索引知识系列一:聚集索引与非聚集索引详解
Posted 程序编织梦想
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了索引知识系列一:聚集索引与非聚集索引详解相关的知识,希望对你有一定的参考价值。
前言
面试的时候,都会被问到索引有哪几种,一般我们都会回答:主键索引,唯一索引,全文索引等等。但是你回答的是具体的索引,实际上索引大体可以分成二大类:聚集索引和非聚集索引。下面我们具体介绍。
聚集索引 (又叫聚簇索引)
聚集索引就好比只有正文(没有目录)的汉语字典一样。我们知道汉语字典的排列顺序是从字母“a”开头并以“z”结尾的。如果我们要找“安”这个字。那就需要找以字母‘a’开头的那部分内容,如果您翻完了所有以“a”开头的部分仍然找不到这个字,那么就说明您的字典中没有这个字。相反,如果您找到了这个字,那您就可以直接找到关于“安”字的所有信息。
通过上面的例子我们总结一下聚集索引的特点:
1.索引内容本身就是目录,您不需要再去查其他目录来找到您需要找的内容。
2.叶子节点上包含着该行的所有信息。当您找到该叶子节点的时候,不需要再回表,直接可以取出该行数据的所有信息。
3.每个表只能有一个聚集索引,因为目录只能按照一种方法进行排序。
用图形化表示如下:
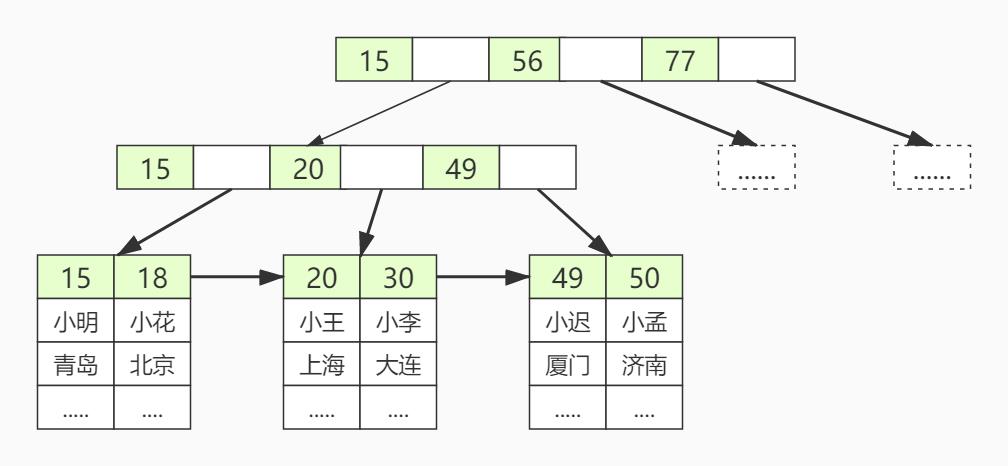
在上图中我们可以看到,叶子节点中包含着该数据行下的所有信息。
因此,像这种正文内容本身就是一种按照一定规则排列并且所有信息都在叶子节点上的目录称为“聚集索引”。
表中数据的排列顺序一定是按照聚集索引来排列的,这也就是为什么大家在建表的时候,一定要建主键。如果不建主键,数据库会以自己的方式来排列数据。
非聚集索引
非聚集索引我们同样用字典来打比方:当遇到你不知道怎么读的字,那么你就需要利用偏旁部首来查询字典,当您在目录上找到这个字后,根据目录后面显示的页码再去字典中找字。比如:我们要找“张字”,根据偏旁部首,我们在检字表中找到“张”的页码是672页,然后,我们再翻到672页查找“张”字的相关信息。
但是我们要知道:结合“部首目录”和“检字表”而查到的字的排序并不是真正的正文的排序方法,检字表中“张”的上面是“驰”字,但页码却是63页,“张”的下面是“弩”字,页面是390页。
我们总结一下:通过这种方式来找到您所需要的字,但它需要两个过程:
1.先找到目录中的结果,
2.再翻到您所需要的页码。
我们把这种目录纯粹是目录,正文纯粹是正文的排序方式称为“非聚集索引”。
用图形化表示如下:
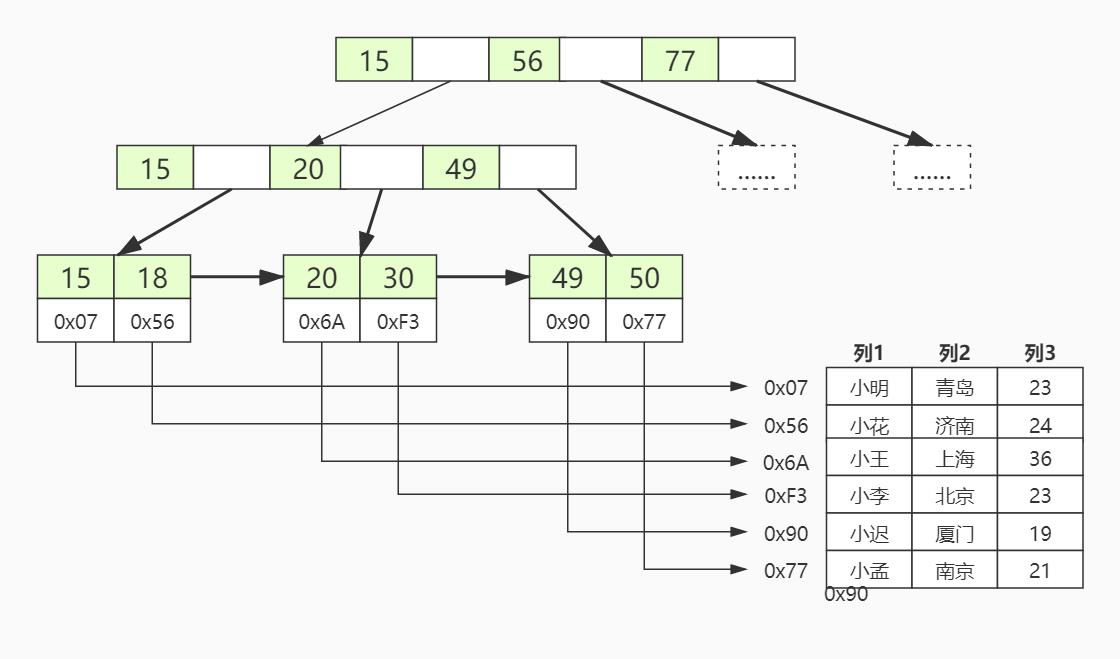
在图中我们可以看到,叶子节点中存的并不是信息,而是地址。既然是地址,那我们就需要拿着地址再回表查询数据信息的过程。
非聚集索引的特点:
1.一张表的聚集索引个数可能有多个,最多可以创建249个非聚集索引。
2.先建聚集索引才能创建非聚集索引。
3.非聚集索引数据与索引不同序。
4.非聚集索引在叶节点上有一个“指针”直接指向要查询的数据区域
聚集索引和非聚集索引优缺点:
1.查询速度上来说:聚集索引优于非聚集索引。
2.插入数据的速度上来说:非聚集索引要比聚集索引要快。
聚集索引和非聚集索引的比较
下面我们再总结一下二者的不同,让大家加深理解:
- 聚集索引一个表只能有一个,而非聚集索引一个表可以存在多个。
- 聚集索引存储记录是物理上连续存在,而非聚集索引是逻辑上的连续,物理存储并不连续。
- 聚集索引:物理存储按照索引排序;聚集索引是一种索引组织形式,索引的键值逻辑顺序决定了表数据行的物理存储顺序。
非聚集索引:物理存储不按照索引排序;非聚集索引则就是普通索引了,仅仅只是对数据列创建相应的索引,不影响整个表的物理存储顺序。 - 索引是通过二叉树的数据结构来描述的,我们可以这么理解聚簇索引:索引的叶节点就是数据节点。而非聚簇索引的叶节点仍然是索引节点,只不过有一个指针指向对应的数据块。
非聚集索引的缺陷弥补
我们知道,非聚集索引需要再回表查询的,那如何避免回表查询,或者减少回表次数呢?那我们就需要了解联合索引、覆盖索引和索引下推的概念。
由于篇幅问题,这一块内容我放在下一章了。
结尾
好了,本章就讲到这里吧希望对大家有所帮助。
另外,大家帮我关注一下我的微信公众号,可领取很多资料。

扫二维码关注公众号【Java程序员的奋斗路】可领取如下学习资料:
1.1T视频教程(大约有100多个视频):涵盖Javaweb前后端教学视频、机器学习/人工智能教学视频、Linux系统教程视频、雅思考试视频教程,android.等
2.项目源码:20个JavaWeb项目源码。
以上是关于索引知识系列一:聚集索引与非聚集索引详解的主要内容,如果未能解决你的问题,请参考以下文章