VIVADO HLS循环语句的优化
Posted 朽月
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了VIVADO HLS循环语句的优化相关的知识,希望对你有一定的参考价值。
VIVADO HLS循环语句的优化
- 参考文献
- 项目描述
- for循环的衡量指标
- 对for循环设置Pipeline操作
- 对for循环设置Unrolling操作
- for循环的合并
- for循环的优化——dataflow
- 嵌套for循环的优化方法
- for循环优化的其他方法
- 总结
参考文献
[1]、lauren的FPGA(微信公众号)
[2]、Xilinx暑期学校
项目描述
有软件基础的同学应该知道程序的两个衡量指标是时间复杂度与空间复杂度,与我们FPGA中的最大时钟频率与资源相对应。时间复杂度的体现形式是循环的结构,这也是主要时间消耗的地方。那么,对于使用VIVADO HLS工具进行进一步的编译,程序的时间延迟也会主要体现在循环语句中。所以,我们只要使用HLS对软件的循环语句添加一定的约束,便很可能取到我们要求的指标。这篇博客主要介绍各种循环语句的优化,进而减少FPGA侧的资源与始终延迟。
循环的主要优化措施有Pipeline、Unrolling。
for循环的衡量指标
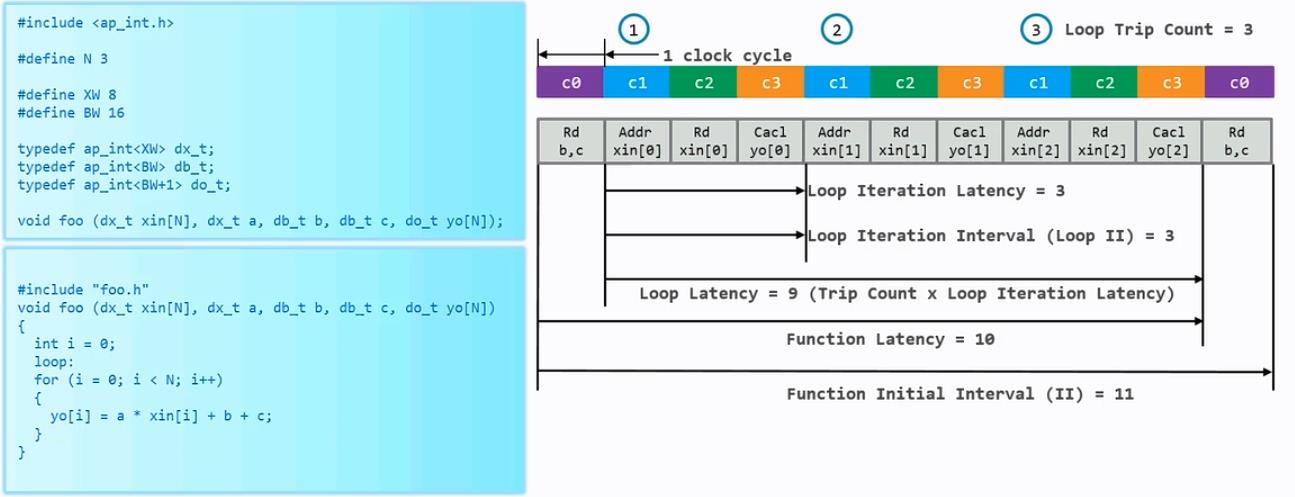
衡量一个for循环的指标有:
1、Loop Iteration Latency :C函数中的for循环每迭代一次需要多少时钟周期。
2、Loop Iteration Interval(Loop II):本次循环开始到下一次循环开始所需要的周期数。
3、Loop Latency :完成整个循环需要多少个时钟周期。
4、Loop Trip Count : for循环的循环迭代的次数。
举一个例子如下:
对for循环设置Pipeline操作
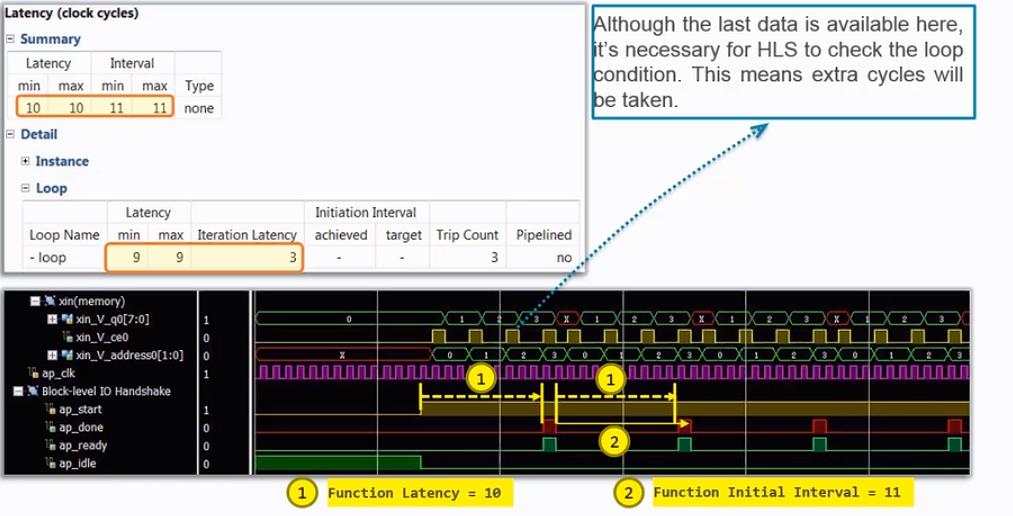
还是以上面的例子添加了Pipeline的约束,如下:
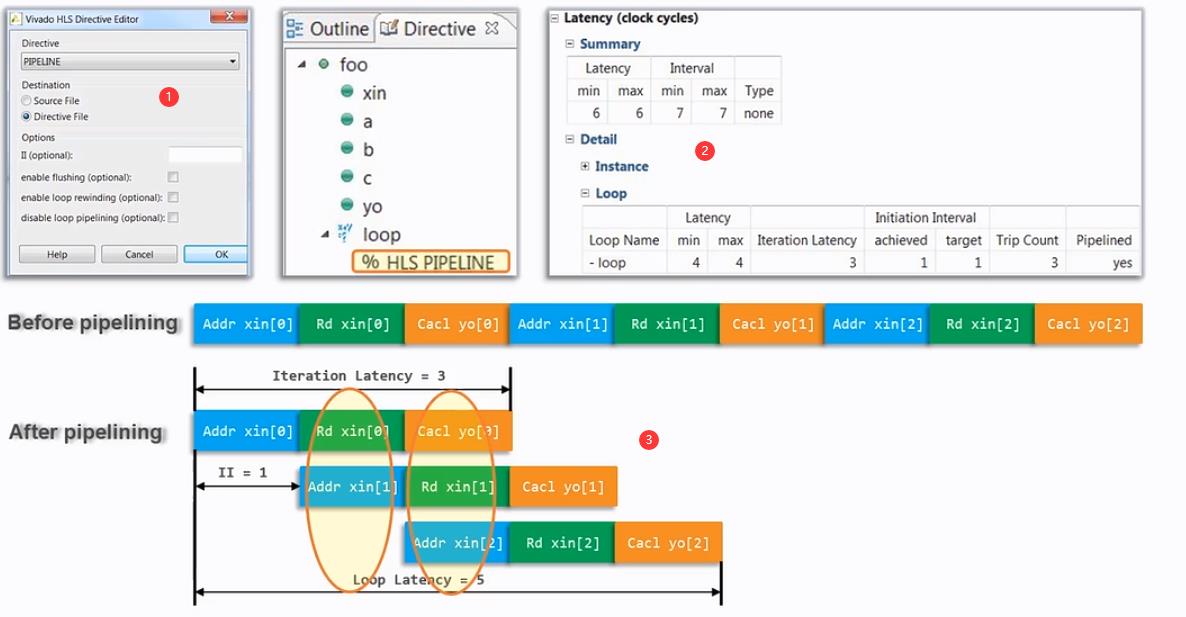
1、添加Pipeline约束的方法。
2、添加Pipeline约束进行性能优化之后的性能指标。
3、为什么添加Pipeline可以减少for循环的指标。
对for循环设置Unrolling操作
在默认的情况下for循环是被折叠的,可以理解for循环每次迭代都使用了同一套电路,所谓展开就是电路被复制了n份。
举例如下:

由上图可知,for循环的迭代被复制了三份,消耗的资源量如下:

1、Unroll的设置方法。
2、消耗的资源量。
for循环的合并
对于两个完全并列的for循环约束方法——合并for循环
举一个例子如下:

for循环综合后的结果是:


然而我们想要的综合后的结构如下:
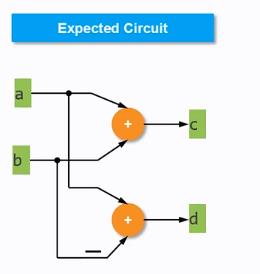
那么进行约束的方法就是进行for循环合并,进行for循环合并的方法就是:
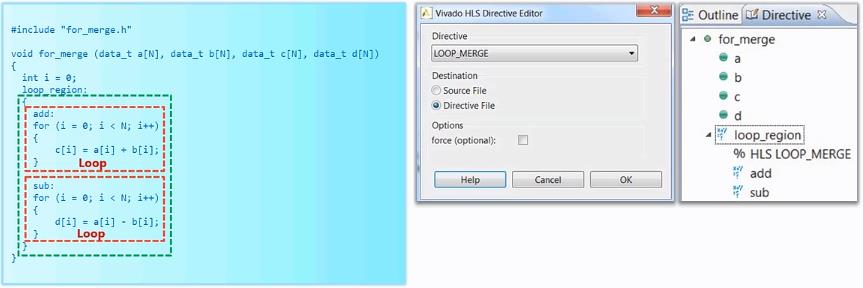
1、先将两个for循环引入一个loop region区域。
2、然后对这个区域加LOOP_MERGE约束。
具体方法如下:
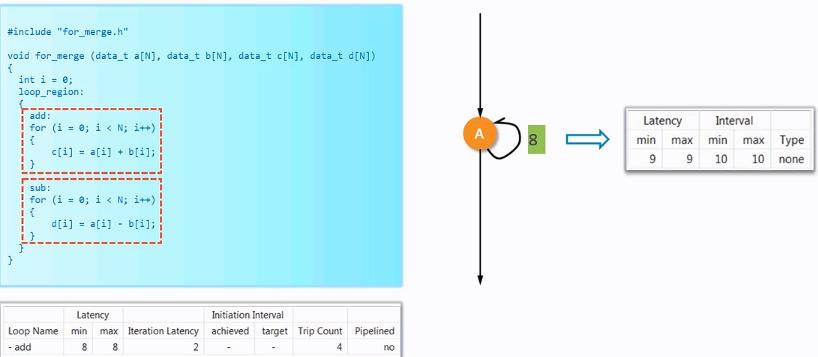
合并之后的结果如下:
对于并列for循环的循环边界为不同常数的循环合并
对于两个for循环的循环边界不一致的情况下,进行合并,外部的时间延迟会按照大的循环边界进行设置,如下:

对于并列for循环的循环边界一个为常数一个为变量的合并
如果直接进行合并,将会报告错误信息,如下:

在这个例子中N为常数,K为变量。
1、两个并列的for循环进行约束
2、进行LOOP_MERGE之后的报错信息
所以for循环中有一个常数,一个变量没法直接进行合并
对于并列for循环的循环边界两个均为变量的合并
遇上一个例子形同,同样会报错:

在这个例子中J,K均为变量。
解决方案,假设K<J,则可以进行下面的改善:
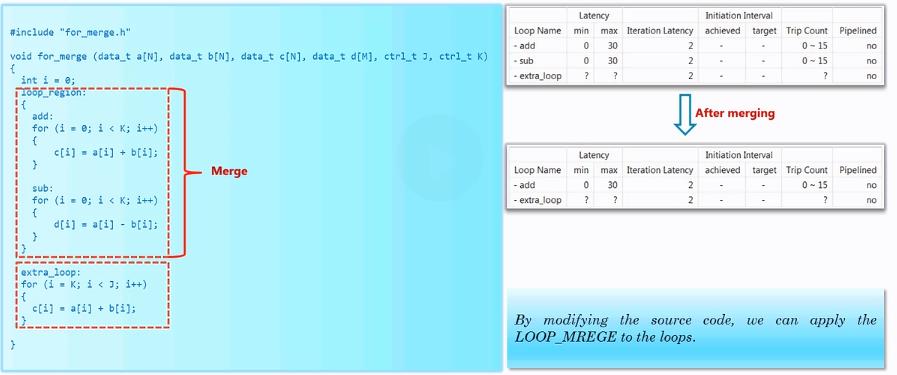
其实就是将下面的for循环进行拆开,同理如果for循环的循环边界一个是常数、一个是变量满足N<K的情况下也可以进行这样的约束。
for循环的优化——dataflow
前面已经讲解过for循环之间没有依赖关系的我们可以对for循环施加LOOP_MERGE约束。那么,for循环之间有依赖关系,我们应该如何操作呢?答案就是进行dataflow操作,举例如下:

默认的执行结果如下:
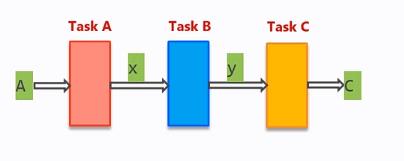
因为for循环之间的依赖性,那么这三个for循环之间不允许进行。
所以我们会对上面的for循环施加dataflow约束,那么dataflow为什么可以较少延迟:
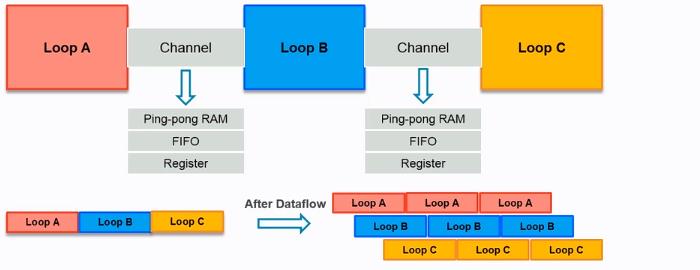
从上面可以看出只要循环有交叠,那么便可以节省for循环的时间。进行约束的方法与约束后的资源报告如下:
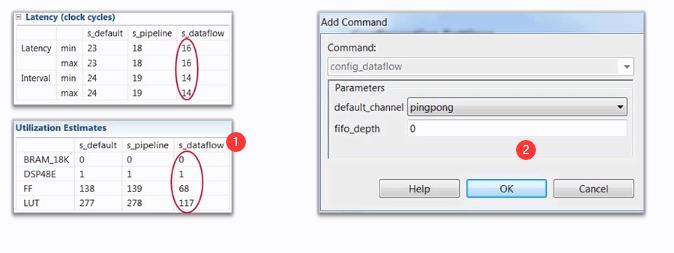
1、资源报告。
2、设置for循环之间的缓存是fifo、ram、pingpang等等操作。
for循环的结果被另外多个for循环使用,为了使用dataflow解决办法
下面的例子不能使用dataflow优化,以为第一层的for循环被后两层均使用:

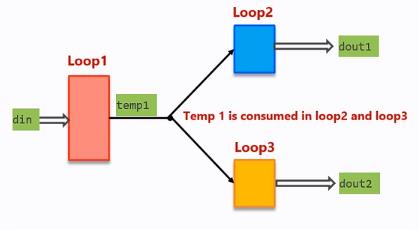
但是这个例子,可以施加Pipeline约束,Loop2与Loop3两个for循环可以进行合并。
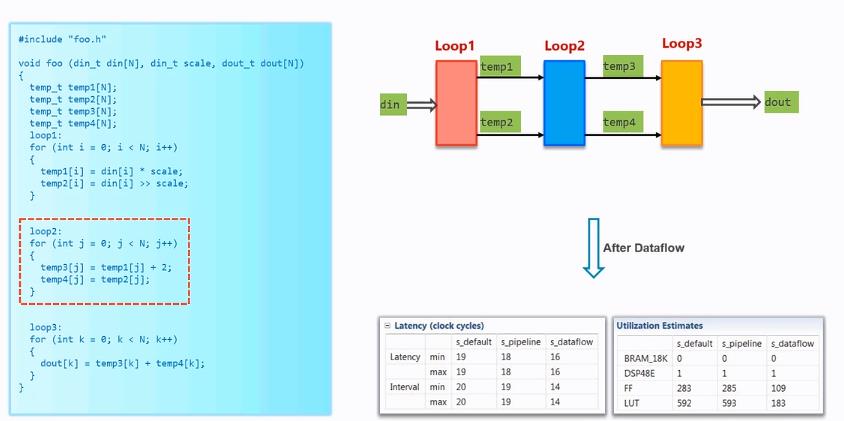
为了使上面的例子可以进行for循环的dataflow优化,采用的办法如下:

1、代码改善。
2、为什么可以使用dataflow的原理。
3、使用dataflow之后的资源对比结果。
另一个不能使用dataflow的例子及解决办法
例子如下:

1、程序代码。
2、为什么不能使用dataflow约束。
解决办法如下:
嵌套for循环的优化方法
VIVADO HLS中for循环的分类:

对于Imperfect loop我们希望经过一些代码优化的手段将其装换成Perfect loop与 Semi-Perfect loop。
Perfect loop的例子

上面的是分别对内部for循环与外部外部for循环进行Pipeline操作,由上面可见,对外部for循环进行Pipeline操作所获得的时钟延迟更少,因为对外部for循环Pipeline操作,默认内部进行了展开操作。
Imperfect loop的例子
以矩阵乘法为例进行进一步的说明,例子如下,
对最内层for循环进行Pipeline操作:
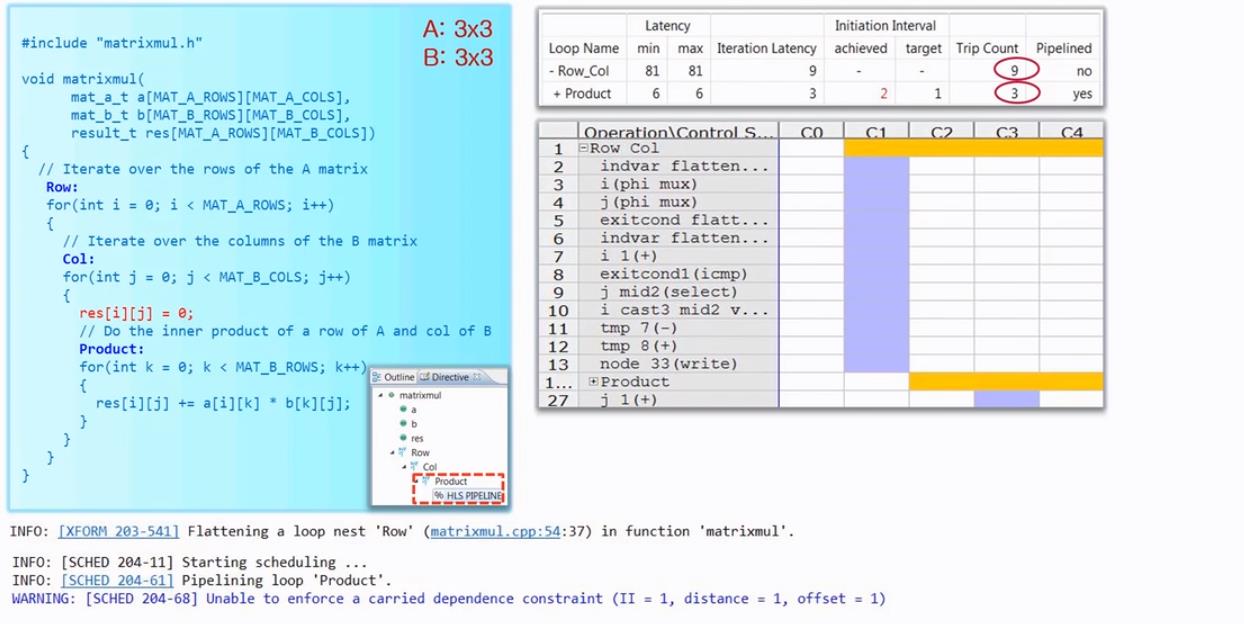
对第二层for循环进行Pipeline操作:
注意这里最内层的for循环被展开。
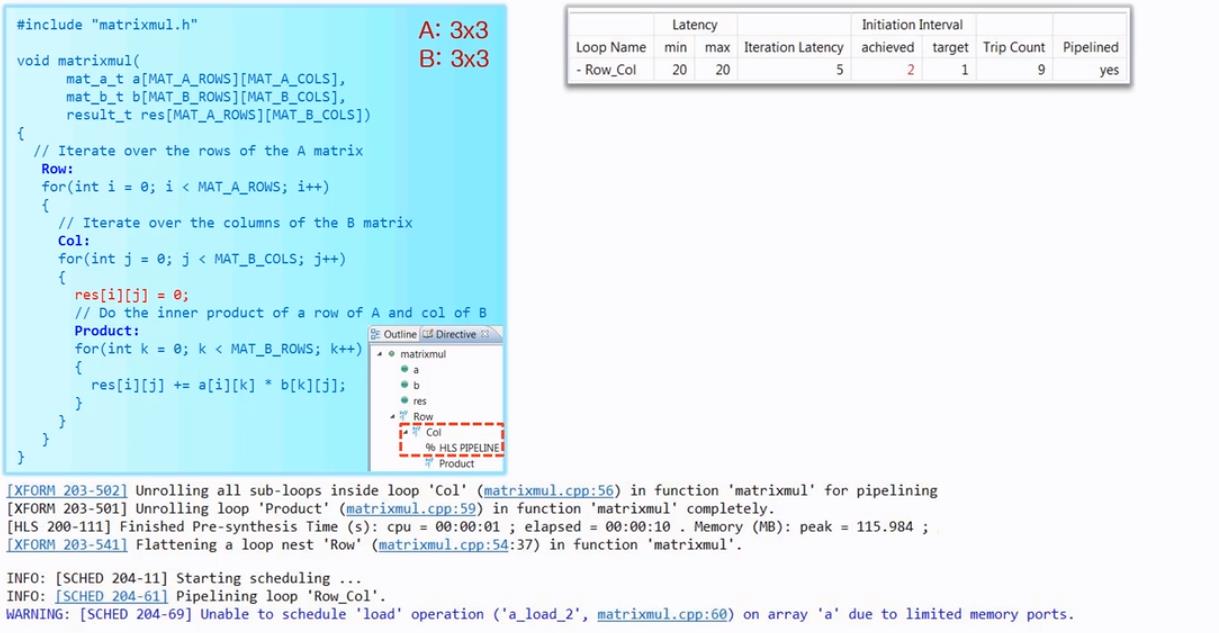
对最外层的for循环进行流水:

可以看到最内层的for循环被展开。
对整个函数进行流水操作:
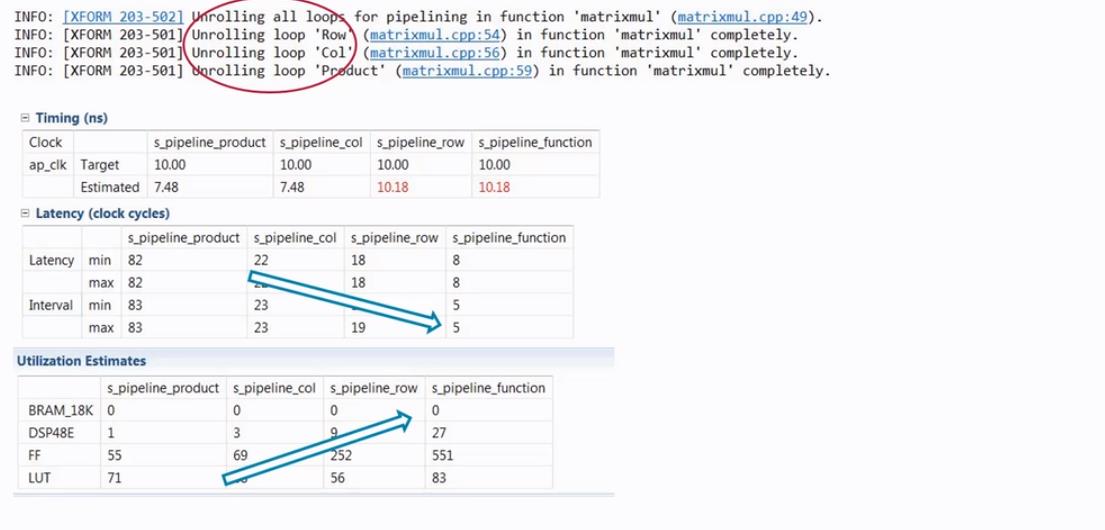
该代码的优化原理:

相应的代码如下:

通常是对最内层的for循环做流水操作,这样在资源与始终延迟之间的均衡较好。
for循环优化的其他方法
先将for循环封装成函数,再将函数复制并行执行
进行函数复制的命令是HLS_ALLOCATION命令。
例子如下:

对for循环执行rewined操作
可以使得Pipeline操作下一次的输入也流水起来,原理如下:

例子如下:

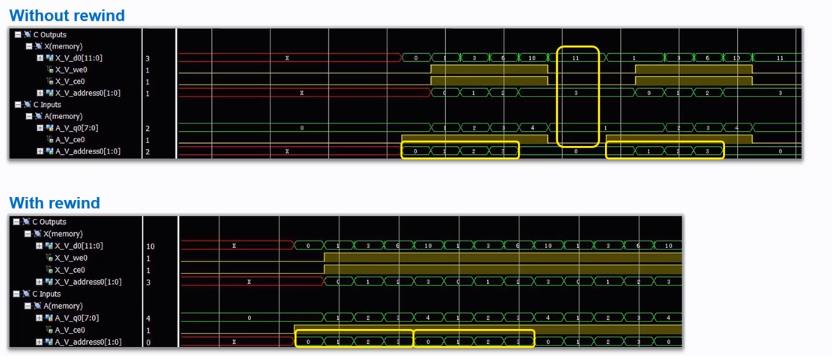
如果一个函数包括了多个for循环,就没办法执行rewined操作。
自动对for循环添加流水

如何处理循环边界时变量的情景
例子如下:
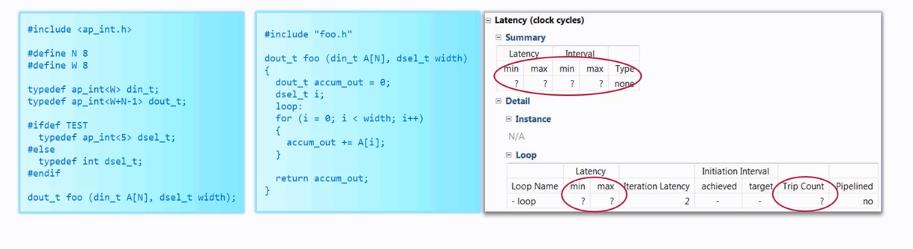
1、采用Tripcount方式
该方式可以直接指定Tripcount的最大值和最小值

但是这种方法不会对设计做任何的优化,只是用于报告的显示。
2、将循环边界的变量声明成ap_int类型
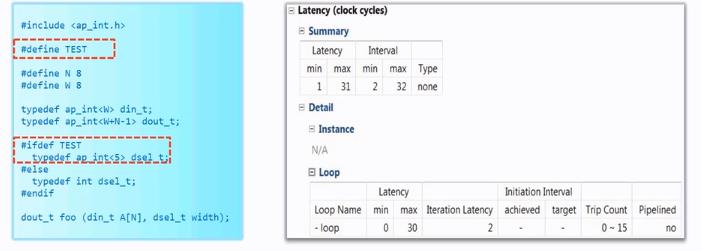
该方法会改善VIVADO HLS的编译结果,编译之后的结果如下:
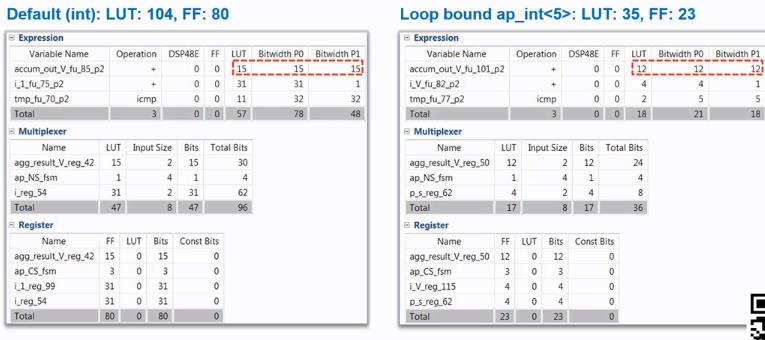
可以看出来,上面的编译结果得到了极大程度的改善。
3、在C++语言中使用assert进行判断方位,如下:

上面的方法也对设计进行了优化,如下:
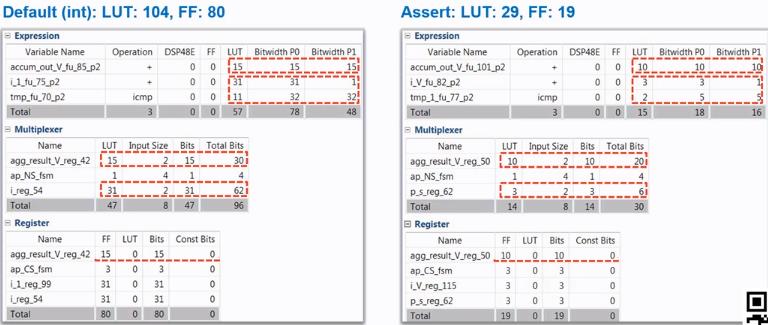
该方法的范围最精细,使用的资源与latency也最好。
总结
创作不易,认为文章有帮助的同学们可以关注、点赞、转发支持。为行业贡献及其微小的一部分。对文章有什么看法或者需要更近一步交流的同学,可以加入下面的群:

以上是关于VIVADO HLS循环语句的优化的主要内容,如果未能解决你的问题,请参考以下文章