英雄联盟数据分析专题
Posted Babyface Killer
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了英雄联盟数据分析专题相关的知识,希望对你有一定的参考价值。
写在前面的话

大部分的英雄联盟玩家应该都知道英雄联盟全球总决赛的重要性,这是由Riot Games组织的世界范围内的英雄联盟俱乐部之间的比赛。该项赛事自2011年创办第一届后每年都会在十月为全球的英雄联盟玩家带来世界最强的俱乐部之间的对抗。自该项赛事创办以来,公认实力最强的也是讨论热度最高的两个赛区分别是:韩国赛区以及中国大陆赛区。在已举办的九届全球总决赛中,韩国赛区拿到过5次总冠军,其中SKT的中单选手Faker更是成为每年关注的焦点。但是2018年S8世界赛上中国大陆赛区IG队伍成功登顶不仅圆了众多国内英雄联盟玩家的梦,也让中国大陆赛区重新回归最强赛区之列,而2019年的S9世界赛中国大陆赛区的FPX队伍再一次拿到世界总冠军才正式让韩国赛区退下神坛。经过一代又一代英雄联盟职业选手的努力终于让中国大陆赛区得到了世界范围的认可,也得以让英雄联盟这款游戏在PUBG的冲击下在中国市场能继续维持生命力。
背景介绍

该数据集包含了2019年英雄联盟全球总决赛自入围赛开始所有队伍的数据,包括ban/pick,kda,游戏时长等总共91个字段。这91项游戏数据足以从整体和细节上完整的描述一场游戏,我们会利用这些数据分析各队伍的特点。因为战队之间的比赛和平时游戏里的排位比赛有很大不同,所以红蓝方,ban/pick,各分路经济情况也成为了需要进行分析的点。
下面是该数据集中包含的字段以及对各字段的解释:
date:比赛进行的日期
side:红方或蓝方
position:选手的位置(Top,Middle,Jungle,ADC,Support)
player:选手的ID
team:队伍名称
champion:选手选择的英雄
ban1,ban2,ban3,ban4,ban5:从第一到第五次禁选的英雄
gamelength:游戏时长
result:游戏结果
k,d,a:击杀,死亡,助攻
teamkills,teamdeaths:队伍总击杀,队伍总死亡
doubles,triples,quadras,pentas:双杀,三杀,四杀,五杀
.......(中间包含的众多游戏元素信息因篇幅过长在这里不做解释,分析用到时会另做解释)
数据预处理
首先照例进行数据预处理。
#导入需要用到的包
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
#导入数据
wc_data=pd.read_csv('wc_players.csv')
#看看数据的总量
wc_data.shape 该数据集有1190条数据,91个字段。
该数据集有1190条数据,91个字段。
接下来看看数据类型以及有没有缺失数据。
#先来看一下数据类型
wc_data.dtypes.value_counts()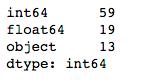
#看一下有没有缺失数据
wc_data.isnull().sum().value_counts() 结果显示有两个字段有40个缺失值,一个字段有1190个缺失值,一个字段有5个缺失值。在确定缺失值的处理方式之前要先看看这些值都是什么类型,有什么含义。
结果显示有两个字段有40个缺失值,一个字段有1190个缺失值,一个字段有5个缺失值。在确定缺失值的处理方式之前要先看看这些值都是什么类型,有什么含义。
#分别找出有缺失值的字段
null_40=wc_data.columns[wc_data.isnull().sum()==40]
null_1190=wc_data.columns[wc_data.isnull().sum()==1190]
null_5=wc_data.columns[wc_data.isnull().sum()==5]
print('Columns with 40 null values:',null_40)
print('Columns with 1190 null values:',null_1190)
print('Columns with 5 null values:',null_5)

得到了有缺值的字段的信息,我们就可以逐一分析如何对缺失值进行处理。对于有40个缺失值的'fbaron' 和 'fbarontime',这两个字段分别表示队伍是否击杀第一条男爵以及击杀第一条男爵的时间,对于这两列缺失值我们直接用'0'填充(注意这里要使用字符串,因为这两列的类型为’object'。再来看有1190条缺失值的字段,'heraldtime' 表示击杀峡谷先锋的时间,因为该列的缺失值过多且无法使用平均数,众数等填充所以直接把这一列删除。最后对于有5个缺失值的'ban5'字段,我们可以选择用第五次禁选最多的英雄填充缺失值。
#为40个缺失值的字段填充0
wc_data['fbaron'].fillna('0',inplace=True)
wc_data['fbarontime'].fillna('0',inplace=True)
#直接删除1190个缺失值的字段
wc_data.drop(columns=['heraldtime'],inplace=True)
#为5个缺失值的字段填充该字段下出现次数最多的英雄
wc_data['ban5'].fillna(wc_data['ban5'].value_counts().index[0],inplace=True)
#检查数据集中现在是否还有缺失值
wc_data.isnull().sum().value_counts()
 结果显示我们的缺失处理过程已经完成。
结果显示我们的缺失处理过程已经完成。
2019全球总决赛包含了两部分:入围赛和正赛,而这两部分无论是队伍实力还是对抗激烈程度都有很大区别,所以我们要把这两部分分开分析。
#把数据分成入围赛部分和正赛部分
#取出入围赛结束日期最后一场比赛最后一个选手对应的index
index=wc_data[wc_data['date']=='2019/10/8'].index[-1]
#分割出入围赛部分
wc_pis=wc_data.iloc[:index+1,:]
#分割出正赛部分
wc_mg=wc_data.iloc[index+1:,:]
到这一步为止,我们的数据预处理就完成了。
探索性数据分析和可视化
我们先对入围赛进行分析。
#先看看入围赛有多少队伍参加
wc_pis['team'].unique()
再来看看入围赛中各位置出场次数最多的英雄。
#入围赛中各位置使用最多的三个英雄及出场次数
wc_pis_top=wc_pis[wc_pis['position']=='Top']['champion'].value_counts()[:3]
wc_pis_jungle=wc_pis[wc_pis['position']=='Jungle']['champion'].value_counts()[:3]
wc_pis_middle=wc_pis[wc_pis['position']=='Middle']['champion'].value_counts()[:3]
wc_pis_adc=wc_pis[wc_pis['position']=='ADC']['champion'].value_counts()[:3]
wc_pis_support=wc_pis[wc_pis['position']=='Support']['champion'].value_counts()[:3]
#可视化
plt.figure(figsize=(20,5))
axe1=plt.subplot(1,5,1)
axe1.bar(np.arange(3),height=wc_pis_top,tick_label=wc_pis_top.index)
axe1.set_title('Top')
axe2=plt.subplot(1,5,2)
axe2.bar(np.arange(3),height=wc_pis_jungle,tick_label=wc_pis_jungle.index)
axe2.set_title('Jungle')
axe3=plt.subplot(1,5,3)
axe3.bar(np.arange(3),height=wc_pis_middle,tick_label=wc_pis_middle.index)
axe3.set_title('Middle')
axe4=plt.subplot(1,5,4)
axe4.bar(np.arange(3),height=wc_pis_adc,tick_label=wc_pis_adc.index)
axe4.set_title('ADC')
axe5=plt.subplot(1,5,5)
axe5.bar(np.arange(3),height=wc_pis_support,tick_label=wc_pis_support.index)
axe5.set_title('Support')
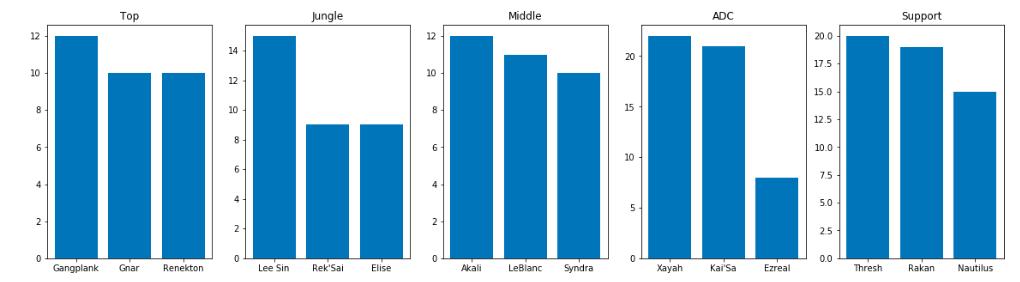
对于ADC和辅助两个位置,选择似乎非常固定,ADC位置霞和卡莎平分秋色,辅助位置锤石和洛各有千秋。其他三个位置上,打野位似乎盲僧会成为队伍首选,但上单和中单位对英雄的选择偏向似乎并不明显。当然各个位置被选择最多的英雄一定是当时版本强势或能反制版本强势英雄的英雄,在战队比赛中英雄选择的自由度并没有排位游戏高,在后面的分析我们应该也会看到这些英雄再次出现在正赛各位置被选择最多的英雄榜单上。从这个结果来看,全球总决赛入围赛中各位置出现最多的英雄分别是:





#看看各个队胜率是多少
win_rate_dict=
for team in list(wc_pis['team'].unique()):
counts=wc_pis[wc_pis['team']==team]['result'].value_counts().sort_index()
win_rate=round(counts[counts.index[1]]/(counts[counts.index[0]]+counts[counts.index[1]]),2)
win_rate_dict[team]=win_rate
#可视化
win_rates=[x for x in win_rate_dict.values()]
team=[x for x in win_rate_dict.keys()]
plt.figure(figsize=(20,5))
plt.bar(np.arange(12),height=win_rates,tick_label=team)
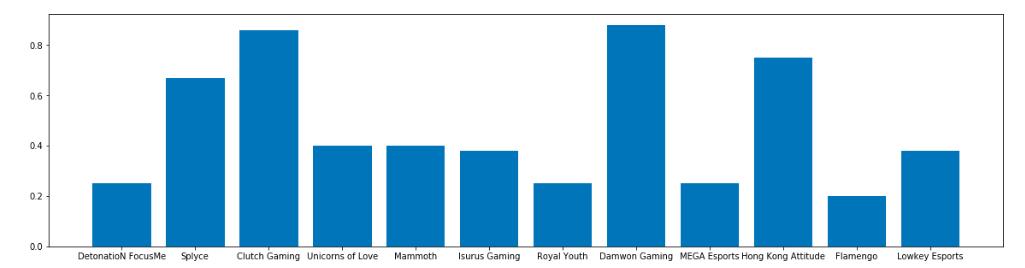
从结果我们可以看到胜率较高的两支队伍分别是:Clutch Gaming 和 Damwon Gaming,这两支队伍也是分别来自实力较强的北美赛区和韩国赛区。胜率前四的四支队伍分别是:Clutch Gaming,Damwon Gaming,Hong Kong Attitude 和 Splyce,这四支队伍也是在入围赛杀入正赛的四支队伍。从这个结果来看,入围赛中各支队伍还是存在着较大的实力差距,外卡赛区的战队胜率皆不足百分之五十,而实力较强的赛区队伍胜率可以达到可怕的百分之八十。
因为数据集中没有每场比赛的MVP选手的数据,我们就用kda来代替MVP来评估选手的表现。我们现在来看看在入围赛中表现最好的五位选手分别是谁,以及他们的KDA分别为多少。注意,由于英雄联盟官方在比赛中使用的KDA计算方法为:(K+A)/D,不同于在游戏中计算KDA的方法,因此在这里我们计算KDA时也使用官方的计算方法。
#入围赛中表现最好的选手(平均kda最高)
KDA=[]
for k,d,a in zip(wc_pis['k'],wc_pis['d'],wc_pis['a']):
if d == 0:
kda=round((k+a)/(d+1),2)
else:
kda=round((k+a)/d,2)
KDA.append(kda)
wc_pis['KDA']=KDA
#单独把选手和KDA提取出来
wc_pis_player_kda=wc_pis.loc[:,['player','KDA']]
#计算每位选手的平均KDA
wc_pis_player_kda=round(wc_pis_player_kda.groupby('player').mean(),2)
wc_pis_player_kda.sort_values(by='KDA',ascending=False,inplace=True)
#入围赛中KDA前五的选手
wc_pis_player_kda[:5] 这五位选手分别是:CG的ADC:Cody Sun,Splyce的ADC:Kobbe,CG的打野:Lira,DWG的打野Canyon,以及DWG的中单Showmaker。在入围赛中吸引了众多眼球的CG上单HUNI却没出现在这份榜单中(呼子哥对不起🙃 🙃 🙃 )。
这五位选手分别是:CG的ADC:Cody Sun,Splyce的ADC:Kobbe,CG的打野:Lira,DWG的打野Canyon,以及DWG的中单Showmaker。在入围赛中吸引了众多眼球的CG上单HUNI却没出现在这份榜单中(呼子哥对不起🙃 🙃 🙃 )。
入围赛只是热身,下面让我进入到对正赛的分析。
我们先来看看参加正赛的都有哪些队伍。
#先看看正赛有多少队伍参加
wc_mg['team'].unique()
再来看看在正赛中各位置使用最多的英雄分别是哪些。
#正赛中各位置使用最多的三个英雄及出场次数
wc_mg_top=wc_mg[wc_mg['position']=='Top']['champion'].value_counts()[:3]
wc_mg_jungle=wc_mg[wc_mg['position']=='Jungle']['champion'].value_counts()[:3]
wc_mg_middle=wc_mg[wc_mg['position']=='Middle']['champion'].value_counts()[:3]
wc_mg_adc=wc_mg[wc_mg['position']=='ADC']['champion'].value_counts()[:3]
wc_mg_support=wc_mg[wc_mg['position']=='Support']['champion'].value_counts()[:3]
#可视化
plt.figure(figsize=(20,5))
axe1=plt.subplot(1,5,1)
axe1.bar(np.arange(3),height=wc_mg_top,tick_label=wc_mg_top.index)
axe1.set_title('Top')
axe2=plt.subplot(1,5,2)
axe2.bar(np.arange(3),height=wc_mg_jungle,tick_label=wc_mg_jungle.index)
axe2.set_title('Jungle')
axe3=plt.subplot(1,5,3)
axe3.bar(np.arange(3),height=wc_mg_middle,tick_label=wc_mg_middle.index)
axe3.set_title('Middle')
axe4=plt.subplot(1,5,4)
axe4.bar(np.arange(3),height=wc_mg_adc,tick_label=wc_mg_adc.index)
axe4.set_title('ADC')
axe5=plt.subplot(1,5,5)
axe5.bar(np.arange(3),height=wc_mg_support,tick_label=wc_mg_support.index)
axe5.set_title('Support')
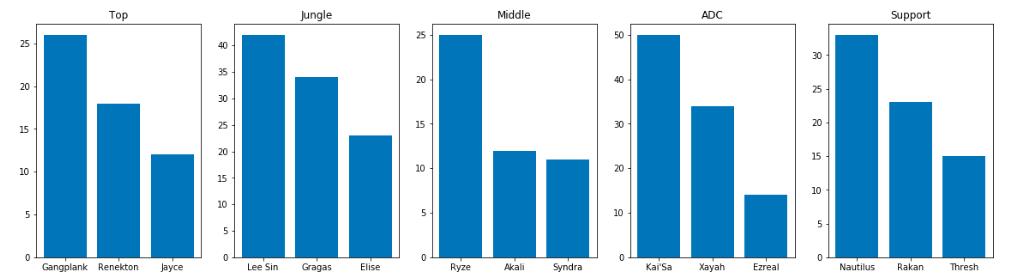
我们来把这个结果和入围赛的结果比较一下:首先看整体,各位置对英雄的选择次数和入围赛相比差距已经拉开,从结果来看每个位置都有一个首选英雄且与第二顺位英雄被选择次数相差较多。再从各分路分析,上单被选择次数最多的英雄依然是船长,在入围赛中结果中出现的鳄鱼也出现在了前三的位置;打野位置盲僧雷打不动依旧排名第一,而第二名从雷克塞变成了酒桶;中单位置第一从阿卡丽变成了瑞兹;而在ADC位置上卡莎和霞拉开了差距,卡莎被选次数达到了50次之多,造成这个结果的原因也可能是因为在ban/pick时霞洛组合其一被ban或被选导致霞的优先级有所下降;在辅助位深海泰坦一跃成为第一,而洛和锤石变为第二和第三,当然部分原因也和前面提到的霞洛组合有关。从这个结果来看,在正赛中,各位置出现最多的英雄分别为:





看完了被选择最多的英雄,我们一样要看看被ban最多的英雄。
#再来观察一下正赛中各轮次被ban次数最多的英雄分别是谁
ban_champ_dict=
ban_round=['ban1','ban2','ban3','ban4','ban5']
for each in ban_round:
counts=wc_mg[each].value_counts()[:3]
ban_champ_dict[each]=counts
#可视化
plt.figure(figsize=(20,5))
axe1=plt.subplot(1,5,1)
axe1.bar(np.arange(3),height=ban_champ_dict['ban1']/5,tick_label=ban_champ_dict['ban1'].index)
axe1.set_title('Ban1')
axe2=plt.subplot(1,5,2)
axe2.bar(np.arange(3),height=ban_champ_dict['ban2']/5,tick_label=ban_champ_dict['ban2'].index)
axe2.set_title('Ban2')
axe3=plt.subplot(1,5,3)
axe3.bar(np.arange(3),height=ban_champ_dict['ban3']/5,tick_label=ban_champ_dict['ban3'].index)
axe3.set_title('Ban3')
axe4=plt.subplot(1,5,4)
axe4.bar(np.arange(3),height=ban_champ_dict['ban4']/5,tick_label=ban_champ_dict['ban4'].index)
axe4.set_title('Ban4')
axe5=plt.subplot(1,5,5)
axe5.bar(np.arange(3),height=ban_champ_dict['ban5']/5,tick_label=ban_champ_dict['ban5'].index)
axe5.set_title('Ban5')
首先来看第一ban,潘森被ban次数达到了惊人的接近70次,证明潘森在当时的版本已经达到了非ban必选的程度,说明英雄联盟的设计师们在对潘森的平衡性设计上还得多下点功夫。第二ban奇亚娜位居榜首,其次是阿卡丽和辛德拉。而从第三ban之后各英雄被ban的次数就相对均衡了许多,注意阿卡丽同时出现在了第一,第二和第三ban的前三名之列,证明在当时的版本阿卡丽也算是一个比较强势的英雄。
下面我们开始转移到到游戏进行中产生的数据。
先来看看野怪数据上能给我们什么启发吧。
#场均野怪击杀最高的前五名选手
#先把选手和击杀野怪数单独提取成为一个DataFrame
monster_killed_df=wc_mg.loc[:,['player','monsterkills']]
#计算每位选手平均击杀野怪数
monster_killed_df=monster_killed_df.groupby(['player']).mean()
#对平均击杀野怪数排序
monster_killed_df.sort_values(by='monsterkills',ascending=False,inplace=True)
#提取出前五名选手和对应平均击杀野怪数
top_5_players=monster_killed_df.index[:5]
top_5_monster_killed=monster_killed_df['monsterkills'][:5]
#对结果进行可视化
plt.figure(figsize=(6,6))
plt.bar(np.arange(5),height=top_5_monster_killed,tick_label=top_5_players)
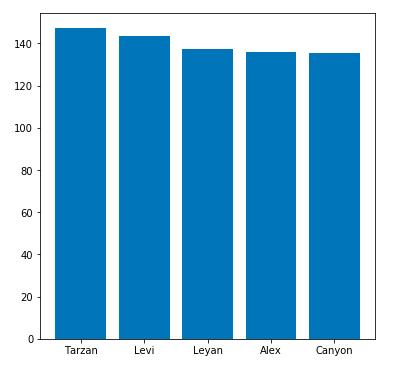 场均击杀野怪数前五名选手相差不多,第一名是Griffin的Tarzan选手,第二名是GAM的Levi(越南打野属实有点东西🤔 🤔 🤔 ),第三名是替补上场的IG打野Leyan,四五名分别是AHQ的Alex和DWG的Canyon。
场均击杀野怪数前五名选手相差不多,第一名是Griffin的Tarzan选手,第二名是GAM的Levi(越南打野属实有点东西🤔 🤔 🤔 ),第三名是替补上场的IG打野Leyan,四五名分别是AHQ的Alex和DWG的Canyon。
我们都知道作为打野,不光要注重在自家野区的刷野效率,是不是也得去对方野区偷点东西以此来给对方打野施加压力😎 😎 😎 ,那么我们就来看看在敌方野区偷东西最多的前五名选手是谁。
#场均对方野区野怪击杀最高的前五名选手
monster_killed_df=wc_mg.loc[:,['player','monsterkillsenemyjungle']]
monster_killed_df=monster_killed_df.groupby(['player']).mean()
monster_killed_df.sort_values(by='monsterkillsenemyjungle',ascending=False,inplace=True)
top_5_players=monster_killed_df.index[:5]
top_5_monster_killed=monster_killed_df['monsterkillsenemyjungle'][:5]
#对结果进行可视化
plt.figure(figsize=(6,6))
plt.bar(np.arange(5),height=top_5_monster_killed,tick_label=top_5_players)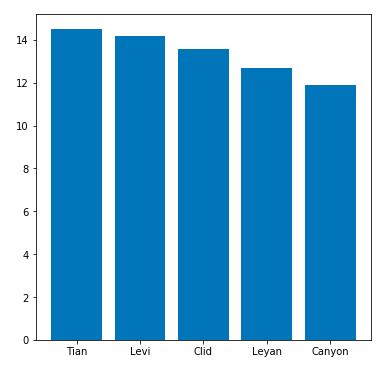 这个结果就非常灵性了,充分展示了亚洲打野的特点,上榜的前五名全部是亚洲打野,从高到低依次是:FPX的Tian,GAM的Levi,SKT的Clid,IG的Leyan以及DWG的Canyon。这充分说明了亚洲打野对于野区的侵略意图是非常高的,而欧洲和北美地区的打野在这一点上似乎并没有引起足够的重视。
这个结果就非常灵性了,充分展示了亚洲打野的特点,上榜的前五名全部是亚洲打野,从高到低依次是:FPX的Tian,GAM的Levi,SKT的Clid,IG的Leyan以及DWG的Canyon。这充分说明了亚洲打野对于野区的侵略意图是非常高的,而欧洲和北美地区的打野在这一点上似乎并没有引起足够的重视。
下面我们再来看看场均补刀数前五的选手分别是谁。
#场均补刀最高的前五名选手
minion_killed_df=wc_mg.loc[:,['player','minionkills']]
minion_killed_df=minion_killed_df.groupby(['player']).mean()
minion_killed_df.sort_values(by='minionkills',ascending=False,inplace=True)
top_5_player=minion_killed_df.index[:5]
top_5_minion_killed=minion_killed_df['minionkills'][:5]
#对结果进行可视化
plt.figure(figsize=(6,6))
plt.bar(np.arange(5),height=top_5_minion_killed,tick_label=top_5_player)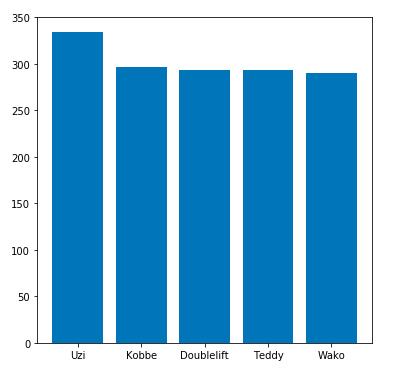 毫不意外,上榜的五位全部为各队ADC选手,我们都知道ADC在前期相对弱势,需要和平补刀来为后期的持续性伤害输出做好铺垫。同时在后期ADC也起到清理/推进各路兵线的主要作用。虽然各位选手的场均补刀数相差不大,但作为第一名的RNG队ADC Uzi还是和后几位拉开了一点差距。即使一直有人对Uzi吃三路兵线质疑,但不得不说Uzi在后期的输出能力确实不容小觑。
毫不意外,上榜的五位全部为各队ADC选手,我们都知道ADC在前期相对弱势,需要和平补刀来为后期的持续性伤害输出做好铺垫。同时在后期ADC也起到清理/推进各路兵线的主要作用。虽然各位选手的场均补刀数相差不大,但作为第一名的RNG队ADC Uzi还是和后几位拉开了一点差距。即使一直有人对Uzi吃三路兵线质疑,但不得不说Uzi在后期的输出能力确实不容小觑。
除了补刀,视野在游戏中,特别是赛场上的作用同样重要。在赛场上各战队配合无缝衔接的情况下,视野稍微有点疏漏就可能会导致一个队友被击杀甚至让对方滚起雪球。那么我们就来看看,场均安插视野数最多的前五位是谁。
#场均插眼数最高前五名
wards_df=wc_mg.loc[:,['player','wards']]
wards_df=wards_df.groupby(['player']).mean()
wards_df.sort_values(by='wards',ascending=False,inplace=True)
top_5_player=wards_df.index[:5]
top_5_wards_placed=wards_df['wards'][:5]
#对结果进行可视化
plt.figure(figsize=(6,6))
plt.bar(np.arange(5),height=top_5_wards_placed,tick_label=top_5_player)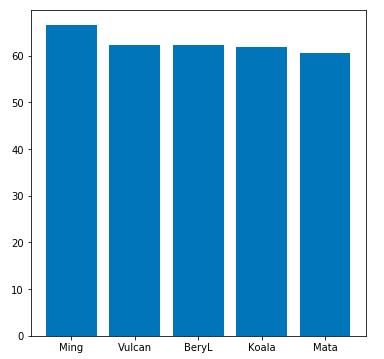 正所谓什么人干什么活,插眼数前五位也毫不例外的被辅助选手包揽。
正所谓什么人干什么活,插眼数前五位也毫不例外的被辅助选手包揽。
前几项分析中各结果前五位选手之间都没有出现明显的差距,这证明世界赛场上强队之间的比拼并不是哪个明星选手的实力,而是团队之间的配合和临场应变能力,而这也是电竞最精彩的地方。
下面就到了每场游戏结束必会出现的造成伤害/承受伤害统计数据环节。
我们先来看看正赛中场均伤害最高的前五名选手都是谁。
#场均伤害最高前五名
damage_df=wc_mg.loc[:,['player','dmgtochamps']]
damage_df=damage_df.groupby(['player']).mean()
damage_df.sort_values(by='dmgtochamps',ascending=False,inplace=True)
top_5_player=damage_df.index[:5]
top_5_damage_to_champion=damage_df['dmgtochamps'][:5]
#对结果进行可视化
plt.figure(figsize=(6,6))
plt.bar(np.arange(5),height=top_5_damage_to_champion,tick_label=top_5_player) 这个结果很有趣,我们来仔细分析一下。第一名是C9的ADC选手Sneaky,而这位选手却没有出现在补刀数前五的队列中,这就是传说中的“吃的是草,挤的是奶”型ADC,而且该选手甚至比第二名场均高出了约4000点伤害值。第二名是CG的上单选手Huni(呼子哥终于来了),在后面的分析中大家会看到CG一场都没赢过,但Huni的场均伤害却高居所有选手的第二(呼子哥表示队友菜逼带不动🙄 🙄 🙄 )。第三名就是我们的“众神之神”Shy哥(对不起我是Shy吹🙃 🙃 🙃 ),虽然场均伤害仅次于Huni,但两位选手不管是对于团战的贡献还是对线技巧上孰强孰弱应该不用我多说了。第四名就是和第一名刚好相反类型的ADC选手RNG的Uzi,虽然补刀数位列第一,场均伤害也高居前五,但和Sneaky这种超级经济实惠型ADC还有一定差距。第五名是来自J Team的中单选手FoFo,而他也是这份榜单中唯一的中单选手。
这个结果很有趣,我们来仔细分析一下。第一名是C9的ADC选手Sneaky,而这位选手却没有出现在补刀数前五的队列中,这就是传说中的“吃的是草,挤的是奶”型ADC,而且该选手甚至比第二名场均高出了约4000点伤害值。第二名是CG的上单选手Huni(呼子哥终于来了),在后面的分析中大家会看到CG一场都没赢过,但Huni的场均伤害却高居所有选手的第二(呼子哥表示队友菜逼带不动🙄 🙄 🙄 )。第三名就是我们的“众神之神”Shy哥(对不起我是Shy吹🙃 🙃 🙃 ),虽然场均伤害仅次于Huni,但两位选手不管是对于团战的贡献还是对线技巧上孰强孰弱应该不用我多说了。第四名就是和第一名刚好相反类型的ADC选手RNG的Uzi,虽然补刀数位列第一,场均伤害也高居前五,但和Sneaky这种超级经济实惠型ADC还有一定差距。第五名是来自J Team的中单选手FoFo,而他也是这份榜单中唯一的中单选手。
我们再来看看在承受伤害方面前五的选手都有哪些。
#场均承受伤害最高前五名
damage_share_df=wc_mg.loc[:,['player','dmgshare']]
damage_share_df=damage_share_df.groupby(['player']).mean()
damage_share_df.sort_values(by='dmgshare',ascending=False,inplace=True)
top_5_player=damage_share_df.index[:5]
top_5_damage_share=damage_share_df['dmgshare'][:5]
#对结果进行可视化
plt.figure(figsize=(6,6))
plt.bar(np.arange(5),height=top_5_damage_share,tick_label=top_5_player)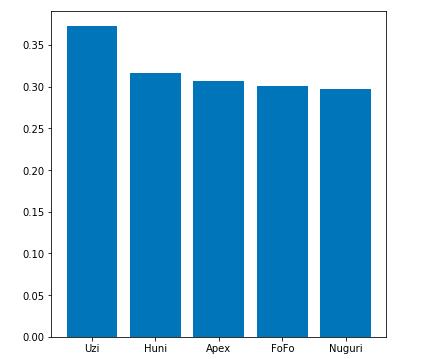 RNG的ADC选手Uzi意外地出现在了这份榜单的第一位,在世界赛场上作为一个ADC去送的情况不太可能出现,那就只能说是因为Uzi在后期超强的carry的能力使得他成为了对手集火的首要目标。而伤害值第二高的Huni在承受伤害榜单中也排在了第二(可我印象中呼子哥好像不怎么玩坦克😏 😏 😏 )。
RNG的ADC选手Uzi意外地出现在了这份榜单的第一位,在世界赛场上作为一个ADC去送的情况不太可能出现,那就只能说是因为Uzi在后期超强的carry的能力使得他成为了对手集火的首要目标。而伤害值第二高的Huni在承受伤害榜单中也排在了第二(可我印象中呼子哥好像不怎么玩坦克😏 😏 😏 )。
接下来我们再来看看在世界赛场上,红蓝方的选择到底对游戏的胜负有没有影响。
#在正赛中红蓝方的胜率分别是多少
side_df=wc_mg.loc[:,['side','result']]
win_count=side_df[side_df['side']=='Red']['result'].value_counts().sort_index()
win_rate=round(win_count[win_count.index[1]]/(win_count[win_count.index[1]]+win_count[win_count.index[0]]),2)
#对结果进行可视化
plt.figure(figsize=(6,6))
sizes=[1-win_rate,win_rate]
labels=('Blue Team','Red Team')
plt.pie(sizes,labels=labels,autopct='%1.0f%%')
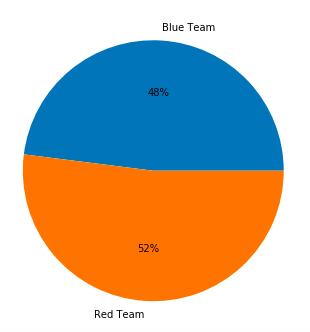 虽然有众多的文章或者解说都会分析红蓝方的选择对游戏结果的影响,但从结果上来看虽然红方胜率比蓝方稍高,但是也不足以达到使双方队伍拉开差距的地步。
虽然有众多的文章或者解说都会分析红蓝方的选择对游戏结果的影响,但从结果上来看虽然红方胜率比蓝方稍高,但是也不足以达到使双方队伍拉开差距的地步。
下面我们再从各支队伍的角度来看一下在全球总决赛中各支队伍的胜率分别是多少。
#看看各个队胜率是多少
win_rate_dict=
for team in list(wc_mg['team'].unique()):
counts=wc_mg[wc_mg['team']==team]['result'].value_counts().sort_index()
if len(counts) == 2:
win_rate=round(counts[counts.index[1]]/(counts[counts.index[0]]+counts[counts.index[1]]),2)
else:
if counts.index == 0:
win_rate=0
else:
win_rate=1
win_rate_dict[team]=win_rate
#为各队胜率创建一个DataFrame并按照胜率降序排序
win_rates=[x for x in win_rate_dict.values()]
team=[x for x in win_rate_dict.keys()]
win_rate_df=pd.DataFrame()
win_rate_df['team']=team
win_rate_df['win_rate']=win_rates
win_rate_df.sort_values(by='win_rate',ascending=False,inplace=True)
#对胜率按照高低排序可视化
win_rates=list(win_rate_df['win_rate'])
team=list(win_rate_df['team'])
plt.figure(figsize=(30,5))
plt.bar(np.arange(len(team)),height=win_rates)
plt.xticks(np.arange(len(team)),team,rotation=-45,ha='left')
plt.rc('font',size=18)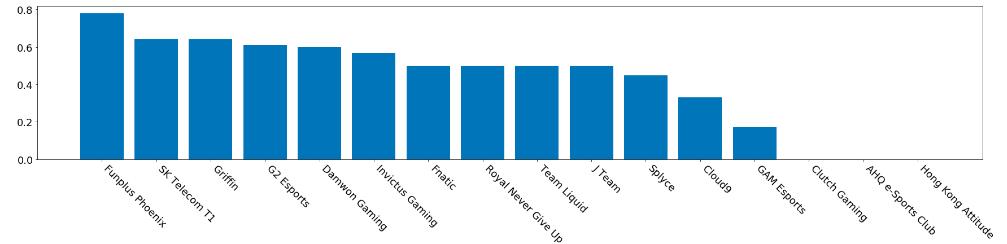
作为S9的冠军,FPX的胜率高达近80%,而两支韩国队伍SKT和Griffin紧随其后,决赛中FPX的对手G2仅位于第四。最后三支队伍CG,AHQ和HKA更是一场胜利都没有得到。
最后,让我们来看看在正赛中表现最好的前十位选手(同样使用KDA最为判断标准)。
#正赛中表现最好的选手(平均kda最高)
KDA=[]
for k,d,a in zip(wc_mg['k'],wc_mg['d'],wc_mg['a']):
if d == 0:
kda=round((k+a)/(d+1),2)
else:
kda=round((k+a)/d,2)
KDA.append(kda)
wc_mg['KDA']=KDA
#单独把选手和KDA提取出来
wc_mg_player_kda=wc_mg.loc[:,['player','KDA']]
#计算每位选手的平均KDA
wc_mg_player_kda=round(wc_mg_player_kda.groupby('player').mean(),2)
wc_mg_player_kda.sort_values(by='KDA',ascending=False,inplace=True)
#正赛中KDA前十的选手
wc_mg_player_kda[:10] 在KDA排名前十的选手中有五位来自我们的LPL赛区,这也再一次证明了我们LPL赛区的实力。
在KDA排名前十的选手中有五位来自我们的LPL赛区,这也再一次证明了我们LPL赛区的实力。
数据建模
在这一部分要做的工作是使用线性判别分析(Linear Discriminant Analysis)来帮我们对数据进行分类。基本思想是:每支队伍都有五个位置,这样就可以把数据分为五类,而数据集中的特征较多使用决策树效果不佳,同时注意到这是一个有监督类的问题,那么我们就可以使用线性判别分析来帮我们解决这类问题。线性判别分析是一种把高维空间的数据投影到低维空间从而更好地进行区分的方法,简单的来说线性判别分析要做的就是使“投影后类内方差最小,类间方差最大”的优化方案。
在使用线性判别分析之前有一个要解决的问题:我们所使用的模型并不认识字符串类型的数据,也就是说机器并不明白文字的意义,所以我们要先帮它翻译成它可以理解的数字。这里就要使用到特征工程中很重要的的方法:编码。常用的编码方法为:定序编码,分箱编码和独热编码。具体问题具体分析,先来看看我们字符串类型的数据都有哪些吧:
#找出原数据集中的object类型字段
object_columns=wc_data.columns[wc_data.dtypes=='object']
#看看object类型字段有哪些
object_columns 通过字面意思大家应该能猜到每个字段分别代表什么,在这当中非常让人疑惑的是‘fbaron’,‘fbarontime’,‘visiblewardclearrate’,‘invisiblewardclearrate’这几项看似应该是整数型或浮点型的数据竟然是字符串类型。于是我就去原数据集中观察了一下,‘fbaron’和‘fbarontime’的数据确实全部是数字类型,而‘visiblewardclearrate’和invisiblewardclearrate‘两个字段下的数据全部为空,但这两个字段在之前处理缺失值时却显示没有缺失值我想可能是因为原数据集中这两个字段下填充是一个‘ ’,也就是空格,所以被当成了字符串类型且没有缺失值。搞清楚了这个问题后我们就可以着手解决了。
通过字面意思大家应该能猜到每个字段分别代表什么,在这当中非常让人疑惑的是‘fbaron’,‘fbarontime’,‘visiblewardclearrate’,‘invisiblewardclearrate’这几项看似应该是整数型或浮点型的数据竟然是字符串类型。于是我就去原数据集中观察了一下,‘fbaron’和‘fbarontime’的数据确实全部是数字类型,而‘visiblewardclearrate’和invisiblewardclearrate‘两个字段下的数据全部为空,但这两个字段在之前处理缺失值时却显示没有缺失值我想可能是因为原数据集中这两个字段下填充是一个‘ ’,也就是空格,所以被当成了字符串类型且没有缺失值。搞清楚了这个问题后我们就可以着手解决了。
#把fbaron和fbarontime两个字段转换成浮点型
wc_data['fbaron']=wc_data['fbaron'].astype(float)
wc_data['fbarontime']=wc_data['fbarontime'].astype(float)
#把date,visiblewardclearrate,invisiblewardclearrate字段删去
wc_data.drop(['date','visiblewardclearrate','invisiblewardclearrate'],axis=1,inplace=True)之所以把date这一列也删去,主要是考虑到这一列对我们模型的分类能力并没有影响。
#再看看现在object类型字段有哪些
object_columns=wc_data.columns[wc_data.dtypes=='object']
object_columns 处理完后的结果显然就符合我们预期了,这时我们就可以考虑编码问题了。通过观察这几个字段,我们会发现这些字段中有几个字段中出现了特别多的不同数据,如:player,champion等,若对这些列进行独热编码我们的数据集会呈现出特别稀疏的状态,这显然不是我们希望看到的,因此我们就使用效果更好的定序编码。(但定序编码也有自己的问题,比如这些字段下的数据并没有明显的优先顺序,但使用定序编码就会出现这个问题,因此在进行数据分析时有时并没有标准答案,更重要的是权衡)
处理完后的结果显然就符合我们预期了,这时我们就可以考虑编码问题了。通过观察这几个字段,我们会发现这些字段中有几个字段中出现了特别多的不同数据,如:player,champion等,若对这些列进行独热编码我们的数据集会呈现出特别稀疏的状态,这显然不是我们希望看到的,因此我们就使用效果更好的定序编码。(但定序编码也有自己的问题,比如这些字段下的数据并没有明显的优先顺序,但使用定序编码就会出现这个问题,因此在进行数据分析时有时并没有标准答案,更重要的是权衡)
#导入LabelEncoder包
from sklearn.preprocessing import LabelEncoder
#使用LabelEncoder把object类型数据编号
le=LabelEncoder()
for each in object_columns:
wc_data[each]=le.fit_transform(wc_data[each])
现在我们已经处理完了数据集,可以开始进行建模了。
#导入模型LDA,分割数据集包,衡量模型效果的accuracy_score
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
clf=LinearDiscriminantAnalysis()
X=wc_data.drop(['position'],axis=1)
y=wc_data['position']
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.3,random_state=0)
clf.fit(X_train,y_train)
result=clf.predict(X_test)
#使用准确率衡量模型效果
accuracy_score(y_test,result)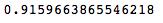 我们使用LDA模型的默认参数(SVD作为solver)得到的准确率是接近92%,这个结果还不错,但是通过参数调整或者对原数据集进一步处理有可能得到更好的结果。
我们使用LDA模型的默认参数(SVD作为solver)得到的准确率是接近92%,这个结果还不错,但是通过参数调整或者对原数据集进一步处理有可能得到更好的结果。
接下来我们对模型做进一步分析,先来看看explained variance ratio,这个结果表明我们训练的LDA模型的各个component对整体的方差解释度。
#看看LDA的各个component的explained varaince ratio
clf.explained_variance_ratio_
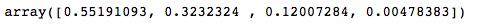 因为我们没有设定LDA模型的n_component参数,所以component的个数是模型自己决定的,也就是n_class-1=5-1=4。在4个component中,最高的解释度为55%,最小的仅为0.4%,这四个解释度加起来的和为1。
因为我们没有设定LDA模型的n_component参数,所以component的个数是模型自己决定的,也就是n_class-1=5-1=4。在4个component中,最高的解释度为55%,最小的仅为0.4%,这四个解释度加起来的和为1。
看过了component对整体方差的解释度,再来看看每个特征对LDA分类起到了多大的作用:
#把各字段的coeffcient做成DataFrame保存起来方便下一步分析
coefficients=pd.DataFrame(clf.coef_)
#找出coefficient最高的三个特征并打印出来
for position in range(0,5):
sorted_coefficient=coefficients.iloc[position,:].sort_values(ascending=False)
columns=wc_data.columns[sorted_coefficient.index[0:3]]
print('Columns with highest coefficient for position ',position,' :',columns)
这里postiontion 0 为ADC,postion 1 为打野,postion 2 为中单,position 3 为辅助,position 4 为上单。
‘dmgshare’:承受伤害比例
‘kpm’:每分钟击杀数
‘airdrake’:风龙击杀数
‘fbtime’:首杀发生时间
‘wardkills’:清除视野数
‘wpm’:每分钟安置视野数
‘wards’:总放置视野数
‘quadras’:四杀次数
‘monsterkillsenemyjungle’:敌方野怪击杀数
这个结果显然不太好理解,像‘airdrakes’,‘quadras’,‘fbtime’这类特征我们显然是不会把它们和某个位置联系起来,而像‘dmgshare’这个特征在对三个位置对分类作用都是最高的,这好像也和我们平常对游戏的理解不太一样。但是也像我之前提到过的,这个模型还有进步的空间,而且我所使用的数据集数据并不是特别充足,如果使用更大的数据集可能效果会更好。于是我就开始思考:如果把我们认为对分类有用的数据放在一起再训练一个模型,会不会准确率比这个模型要高呢?
#把我们认为有用的字段提取成一个新的DataFrame
wc_new=wc_data.loc[:,['position','player','champion','k','d','a','dmgtochamps','dmgshare','wards','minionkills','monsterkills']]
#观察一下新的DataFrame
wc_new.head()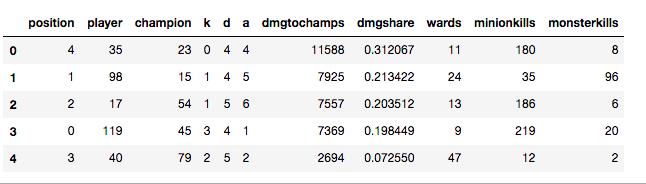 我所使用的都是前面的分析中表现出比较能对位置信息进行区分的字段,我们来看看效果怎么样。
我所使用的都是前面的分析中表现出比较能对位置信息进行区分的字段,我们来看看效果怎么样。
#使用新的DataFrame训练LDA模型
clf=LinearDiscriminantAnalysis()
X=wc_new.drop(['position'],axis=1)
y=wc_new['position']
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.3,random_state=0)
clf.fit(X_train,y_train)
result=clf.predict(X_test)
#观察准确率得分
accuracy_score(y_test,result)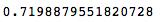 结果出来了,竟然还比之前的模型准确率差不少,这也说明了我们做数据挖掘的意义。在巨大的数据集中使用人的经验或是感觉并不是得到准确结果的最好办法,要在数据中挖掘出有用的宝藏就要善用科学的方法,在数学和统计学的帮助下把看似无用或毫无意义的数据变成辅助我们更好地进行决策的工具。
结果出来了,竟然还比之前的模型准确率差不少,这也说明了我们做数据挖掘的意义。在巨大的数据集中使用人的经验或是感觉并不是得到准确结果的最好办法,要在数据中挖掘出有用的宝藏就要善用科学的方法,在数学和统计学的帮助下把看似无用或毫无意义的数据变成辅助我们更好地进行决策的工具。
写在最后的话
作者能力有限,本文中难免有错误或纰漏,希望各位读者可以及时指出
希望各位可以对本篇提出宝贵意见
转载请注明出处
以上是关于英雄联盟数据分析专题的主要内容,如果未能解决你的问题,请参考以下文章