读书笔记
Posted ball球
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了读书笔记相关的知识,希望对你有一定的参考价值。
第4部分 组件构建原则
如果说SOLID原则是用于指导我们如何将砖块砌成墙与房间的,那么组件构建原则就是用来指导我们如何将这些房间组合成房子的。
第12章 组件
组件是软件的部署单元,是整个软件系统在部署过程中可以独立完成部署的最小实体。
在编译运行语言中,组件是一组二进制文件的集合。而在解释运行语言中,组件则是一组源代码文件的集合。无论采用什么编程语言来开发软件,组件都是该软件在部署过程中的最小单元。
但无论采用哪种部署形式,设计良好的组件都应该永远保持可被独立部署的特性,这同时也意味着这些组件应该可以被单独开发。
程序的规模会一直不断地增长下去,直到将有限的编译和链接时间填满为止。
我们常常会在程序运行时插入某些动态链接文件,这些动态链接文件所使用的就是软件架构中的组件概念。
组件化的插件式架构已经成为我们习以为常的软件构建形式了。
第13章 组件聚合
与构建组件相关的三个基本原则:
- REP:复用/发布等同原则。
- CCP:共同闭包原则。
- CRP:共同复用原则。
复用/发布等同原则(REP)
软件复用的最小粒度应等同于其发布的最小粒度。
从软件设计和架构设计的角度来看,REP原则就是指组件中的类与模块必须是彼此紧密相关的。也就是说,一个组件不能由一组毫无关联的类和模块组成,它们之间应该有一个共同的主题或者大方向。
共同闭包原则(CCP)
我们应该将那些会同时修改,并且为相同目的而修改的类放到同一个组件中,而将不会同时修改,并且不会为了相同目的而修改的那些类放到不同的组件中。
CCP原则也认为一个组件不应该同时存在着多个变更原因。
CCP的主要作用就是提示我们要将所有可能会被一起修改的类集中在一处。也就是说,如果两个类紧密相关,不管是源代码层面还是抽象理念层面,永远都会一起被修改,那么它们就应该被归属为同一个组件。
与SRP的相似点:在SRP原则的指导下,我们将会把变更原因不同的函数放入不同的类中。而CCP原则指导我们应该将变更原因不同的类放入不同的组件中。简而言之,这两个原则都可以用以下一句简短的话来概括:将由于相同原因而修改,并且需要同时修改的东西放在一起。将由于不同原因而修改,并且不同时修改的东西分开。
共同复用原则(CRP)
不要强迫一个组件的用户依赖他们不需要的东西。
CRP原则实际上是在指导我们:不是紧密相连的类不应该被放在同一个组件里。
与与ISP原则的关系:ISP原则是建议我们不要依赖带有不需要的函数的类,而CRP原则则是建议我们不要依赖带有不需要的类的组件。上述两条建议实际上都可以用下面一句话来概括:不要依赖不需要用到的东西。
组件聚合张力图
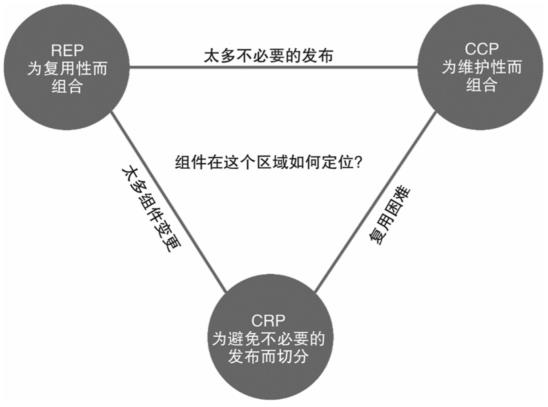
一般来说,一个软件项目的重心会从该三角区域的右侧开始,先期主要牺牲的是复用性。然后,随着项目逐渐成熟,其他项目会逐渐开始对其产生依赖,项目重心就会逐渐向该三角区域的左侧滑动。换句话说,一个项目在组件结构设计上的重心是根据该项目的开发时间和成熟度不断变动的,我们对组件结构的安排主要与项目开发的进度和它被使用的方式有关,与项目本身功能的关系其实很小。
本章小结
在决定将哪些类归为同一个组件时,必须要考虑到研发性与复用性之间的矛盾,并根据应用程序的需要来平衡这两个矛盾。
这种平衡本身也在不断变化。也就是说,当下适用的分割方式可能明年就不再适用了。所以,组件的构成安排应随着项目重心的不同,以及研发性与复用性的不同而不断演化。
第14章 组件耦合
三条组件之间关系的原则:
- 无依赖环原则
- 稳定依赖原则
- 稳定抽象原则
无依赖环原则
组件依赖关系图中不应该出现环。
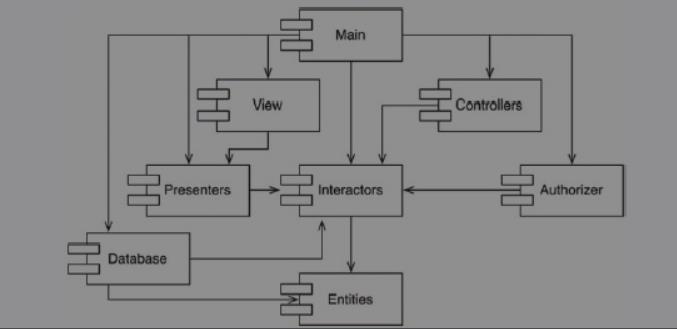
不管我们从该图中的哪个节点开始,都不能沿着这些代表了依赖关系的边最终走回到起始点。也就是说,这种结构中不存在环,我们称这种结构为有向无环图(Directed AcyclicGraph,简写为DAG)。
只有消除循环依赖,才能消除团队之间相互依赖的情况,进而进行独立开发。
打破循环依赖
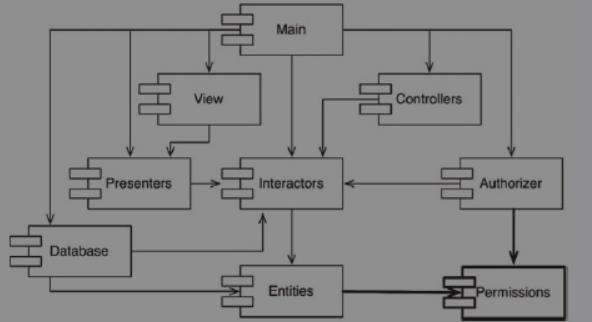
下面是一个循环依赖的例子,右下角的Authorizer, Interactors, Entities形成了循环依赖。
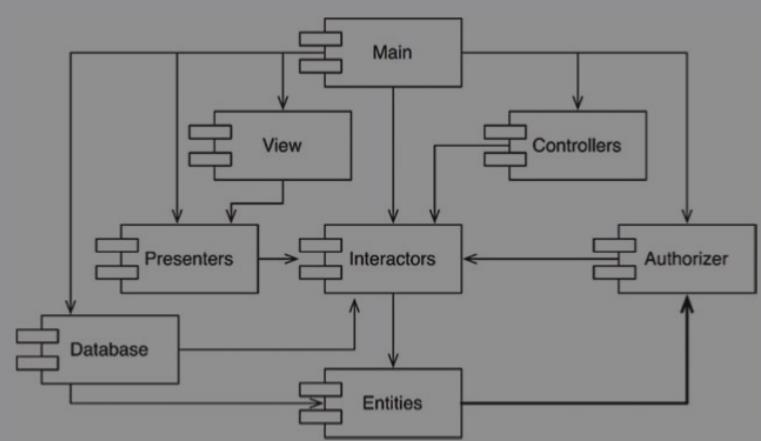
目前有以下两种主要机制可以做到这件事情。
- 1.应用依赖反转原则(DIP)
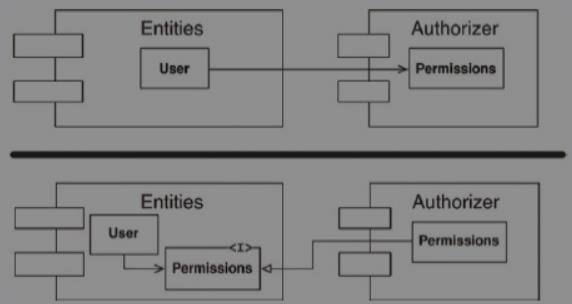
将Entities与Authorizer之间的依赖关系反转。
- 2.创建一个新的组件,并让Entities与Authorize这两个组件都依赖于它。
自上而下的设计
组件结构图是不可能自上而下被设计出来的。它必须随着软件系统的变化而变化和扩张,而不可能在系统构建的最初就被完美设计出来。
组件依赖结构图并不是用来描述应用程序功能的,它更像是应用程序在构建性与维护性方面的一张地图。这就是组件的依赖结构图不能在项目的开始阶段被设计出来的原因——当时该项目还没有任何被构建和维护的需要,自然也就不需要一张地图来指引。
组件结构图中的一个重要目标是指导如何隔离频繁的变更。我们不希望那些频繁变更的组件影响到其他本来应该很稳定的组件,
组件依赖关系是必须要随着项目的逻辑设计一起扩张和演进的。
稳定依赖原则(SDP)
依赖关系必须要指向更稳定的方向。
通过遵守稳定依赖原则(SDP),我们就可以确保自己设计中那些容易变更的模块不会被那些难于修改的组件所依赖。
稳定性
让软件组件难于修改的一个最直接的办法就是让很多其他组件依赖于它。带有许多入向依赖关系的组件是非常稳定的,因为它的任何变更都需要应用到所有依赖它的组件上。
在图14.5中,X不依赖于任何组件,所以不会有任何原因导致它需要被变更,我们称它为“独立”组件。
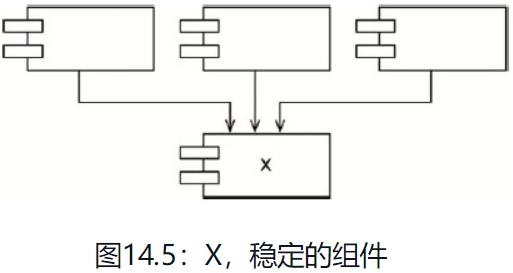
图14.6中,Y同时依赖于三个组件,所以它的变更就可能由三个不同的源产生。这里就说Y是有依赖性的组件。
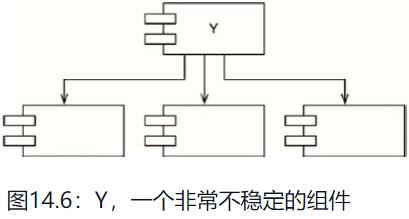
稳定性指标
究竟该如何来量化一个组件的稳定性呢?其中一种方法是计算所有入和出的依赖关系。通过这种方法,我们就可以计算出一个组件的位置稳定性(positionalstability)。
- Fan-in:入向依赖,这个指标指代了组件外部类依赖于组件内部类的数量。
- Fan-out:出向依赖,这个指标指代了组件内部类依赖于组件外部类的数量。
- I:不稳定性
I=Fan-out/(Fan-in + Fan-out)。
该指标的范围是[0,1], I=0意味着组件是最稳定的,I=1意味着组件是最不稳定的。
当I指标等于1时,说明没有组件依赖当前组件(Fan-in=0),同时该组件却依赖于其他组件(Fan-out>0)。这是组件最不稳定的一种情况,我们认为这种组件是“不负责的(irresponsible)、对外依赖的(dependent)”由于这个组件没有被其他组件依赖,所以自然也就没有力量会干预它的变更,同时也因为该组件依赖于其他组件,所以就必然会经常需要变更。
当I=0的时候,说明当前组件是其他组件所依赖的目标(Fan-in>0),同时其自身并不依赖任何其他组件(Fan-out=0)。我们通常认为这样的组件是“负责的(responsibile)、不对外依赖的(independent)”。这是组件最具稳定性的一种情况,其他组件对它的依赖关系会导致这个组件很难被变更,同时由于它没有对外依赖关系,所以不会有来自外部的变更理由。
稳定依赖原则(SDP)的要求是让每个组件的I指标都必须大于其所依赖组件的I指标。也就是说,组件结构依赖图中各组件的I指标必须要按其依赖关系方向递减。
并不是所有组件都应该是稳定的
如果一个系统中的所有组件都处于最高稳定性状态,那么系统就一定无法再进行变更了,这显然不是我们想要的。事实上,我们设计组件架构图的目的就是要决定应该让哪些组件稳定,让哪些组件不稳定。
抽象组件
抽象组件通常会非常稳定,可以被那些相对不稳定的组件依赖。
稳定抽象原则(SAP)
一个组件的抽象化程度应该与其稳定性保持一致。
高阶策略应该放在哪
代表了系统高阶策略的组件应该被放到稳定组件(I=0)中,而不稳定的组件(I=1)中应该只包含那些我们想要快速和方便修改的部分。
如何才能让一个无限稳定的组件(I=0)接受变更呢?开闭原则(OCP)为我们提供了答案。这个原则告诉我们:创造一个足够灵活、能够被扩展,而且不需要修改的类是可能的,而这正是我们所需要的。哪一种类符合这个原则呢?答案是抽象类。
稳定抽象原则简介
稳定抽象原则(SAP)为组件的稳定性与它的抽象化程度建立了一种关联。一方面,该原则要求稳定的组件同时应该是抽象的,这样它的稳定性就不会影响到扩展性。另一方面,该原则也要求一个不稳定的组件应该包含具体的实现代码,这样它的不稳定性就可以通过具体的代码被轻易修改。
如果一个组件想要成为稳定组件,那么它就应该由接口和抽象类组成,以便将来做扩展。
将SAP与SDP这两个原则结合起来,就等于组件层次上的DIP。因为SDP要求的是让依赖关系指向更稳定的方向,而SAP则告诉我们稳定性本身就隐含了对抽象化的要求,即依赖关系应该指向更抽象的方向。
衡量抽象化程度
假设A指标是对组件抽象化程度的一个衡量,它的值是组件中抽象类与接口所占的比例。
- Nc:组件中类的数量。
- Na:组件中抽象类和接口的数量。
- A:抽象程度
A = Na / Nc
A指标的取值范围是从0到1,值为0代表组件中没有任何抽象类,值为1就意味着组件中只有抽象类。
主序列
下面的I/A图中,最稳定的、包含了无限抽象类的组件应该位于左上角(0,1),最不稳定的、最具体的组件应该位于右下角(1,0)。
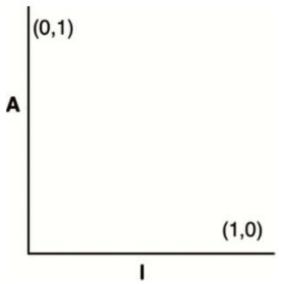
14.13为I/A图中的区域划分
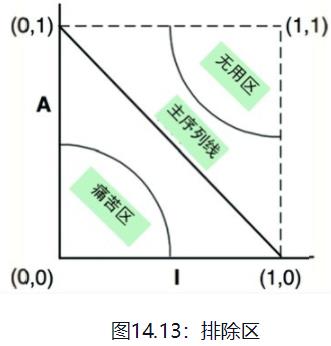
痛苦区
假设某个组件处于(0,0)位置,那么它应该是一个非常稳定但也非常具体的组件。这样的组件在设计上是不佳的,因为它很难被修改,这意味着该组件不能被扩展。这样一来,因为这个组件不是抽象的,而且它又由于稳定性的原因变得特别难以被修改,我们并不希望一个设计良好的组件贴近这个区域,因此(0,0)周围的这个区域被我们称为痛苦区(zone of pain)。
不可变组件落在(0,0)这一区域中是无害的,因为它们不太可能会发生变更。正因为如此,只有多变的软件组件落在痛苦区中才会造成麻烦,而且组件的多变性越强,造成的麻烦就会越大。
无用区
靠近(1,1)这一位置点的组件不会是我们想要的,因为这些组件通常是无限抽象的,但是没有被其他组件依赖,这样的组件往往无法使用。因此我们将这个区域称为无用区。
主序列线(mainsequence)
在整条主序列线上,组件所能处于最优的位置是线的两端。一个优秀的软件架构师应该争取将自己设计的大部分组件尽可能地推向这两个位置。
离主序列线的距离
D指标:
距离 D=|A+I-1|
该指标的取值范围是[0,1]。值为0意味着组件是直接位于主序列线上的,值为1则意味着组件在距离主序列最远的位置。
通过计算每个组件的D指标,就可以量化一个系统设计与主序列的契合程度了。另外,我们也可以用D指标大于0多少来指导组件的重构与重新设计。
对于一个良好的系统设计来说,D指标的平均值和方差都应该接近于0。
在图14.14中,我们可以看到大部分的组件都位于主序列附近,但是有些组件处于平均值的标准差(Z=1)以外。这些组件值得被重点分析,它们要么过于抽象但依赖不足,要么过于具体而被依赖得太多。
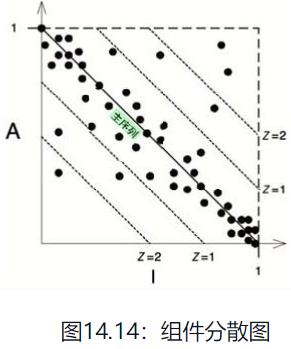
D指标的另外一种用法是按时间来跟踪每个组件的值。如果某个组件在某版本时的D值超过了达标红线,则需要进行重点关注。
以上是关于读书笔记的主要内容,如果未能解决你的问题,请参考以下文章
MapReduce与批处理------《Designing Data-Intensive Applications》读书笔记14