Scrapy学习第五课
Posted helenandyoyo
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Scrapy学习第五课相关的知识,希望对你有一定的参考价值。
python爬虫框架scrapy学习第五课
任务:爬取简书30日热门文章信息,数据存储在MongoDB库中

执行:爬虫操作及数据存储
安装mongdb
-
下载mongodb安装包。由于尝试官网下载一直失败,故从该mongodb下载链接 处下载安装包。
-
参照mongoDB入门与安装进行安装。这里需要注意的是msi文件安装完成后,自带data文件夹,因此不需要额外新建数据存放目录。

-
以管理员身份启动mongodb服务。注意执行net start mongodb一定是在管理员身份下运行cmd/powershell,否则会出现没有访问权限/访问被拒绝的错误。
python 连接mongodb驱动PyMongo
- 安装PyMongo需执行如下命令
pip install pymongo
- 在python文件需要连接mongodb处,导入
import pymongo
爬虫实例
- 具体爬虫文件——jian.py
# -*- coding: utf-8 -*-
import scrapy
from JianShu.items import JianshuItem
class JianSpider(scrapy.Spider):
name = 'jian'
allowed_domains = ['www.jianshu.com']
start_urls = ('https://www.jianshu.com/trending/monthly?utm_medium=index-banner-s&utm_source=desktop',)
def parse(self, response):
item = JianshuItem()
content = response.xpath('//div[@class="content"]')
for each in content:
item['title'] = each.xpath('./a/text()')[0].extract()
abstract = each.xpath('./p/text()')[0].extract()
abstract = abstract.replace("\\n", "")
abstract = abstract.strip()
item['abstract'] = abstract
item['nickname'] = each.xpath('./div/a/text()')[0].extract()
item['link'] = "https://www.jianshu.com" + each.xpath('./a/@href')[0].extract()
yield item
import scrapy
class JianshuItem(scrapy.Item):
#文章标题
title = scrapy.Field()
#摘要
abstract = scrapy.Field()
#作者
nickname = scrapy.Field()
#文章链接
link = scrapy.Field()
import pymongo
from scrapy.conf import settings
class JianshuPipeline(object):
def __init__(self):
#主机
host = settings["MONGODB_HOST"]
#端口
port = settings["MONGODB_PORT"]
#数据库名
dbname = settings["MONGODB_DBNAME"]
#数据表
sheetname = settings["MONGODB_SHEETNAME"]
#创建MONGODB数据库
client = pymongo.MongoClient(host=host, port=port)
#指定数据库
mydb = client[dbname]
#指定数据表
self.post = mydb[sheetname]
def process_item(self, item, spider):
data = dict(item)
self.post.insert(data)
return item
# Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = 'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0;'
ITEM_PIPELINES=
'JianShu.pipelines.JianshuPipeline':300
MONGODB_HOST = "127.0.0.1"
MONGODB_PORT = 27017
MONGODB_DBNAME = "jianshu"
MONGODB_SHEETNAME = "jianshuPaper"
结果:爬取结果展示
爬取到的数据存储在mongodb数据库中,查看新建的数数据库“jianshu”,数据表“jianshuPaper”和表内容是否存在,具体操作如下。
-
连接数据库

-
查看已有数据库
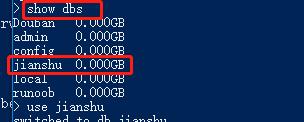
-
查看库jianshu的表

-
查看表jianshuPaper内容

问题总结
DEBUG: Crawled (403) XXX
解决:settings.py文件中增加如下代理
USER_AGENT = ‘Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0;’
以上是关于Scrapy学习第五课的主要内容,如果未能解决你的问题,请参考以下文章