编译WordCount实例
Posted Zip Zou
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了编译WordCount实例相关的知识,希望对你有一定的参考价值。
预节知识
在Hadoop集群环境中,其有两个重要和关键的系统,分别是HDFS和MapReduce。
其中HDFS是Hadoop的分布式存储的策略和核心,它实现了将数据分块,并且存储到多个DataNode上。
mapreduce的简单的可主要分为以下几个阶段:
- FileInputFormat中的input路径,读取进入输入文件,该输入文件会经过默认的算法和策略进行split形成分片,形成分片后,将会传入到mapper
- 默认情况下,产生的InputSplit作为了mapper的输入,而该输入也是一种键值对的形式,其key类型为LongWritable,为一个可写的长整型,并且其代表的是,当前分片在原始文件的字节偏移量;其value类型为Text类型,代表了文件按行分割(默认分割)后的行内容。该LongWritable
- Text输入到mapper后,hadoop会自动按照其内定的规约,去执行mapper的方法(该方法不止map方法一个,还有setup等方法,但是该方法提供了重写,默认下这些方法什么都不做),调用map方法后,会产生中间键值对。
- 该中间键值对,是在map产生的,如何产生,其产生的策略是什么,其以何为key,以何为value,都有用户在map方法中自行定义。产生的中间键值对,会根据用户的配置,有选择的决定是否进行Combine组合。
组合过程实际上,是一个reduce过程,其可以在map产生中间键值对后,对中间键值对做一个组合,一般来说是为了去整合每个map中产生的具有相同key值的value,从而将重复的key,进行一个首次的合并,从而减少重复key的map进行传输到reduce中,消耗带宽。
该过程为用户进行选择,并且为可选的执行过程,其主要过程是为了能够减少网络传输所消耗的不必要的带宽资源。 - 在mapper或combiner结束后,其产生的中间键值对,会作为reduce或下一个mapper的输入(这是一种链式的mapreduce,为简化整个过程不做详细说明)。接着这些键值对会被传入到reduce方法中,因此map的输出
终端编译实例hadoop程序
准备好JAVA文件,以下为官方源码,以下为旧API的使用:
package org.apache.hadoop.examples;
import java.io.IOException;
import java.util.Iterator;
import java.util.StringTokenizer;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.FileInputFormat;
import org.apache.hadoop.mapred.FileOutputFormat;
import org.apache.hadoop.mapred.JobClient;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapred.MapReduceBase;
import org.apache.hadoop.mapred.Mapper;
import org.apache.hadoop.mapred.OutputCollector;
import org.apache.hadoop.mapred.Reducer;
import org.apache.hadoop.mapred.Reporter;
import org.apache.hadoop.mapred.TextInputFormat;
import org.apache.hadoop.mapred.TextOutputFormat;
public class WordCount
public static class Map extends MapReduceBase implements
Mapper<LongWritable, Text, Text, IntWritable>
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(LongWritable key, Text value,
OutputCollector<Text, IntWritable> output, Reporter reporter)
throws IOException
String line = value.toString();
StringTokenizer tokenizer = new StringTokenizer(line);
while (tokenizer.hasMoreTokens())
word.set(tokenizer.nextToken());
output.collect(word, one);
public static class Reduce extends MapReduceBase implements
Reducer<Text, IntWritable, Text, IntWritable>
public void reduce(Text key, Iterator<IntWritable> values,
OutputCollector<Text, IntWritable> output, Reporter reporter)
throws IOException
int sum = 0;
while (values.hasNext())
sum += values.next().get();
output.collect(key, new IntWritable(sum));
public static void main(String[] args) throws Exception
JobConf conf = new JobConf(WordCount.class);
conf.setJobName("wordcount");
conf.setOutputKeyClass(Text.class);
conf.setOutputValueClass(IntWritable.class);
conf.setMapperClass(Map.class);
conf.setCombinerClass(Reduce.class);
conf.setReducerClass(Reduce.class);
conf.setInputFormat(TextInputFormat.class);
conf.setOutputFormat(TextOutputFormat.class);
FileInputFormat.setInputPaths(conf, new Path(args[0]));
FileOutputFormat.setOutputPath(conf, new Path(args[1]));
JobClient.runJob(conf);
源码解析
main方法解析
首先在该方法中,加载一个Hadoop的job,并指定Job名,之后再为job设置输出类型为
Map类解析
该类继承自Mapper,从代码中可以看出,其输入的map为:
Reduce类解析
该Reducer在main方法中可以看出,它充当了两个成分,一个是Combiner,另一个是Reducer,Combiner在map方法执行结束后再本地调用,这是该reduce的作用就是,将同key的map的value进行累加,并写入到该key所代表的map中,使得该key对应的单词次数,不为1,而是将多个重复key并且出现次数为1的map聚合成了该单词在该行中出现的次数,如有文件一行如下:
hello java hello world hello hadoop
那么在map中产生键值对为:\\
# 编辑模式
sudo vim /etc/profile
# 将上述的hadoop classpath结果,拷贝到CLASSPATH中
# 保存生效
source /etc/profile如图:

再进行编译,执行:javac WordCount.java,前提已经cd进该目录,ls可以看到该java文件,方可正确执行,如图:

可以看到生成了多个.class字节码文件,并且有两个带$号的文件,表示他们是WordCount的内部类,Map类和Reduce类,我们只需要将他们一起打包即可,执行jar cvf WordCount.jar *.class如图:



打包好后,我们即可以运行jar文件,但是此时还需要一些额外的准备工作,因为在这个程序中,需要两个参数,一个是输入文件的路径,一个是输出文件夹的路径,并且输出文件夹不可存在。
因此我们需要执行以下以下操作(frank指代用户名,要根据实际用户名替换):
hdfs -mkdir -p /user/frank/input,创建完了需要将测试文件,提交到input目录,执行:hdfs dfs -put [你的文件路径]/* input即可提交,put后的路径表示你文件的位置,用户可上传包含若干个单词的txt文档,其中单词以空格分隔。
即可执行:java -jar org.apache.hadoop.examples.WordCount input output
注:若已经执行一次,第二次执行,必须要删除output文件方可执行!可执行:
hdfs dfs -rm -r output进行删除,如图:

执行此操作必须保证hadoop服务已经开启
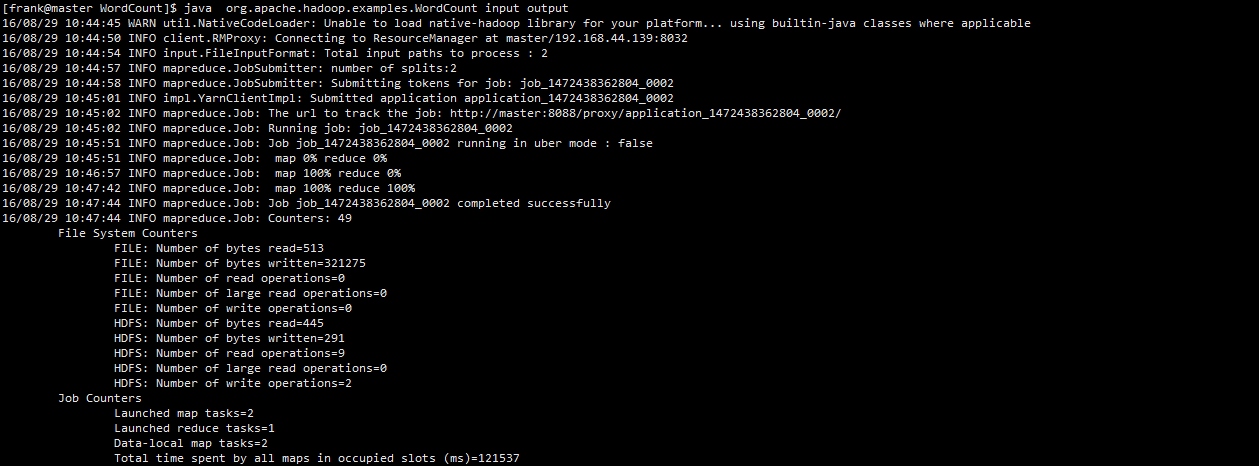
以上为执行效果,我们可以查看到远程的output文件:
执行:hdfs dfs -cat output/*,效果如图(文件内容可能不一样):
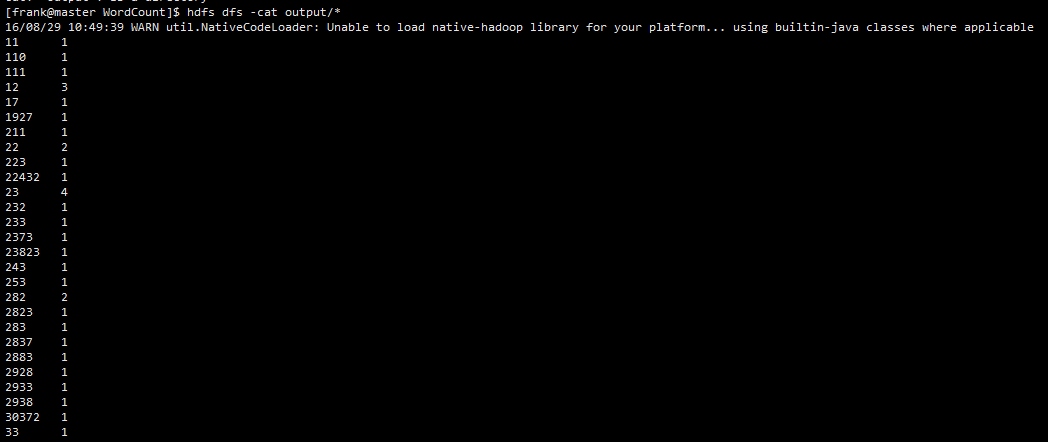
这是在远程查看文件,我们也可以将文件下载到本地,执行:
# 创建保存的目录(若该目录存在则不需要执行)
mkdir ~/myoutput
# 将远程下载下来
hdfs dfs -get output/* ~/myoutput效果如图:

我们可以查看本地的文件,执行:cat ~/myoutput/*,效果如下:
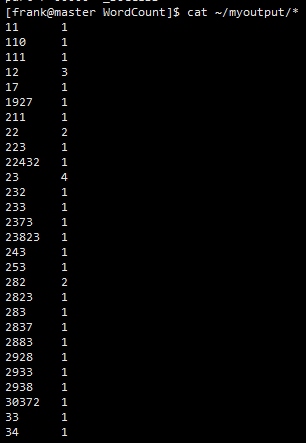
至此,使用命令行执行已经成功。
注意:多次执行该例子,请先删除output文件夹!
使用Eclipse在Linux中执行WordCount
既然是在Eclipse中编译和运行Hadoop,那么就是可视化的界面。
如果在Linux中安装了tar解压工具,可以直接解压eclipse到home路径。
注:该解压路径是任意的,但是尽量避免使用/usr、/lib等目录,这些目录必须要拥有root权限方可操作!
由于笔者的Linux中,未安装解压工具,这里使用命令行进行。
执行解压命令:tar -zxvf ~/Desktop/eclipse-java-neon-R-linux-gtk.tar.gz -C ~,由于笔者的eclipse放在了~/Desktop/eclipse-java-neon-R-linux-gtk.tar.gz,所以路径为这个,若读者路径不一样,请加以替换。
解压完成后,可以看到一个eclipse文件夹,里面的eclipse未可执行文件,接下来我们需要将hadoop的eclipse插件导入,如我们已经下载好了插件jar包,直接拖入解压后的eclipse文件夹中的plugins文件夹中,并执行:~/eclipse -clean来启动eclipse
启动成功后,我们需要配置MapReduce插件,首先选择:Window-Perspective-Open Perspective-Other,选择Map/Reduce后Ok
在eclipse中找到

Map/Reduce Locations项,单击右侧带+图标,新建一个Location
进入如下界面:
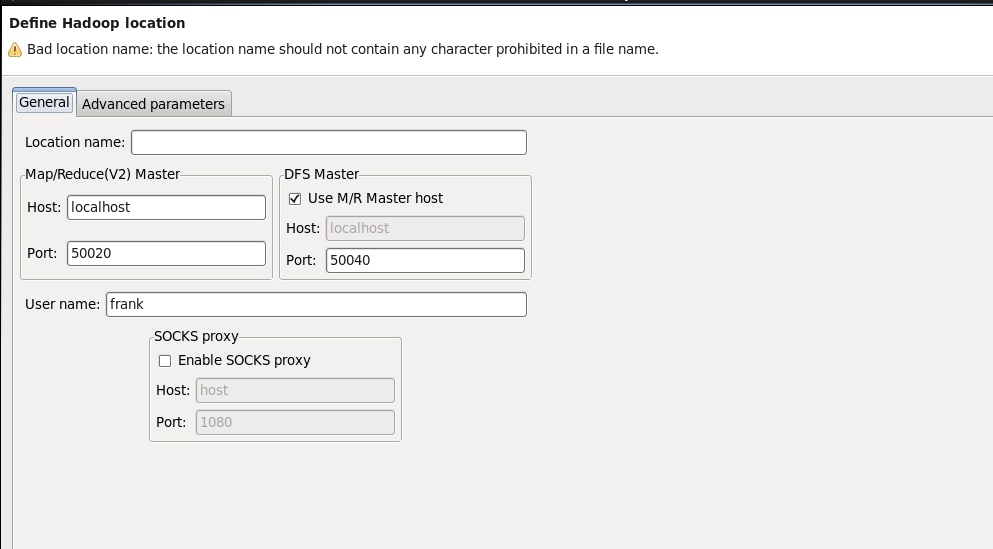
在Location name中,输入名称,名称可随意
在左侧的Master 中的Host中,输入master主机的IP地址,将其Port该为8088,
右侧DFS Master改为9000
保存后退出
退出后,我们在左侧Project Explorer中可以看到一个DFS的浏览器,里面可以看到我们的HDFS信息(启动了Hadoop服务)
接着我们需要配置我们的Hadoop路径到插件中,笔者的Hadoop配置在了,/usr/hadoop。
选择Window-Preferences-Hadoop Map-Reduce
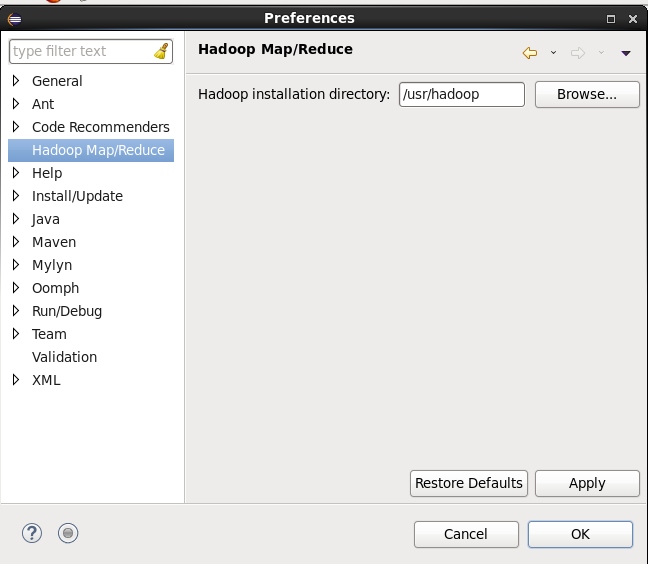
选择Browse,或者直接在输入框中输入路径
注:该路径必须为hadoop的最终路径,该hadoop路径下包含了bin文件夹,sbin文件夹等
保存后,即可新建一个MapReduce项目,选择File-New-Other-Map/Reduce Project如:
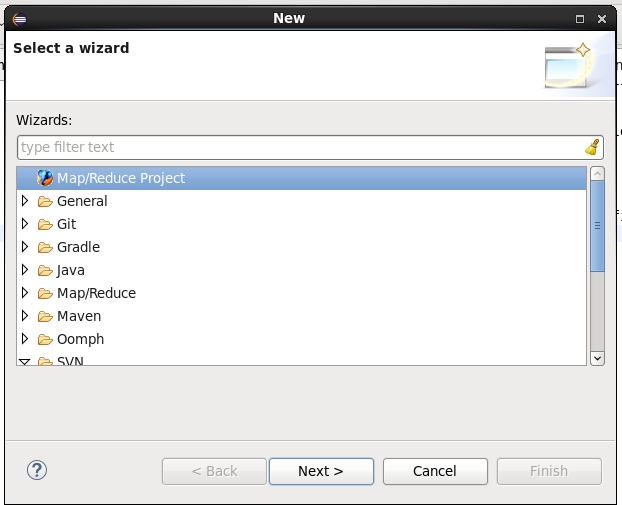
输入项目名
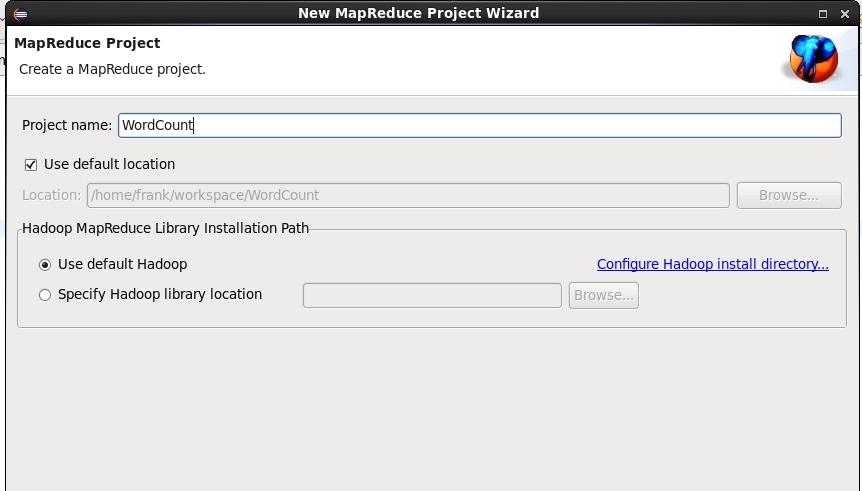
并一直Next直到项目创建成功,可发现在项目中展开,可以发现Referenced Libraries,否则配置失败!
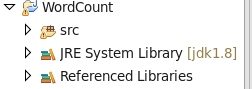
配置成功后,在src文件夹中,新建一个包:new-Package
由于在官方代码中,是有package的,所以我们需要给src新建一个包,防止源代码拷贝进来时会出错,包名为:org.apache.hadoop.examples,如果不新建包,可以直接粘贴代码,但是需要在源码中将package一句去除。
如图加入源码文件,除此之外,还需要将hadoop的两个xml配置文件,拖入到工程中,其分别是:core-site.xml,hdfs-site.xml,log4j.properties文件
路径在$HADOOP_HOME/etc/hadoop下,直接拷至项目的src文件夹下即可。
这样即可配置好了可执行环境,选择WordCount.java,右键Run As… - Run Configuration,在arguments中,填写入input output
该两个参数为指定hadoop程序的输入目录和输出目录,会用input和output则默认使用hdfs中/user/[用户名]/input和/user/[用户名]/output目录,读者可自行将input替换为HDFS中的存在的某个目录,这时候请尽量使用绝对路径,如:/user/frank/myinput
配置好运行参数后,Apply保存,关闭该窗口,右键该Java文件,选择Run As-Run on Hadoop即可启动运行。
至此运行结束后,可以在左上角的HDFS目录中,刷新,查看其产生的output目录下的文件,存储了结果文件。
以上是关于编译WordCount实例的主要内容,如果未能解决你的问题,请参考以下文章