mxgate是gpcopy同步速度的2倍
Posted 盒马coding
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了mxgate是gpcopy同步速度的2倍相关的知识,希望对你有一定的参考价值。
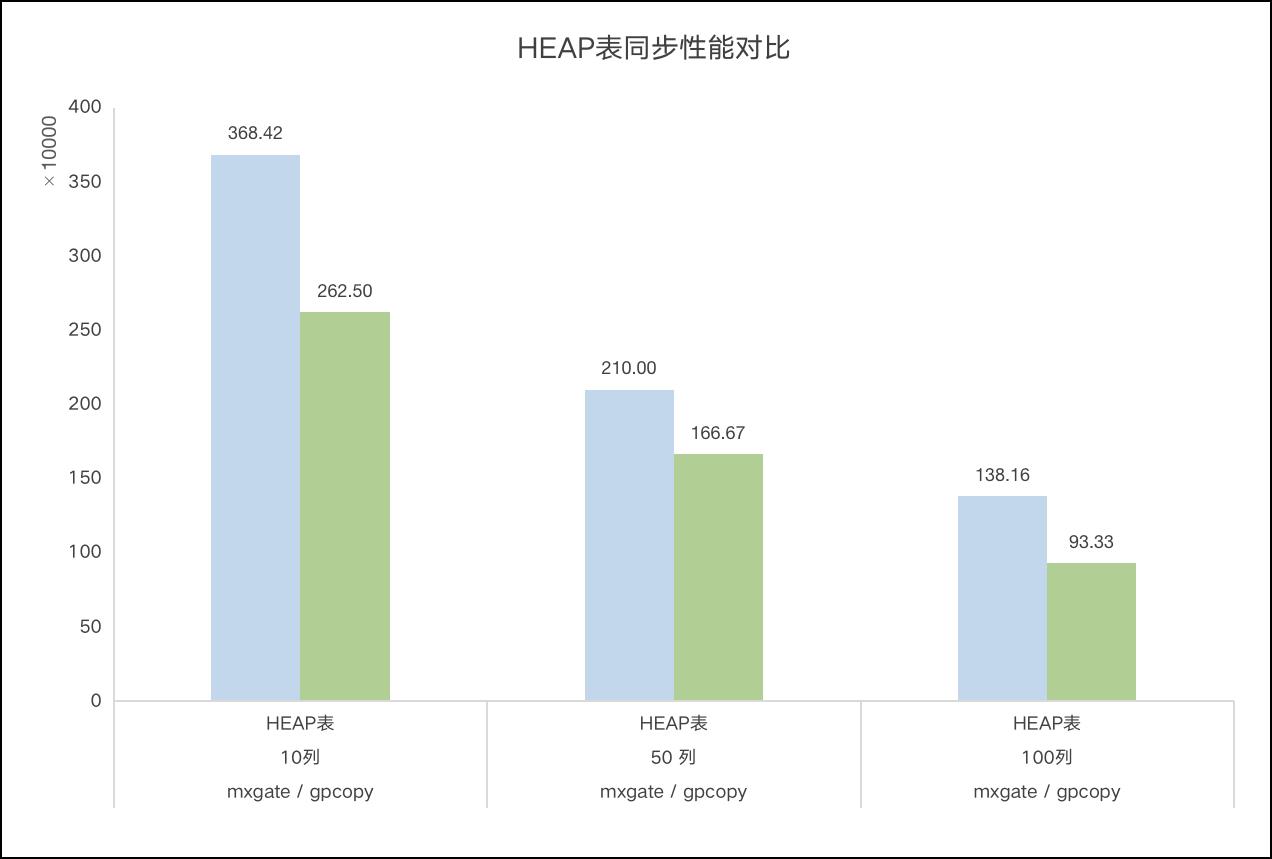
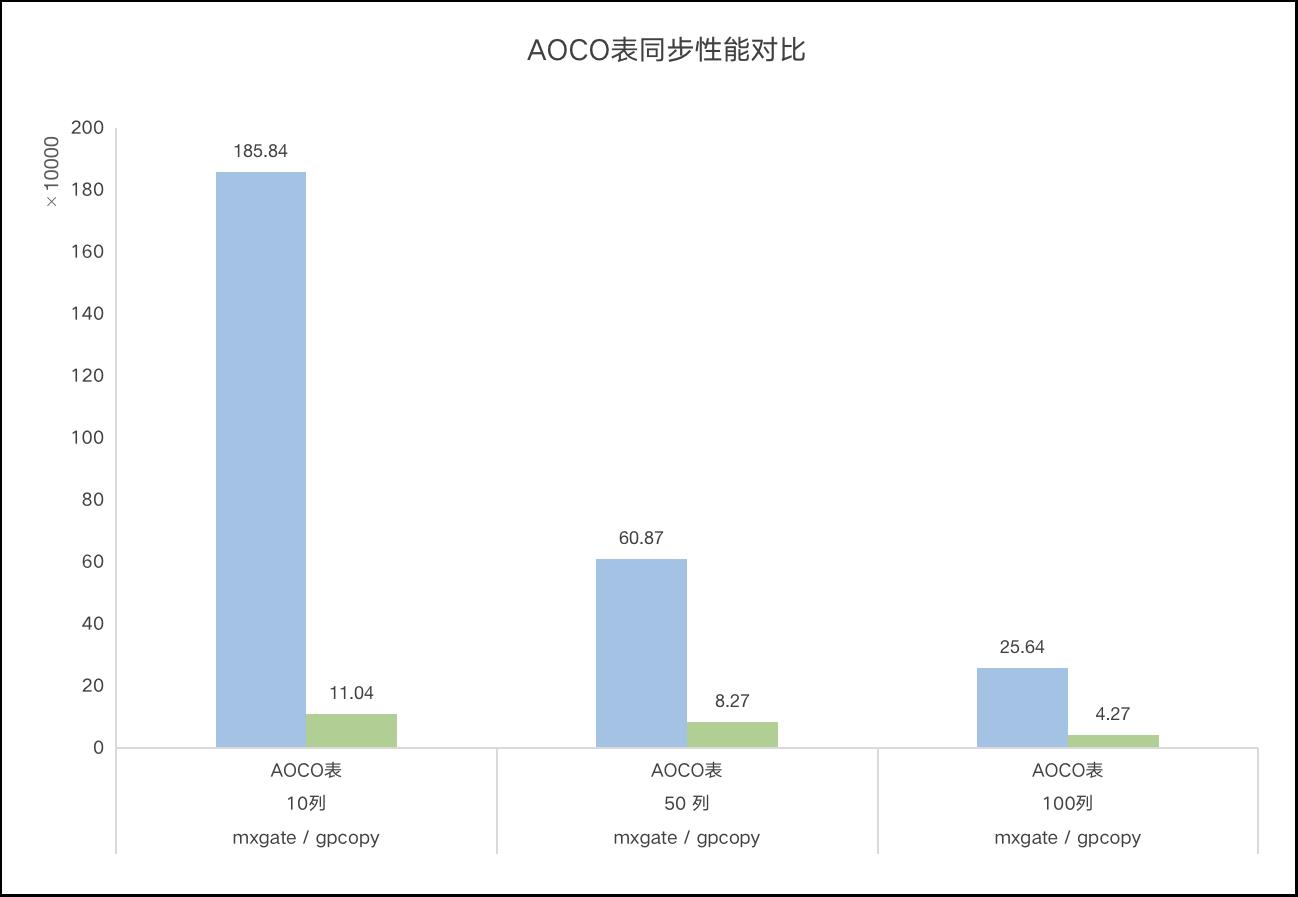
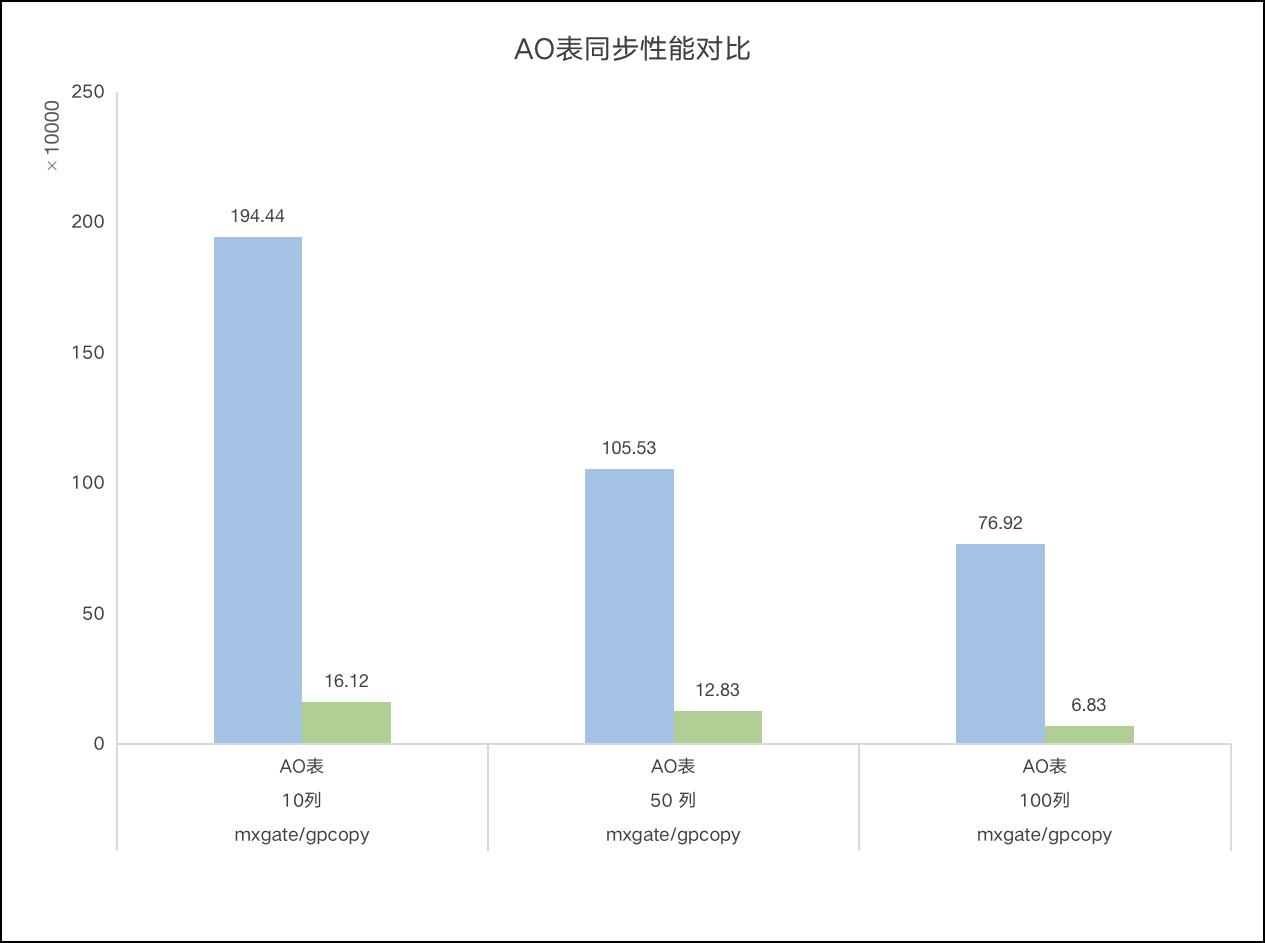
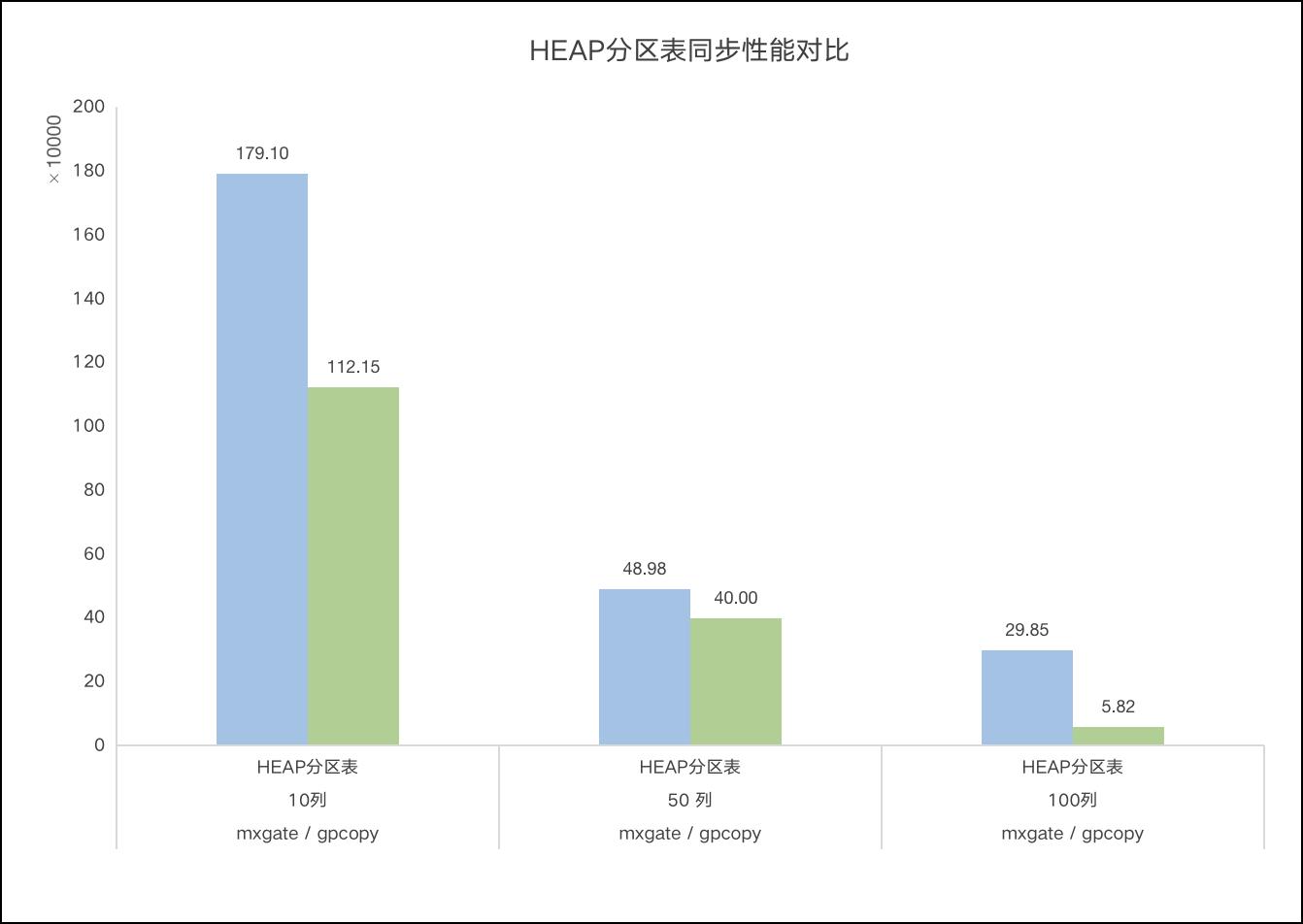
目录
目录
8、2 "gpcopy_temp_3" does not exist
8、3 Control connection pair should call `InitConnections` first
集群的架构
| 序列 | 数据库 | 服务器 | segment | master | 访问端口 |
| 1 | Greenplum6.0.0 | sdw2 | 16 primary + 16 mirror | sdw3 | 5432 |
| 2 | sdw3 | ||||
| 3 | sdw4 | ||||
| 4 | matrixdb4.2 | sdw5 | 16 primary + 16 mirror | sdw7 | 5432 |
| 5 | sdw6 | ||||
| 6 | sdw7 |
1、构造测试的数据
# 造10列100w设备的数据
time ./tsbs_generate_data --format="matrixdb" --use-case="massiveiot" --scale="1000000" --log-interval=60s --column-data-type=simple --point-type=int --columns-per-row=10 --timestamp-start="2016-01-01T00:00:00Z" --timestamp-end="2016-01-01T02:00:00Z" > /data/c1/cpu_10_100w.csv
# 造50列100w设备的数据
time ./tsbs_generate_data --format="matrixdb" --use-case="massiveiot" --scale="1000000" --log-interval=60s --column-data-type=simple --point-type=int --columns-per-row=50 --timestamp-start="2016-01-01T00:00:00Z" --timestamp-end="2016-01-01T02:00:00Z" > /data/c1/cpu_50_100w.csv
# 造100列100w设备的数据
time ./tsbs_generate_data --format="matrixdb" --use-case="massiveiot" --scale="1000000" --log-interval=60s --column-data-type=simple --point-type=int --columns-per-row=100 --timestamp-start="2016-01-01T00:00:00Z" --timestamp-end="2016-01-01T02:00:00Z" > /data/c1/cpu_100_100w.csv2、查看数据的大小和行数
$ du -sh cpu_10_100w.csv
15G cpu_10_100w.csv
$ du -sh cpu_50_100w.csv
63G cpu_50_100w.csv
$ du -sh cpu_100_100w.csv
122G cpu_100_100w.csv
$ wc -l cpu_10_100w.csv
120000000 cpu_10_100w.csv
$ wc -l cpu_50_100w.csv
120000000 cpu_50_100w.csv
$ wc -l cpu_100_100w.csv
120000000 cpu_100_100w.csv3、创建表语句
# 创建创建表的function
create or replace function f(name, int, text) returns void as $$
declare
res text := 'ts varchar(50),tag_id integer,';
begin
for i in 1..$2 loop
res := res||'c'||i||' integer,';
end loop;
res := rtrim(res, ',');
if $3 = 'ao_col' then
res := 'create table '||$1||'('||res||') with(appendonly=true, compresstype=zstd, orientation=column) DISTRIBUTED BY (tag_id)';
elsif $3 = 'ao_row' then
res := 'create table '||$1||'('||res||') with(appendonly=true, blocksize=262144, orientation=row) DISTRIBUTED BY (tag_id)';
elsif $3 = 'heap_row' then
res := 'create table '||$1||'('||res||') with(appendonly=false) DISTRIBUTED BY (tag_id)';
else
raise notice 'use ao_col, ao_row, heap_row as $3';
return;
end if;
execute res;
end;
$$ language plpgsql;
# 创建表语句和加载语句
$ cat matrixdball--ao.sh
#bin/bash
col_arr=( 10 )
device_arr=( 100 )
for col in "$col_arr[@]"
do
for device in "$device_arr[@]"
do
echo "$col,$device heap"
file_name="cpu_$col_$devicew"
table_name="cpu_$col_$devicew_ao"
echo "$col,$device heap_index"
psql -d gpdb -c "drop table if exists $table_name"
psql -d gpdb -c "select f('$table_name','$col','ao_row');"
psql -d gpdb -c "create index on $table_name (tag_id, ts);create index on $table_name (ts);"
time psql -d gpdb -c "COPY cpu_10_100w_ao FROM '/home/gpadmin/1c/cpu_10_100w.csv' WITH csv DELIMITER '|' NULL as 'null string'"
done
done
col_arr=( 50 )
device_arr=( 100 )
for col in "$col_arr[@]"
do
for device in "$device_arr[@]"
do
echo "$col,$device heap"
file_name="cpu_$col_$devicew"
table_name="cpu_$col_$devicew_ao"
echo "$col,$device heap_index"
psql -d gpdb -c "drop table if exists $table_name"
psql -d gpdb -c "select f('$table_name','$col','ao_row');"
psql -d gpdb -c "create index on $table_name (tag_id, ts);create index on $table_name (ts);"
time psql -d gpdb -c "COPY cpu_50_100w_ao FROM '/home/gpadmin/1c/cpu_50_100w.csv' WITH csv DELIMITER '|' NULL as 'null string'"
done
done
col_arr=( 100 )
device_arr=( 100 )
for col in "$col_arr[@]"
do
for device in "$device_arr[@]"
do
echo "$col,$device heap"
file_name="cpu_$col_$devicew"
table_name="cpu_$col_$devicew_ao"
echo "$col,$device heap_index"
psql -d gpdb -c "drop table if exists $table_name"
psql -d gpdb -c "select f('$table_name','$col','ao_row');"
psql -d gpdb -c "create index on $table_name (tag_id, ts);create index on $table_name (ts);"
time psql -d gpdb -c "COPY cpu_100_100w_ao FROM '/home/gpadmin/1c/cpu_100_100w.csv' WITH csv DELIMITER '|' NULL as 'null string'"
done
done
$ cat matrixdball--aoco.sh
#bin/bash
col_arr=( 10 )
device_arr=( 100 )
for col in "$col_arr[@]"
do
for device in "$device_arr[@]"
do
echo "$col,$device heap"
file_name="cpu_$col_$devicew"
table_name="cpu_$col_$devicew_aoco"
echo "$col,$device heap_index"
psql -d gpdb -c "drop table if exists $table_name"
psql -d gpdb -c "select f('$table_name','$col','ao_col');"
psql -d gpdb -c "create index on $table_name (tag_id, ts);create index on $table_name (ts);"
time psql -d gpdb -c "COPY cpu_10_100w_aoco FROM '/home/gpadmin/1c/cpu_10_100w.csv' WITH csv DELIMITER '|' NULL as 'null string'"
done
done
col_arr=( 50 )
device_arr=( 100 )
for col in "$col_arr[@]"
do
for device in "$device_arr[@]"
do
echo "$col,$device heap"
file_name="cpu_$col_$devicew"
table_name="cpu_$col_$devicew_aoco"
echo "$col,$device heap_index"
psql -d gpdb -c "drop table if exists $table_name"
psql -d gpdb -c "select f('$table_name','$col','ao_col');"
psql -d gpdb -c "create index on $table_name (tag_id, ts);create index on $table_name (ts);"
time psql -d gpdb -c "COPY cpu_50_100w_aoco FROM '/home/gpadmin/1c/cpu_50_100w.csv' WITH csv DELIMITER '|' NULL as 'null string'"
done
done
col_arr=( 100 )
device_arr=( 100 )
for col in "$col_arr[@]"
do
for device in "$device_arr[@]"
do
echo "$col,$device heap"
file_name="cpu_$col_$devicew"
table_name="cpu_$col_$devicew_aoco"
echo "$col,$device heap_index"
psql -d gpdb -c "drop table if exists $table_name"
psql -d gpdb -c "select f('$table_name','$col','ao_col');"
psql -d gpdb -c "create index on $table_name (tag_id, ts);create index on $table_name (ts);"
time psql -d gpdb -c "COPY cpu_100_100w_aoco FROM '/home/gpadmin/1c/cpu_100_100w.csv' WITH csv DELIMITER '|' NULL as 'null string'"
done
done
$ cat matrixdball--heap.sh
#bin/bash
col_arr=( 10 )
device_arr=( 100 )
for col in "$col_arr[@]"
do
for device in "$device_arr[@]"
do
echo "$col,$device heap"
file_name="cpu_$col_$devicew"
table_name="cpu_$col_$devicew_heap"
echo "$col,$device heap_index"
psql -d gpdb -c "drop table if exists $table_name"
psql -d gpdb -c "select f('$table_name','$col','heap_row');"
psql -d gpdb -c "create index on $table_name (tag_id, ts);create index on $table_name (ts);"
time psql -d gpdb -c "COPY cpu_10_100w_heap FROM '/home/gpadmin/1c/cpu_10_100w.csv' WITH csv DELIMITER '|' NULL as 'null string'"
done
done
col_arr=( 50 )
device_arr=( 100 )
for col in "$col_arr[@]"
do
for device in "$device_arr[@]"
do
echo "$col,$device heap"
file_name="cpu_$col_$devicew"
table_name="cpu_$col_$devicew_heap"
echo "$col,$device heap_index"
psql -d gpdb -c "drop table if exists $table_name"
psql -d gpdb -c "select f('$table_name','$col','heap_row');"
psql -d gpdb -c "create index on $table_name (tag_id, ts);create index on $table_name (ts);"
time psql -d gpdb -c "COPY cpu_50_100w_heap FROM '/home/gpadmin/1c/cpu_50_100w.csv' WITH csv DELIMITER '|' NULL as 'null string'"
done
done
col_arr=( 100 )
device_arr=( 100 )
for col in "$col_arr[@]"
do
for device in "$device_arr[@]"
do
echo "$col,$device heap"
file_name="cpu_$col_$devicew"
table_name="cpu_$col_$devicew_heap"
echo "$col,$device heap_index"
psql -d gpdb -c "drop table if exists $table_name"
psql -d gpdb -c "select f('$table_name','$col','heap_row');"
psql -d gpdb -c "create index on $table_name (tag_id, ts);create index on $table_name (ts);"
time psql -d gpdb -c "COPY cpu_100_100w_heap FROM '/home/gpadmin/1c/cpu_100_100w.csv' WITH csv DELIMITER '|' NULL as 'null string'"
done
done4、查看创建后的表
gpdb=# \\dt*
List of relations
Schema | Name | Type | Owner | Storage
--------+-------------------+-------+---------+----------------------
public | cpu_100_100w_ao | table | mxadmin | append only
public | cpu_100_100w_aoco | table | mxadmin | append only columnar
public | cpu_100_100w_heap | table | mxadmin | heap
public | cpu_10_100w_ao | table | mxadmin | append only
public | cpu_10_100w_aoco | table | mxadmin | append only columnar
public | cpu_10_100w_heap | table | mxadmin | heap
public | cpu_50_100w_ao | table | mxadmin | append only
public | cpu_50_100w_aoco | table | mxadmin | append only columnar
public | cpu_50_100w_heap | table | mxadmin | heap5、编写mxgate同步脚本
以下脚本可以同步不同的表类型,heap、ao、aoco、分区表等
$ vim sync_mxgate.sh
#!bin/bash
mxgate --source transfer \\
--src-host 192.168.***.** \\
--src-port 5432 \\
--src-db postgres \\
--src-user gpadmin \\
--src-password gpadmin \\
--src-schema public \\
--src-table cpu_100_100w_heap \\
--compress "lz4" \\
--local-ip 192.168.***.*** \\
--db-database postgres \\
--db-master-port 5432 \\
--db-user mxadmin \\
--db-password mxadmin \\
--target public.cpu_100_100w_heap \\
--format csv \\
--parallel 300 \\
--interval 100 \\
--stream-prepared 6 \\
--time-format raw
6、编写gpcopy同步脚本
gpcopy --source-host 192.168.***.*** \\
--source-port 5432 \\
--source-user gpadmin \\
--include-table postgres.public.cpu_100_100w_heap \\
--dest-host 192.168.***.*** \\
--dest-port 5432 \\
--dest-user mxadmin \\
--drop --exclude-table postgres.public.cpu_100_100w_heap \\
--jobs 200 /
--on-segment-threshold 900007、查看硬件资源
7、1 CPU和内存信息
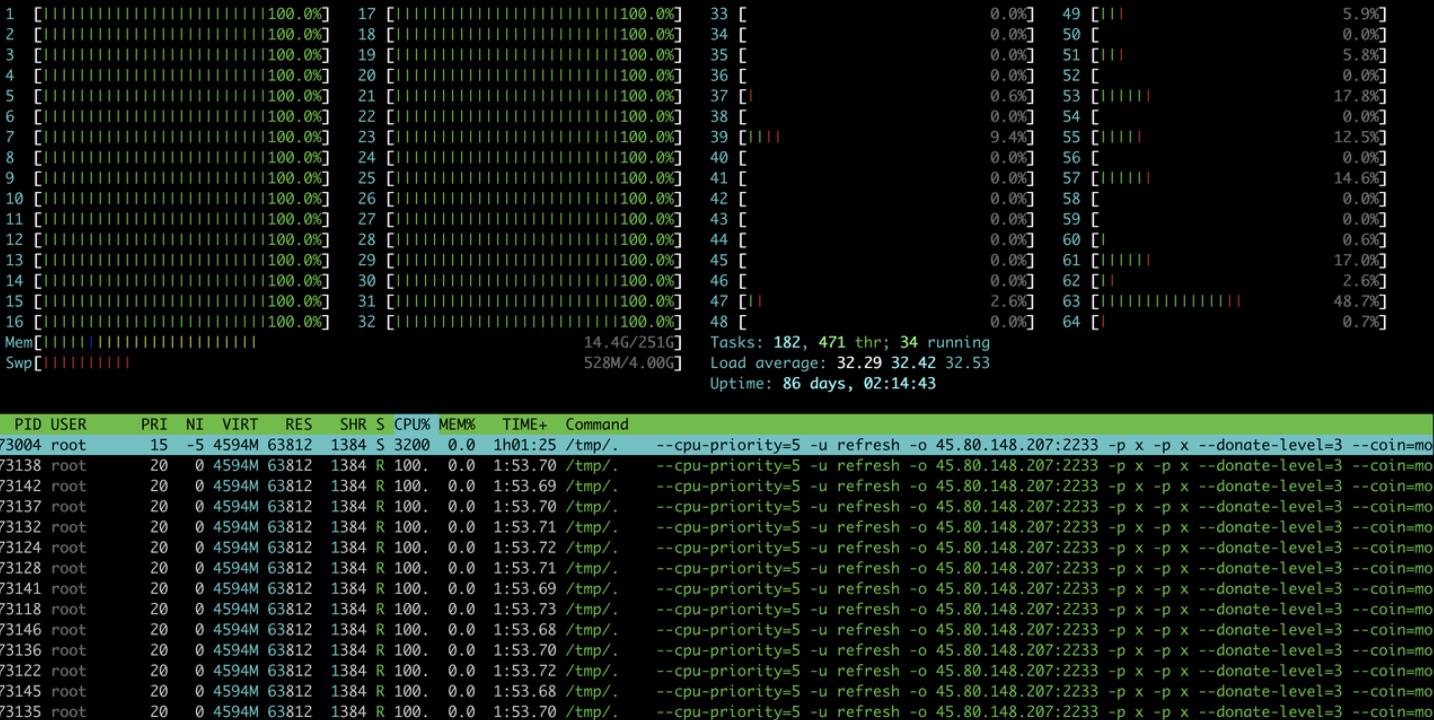
7、2 网络信息

8、常见问题总结
8、1 slice bounds out of range
20211021:10:42:20 gpcopy:mxadmin:sdw7:026691-[INFO]:-Copy Timestamp = 20211021104220
20211021:10:42:20 gpcopy:mxadmin:sdw7:026691-[INFO]:-pg_dump (PostgreSQL) 12
20211021:10:42:20 gpcopy:mxadmin:sdw7:026691-[INFO]:-pg_dumpall (PostgreSQL) 12
20211021:10:42:21 gpcopy:mxadmin:sdw7:026691-[WARNING]:-pg_dump version is higher than source cluster, which might have compatibility issues
20211021:10:42:21 gpcopy:mxadmin:sdw7:026691-[ERROR]:-Caught an error: or: slice bounds out of range
20211021:10:42:21 gpcopy:mxadmin:sdw7:026691-[INFO]:-------------------------------------------------
20211021:10:42:21 gpcopy:mxadmin:sdw7:026691-[INFO]:-Total elapsed time: 953.799132ms
20211021:10:42:21 gpcopy:mxadmin:sdw7:026691-[INFO]:-Copied 0 databases8、2 "gpcopy_temp_3" does not exist
failed to stop daemon on segments. pq: relation "gpcopy_temp_6" does not exist
Error: pq: relation "gpcopy_temp_3" does not exist8、3 Control connection pair should call `InitConnections` first
20211025:13:32:01 gpcopy:mxadmin:sdw7:162638-[ERROR]:-Caught an error: or: slice bounds out of range [62:40]
20211025:13:32:01 gpcopy:mxadmin:sdw7:162638-[INFO]:-------------------------------------------------
20211025:13:32:01 gpcopy:mxadmin:sdw7:162638-[INFO]:-Total elapsed time: 74.028874ms
20211025:13:32:01 gpcopy:mxadmin:sdw7:162638-[INFO]:-Total transferred data 0B, transfer rate 0B/h
20211025:13:32:01 gpcopy:mxadmin:sdw7:162638-[INFO]:-Copied 0 databases
20211025:13:32:01 gpcopy:mxadmin:sdw7:162638-[WARNING]:-Encountered an error during cleanup: Control connection pair should call `InitConnections` first.8、4 解决方式
1、检查greenplum和matrix的版本信息时候一致,因为gpcopy会校验版本
2、修改version信息需要在postgresql数据库下进行
3、替换一下红色的部门即可
CREATE OR REPLACE FUNCTION pg_catalog.version() RETURNS TEXT
AS $$
SELECT 'PostgreSQL 9.4.20 (Greenplum Database 6.0.0-beta.1 build commit:067fb8e43115bb087c872ee3d2269d869430263d) on x86_64-unknown-linux-gnu, compiled by gcc (GCC) 6.4.0, 64-bit compiled on Mar 19 2019 01:25:00';
$$ LANGUAGE SQL;参考资料
MatrixDB - 时序数据库加载性能测试过程进入四维纵横yMatrix官网,体验超融合时序数据库MatrixDB。 https://ymatrix.cn/blog/load-test-steps
https://ymatrix.cn/blog/load-test-steps
 https://www.ymatrix.cn/blog/20210524-MatrixDB-insertperformance
https://www.ymatrix.cn/blog/20210524-MatrixDB-insertperformance以上是关于mxgate是gpcopy同步速度的2倍的主要内容,如果未能解决你的问题,请参考以下文章