的视频是0。论文中还特意提到引入时间特征和不引入时间特征的对比图,如下所示,蓝色的线为基本模型,红色的线为增加了age特征,可以看出增加该特征后,模型预估的分布十分接近经验分布。

- 5、构建用户序列数据时,应该是基于全平台的数据进行构建的,而不仅仅是推荐结果,这样有利于新内容的建模
- 6、构建序列时每个用户采用相同长度的序列,目的是降低活跃用户的影响
- 7、打乱搜索序列数据,避免时序带来影响
- 8、选取序列时,只使用label前的序列数据,避免引起数据穿越
- 9、视频和搜索关键词被编码成256长度的embedding,序列长度为50
- 10、用户的最终表示向量和视频的最终表示向量维度要一致,然后才能做内积计算,如结构图的右上角所示
c)在线召回
在线服务阶段,通过视频向量 v v v和用户向量 u u u 进行相似度计算,为了满足时延要求,在进行实际的召回计算时采用的是最近邻查询的方式。对于每个用户向量 u u u,对视频库中的所有视频根据向量 v v v做最近邻算法,得到top-N的视频作为召回结果。
基于深度学习的排序
a)网络结构
排序模型的网络结构图如下所示:
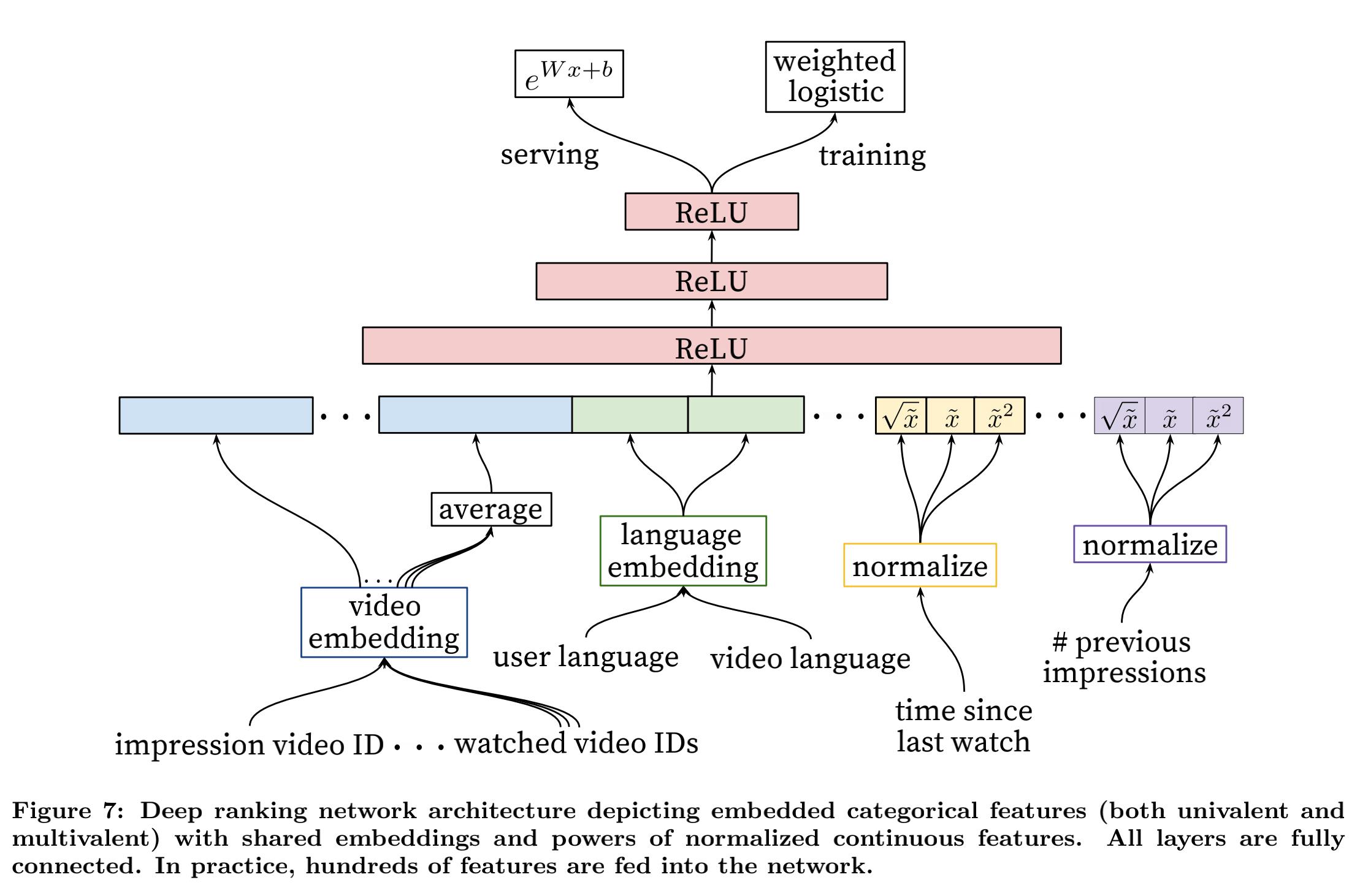
整个结构分为:
- 特征输入拼接层:序列embedding特征,类别特征的embedding,连续特征的处理之后进行拼接
- 三层的神经网络:每层神经网络激活函数使用的是ReLU,最优得结构为: 1024 − > 512 − > 256 1024 ->512 ->256 1024−>512−>256
- 输出层:在训练时,采用得时加权得逻辑回归,在线预测时,采用的是 e W x + b e^Wx + b eWx+b
b)特征表示
模型使用到的特征是非常丰富的,首先将特征分为:离散特征和连续特征(每类特征的处理方式不同),离散特征又可以划分为二值的(比如登录状态,即是否登录)和多值的(用户搜索关键词),连续特征主要是一些统计类特征,比如观看时长,年龄等。
论文中提到一些独特的特征构造和一些通用的特征处理方式。
1、特征构造
- 用户会上传视频到指定的频道,那么用户在其上传频道下的观看视频次数是一个很重要的特征(也可以扩展到,用户在需要排序的item所属频道下的观看次数等统计指标)
- 用户距离上一次观看item所属频道下的视频的时间
- 用户的实时交互特征也特别重要,比如第一刷的时候,用户对视频产生了行为(正向的或者负向的),那么在第二刷的时候应该被体现到(但是这个比较依赖数据实时处理技术,对数据延迟不太友好)
- 其他的就是一些正常的特征构造技巧,但一些独特的特征还是需要深入业务进行了解和挖掘
2、类别特征的embedding编码
- 类别特征的embedding编码可以采用基础的word2v
以上是关于结合论文看Youtube推荐系统中召回和排序的演进之路(中)篇的主要内容,如果未能解决你的问题,请参考以下文章