7 个有用的 PyTorch 技巧
Posted spearhead_cai
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了7 个有用的 PyTorch 技巧相关的知识,希望对你有一定的参考价值。
原文:https://www.reddit.com/r/MachineLearning/comments/n9fti7/d_a_few_helpful_pytorch_tips_examples_included/
原文标题:a_few_helpful_pytorch_tips_examples_included
译文作者:kbsc13
联系方式:
Github:https://github.com/ccc013/AI_algorithm_notes
知乎专栏:机器学习与计算机视觉,AI 论文笔记
微信公众号:AI 算法笔记
前言
这是在国外的论坛 reddit 的机器学习版块,有人总结了大概 7 个有用的 PyTorch 技巧,并且还附带了 colab 的代码例子和视频,代码和视频链接分别如下:
代码:https://colab.research.google.com/drive/15vGzXs_ueoKL0jYpC4gr9BCTfWt935DC?usp=sharing
视频:https://youtu.be/BoC8SGaT3GE
视频也同步上传到我的 b 站上,链接如下:
https://www.bilibili.com/video/BV1YK4y1A7KM/
另外代码和视频可以在我的公众号后台回复"12"获取。
1. 直接在目标设备上创建 Tensors
第一个技巧就是使用 device 参数直接在目标设备上创建张量,这里分别演示了两种做法的运行时间,
第一种是先在 cpu 上创建 tensors,然后用.cuda() 移动到 GPU 上,代码如下所示:
start_time = time.time()
for _ in range(100):
# Creating on the CPU, then transfering to the GPU
cpu_tensor = torch.ones((1000, 64, 64))
gpu_tensor = cpu_tensor.cuda()
print('Total time: :.3fs'.format(time.time() - start_time))
第二种则是直接在目标设备上创建张量,代码如下所示:
start_time = time.time()
for _ in range(100):
# Creating on GPU directly
cpu_tensor = torch.ones((1000, 64, 64), device='cuda')
print('Total time: :.3fs'.format(time.time() - start_time))
两种方法的运行时间如下所示:

可以看到直接在目标设备创建 Tensors 的速度是非常快速的;
2. 尽可能使用 Sequential 层
第二个技巧就是采用Sequential 层来让代码看起来更加简洁。
第一种搭建网络模型的代码如下:
class ExampleModel(nn.Module):
def __init__(self):
super().__init__()
input_size = 2
output_size = 3
hidden_size = 16
self.input_layer = nn.Linear(input_size, hidden_size)
self.input_activation = nn.ReLU()
self.mid_layer = nn.Linear(hidden_size, hidden_size)
self.mid_activation = nn.ReLU()
self.output_layer = nn.Linear(hidden_size, output_size)
def forward(self, x):
z = self.input_layer(x)
z = self.input_activation(z)
z = self.mid_layer(z)
z = self.mid_activation(z)
out = self.output_layer(z)
return out
其运行效果如下:

而采用 Sequential 来搭建网络模型的写法如下所示:
class ExampleSequentialModel(nn.Module):
def __init__(self):
super().__init__()
input_size = 2
output_size = 3
hidden_size = 16
self.layers = nn.Sequential(
nn.Linear(input_size, hidden_size),
nn.ReLU(),
nn.Linear(hidden_size, hidden_size),
nn.ReLU(),
nn.Linear(hidden_size, output_size))
def forward(self, x):
out = self.layers(x)
return out
其运行效果如下:

可以看到用 nn.Sequential 来搭建网络模型的代码是更加的简洁。
3. 不要使用列表来存放网络层
第三个技巧是不建议使用列表来存放创建的网络层,因为 nn.Module 类不能成功注册他们。相反,应该把列表传入到nn.Sequential 中。
首先是展示一个错误的例子:
class BadListModel(nn.Module):
def __init__(self):
super().__init__()
input_size = 2
output_size = 3
hidden_size = 16
self.input_layer = nn.Linear(input_size, hidden_size)
self.input_activation = nn.ReLU()
# Fairly common when using residual layers
self.mid_layers = []
for _ in range(5):
self.mid_layers.append(nn.Linear(hidden_size, hidden_size))
self.mid_layers.append(nn.ReLU())
self.output_layer = nn.Linear(hidden_size, output_size)
def forward(self, x):
z = self.input_layer(x)
z = self.input_activation(z)
for layer in self.mid_layers:
z = layer(z)
out = self.output_layer(z)
return out
bad_list_model = BadListModel()
print('Output shape:', bad_list_model(torch.ones([100, 2])).shape)
gpu_input = torch.ones([100, 2], device='cuda')
gpu_bad_list_model = bad_list_model.cuda()
print('Output shape:', bad_list_model(gpu_input).shape)
上述写法在打印第二句的时候,会报错:
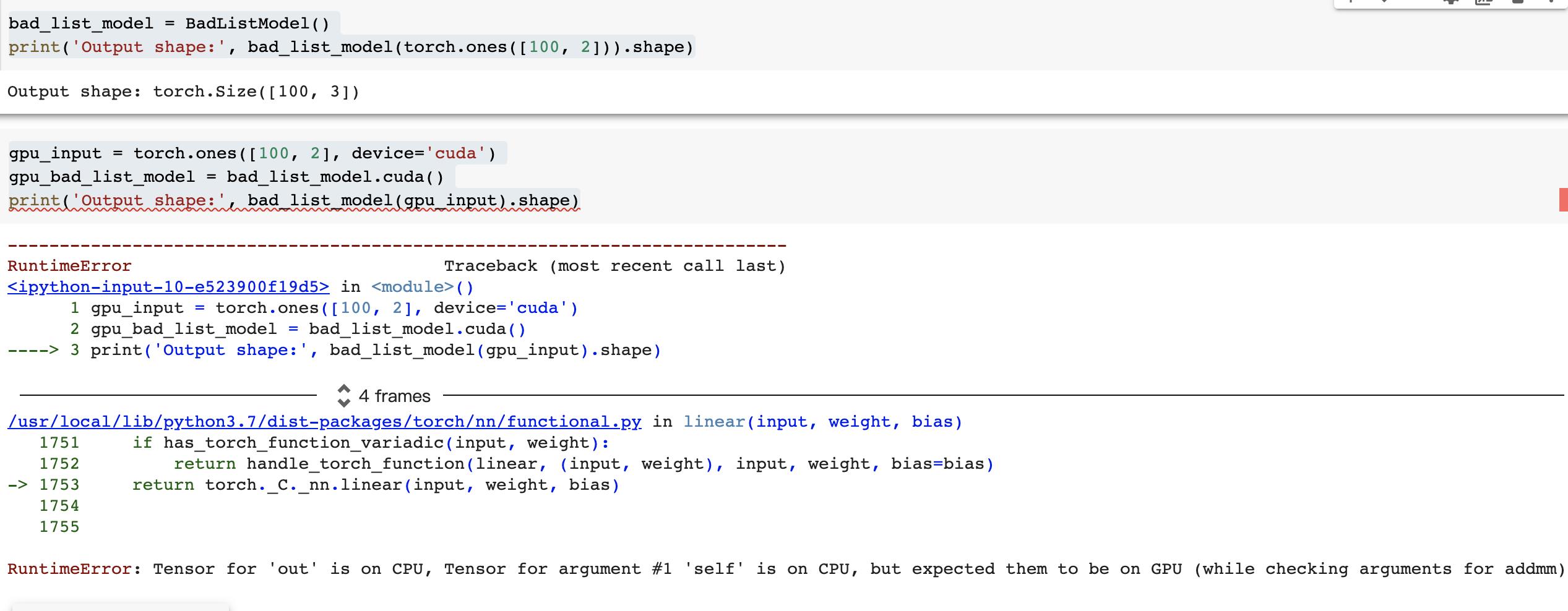
正确的写法:
class CorrectListModel(nn.Module):
def __init__(self):
super().__init__()
input_size = 2
output_size = 3
hidden_size = 16
self.input_layer = nn.Linear(input_size, hidden_size)
self.input_activation = nn.ReLU()
# Fairly common when using residual layers
self.mid_layers = []
for _ in range(5):
self.mid_layers.append(nn.Linear(hidden_size, hidden_size))
self.mid_layers.append(nn.ReLU())
self.mid_layers = nn.Sequential(*self.mid_layers)
self.output_layer = nn.Linear(hidden_size, output_size)
def forward(self, x):
z = self.input_layer(x)
z = self.input_activation(z)
z = self.mid_layers(z)
out = self.output_layer(z)
return out
correct_list_model = CorrectListModel()
gpu_input = torch.ones([100, 2], device='cuda')
gpu_correct_list_model = correct_list_model.cuda()
print('Output shape:', correct_list_model(gpu_input).shape)
其打印结果:

4. 好好使用 distributions
第四个技巧是PyTorch 的 torch.distributions 库中有一些很棒的对象和方法来实现分布式,但是并没有得到很好地使用,官方文档链接:
https://pytorch.org/docs/stable/distributions.html
下面是一个使用的例子:
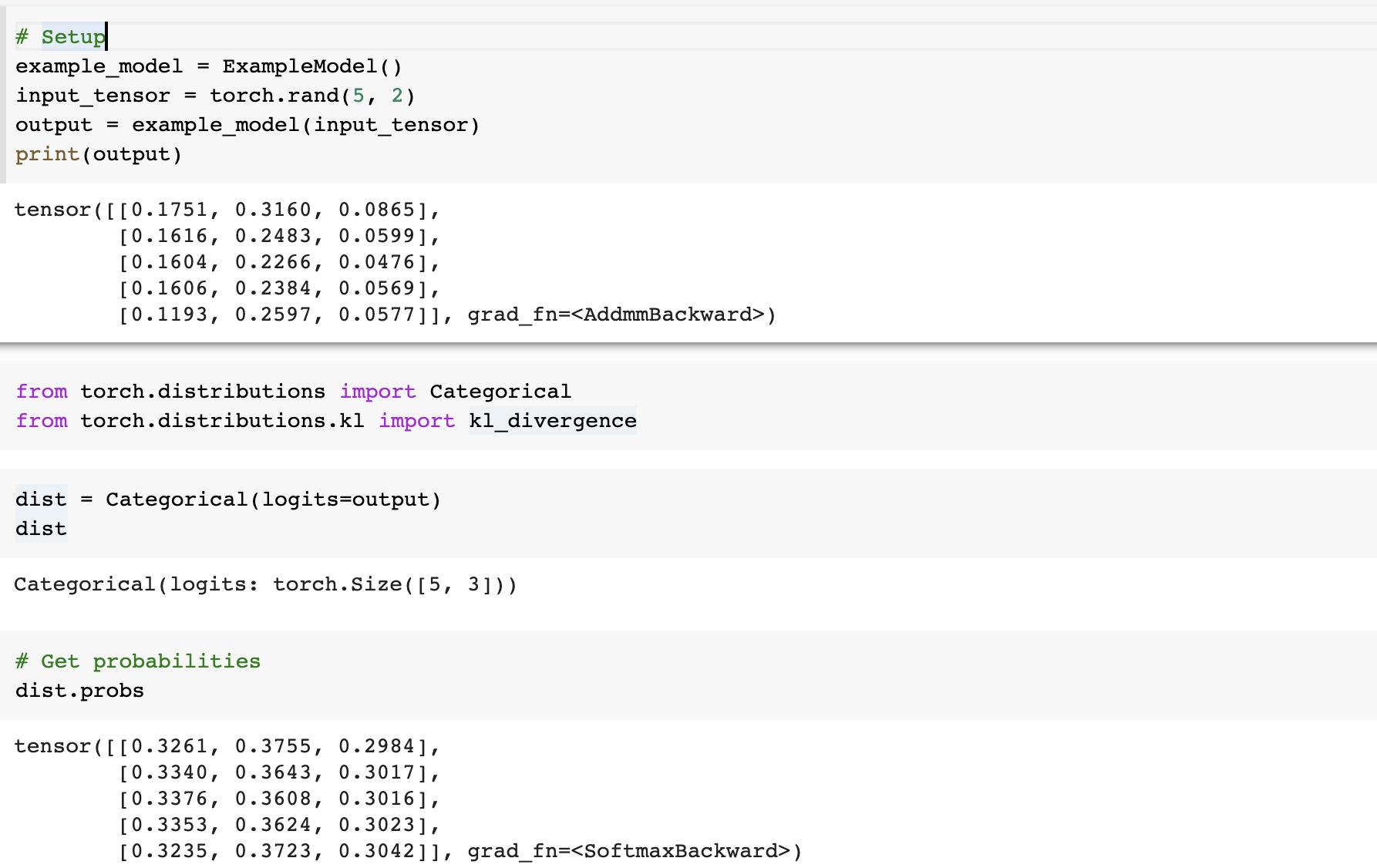

5. 在长期指标上使用 detach
第 5 个技巧是在每个 epoch 之间如果需要存储张量指标,采用 .detach() 来防止内存泄露。
下面用一个代码例子来说说明,首先是初始配置:
# Setup
example_model = ExampleModel()
data_batches = [torch.rand((10, 2)) for _ in range(5)]
criterion = nn.MSELoss(reduce='mean')
错误的代码例子:
losses = []
# Training loop
for batch in data_batches:
output = example_model(batch)
target = torch.rand((10, 3))
loss = criterion(output, target)
losses.append(loss)
# Optimization happens here
print(losses)
打印结果如下:

正确的写法
losses = []
# Training loop
for batch in data_batches:
output = example_model(batch)
target = torch.rand((10, 3))
loss = criterion(output, target)
losses.append(loss.item()) # Or `loss.item()`
# Optimization happens here
print(losses)
打印结果如下:

这里应该调用 loss.item() 方法来保存每个 epoch 中的 loss 数值。
6. 删除 GPU上模型的技巧
第六个技巧是可以采用 torch.cuda.empty_cache() 来清理 GPU 缓存,这个方法在使用 notebook 的时候很有帮助,特别是你想要删除和重新创建一个很大的模型的时候。
使用例子如下所示:
import gc
example_model = ExampleModel().cuda()
del example_model
gc.collect()
# The model will normally stay on the cache until something takes it's place
torch.cuda.empty_cache()
7. 测试前调用 eval()
最后一个是开始测试前别忘了调用 model.eval() ,这个很简单但很容易忘记。这个操作会让一些在训练和验证阶段设置不一样的网络层有必要的改变,会有影响的模块包括:
- Dropout
- Batch Normalization
- RNNs
- Lazy Variants
这个可以参考:https://stackoverflow.com/questions/66534762/which-pytorch-modules-are-affected-by-model-eval-and-model-train
使用例子如下:
example_model = ExampleModel()
# Do training
example_model.eval()
# Do testing
example_model.train()
# Do training again
以上是关于7 个有用的 PyTorch 技巧的主要内容,如果未能解决你的问题,请参考以下文章