海量数据处理-重新思考排序2
Posted xiaoranone
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了海量数据处理-重新思考排序2相关的知识,希望对你有一定的参考价值。
海量数据处理--重新思考排序(2)
如今互联网产生的数据量已经达到PB级别,如何在数据量不断增大的情况下,依然保证快速的检索或者更新数据,是我们面临的问题。在之前我们也提到过,然而在大数据处理的技术中,排序起到很重要的作用,可能不是直接使用,要不使用这用划分的思想,或者在小的方面使用到排序的方法,例如在在我们之前提到的Top k问题,用用到了堆排序中堆,在上一节介绍堆排序额时候,我们也给出了一个使用最大堆的例子。本篇文章,我们继续讨论排序。
闲话少叙,进入主题
今天我们主要讨论归并排序,快速排序,桶排序,计数排序,他们的思想已经我们会怎么用到这用思想,还有一点他们的扩张,我们尽量将这些方法使用在大数据处理上。上篇文章提到过的排序的方法,读者有兴趣的话可以自己学习。对这四种排序方式,我都会总结一句话,表达它的思想。
- 归并排序,分而治之,先排后归。
- 快速排序,以轴划分,左右并行。
- 桶排序, 划分进桶,桶中排序。
- 计数排序,确定范围,填充位置。
归并排序
归并排序: 建立在归并操作上的一种排序算法,该方法采用分治法的一个非常典型应用,一般我们都是使用二路归并,就是将数据划分成两部分进行处理,但是注意我们可以是多路归并,不要让二路归并排序限制我们的思想。
从下面的伪代码中,我们可以很容易看到二路归并排序只有两个部分,一个是递归划分,一个是归并操作,这就是我们最长用到的归并排序。但是在海量数据的排序过程中,我们可以使用二路归并,当然我也可以选择多路归并排序。
伪代码:
// 归并
merge(array, left, mid, right):
tmp = new int[right - left + 1] // 申请复制空间
i = left, j = mid+1, k = 0;
while(i <= mid && j <= right)
if(array[i] < array[j]) tmp[k++] = array[i++];
else tmp[k++] = array[j++];
// 处理尾部,可能会有一部分没有处理结束
while(i <= mid) tmp[k++] = array[i++];
while(j <= right) tmp[k++] = array[j++];
// copy回到原来的数据, tmp -> array
copy(array[left, right], tmp[0,k-1])
// 调用
merge_sort(array, left, right):
if(left < right)
mid = (left + right) / 2;
merge_sort(array, left, mid);
merge_sort(array, mid+1, right);
// 调用归并函数
merge(arr, left, mid, right);
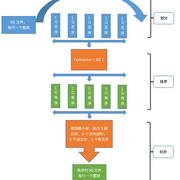
海量数据排序,使用归并排序的思想进行排序,例如我们现在有一个5G的数据文件,每一行有一个32位的正整数,现在要求只能使用1G的内存空间,对这个文件排序。
我们有大数据处理的经验都知道,内存放不下,只能将大文件分成几个小文件,这就是划分,之后对每个文件进行排序,最后归并这几个小文件的排序结果,叫做多路归并。上述的过程可以叫做外排序,即借助外部的文件进行排序。
从这个题目出发我们使用之前介绍过的大数据处理技术完成这个排序过程。
- 划分成5个小文件,5G / 1G = 5
- 将单个文件读入内存,进行排序,写入文件
- 使用5路归并,将每个文件作为一路排序,归并最后得到结果
在上述的问题中,我们使用归并排序的思想加数据结构堆来进行了大文件的排序。我们都知道多次的读写文件是很浪费时间的,能不能进行优化呢?有一个条件没有使用到,那就是所有数字都是32的正整数。我们可以知道数据的范围[0-2^32-1].还记得计数排序,确定范围,填充位置。
计数排序
计算排序是非比较的排序算法,使用的位置空间,在对一定范围内的整数排序时,它有很大优势。这是空间换时间的典型做法。时间复杂度基于范围中最大的数k和长度n。O(k+n)
伪代码
countsort(array):
max_value = max(array); // 找到最大值
count[max_value+1] = 0; // 计数置0
for v in array:
count[v] ++
for (i = 0; i <= max_value; i++)
count[i] += count[i-1];
rank[n+1];
// 放置到排序对应的位置
for (i= 0; i < n; i++)
rank[--count[a[i]]] = a[i]; // count[a[i]] 对应i的位置
return rank;
位图排序
使用提示,如何想到使用计数排序或者在海量数据处理方面使用计数排序的思想呢?如果我们知道所有的数字只出现一次,我们就可以只使用计算排序中的记录函数,将所有存在的值对应的位置设置为1,否则对应为0,扫描整个数组输出位置为1对应的下标即可完成排序。这种思想可以转为位图排序。
我们使用一个位图来表示所有的数据范围,01位串来表示,如果这个数字出现怎对应的位置就是1,否则就是0.例如我们有一个集合S = 1,4,2,3,6,10,7; 注意到最大值10,用位图表示为1111011001,对应为1的位置表示这个数字存在,否则表示这个数字不存在。
伪代码
// step 1, 初始化为0
for(i = 0; i < n; i++)
bit[i] = 0;
// step 2, 读取数据,对应设置为1
for d in all file_read:
bit[d] = 1
// step3, 对应为1的位置写入文件
for(i = 0; i < n; i++)
if(bit[i] == 1)
write i to sort_file
例如题目:
给你一个文件,里面有n个不重复的正整数,而且每一个数都小于等于n(10^7)。请最多使用1M的内存空间,对这个文件进行排序。
可以使用归并排序,但是时间应该慢,我们这里使用位图排序, 1 0 7 / 8 = 1.25 M b 10^7 / 8 = 1.25Mb 107/8=1.25Mb, 我们只有1M内存空间,这里可以分成两个读取文件, ( 1 , 5 ∗ 1 0 6 ) (1, 5*10^6) (1,5∗106)和 ( 5 ∗ 1 0 6 , 1 0 7 ) (5*10^6, 10^7) (5∗106,107)进行分开使用位图,空间占用0.625Mb.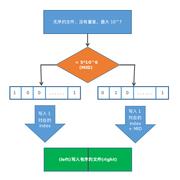
桶排序
桶排序的工作原理是将数据分装到有限数量的桶里,对每个桶分别进行排序,如果能将数据均匀分配,排序的速度将是很快的。
伪代码
bucket_sort(array):
buckets[10]; // 申请10个桶
for d in array:
index = function(d) // 将d划分到每一个桶中
buckets[index].append(index)
// 对每一个桶分别进行排序
for i in 1...10:
sort(buckets[i])
// concat所有结果,这里是连接不是归并,
// 我们划分的时候保证buckets[i] < buckets[i+1]
应用实例: 寻找中位数
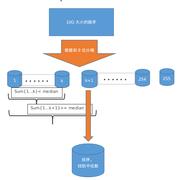
在一个大小为10GB的文件中有一堆整数,乱序排列,要求找出中位数。内存限制2GB。
这个问题,我们可以使用外排序,并且记录元素的各种,最后得到中位数即可。这里我们使用桶排序的思想。
- 将所有的数据根据前8位进行分桶,最多有255个桶,并且记录每个桶中元素的格式。这里的桶是文件表示。
- 根据划分性质,我们有buckets[i] < buckets[i+1]; count[i]:个数
- 如果sumcount1,k < sum(count1,n) / 2 <= sumcount(1,k+1),得到中位数在k+1个桶中,
- 将k+1个桶中读取内存(假设小于2GB,否则要根据次8位进行继续分桶),找到第m个数字,sumcount1,k+m对应的是中位数的下标。
快速排序
快速排序是对冒泡排序的改进。通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列。
伪代码
int partition(array,left,right)
index = left;
i = left+1, j = right;
while(1)
while(i<j && array[i]<array[index]) ++i;
while(i<j && array[j]>array[index]) ++i;
if(i>j) break;
else
swap(array[i],array[j]);
++i; --j;
swap(array[index], array[j]);
return j
// Qsort(array,0,n-1)
void Qsort(array, left, right)
if(left < right)
mid = partition(array, left, right);
Qsort(array, left, mid-1);
Qsort(array, mid+1, right);
快速排序在海量数据处理的过程中,一般不会直接使用,因为快速排序在基于内存的排序时,性能很好,是最常用的方法,例如我们对大数据进行划分后,可以对单个小文件应用快速排序。其实应用多还有就是快速排序中的一次划分很重要,比如我们有很多性别男,女,请将所有的女性放到男性的前面,我们只需要才有划分思想就OK了。
总结
至此,海量数据处理-重新思考排序就结束了,我们没有太关注排序的细节,而是关注排序在海量数据中怎么使用的。当然其中难免有错,希望大家多多指教。
生活如此,问题不大。喵~
以上是关于海量数据处理-重新思考排序2的主要内容,如果未能解决你的问题,请参考以下文章