推荐系统_基于内容的推荐
Posted 漠小浅
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了推荐系统_基于内容的推荐相关的知识,希望对你有一定的参考价值。
关于推荐系统的算法大概可以分类两类:
一类就是基于用户或者基于商品的协同过滤,我们主要是通过用户行为这个海量数据来挖掘出用户在品味上的一些相似程度,或者说
商品的相似程度,然后我们在利用相似性来进行推荐。
另一类就是更早期的,而且更加容易理解的推荐,即基于内容的推荐,其主要思想就是:我们首先给商品划分一些属性,
你也可以称为分类,比如说,对汽车分为一些类别,比如微型车,中型车,大型车,豪华车等等,每一类中又可以在细分,例如按照马力,门数等等,我们建立了这些属性数
据以后,我们怎么样进行推送呢?当用户看某一个商品的时候,可以给他推荐一些同类的,比如说它的属性比较相近,或者分类在同一类里面,或者说不是同一类但是是相近
的分类的这么一些其它的汽车给他,这个就是一种称为内容的推荐。还有一种就是根据用户标签进行的推荐,这个标签就是我们给商品或者人打上的一些属性信息,这个跟前
面的分类的区别:其实标签本质上也是一种分类,但是我们之前所说的对于汽车的分类可能是一种比较严肃的分类,比如说网站聘用了一些专业的编辑回来,这些编辑有比较
强的业务能力,他对这个专业里面的知识理解的比较透彻,有这些人对这些商品进行分类;而标签应该是那种比较随意的,比较松散的,这个一般是由用家,玩家来做的,比
如说玩家看每一辆车,对这辆车打上一个标签,例如可爱,大气等等,或者说可能是机器给你加的,机器可能根据浏览的一些人的情况给这些商品加上标签,对人的标签也
是一样,例如在移动公司里面,在它的交换机上得到一个日志,这个日志记录着用户访问网站的信息,有了用的访问的链接之后,可以通过这些链接把用户访问的网页抓回来,
然后对抓回来的网页做一些文本挖掘,比如分词,提取一些关键字,然后分析一下这篇文章是属于哪种类型的,比如说是科技类文章,旅游类文章,电影类等等,可以知道用
户是属于那种类型的人,对什么东西感兴趣,例如用户到周末经常看一些电影院,电影的网站,可能断定该用户是一个电影爱好者,移动就可以赠送给这个用户电影票来绑定
该用户。所以说不光是商品,人其实也可以打标签,人的标签可以是人与人之间打标签,例如说qq上面给好友打标签,作评价,也可以是机器给人打标签,例如刚才所说的移
动公司的例子。 不论是专业编辑给它赋属性也好,或者是业余人士(用户)随意的给它打上标签也好,也可能是机器打上去的,我们基于这种分类来做推荐的话,我们称之为
基于内容的推荐(有些人称之为基于标签的推荐)。
自己感觉隐语义模型就是使用机器给内容打上标签,用来代替人工,隐语义模型给内容打上标签,即分类。有分类了就可以进行推荐了。
隐语义模型的核心是通过隐含特征(latent factor)联系用户兴趣和物品。
举例:例如两个用户的读书列表。用户A的兴趣涉及侦探小说、科普图书以及一些计算机技术书,而用户B的兴趣比较集中在数学和机器学习方面。
那么如何对A和B推荐图书呢?
对于UserCF,首先需要找到和他们看了同样书的其他用户(兴趣相似的用户),然后给他们推荐那些用户喜欢的其他书。
对于ItemCF,需要给他们推荐和他们已经看的书相似的书,比如作者B看了许多关于数据挖掘的书,可以给他们推荐机器学习或者模式识别方面的书。
还有一种方法,可以对书和物品的兴趣进行分类。对于某个用户,首先得到他的兴趣分类,然后从分类中挑选他可能喜欢的物品。
根据商品属性/分类(基于内容的推荐)进行推荐的基本思路:
1,怎样给物品进行分类?用人或者专家来进行分类会产生许多的问题;用机器来进行分类(隐语义模型进行自动分类)
2,怎样确定用户对哪些类别的商品有兴趣(可能需要对感兴趣程度量化衡量)?可能需要用权重来进行用户感兴趣的类别的描述,权重的设定怎么来设定,使用机器来对用户的行为进行分析,然后得出他对商品兴趣的权值(隐语义模型中有一种很巧妙的方法可以解决这个问题);
3,确定类别以后,要向用户推荐这个类里的哪些商品?怎样确定商品在类里的权重?类别中的哪些商品推荐给用户呢?我们应该把类别按照次序从高到低进行排序,那怎么确定该商品在该类别中的权重有多大呢?可以肯定基本不可能是用人来进行的,(隐语义模型有一种巧妙的办法可以解决);
刚才我们也说过了不适用机器,用专业的人员,编辑来对商品进行整理分类,赋予权重的话其实会有许多问题(这里做下总结):
使用专业人员(编辑)对商品进行整理分类,但这样会产生成本和效率瓶颈
受限于编辑的专业水平,编辑的意见未必能代表用户的意见
分类的粒度难于控制
如果商品有多个分类,很难考虑周全
多维度,多规角分类
编辑很难决定商品在类别里的权重
为了解决上面的问题,研究人员提出:为什么我们不从数据出发,自动地找到那些类,然后进行个性化推荐?于是,隐含语义分析(latent variable analysis)出现了。隐含语义分析技术因为采取基于用户行为统计的自动聚类,较好地解决了上面提出的5个问题。
隐含语义技术从诞生到今天产生了很多著名的模型和方法,其中和该技术相关且耳熟能详的名词有pLSA、LDA、隐含类别模型(latent class model)、隐含主题模型(latent topic model)、矩阵分解(matrix factorization)。这些技术和方法在本质上是想通的,其中很多方法都可以用于个性化推荐系统。下来以LFM为例介绍隐含语义分析在推荐系统中的应用。
隐语义模型(LFM(latent foctor model))
关键公式:

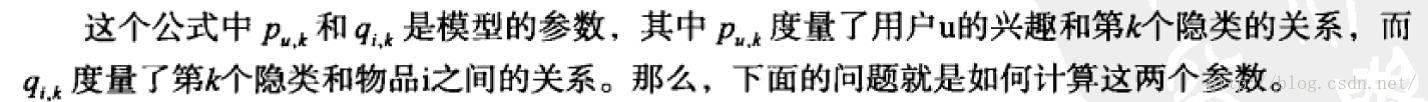
举例如下:
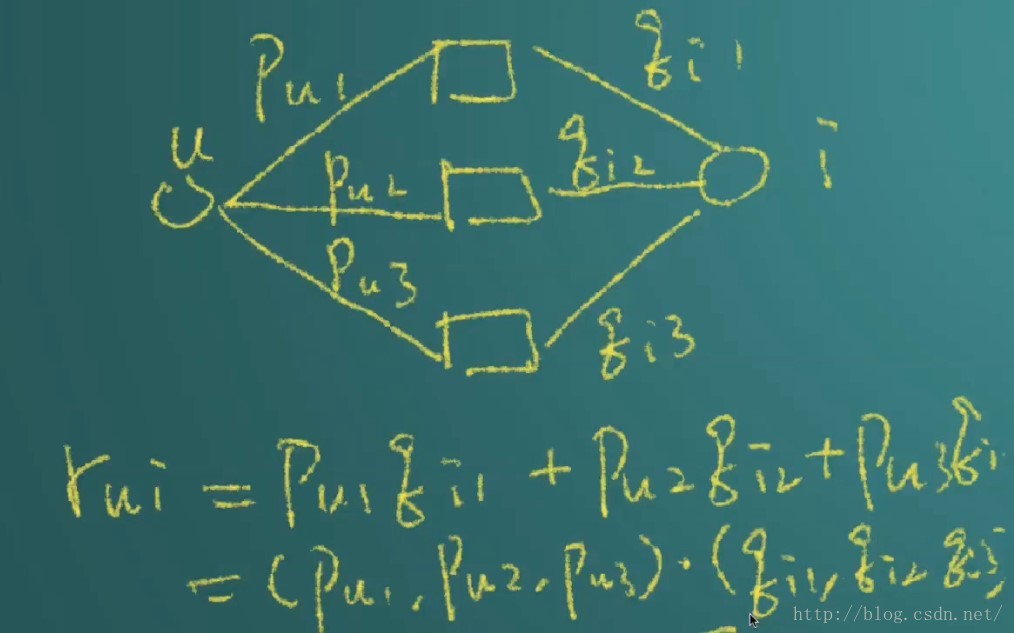
我们后面要做的事情就是抽样产生一个学习集,比如用户在网站上对商品的评分,例如用户对电影的评价,这种叫显性学习集,即用户主动的对一些商品进行了打分,隐形学习集:用户并没表现
出对某个商品的喜爱程度,他只是通过自己的一些行为,暗示了他的喜爱,比如说他经常浏览哪些商品,或者购买过哪些商品,购买过明显就是一个喜爱行为,我们可以通过用户的行为推测出他
的喜爱程度。不论用哪种数据集,我们以上面给出的关键公式建立一个数学模型,通过学习数据来对这个模型进行训练求解,求解出puk和qik。这个就是隐语义模型的基本思想。
LFM的前世今生:
源于对SVD(奇异值分解)方法的改进,传统SVD是线性代数典型问题,具体见:http://zh.wikipedia.org/wiki/%E5%A5%87%E5%BC%82%E5%80%BC%E5%88%86%E8%A7%A3
SVD可用于推荐系统评分矩阵补全,但由于计算量太大,实际上只是适用于觃模很小的系统
Simon Funk改进SVD(Funk-SVD),后来被称为Latent Factor Model(SVD是纯矩阵问题,运算过程中会产生一巨大的矩阵,一般适合比较小的系统,Fuck改进以后,他不用矩阵计算,变成
用迭代计算,使用梯度下降法来求解,比较容易计算。即用梯度下降算法解决一个SVD问题)
项亮书第187页
隐语义模型的适用性:
LFM可以很好地解决之前所提到的困难
不能存在编辑的主观评判或专业因素限制,所有的分类和权重都来自于算法对用户数据进行的客观统计分析,只存在这模型适用性问题。也丌会额外产生编辑的人力成本开销。
分类数k是先验指定,通过k可以控制分类的粒度
LFM中,商品针对每个类都可以计算权重,是天生的多分类,多维度
关于训练集:
对于每个用户u,训练集包含了u喜欢的商品和不感兴趣的物品
LFM在显性反馈数据(即用户精确给出正负面评价数据)上工作良好,精度很高
隐性反馈数据,这类数据的特点是只有正样本(购物篮数据,用户点击数据),没有负样本
在隐性反馈数据下产生负样本的几种方法:


然后喜欢设定rui为1,不喜欢设定为rui为0(最简单)
常见同类问题求解思路:
最大似然(类似于训练贝叶斯信念网络和EM算法)
转化为求解损失凼数极小值问题(采用梯度下降算法求解):

LFM损失函数极值用梯度下降法求解:

LFM中的重要参数:
模型中隐特征个数(尝试,根据经验)
梯度下降法中选取的学习速率
损失凼数中的惩罚项系数lambda
训练集的负样本/正样本比例ratio(一般取1)
LFM SVD奇异值分解求解:

一下是项亮的书里面的截图

“隐语义”的真正背景
摘自:http://blog.csdn.net/wangran51/article/details/7408406
LSA(latent semantic analysis)潜在语义分析,也被称为LSI(latent semantic index),是Scott Deerwester, Susan T. Dumais等人在1990年提出来的一种新的索引和检索方法。该方法和传统向量空间模型(vector space model)一样使用向量来表示词(terms)和文档(documents),并通过向量间的关系(如夹角)来判断词及文档间的关系;而不同的是,LSA将词和文档映射到潜在语义空间,从而去除了原始向量空间中的一些“噪音”,提高了信息检索的精确度。
场景:

利用SVD求解LSA
分析文档集合,建立Term-Document矩阵。
对Term-Document矩阵进行奇异值分解。
对SVD分解后的矩阵进行降维,也就是奇异值分解一节所提到的低阶近似。
使用降维后的矩阵构建潜在语义空间,或重建Term-Document矩阵。
例子:

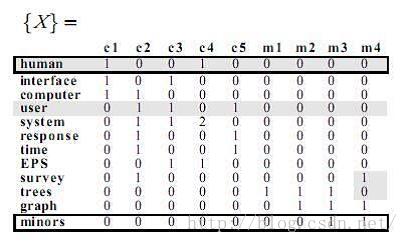

然后对分解后的矩阵降维,这里保留S的最大两个奇异值,相应的WP矩阵如图,注意P在公式中需要转置。
到了这一步后,我们有两种处理方法,论文Introduction to Latent Semantic Analysis是将降维后的三个矩阵再乘起来,重新构建了X矩阵如下:
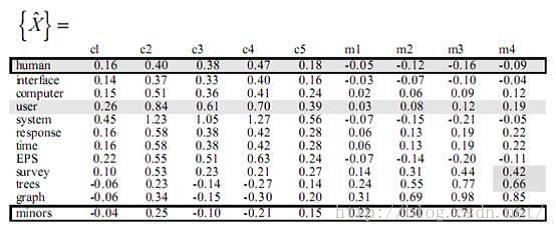
观察X矩阵和X^矩阵可以发现:
X中human-C2值为0,因为C2中并不包含human单词,但是X^中human-C2为0.40,表明human和C2有一定的关系,为什么呢?因为C2:”A survey of user opinion of computer system response time”中包含user单词,和human是近似词,因此human-C2的值被提高了。同理还可以分析其他在X^中数值改变了的词。
基于标签的推荐系统
推荐系统的目的是联系用户的兴趣和物品,这种联系需要依赖不同的媒体。目前流行的推荐系统基本上通过3中方式联系用户兴趣和物品。如下图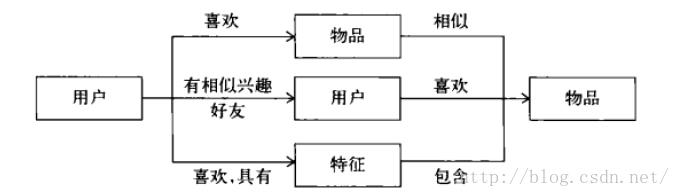
第一种方式是利用用户喜欢过的物品,给用户推荐与他喜欢过的物品相似的物品,这就是前面提到的基于物品的算法。第二种方式是利用和用户兴趣相似的其他用户,给用户推荐那些和他们兴趣爱好相似的其他用户喜欢的物品,这是前面提到的基于用户的算法。除了这两种方法,第三种重要的方式是通过一些特征联系用户和物品,给用户推荐那些具体用户喜欢的特征的物品。这里的特征有不同的表现方式,比如可以表现为物品的属性集合(比如对于图书,属性集合包括作者、出版社、主题和关键词等),也可以表现为隐语义向量(latent factor vector),这可以通过前面提示的隐语义模型得到,下面讨论一种重要的特征表现方式----标签。根据给物品打标签的对象的不同,标签应用一般分为两种:一种是让作者或者专家或者机器给物品打标签(LFM);另一种是让普通用户给物品打标签;
标签跟分类有什么不一样的呢?前面说过了,分类一般是由专业人员或者机器(例如:LFM)打上的,标签是有用户自由打上的。 用户为什么要打标签呢?

基于标签的推荐系统的思想:

即:
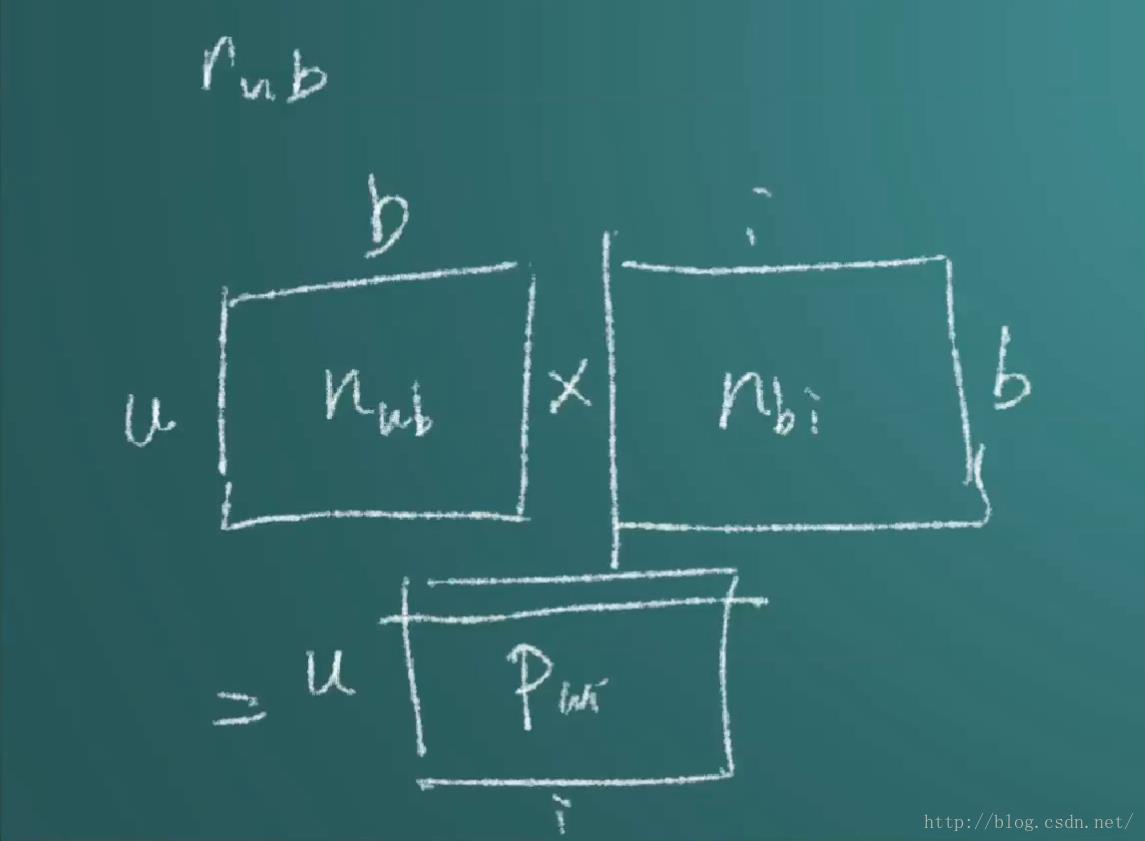 怎么进行推荐呢?例如一个用户进来,就找找最后一个矩阵ui中用户对应的一行,里面有很多歌pui,看看那个pui是最大的,就把那个商品推荐给他。
怎么进行推荐呢?例如一个用户进来,就找找最后一个矩阵ui中用户对应的一行,里面有很多歌pui,看看那个pui是最大的,就把那个商品推荐给他。
前面这个公式倾向于给热门标签对应的热门物品很大的权重,因此会造成推荐热门的物品给用户,从而降低推荐结果的新颖性。例如现在有一部电影
正在很热门的播放,多半都会把这个电影推荐给你,但是这部电影其实不需要推荐给你你也知道,这就是说推荐系统推荐给你的东西不是新颖的。推荐
给你也没有什么用处,其实你估计也知道了(热门),这对于推荐系统没有多大的意义,所以我们可能需要改进推荐系统,来纠正这种情况,来防止一些
过热的物品,过热的标签干扰到我们这个推荐系统的新颖性,这里所采取的方法是TF-IDF。
TagBasedTFIDF(应用TF-IDF的思想):
前面这个公式倾向于给热门标签对应的热门物品很大的权重,因此会造成推荐热门的物品给用户,从而降低推荐结果的新颖性。另外,这个公式利用用户的
标签向量对用户兴趣建模,其中每个标签都是用户使用过的标签,而标签的权重是用户使用该标签的次数。这种建模方法的缺点是给热门标签过大的权重,从而不能反映
用户个性化的兴趣。这里我们借鉴TF-IDF的思想,对这一共识进行改进:
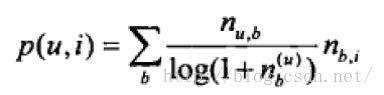
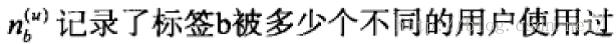
这样,热门的东西就不会被反复的给推荐出来了。

假如一个用户他比较新,举例来说,假如一个商品刚放到这个系统里面没多久,这个时候可能用户打的标签可能很少,
这个样子就不好推荐,例如购买东西,购买的东西多了就很好的推荐,如果一个人只买了一个商品,就不好推荐,如果
这个人什么都没有购买,就更难进行推荐。这个时候我们就可能需要对他的标签进行扩展,比如说你使用过某一个标签,
我可能在这个标签上获得的物品不是很多,甚至可能没有人使用过这个标签,但是如果我找出与这个标签相似的标签,
那么相对来说我可能获得的物品就可能多一些,我们可以这这些标签认为是同一个标签,那么这样就好了。那么现在的关键
就是要挖掘出那些新的相似的标签出来,标签的相似度怎么计算呢?公式如下:
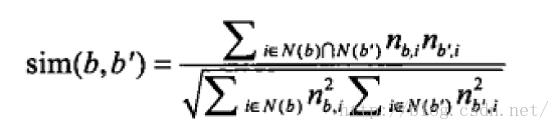
通过这个就可以获得一些相似的标签出来,


以上是关于推荐系统_基于内容的推荐的主要内容,如果未能解决你的问题,请参考以下文章