推荐系统_关联规则挖掘
Posted 漠小浅
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了推荐系统_关联规则挖掘相关的知识,希望对你有一定的参考价值。
购物篮分析(关联规则挖掘,频繁规则挖掘)
名词解释:
挖掘数据集(事务数据集,交易数据集):购物篮数据
频繁模式:频繁地出现在数据集中的模式,例如项集,子结构,子序列等
挖掘目标:频繁模式,频繁项集,关联规则等
关联规则:牛奶=》鸡蛋【支持度=2%,置信度=60%】
支持度:分析中的全部事物的2%同时购买了牛奶和鸡蛋
置信度:购买了牛奶的筒子有60%也购买了鸡蛋
最小支持度阈值和最小置信度阈值:由挖掘者或领域专家设定
项集:项(商品)的集合
k-项集:k个项组成的集合
频繁项集:满足最小支持度的项集,频繁k-项集一般记为Lk
强关联规则:满足最小支持度阈值和最小置信度阈值的规则
我感觉:主要就是挖掘频繁模式或者频繁项集(频繁项集是频繁模式的一种),进而找到关联规则。
关联规则挖掘:Apriori算法
两步过程:找出所有频繁项集;由频繁项集产生强关联规则
算法:Apriori
例子:
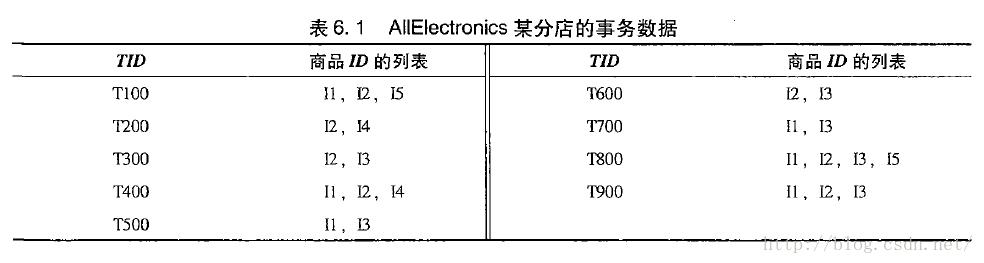
Apriori算法的工作过程:
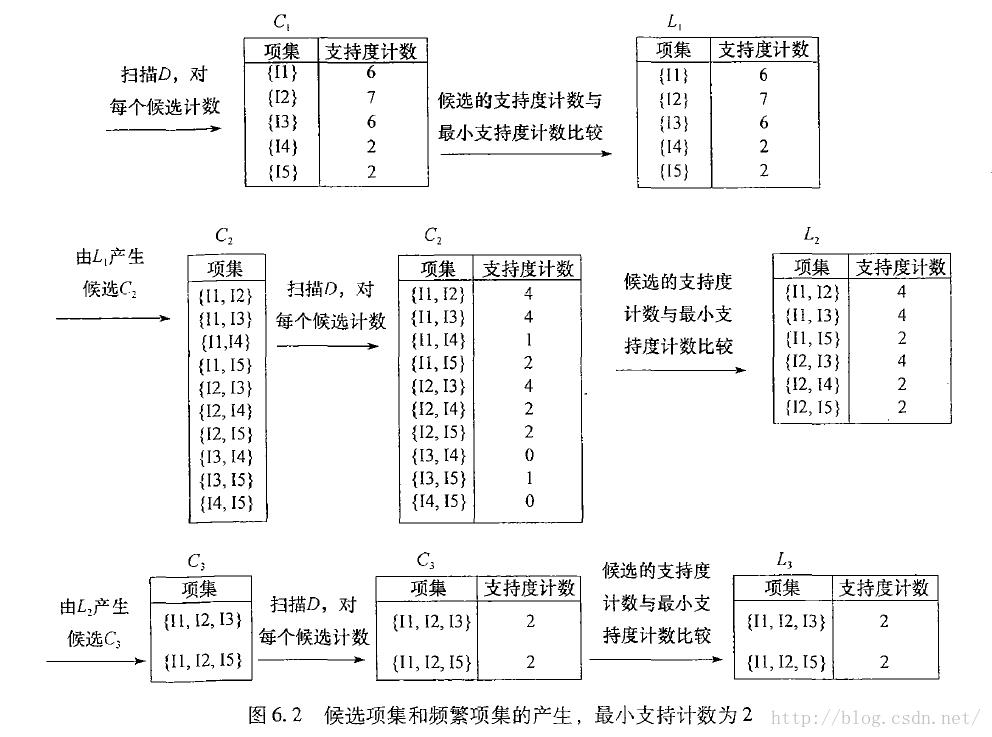
步骤说明:
扫描D,对每个候选项计数,生成候选1-项集C1
定义最小支持度阈值为2,从C1生成频繁1-项集L1
通过L1xL1生成候选2-项集C2
扫描D,对C2里每个项计数,生成频繁2-项集L2
计算L3xL3,利用apriori性质:频繁项集的子集必然是频繁的,我们可以删去一部分项,从而得到C3,由C3再经过支持度计数生成L3
可见Apriori算法可以分成连接,剪枝两个步骤不断循环重复

由频繁项集提取关联规则:
例子:我们计算出频繁项集I1,I2,I5,能提取哪些规则?
I1^I2=>I5,由于I1,I2,I5出现了2次,I1,I2出现了4次,故置信度为2/4=50%
类似可以算出

算法的缺点:L1到C2是笛卡尔积,如果L1比较大,C2难以想象,如果要控制L1较小,则需要提高支持度。有时候不需要提交支持度,那怎么样进行优化呢?
提高Apriori的效率:
基于散列的算法(基本不用,不做讲解)
基于FP tree的算法(如下)
TP树:
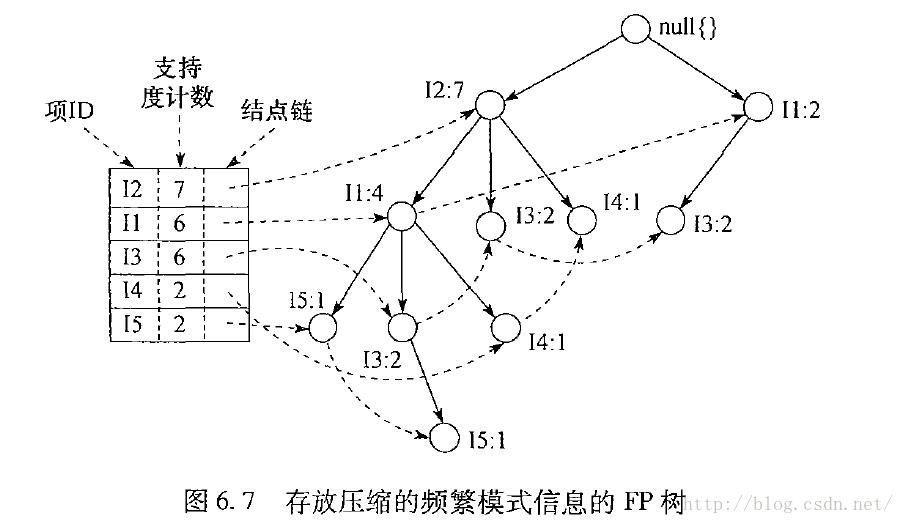
挖掘过程图示:

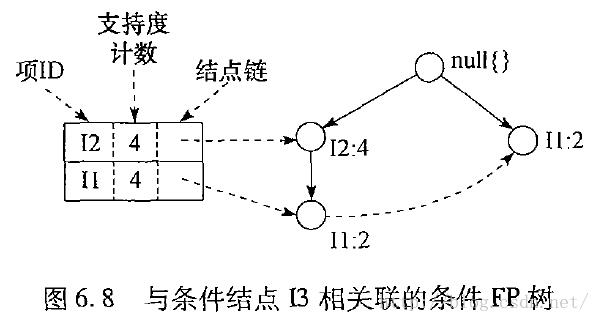
FP-Growth算法伪代码:

FPGrowth算法出来以后,因为他很耗内存(建立树),一台机器的内存可能不够,所以我们如果能把他分散在多台计算机里面计算的话,那么可以减少我们计算的复杂程度,
进而诞生出了PFP
分布式FP-Growth

如果reduce阶段采用上述,reduce阶段数据量一样会非常大,一样没有解决问题,若果吧reduce的任务放在多个机器上,会有多台机器之间的交互(数据丢失,交互),也没有解决问题,可以采用映射的方式,机器直接也不会数据存在丢失或者交互。如下步骤(G-List):
主要步骤:
将数据集分片
计数,产生排序的F-List
将物品分组,产生G-List(这个样子可以导致reduce在许多台机器上同时运行)
(PFP算法关键步骤)并行FP-Growth过程
聚合结果
应用:网页中的最佳拍档:如下所示:
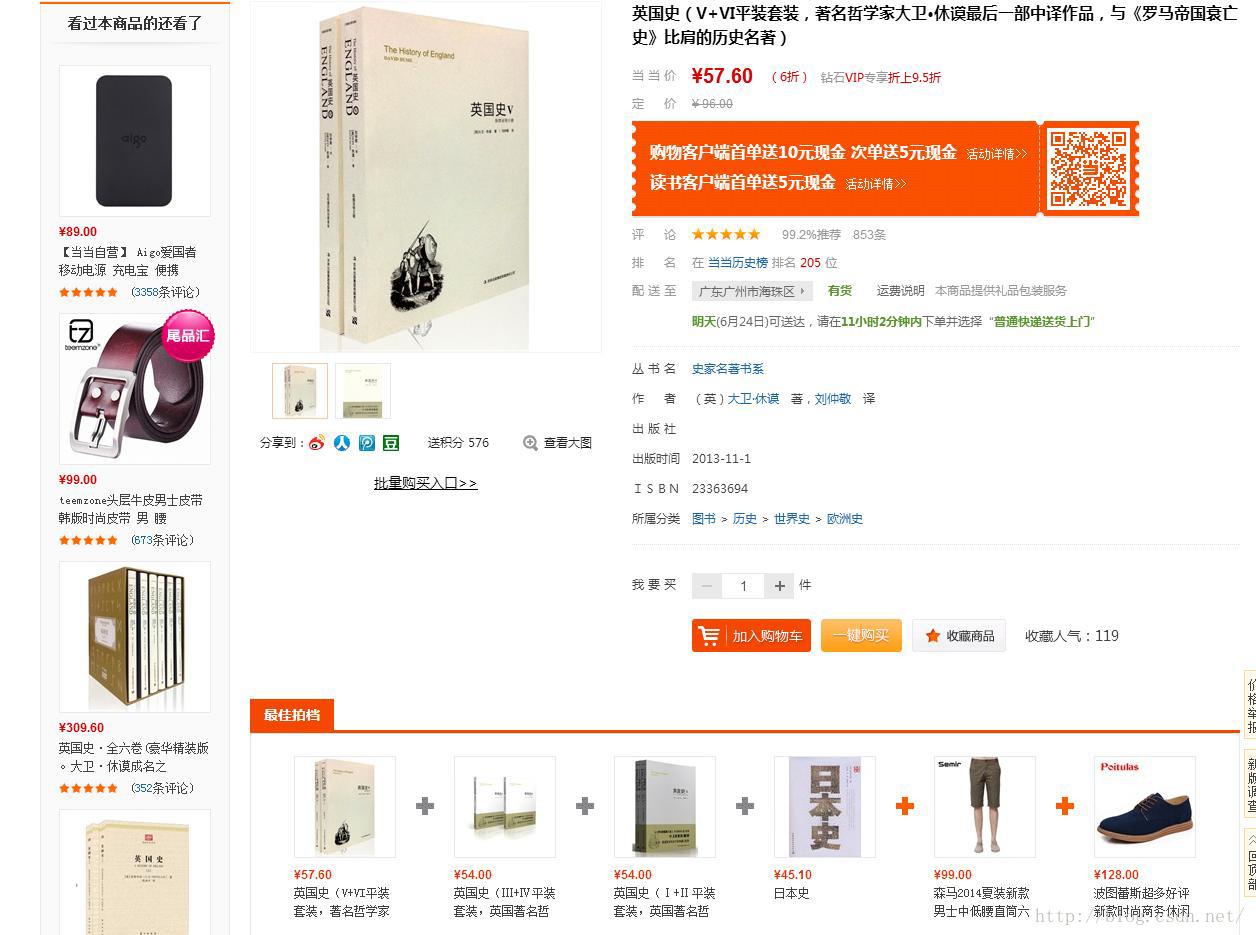
用户行为的一些思量:
互斥的商品,例如同类的自行车,汽车,内容相近的书籍,此时不能使用套餐推荐
推荐相近商品的时候使用浏览记录,使用购买记录更类似于关联规则挖掘
考虑兴趣的时效性,例如已经购买了某种自行车,就没必要再向用户推荐相近的自行车
总结一下:当我们推荐相近商品的时候,最好可以使用浏览记录来进行推荐,使用基于物品的协同过滤算法;
如果要推荐套餐的话,最好是基于购买记录,购物篮分析,用关联模式挖掘(关联规则挖掘)。
以上是关于推荐系统_关联规则挖掘的主要内容,如果未能解决你的问题,请参考以下文章