C++ C++实战笔记
Posted baiiu
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了C++ C++实战笔记相关的知识,希望对你有一定的参考价值。
前言
本文整理C++实战笔记,是极客时间罗剑锋老师的C++实战笔记笔记,希望大家购买原版,本文如有侵权立删。
- google c++ code style
https://zh-google-styleguide.readthedocs.io/en/latest/google-cpp-styleguide/
C++语言的编程范式
“编程范式”是一种“方法论”,就是指导你编写代码的一些思路、规则、习惯、定式和常用语。
C++是一种多范式的编程语言。具体来说,现代C++(11/14以后)支持“面向过程”“面向对象”“泛型”“模板元”“函数式”这五种主要的编程范式。
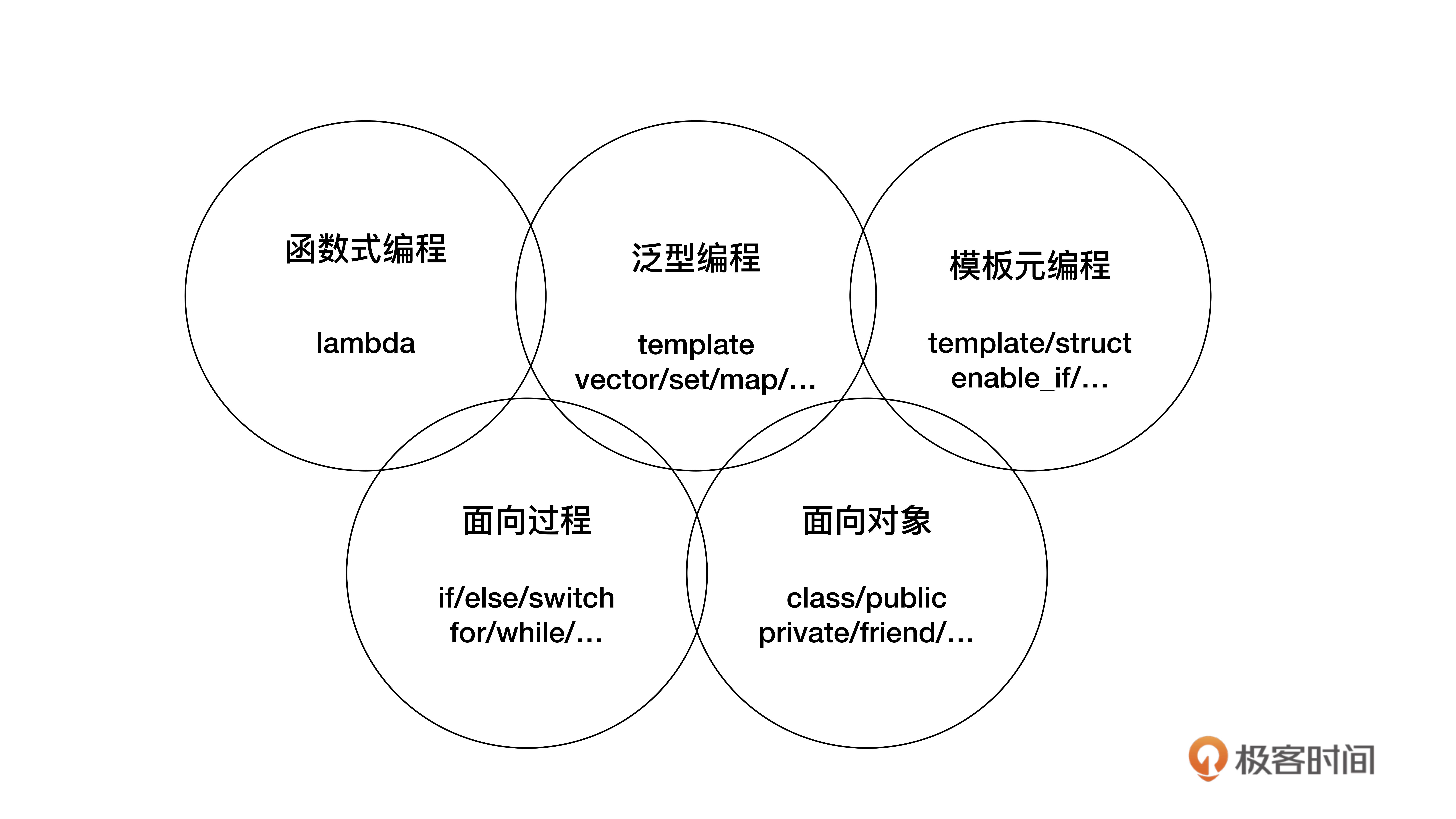
-
面向过程是C++里最基本的一种编程范式。它的核心思想是“命令”,通常就是顺序执行的语句、子程序(函数),把任务分解成若干个步骤去执行,最终达成目标。
-
面向对象是C++里另一个基本的编程范式。它的核心思想是“抽象”和“封装”,倡导的是把任务分解成一些高内聚低耦合的对象,这些对象互相通信协作来完成任务。它强调对象之间的关系和接口,而不是完成任务的具体步骤。
在C++里,面向对象范式包括class、public、private、virtual、this等类相关的关键字,还有构造函数、析构函数、友元函数等概念。 -
泛型编程是自STL(标准模板库)纳入到C++标准以后才逐渐流行起来的新范式,核心思想是“一切皆为类型”,或者说是“参数化类型”“类型擦除”,使用模板而不是继承的方式来复用代码,所以运行效率更高,代码也更简洁。
在C++里,泛型的基础就是template关键字,然后是庞大而复杂的标准库,里面有各种泛型容器和算法,比如vector、map、sort,等等。 -
模板元编程,这个词听起来好像很新,其实也有十多年的历史了,不过相对于前三个范式来说,确实“资历浅”。它的核心思想是“类型运算”,操作的数据是编译时可见的“类型”,所以也比较特殊,代码只能由编译器执行,而不能被运行时的CPU执行。
模板元编程是一种高级、复杂的技术,C++语言对它的支持也比较少,更多的是以库的方式来使用,比如type_traits、enable_if等。 -
函数式,它几乎和“面向过程”一样古老,但却直到近些年才走入主流编程界的视野。所谓的“函数式”并不是C++里写成函数的子程序,而是数学意义上、无副作用的函数,核心思想是“一切皆可调用”,通过一系列连续或者嵌套的函数调用实现对数据的处理。
函数式直到C++11引入了Lambda表达式,它才真正获得了可与其他范式并驾齐驱的地位。
说得具体一点,就是要认识、理解这些范式的优势和劣势,在程序里适当混用,取长补短才是“王道”。
如果是开发直接面对用户的普通应用(Application),那么你可以再研究一下“泛型”和“函数式”,就基本可以解决90%的开发问题了;如果是开发面向程序员的库(Library),那么你就有必要深入了解“泛型”和“模板元”,优化库的接口和运行效率。
如何写出好的c++代码
编码阶段的code style
- 混用这几种中能够让名字辨识度最高的那些优点,就是四条规则:
变量、函数名和名字空间用snake_case,全局变量加“g_”前缀;
自定义类名用CamelCase,成员函数用snake_case,成员变量加“m_”前缀;
宏和常量应当全大写,单词之间用下划线连接;
尽量不要用下划线作为变量的前缀或者后缀(比如_local、name_),很难识别。
#define MAX_PATH_LEN 256 //常量,全大写
int g_sys_flag; // 全局变量,加g_前缀
namespace linux_sys // 名字空间,全小写
void get_rlimit_core(); // 函数,全小写
class FilePath final // 类名,首字母大写
public:
void set_path(const string& str); // 函数,全小写
private:
string m_path; // 成员变量,m_前缀
int m_level; // 成员变量,m_前缀
;
预处理阶段:宏定义和条件编译
预处理阶段编程的操作目标是“源码”,用各种指令控制预处理器,把源码改造成另一种形式,就像是捏橡皮泥一样。
首先,预处理指令都以符号“#”开头,虽然都在一个源文件里,但它不属于C++语言,它走的是预处理器,不受C++语法规则的约束。
所以,预处理编程也就不用太遵守C++代码的风格。一般来说,预处理指令不应该受C++代码缩进层次的影响,不管是在函数、类里,还是在if、for等语句里,永远是顶格写。
单独的一个“#”也是一个预处理指令,叫“空指令”,可以当作特别的预处理空行。而“#”与后面的指令之间也可以有空格,从而实现缩进,方便排版。
包含文件#include
在写头文件的时候,为了防止代码被重复包含,通常要加上“Include Guard”,也就是用“#ifndef/#define/#endif”来保护整个头文件,
#ifndef _XXX_H_INCLUDED_
#define _XXX_H_INCLUDED_
... // 头文件内容
#endif // _XXX_H_INCLUDED_
宏定义#define/#undef
宏定义是预处理编程里最重要、最核心的指令“#define”,它用来定义一个源码级别的“文本替换”。
使用宏的时候一定要谨慎,时刻记着以简化代码、清晰易懂为目标,不要“滥用”,避免导致源码混乱不堪,降低可读性。
-
首先,因为宏的展开、替换发生在预处理阶段,不涉及函数调用、参数传递、指针寻址,没有任何运行期的效率损失,所以对于一些调用频繁的小代码片段来说,用宏来封装的效果比inline关键字要更好,因为它真的是源码级别的无条件内联。
-
其次,你要知道,宏是没有作用域概念的,永远是全局生效。所以,对于一些用来简化代码、起临时作用的宏,最好是用完后尽快用“#undef”取消定义,避免冲突的风险。像下面这样:
-
使用宏时,关键是要“适当”,自己把握好分寸,不要把宏弄得“满天飞”。
用好“文本替换”的功能,
// nginx中的宏函数
#define ngx_tolower(c) ((c >= 'A' && c <= 'Z') ? (c | 0x20) : c)
#define ngx_toupper(c) ((c >= 'a' && c <= 'z') ? (c & ~0x20) : c)
#define ngx_memzero(buf, n) (void) memset(buf, 0, n)
#define CUBE(a) (a) * (a) * (a) // 定义一个简单的求立方的宏
cout << CUBE(10) << endl; // 使用宏简化代码
cout << CUBE(15) << endl; // 使用宏简化代码
#undef CUBE // 使用完毕后立即取消定义
// 另一种做法是宏定义前先检查,如果之前有定义就先undef,然后再重新定义:
#ifdef AUTH_PWD // 检查是否已经有宏定义
# undef AUTH_PWD // 取消宏定义
#endif // 宏定义检查结束
#define AUTH_PWD "xxx" // 重新宏定义
条件编译 #if/#else/#endif
可以在预处理阶段实现分支处理,通过判断宏的数值来产生不同的源码,改变源文件的形态,这就是“条件编译”。
编译阶段:属性和静态断言
编译是预处理之后的阶段,它的输入是(经过预处理的)C++源码,输出是二进制可执行文件(也可能是汇编文件、动态库或者静态库)。这个处理动作就是由编译器来执行的。
编译阶段的特殊性在于,它看到的都是C++语法实体,比如typedef、using、template、struct/class这些关键字定义的类型,而不是运行阶段的变量。
所以,这时的编程思维方式与平常大不相同。
属性
可以把它理解为给变量、函数、类等“贴”上一个编译阶段的“标签”,方便编译器识别处理;
“属性”相当于编译阶段的“标签”,用来标记变量、函数或者类,让编译器发出或者不发出警告;
“属性”是用两对方括号的形式“[[…]]”,方括号的中间就是属性标签。
[[noreturn]] // 属性标签,表示这个函数没有返回值
int func(bool flag)
throw std::runtime_error("XXX");
[[deprecated("deadline:2020-12-31")]] // C++14 or later,表示这个函数已过期
int old_func();
[[gnu::unused]] // 声明下面的变量暂不使用,不是错误
int nouse;
- 好在“属性”也支持非标准扩展,允许以类似名字空间的方式使用编译器自己的一些“非官方”属性。GCC的部分常用属性如下:
deprecated:与C++14相同,但可以用在C++11里。
unused:用于变量、类型、函数等,表示虽然暂时不用,但最好保留着,因为将来可能会用。
constructor:函数会在main()函数之前执行,效果有点像是全局对象的构造函数。
destructor:函数会在main()函数结束之后执行,有点像是全局对象的析构函数。
always_inline:要求编译器强制内联函数,作用比inline关键字更强。
hot:标记“热点”函数,要求编译器更积极地优化。
静态断言
- 动态断言:
assert用来断言一个表达式必定为真。当程序(也就是CPU)运行到assert语句时,就会计算表达式的值,如果是false,就会输出错误消息,然后调用abort()终止程序的执行。
assert虽然是一个宏,但在预处理阶段不生效,而是在运行阶段才起作用,所以又叫“动态断言”。
assert(i > 0 && "i must be greater than zero");
assert(p != nullptr);
assert(!str.empty());
- 静态断言:
叫“static_assert”,不过它是一个专门的关键字,而不是宏。因为它只在编译时生效,运行阶段看不见,所以是“静态”的。
它是在编译阶段计算常数和类型,如果断言失败就会导致编译错误;编译器看到static_assert也会计算表达式的值,如果值是false,就会报错,导致编译失败。
static_assert运行在编译阶段,只能看到编译时的常数和类型,看不到运行时的变量、指针、内存数据等,是“静态”的,所以不要简单地把assert的习惯搬过来用。
// 保证程序在64位系统上运行,使用静态断言在编译阶段检查long的大小
static_assert(sizeof(long) >= 8, "must run on x64");
// 下面的代码想检查空指针,由于变量只能在运行阶段出现,而在编译阶段不存在,所以静态断言无法处理。
char* p = nullptr;
static_assert(p == nullptr, "some error."); // 错误用法
面向对象编程
C++里类的四大函数:它们是构造函数、析构函数、拷贝构造函数、拷贝赋值函数。
C++11因为引入了右值(Rvalue)和转移(Move、移动),又多出了两大函数:转移构造函数和转移赋值函数。所以,在现代C++里,一个类总是会有六大基本函数:三个构造、两个赋值、一个析构。
-
= default
对于比较重要的构造函数和析构函数,应该用“= default”的形式,明确地告诉编译器(和代码阅读者):“应该实现这个函数,但我不想自己写。”这样编译器就得到了明确的指示,可以做更好的优化。 -
= delete
这种“= default”是C++11新增的专门用于六大基本函数的用法,相似的,还有一种“= delete”的形式。它表示明确地禁用某个函数形式,而且不限于构造/析构,可以用于任何函数(成员函数、自由函数),让外界无法调用。 -
explicit
因为C++有隐式构造和隐式转型的规则,如果你的类里有单参数的构造函数,或者是转型操作符函数,为了防止意外的类型转换,保证安全,就要使用“explicit”将这些函数标记为“显式”。 -
成员变量初始化(In-class member initializer)
可以在类里声明变量的同时给它赋值,实现初始化,这样不但简单清晰,也消除了隐患。 -
使用using或typedef可以为类型起别名,既能够简化代码,还能够适应将来的变化。
类型别名不仅能够让代码规范整齐,而且因为引入了这个“语法层面的宏定义”,将来在维护时还可以随意改换成其他的类型。比如,把字符串改成string_view(C++17里的字符串只读视图),把集合类型改成unordered_set,只要变动别名定义就行了,原代码不需要做任何改动。 -
传统的编写方式是
.h头文件加上.cpp,声明与实现分离。
但是更推荐在一个.hpp里实现类的全部功能,这样更现代。很多著名的开源现代c++项目全面采用了hpp的方式。
// 使用final避免被继承
class DemoClass final
private:
int a = 0; // 整数成员,赋值初始化
string s = "hello"; // 字符串成员,赋值初始化
vector v1,2,3; // 容器成员,使用初始化列表
public:
DemoClass() = default; // 明确告诉编译器,使用默认实现
~DemoClass() = default; // 明确告诉编译器,使用默认实现
DemoClass(const DemoClass&) = delete; // 禁止拷贝构造
DemoClass& operator=(const DemoClass&) = delete; // 禁止拷贝赋值
explicit DemoClass(const string_type& str) // 显式单参构造函数
explicit operator bool() // 显式转型为bool
DemoClass(int x) : a(x) // 可以单独出似乎还成员,其它使用默认值
using uint_t = unsigned int; // using别名
typedef unsigned int uint_t; // 等价的typedef
using this_type = DemoClass; // 给自己起个别名
using string_type = std::string; // 字符串类型别名
using uint32_type = uint32_t; // 整数类型别名
using set_type = std::set; // 集合类型别名,方便以后替换成unordered_set;
using vector_type = std::vector;// 容器类型别名
;
C++语言特性
自动类型推到auto、decltype
auto
除了简化代码,auto还避免了对类型的“硬编码”,也就是说变量类型不是“写死”的,而是能够“自动”适应表达式的类型。比如,你把map改为unordered_map,那么后面的代码都不用动。这个效果和类型别名有点像,但你不需要写出typedef或者using,全由auto“代劳”。
“自动类型推导”实际上和“attribute”一样,是编译阶段的特殊指令,指示编译器去计算类型。
-
auto的“自动推导”能力只能用在“初始化”的场合。
具体来说,就是赋值初始化或者花括号初始化(初始化列表、Initializer list),变量右边必须要有一个表达式(简单、复杂都可以)。这样你才能在左边放上auto,编译器才能找到表达式,帮你自动计算类型。 -
auto总是推导出“值类型”,绝不会是“引用”;
-
auto可以附加上const、volatile、*、&这样的类型修饰符,得到新的类型。
auto str = "hello"; // 自动推导为const char [6]类型,需要手动写std::string;
std::map m = 1,"a", 2,"b"; // 自动推导不出来,需要手动声明std::map<int,string>
auto iter = m.begin(); // 自动推导为map内部的迭代器类型,代码简洁很多
auto x = 10L; // auto推导为long,x是long
auto& x1 = x; // auto推导为long,x1是long&
auto* x2 = &x; // auto推导为long,x2是long*
const auto& x3 = x; // auto推导为long,x3是const long&
auto x4 = &x3; // auto推导为const long*,x4是const long*
vector v = 2,3,5,7,11; // vector顺序容器
for(const auto& i : v) // 常引用方式访问元素,避免拷贝代价
cout << i << ","; // 常引用不会改变元素的值
for(auto& i : v) // 引用方式访问元素
i++; // 可以改变元素的值
cout << i << ",";
decltype
decltype的形式很像函数,后面的圆括号里就是可用于计算类型的表达式(和sizeof有点类似),其他方面就和auto一样了,也能加上const、*、&来修饰。
decltype不仅能够推导出值类型,还能够推导出引用类型,也就是表达式的“原始类型”。
int x = 0; // 整型变量
decltype(x) x1; // 推导为int,x1是int
decltype(x)& x2 = x; // 推导为int,x2是int&,引用必须赋值
decltype(x)* x3; // 推导为int,x3是int*
decltype(&x) x4; // 推导为int*,x4是int*
decltype(&x)* x5; // 推导为int*,x5是int**
decltype(x2) x6 = x2; // 推导为int&,x6是int&,引用必须赋值
- 实际上,它也有个缺点,就是写起来略麻烦,特别在用于初始化的时候,表达式要重复两次(左边的类型计算,右边的初始化),把简化代码的优势完全给抵消了。
所以,C++14就又增加了一个“decltype(auto)”的形式,既可以精确推导类型,又能像auto一样方便使用。
int x = 0; // 整型变量
decltype(auto) x1 = (x); // 推导为int&,因为(expr)是引用类型
decltype(auto) x2 = &x; // 推导为int*
decltype(auto) x3 = x1; // 推导为int&
- 在定义类的时候,因为auto被禁用了,所以这也是decltype可以“显身手”的地方。它可以搭配别名任意定义类型,再应用到成员变量、成员函数上,变通地实现auto的功能。
class DemoClass final
public:
using set_type = std::set; // 集合类型别名
private:
set_type m_set; // 使用别名定义成员变量
// 使用decltype计算表达式的类型,定义别名
using iter_type = decltype(m_set.begin());
iter_type m_pos; // 类型别名定义成员变量
;
const、volatile、mutable
-
const和宏定义的区别:
const定义的常量在预处理阶段并不存在,而是直到运行阶段才会出现。
即const修饰的实际上是运行时的“变量”,只不过不允许修改,是“只读”的(read only),叫“只读变量”更合适。 -
const修饰指针,
const int *p,即常量指针,指针的指向不可改,即指向一个只读变量;
const也可以修饰引用,const int& rx = x;即常量引用;const &可以引用任何类型,被称为万能引用; -
在设计函数的时候,建议尽可能地使用它作为入口参数,一来保证效率,二来保证安全。
-
const成员函数
表示该函数的执行过程中不会修改类中的成员变量, -
可以使用指针强制修改const值,但需要加上volatile,避免编译器优化
不添加volatile的话,编译期会将引用该常量的值直接替换成原始值;添加volatile后,禁止编译器对该值进行优化,必须在运行时去读取该值。
// 需要加上volatile修饰,运行时才能看到效果
const volatile int MAX_LEN = 1024;
auto ptr = (int*)(&MAX_LEN);
*ptr = 2048;
cout << MAX_LEN << endl; // 输出2048
int x = 100;
const int& rx = x; // const修饰引用
const int* px = &x; // const修饰指针
class DemoClass final
private:
const long MAX_SIZE = 256; // const成员变量
int m_value; // 成员变量
mutable mutex_type m_mutex;
public:
int get_value() const // const成员函数,不能修改非mutable成员变量
// m_mutex,可以操作mutable修饰的成员变量
return m_value;
;


智能指针
-
学会使用智能指针,避免再使用裸指针、new和delete来操作内存了。
-
如果指针是“独占”使用,就应该选择unique_ptr,它为裸指针添加了很多限制,更加安全。
如果指针是“共享”使用,就应该选择shared_ptr,它的功能非常完善,用法几乎与原始指针一样。
应当使用工厂函数make_unique()、make_shared()来创建智能指针,强制初始化,而且还能使用auto来简化声明。
shared_ptr有少量的管理成本,也会引发一些难以排查的错误,所以不要过度使用。 -
智能指针是代理模式的具体应用,它完全实践了RAII惯用法,把裸指针包装起来,在构造函数里初始化,在析构函数里释放。这样当对象失效销毁时,C++就会自动调用析构函数,完成内存释放、资源回收等清理工作。而且它还重载了*和->操作符,用起来和原始指针一模一样。
-
智能指针实际上并不是指针,而是一个对象。
所以,不要企图对它调用delete,它会自动管理初始化时的指针,在离开作用域时析构释放内存。 -
智能指针也没有定义加减运算,不能随意移动指针地址,这就完全避免了指针越界等危险操作,可以让代码更安全
unique_ptr
- unique_ptr表示指针的所有权是“唯一”的,不允许共享,任何时候只能有一个“人”持有它。
unique_ptr禁止了拷贝赋值,所以在向另一个unique_ptr赋值的时候,必须用std::move()函数显式地声明所有权转移。
unique_ptr ptr1(new int(10)); // int智能指针
assert(*ptr1 == 10); // 可以使用*取内容
assert(ptr1 != nullptr); // 可以判断是否为空指针
unique_ptr ptr2(new string("hello")); // string智能指针
assert(*ptr2 == "hello"); // 可以使用*取内容
assert(ptr2->size() == 5); // 可以使用->调用成员函数
auto ptr3 = make_unique(42); // 工厂函数创建智能指针
assert(ptr3 && *ptr3 == 42);
auto ptr4 = make_unique("god of war"); // 工厂函数创建智能指针
assert(!ptr4->empty());
template // 可变参数模板
std::unique_ptr // 返回智能指针
my_make_unique(Args&&... args) // 可变参数模板的入口参数
return std::unique_ptr( // 构造智能指针
new T(std::forward(args)...)); // 完美转发
auto ptr1 = make_unique(42); // 工厂函数创建智能指针
assert(ptr1 && *ptr1 == 42); // 此时智能指针有效
auto ptr2 = std::move(ptr1); // 使用move()转移所有权
assert(!ptr1 && ptr2); // ptr1变成了空指针
share_ptr
-
shared_ptr所有权是可以被安全共享的,支持拷贝赋值,允许被多个“人”同时持有,就像原始指针一样。
-
shared_ptr支持安全共享的秘密在于内部使用了“引用计数”。
引用计数最开始的时候是1,表示只有一个持有者。如果发生拷贝赋值——也就是共享的时候,引用计数就增加,而发生析构销毁的时候,引用计数就减少。
只有当引用计数减少到0,也就是说,没有任何人使用这个指针的时候,它才会真正调用delete释放内存。 -
使用shared_ptr也是有代价的,引用计数的存储和管理都是成本,这方面是shared_ptr不如unique_ptr的地方。
如果不考虑应用场合,过度使用shared_ptr就会降低运行效率。不过,你也不需要太担心,shared_ptr内部有很好的优化,在非极端情况下,它的开销都很小。 -
析构函数里不要有非常复杂、严重阻塞的操作。
因为在运行阶段,引用计数的变动是很复杂的,很难知道它真正释放资源的时机,无法像Java、Go那样明确掌控、调整垃圾回收机制。一旦shared_ptr在某个不确定时间点析构释放资源,就会阻塞整个进程或者线程,stop the world。
shared_ptr ptr1(new int(10)); // int智能指针
assert(*ptr1 = 10); // 可以使用*取内容
shared_ptr ptr2(new string("hello")); // string智能指针
assert(*ptr2 == "hello"); // 可以使用*取内容
auto ptr3 = make_shared(42); // 工厂函数创建智能指针
assert(ptr3 && *ptr3 == 42); // 可以判断是否为空指针
auto ptr4 = make_shared("zelda"); // 工厂函数创建智能指针
assert(!ptr4->empty()); // 可以使用->调用成员函数
auto ptr1 = make_shared(42); // 工厂函数创建智能指针
assert(ptr1 && ptr1.unique() ); // 此时智能指针有效且唯一
auto ptr2 = ptr1; // 直接拷贝赋值,不需要使用move()
assert(ptr1 && ptr2); // 此时两个智能指针均有效
assert(ptr1 == ptr2); // shared_ptr可以直接比较
// 两个智能指针均不唯一,且引用计数为2
assert(!ptr1.unique() && ptr1.use_count() == 2);
assert(!ptr2.unique() && ptr2.use_count() == 2);
auto ptr_demo = make_shared以上是关于C++ C++实战笔记的主要内容,如果未能解决你的问题,请参考以下文章