记一次d2l_softmax回归中的错误
Posted 量子智能龙哥
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了记一次d2l_softmax回归中的错误相关的知识,希望对你有一定的参考价值。
错误代码与现象分析
def train_epoch_ch3(net, train_iter, loss, updater): #@save
"""训练模型一个迭代周期"""
# 将模型设置为训练模式
if isinstance(net, torch.nn.Module):
net.train()
# 训练损失总和、训练准确度总和、样本数
metric = Accumulator(3)
for X, y in train_iter:
# 计算并更新梯度
y_hat = net(X)
l = loss(y_hat, y)
# 如果是pytorch的优化器
if isinstance(updater, torch.optim.Optimizer):
# 使用Pytorch内置的优化器和损失函数
updater.zero_grad()
l.sum().backward()
updater.step()
else:
# 使用定制的优化器和损失函数
l.sum().backward()
updater(X.shape[0]) # X.shape[0] 就是指批量的大小,X是一个大的Tensor 18个小的Tensor每个小的Tensor代表一个图片
metric.add(float(l.sum()), accuracy(y_hat, y), y.numel())
# 损失/样本数 分类正确的数目/样本数
return metric[0] / metric[2], metric[1] / metric[2]训练的结果
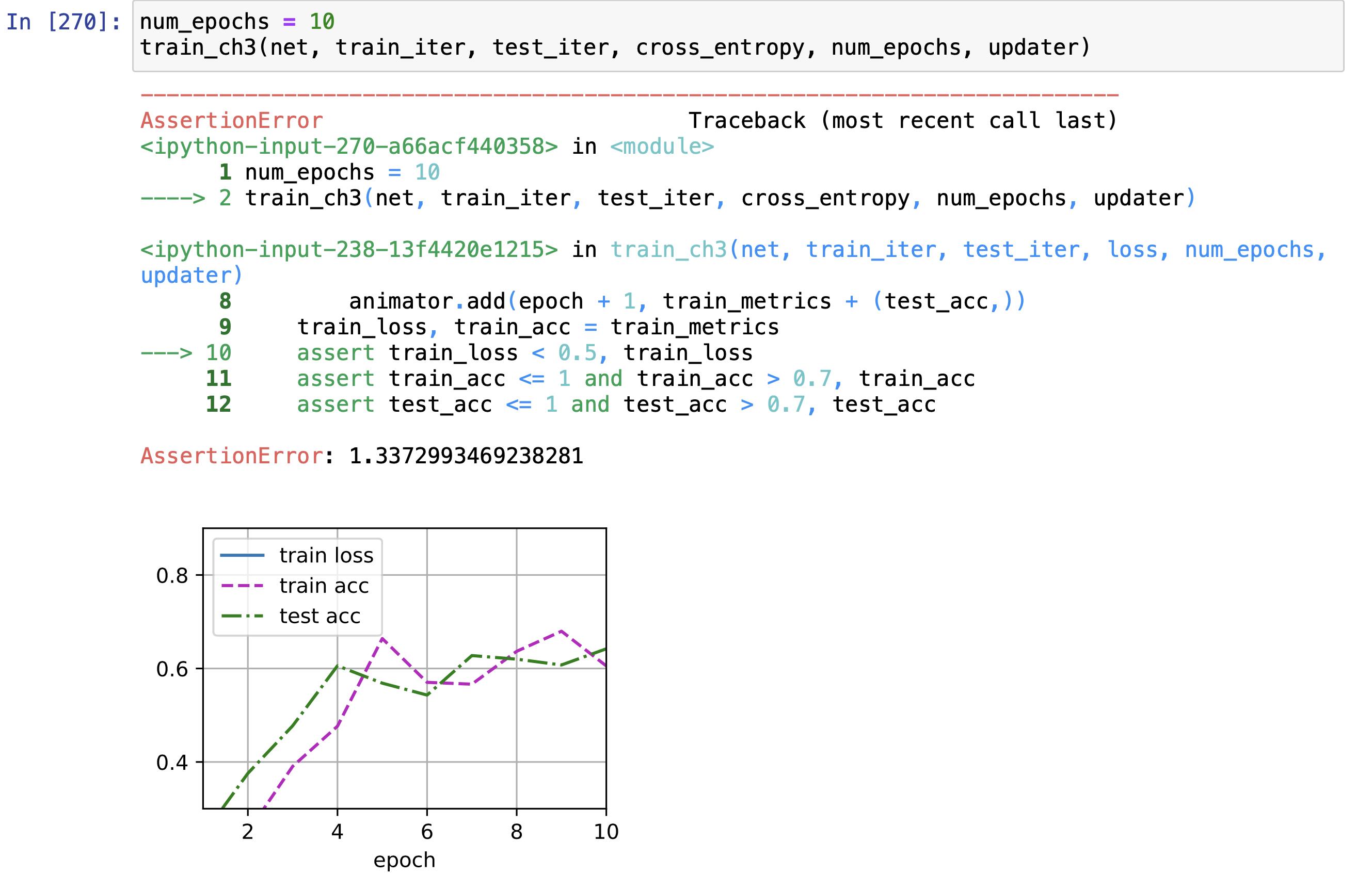
模型的精度停留在0.6附近,事实上等价于进行了一次模型调整 ,因为把return写到了for循环里面了!这是个低级错误,导致每一次epoch都在做同一件事情(独立)return的内容都是当前独立的epoch的模型精度的显示。
修正之后
def train_epoch_ch3(net, train_iter, loss, updater): #@save
"""训练模型一个迭代周期"""
# 将模型设置为训练模式
if isinstance(net, torch.nn.Module):
net.train()
# 训练损失总和、训练准确度总和、样本数
metric = Accumulator(3)
for X, y in train_iter:
# 计算并更新梯度
y_hat = net(X)
l = loss(y_hat, y)
# 如果是pytorch的优化器
if isinstance(updater, torch.optim.Optimizer):
# 使用Pytorch内置的优化器和损失函数
updater.zero_grad()
l.sum().backward()
updater.step()
else:
# 使用定制的优化器和损失函数
l.sum().backward()
updater(X.shape[0]) # X.shape[0] 就是指批量的大小,X是一个大的Tensor 18个小的Tensor每个小的Tensor代表一个图片
metric.add(float(l.sum()), accuracy(y_hat, y), y.numel())
# 损失/样本数 分类正确的数目/样本数
return metric[0] / metric[2], metric[1] / metric[2]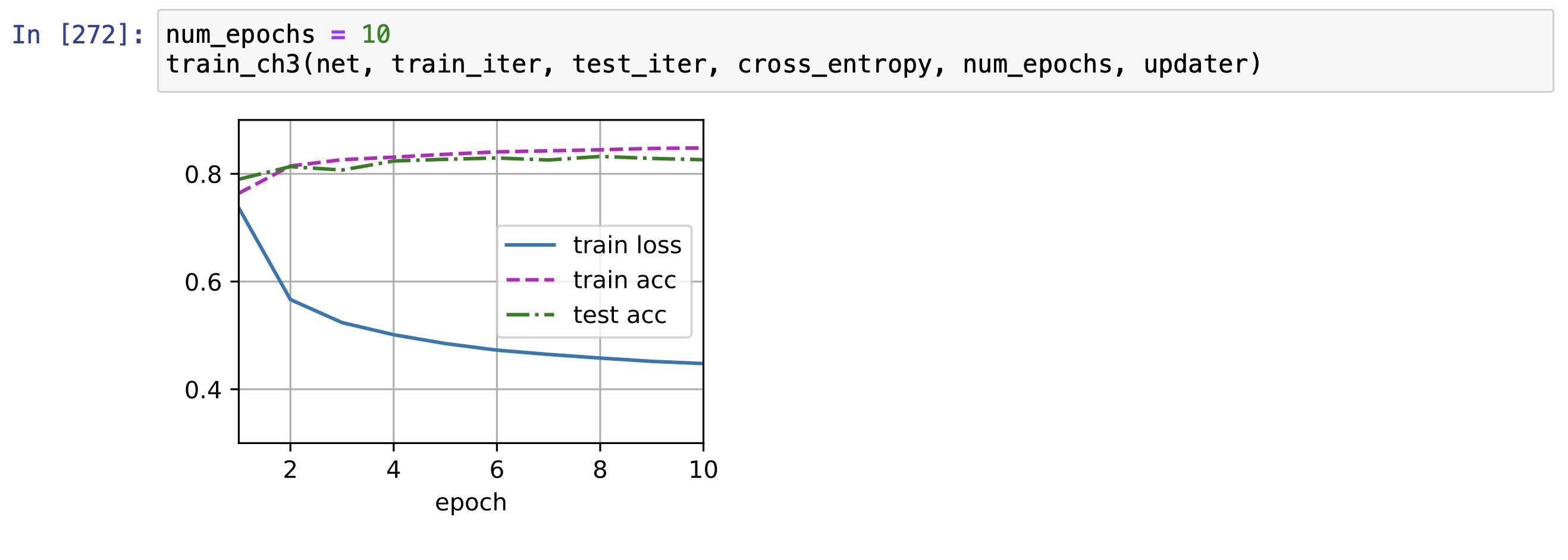
完美解决!
本质上是Py的语法不够熟悉。
以上是关于记一次d2l_softmax回归中的错误的主要内容,如果未能解决你的问题,请参考以下文章