网络编程笔记Linux系统常见的网络编程I/O模型简述
Posted slvher
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了网络编程笔记Linux系统常见的网络编程I/O模型简述相关的知识,希望对你有一定的参考价值。
1. 典型的I/O模型
根据”Unix Network Programming Volume 1”一书第6.2节的说明,Linux系统支持的典型I/O模型包含下面5种:
- 阻塞I/O(blocking I/O)
- 非阻塞I/O(nonblocking I/O)
- I/O多路复用(I/O multiplexing, e.g. select and poll)
- 信号驱动型I/O(signal driven I/O, e.g. SIGIO)
- 异步I/O(asynchronous I/O, e.g. the POSIX aio_* functions)
对于输入操作来说,可以拆分为两个典型的阶段:
1) 等待数据ready
2) 将数据从kernel buffer拷贝至应用进程buffer(在这之前,数据要从socket buffer拷贝至kernel buffer)
所有的I/O模型都包含这两个阶段,只不过等待数据ready的实现方式有所不同,下面分别举例说明。
2. Blocking I/O Model
阻塞I/O模型是最简单的I/O模型,顾名思义,采用阻塞IO模型时,在等待某个socket的数据ready的过程中,整个应用进程被阻塞。
以调用UDP socket阻塞模式的recvfrom函数为例,其过程如下图所示。
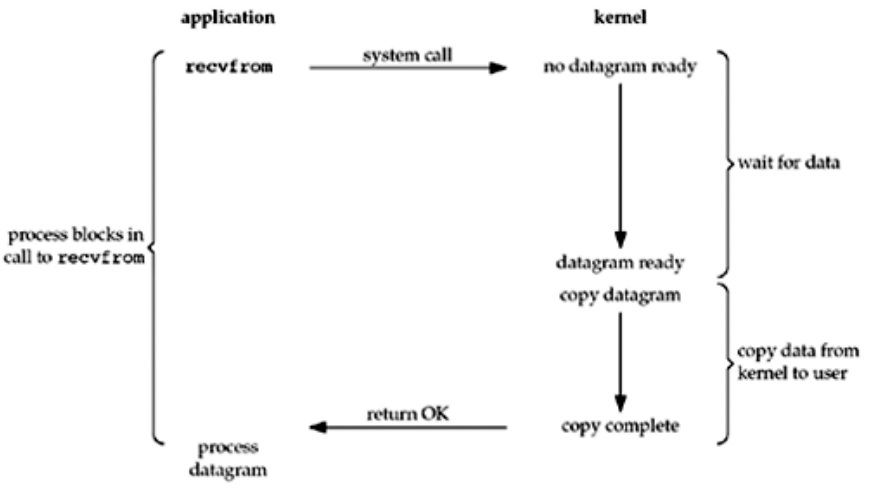
可见,当调用recvfrom后,进程会阻塞,直到该函数收到数据后返回,而在阻塞期间,进程处于sleep状态。显然,这种IO模型会存在较严重的性能问题。
3. Nonblocking I/O Model
当把socket设置为非阻塞模式时,我们期望kernel完成以下操作:
when an I/O operation that I request cannot be completed without putting the process to sleep, do not put the process to sleep, but return an error instead.
以调用UDP socket非阻塞模式的recvfrom函数为例,其过程如下图所示。

由上图可见,在非阻塞模式下调用recvfrom时,若数据未ready,则函数会立即返回一个表示错误的非零返回值(如上图中的EWOULDBLOCK)。
应用程序应当检查返回值并反复调用recvfrom,直到recvfrom函数收到正常数据后返回零值。这个在非阻塞fd上循环调用recvfrom的动作被称为polling。
可见,非阻塞模式下,应用程序需不断主动轮询kernel以便确定数据是否ready,这对CPU资源来说显然是一种浪费。
4. I/O Multiplexing Model
在IO多路复用模式下,应用程序在进行真正的数据读写操作前,先调用select或poll,若socket的读/写条件不满足,则程序会阻塞在select或poll函数处。函数返回后,表明socket满足读/写条件,此时,应用程序再调用真正的IO操作函数进行数据读写。
以UDP socket的IO多路复用模式为例,其过程示意如下所示。

由上图可见,调用select后,进程阻塞在该函数处,若后续数据ready,则select返回可读的fd,接着,对该fd调用recvfrom进行数据读取。
从示意图来看,IO多路复用模型与前面介绍的阻塞IO模型相比,似乎并没有优势,甚至还多一次系统调用。
事实上,若应用程序操作的fd只有1个时,通过select实现IO多路复用模式确实没有优势,但当进程操作的fd远不只1个时,select的优势就会体现出来,此时,这些fd通过select进行统一管理,这极大地简化了编程实现细节。
但目前kernel的select实现代码中,它能管理的fd上限默认只有1024个,且它在内部是通过依次遍历来确定某个fd是否可读/写的。因此,即使可以通过修改kernel相关代码来增加其管理的fd上限,但遍历fd数组仍然是个线性操作。因此,在fd数量较大时,通过select或poll实现的IO多路复用模型也会存在性能问题。
5. Signal-Driven I/O Model
上面介绍的几种IO模型需要通过阻塞或轮询来确定某个fd是否可读或可写,它们在高并发的网络场景下均存在不小的性能瓶颈。
鉴于此,Linux kernel引入了下面的IO模型:
应用程序创建支持信号驱动的socket后,借助操作系统支持的信号注册机制向kernel注册SIGIO信号的回调函数,此后,应用程序可以去做不依赖该socket数据的其它任务。当某个fd满足读写条件后,kernel会主动调用回调函数,应用程序可以在回调函数中对给定fd做数据读写,或者在回调函数中通知主进程去读写数据。
以UDP socket的signal-driven IO模型为例,其过程如下图所示。
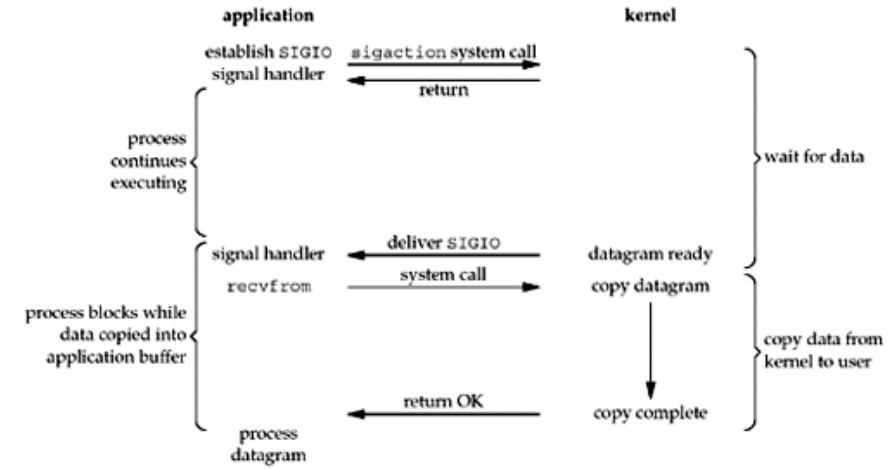
信号驱动IO模型的优势是在等待数据ready期间真正避免了进程阻塞,主进程可以进行其它操作,目标fd对应的数据ready后,kernel会通过回调函数通知应用程序去读/写数据。
从处理流程看,它已经是异步模式了,它与下面要介绍的符合POSIX规范的异步模型的唯一区别在于:在该模型下,当fd可读/写时,kernel就会通过回调函数通知应用程序;而POSIX规范的异步模型引入了一组异步IO操作函数且IO操作完成后,kernel才会通知应用程序。也即,它们的区别仅在于kernel通知应用进程的时机,其余的流程是相似的。
需要说明的是,并非所有的Linux发行版本均支持signal-driven IO模型,实际使用时,需要通过系统手册来确认这种模型是否可用。
6. Asynchronous I/O Model
异步IO模型是在POSIX规范中定义的,概括来说,它的工作模式是:调用异步IO函数以告知kernel开始读/写操作,对异步IO函数的调用会立即返回,当IO操作完成后(以read操作为例,操作完成意味着数据已经从内核缓冲区copy至进程缓冲区),kernel会根据异步IO函数参数中设置的方式来通知应用进程。
以UDP socket的asynchronous IO模型为例,其过程如下图所示。
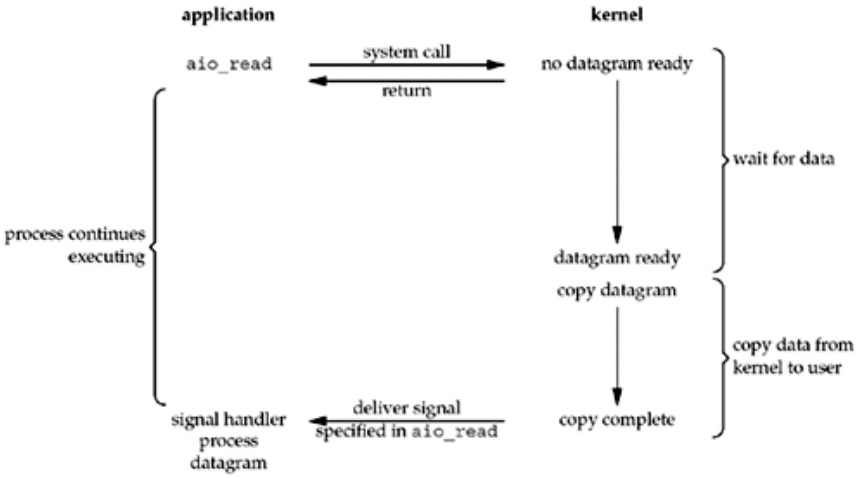
从上图可见,异步IO模型中,socket对应的数据从内核buffer至进程buffer的拷贝过程完成后,应用进程才会收到通知。
POSIX规范的异步IO模型与signal-driven IO模型的区别前面已经做过说明,这里不赘述。
需要说明的是,并非所有的Linux发行版本都支持符合POSIX规范的异步模型,使用前需确认。
7. I/O模型的总结比较
下面是5种典型I/O模型的对比示意图。

总结说明如下:
- blocking模型下,从应用进程调用IO操作函数到函数返回期间,进程处于阻塞状态;
- nonblocking模型下,应用程序调用IO操作函数时,函数会立即返回,但应用程序需要通过不断调用IO操作函数来轮询kernel,以便进行读/写操作;
- io多路复用模型下,应用程序调用select或poll时,进程阻塞直到select管理的fd可读/写,select或poll返回后,应用程序需要调用真正的IO操作函数进行读/写操作;
- signal-driven模型下,应用程序向kernel注册信号回调函数,当目标fd可读/写时,kernel通过回调通知应用程序进行数据读/写。它避免了进程阻塞;
- asynchronous io模型下,应用程序调用异步IO函数时,函数立即返回,当函数完成真正的IO操作后,kernel会通知应用程序进行后续操作。它也避免了进程阻塞。
8. 补充说明
POSIX规范对同步(synchronous)和异步(asynchronous)的定义如下:
A synchronous I/O operation causes the requesting process to be blocked until that I/O operation completes.
An asynchronous I/O operation does not cause the requesting process to be blocked.
按照这种定义,上面介绍的前4中IO模型均是同步的,因为真正的IO操作函数在进行数据读/写时,均会阻塞进程;只有异步IO模型真正符合异步IO操作的定义。
需要特别说明的是,目前流行的Web Server(如nginx)通常是通过内核提供的epoll或kqueue来管理fd的。
以epoll为例,其工作模式与本文介绍的I/O多路复用模型类似,只不过其管理的fd(s)满足读/写条件时,内核会通过回调通知epoll来获取这些fd,应用程序调用的epoll_wait会将这些可读/写的fd返回给应用程序;而采用select方式实现IO多路复用模式时,符合读/写条件的fd是通过select内部遍历整个fd数组来获取的,显然,epoll方式下的fd触发方式更高效。也正是由于回调触发避免了线性遍历,epoll可管理的fd数量可以很大且不影响触发性能。
由于epoll是通过事件驱动的(其事件触发方式分为Edge Triggered和Level Triggered两种,二者区别可通过man epoll查看),因此,借助epoll实现的IO操作模式又被称为Event-Driven I/O模型。
在epoll模式下,由于epoll_wait通常是个阻塞调用,故epoll是个阻塞模型;至于同步还是异步,与epoll管理的fd被触发后的处理方式有关。
具体而言:
1) 若其管理的fd可读/写条件触发后,进程主线程负责处理该fd对应的数据,则由于回调函数中真正进行数据读/写的IO操作仍然会阻塞(这里的阻塞是指从内核缓冲区拷贝数据至应用进程缓冲区的过程中,进程主线程会阻塞,阻塞时间取决于数据量),因此,从POSIX规范对同步/异步的定义来看,这种处理逻辑下的epoll模型是个同步模型。
2) 若其管理的fd可读/写条件触发后,进程主线程将该fd压入队列,由其它线程负责从队列中消费该fd,则由于主线程不会阻塞,故这种处理逻辑下,此时的epoll模型是个异步模型。
【参考资料】
- Unix Network Programming, Volume 1, Chapter6.2: I/O Models
- StackOverflow: What is the status of POSIX asynchronous I/O (AIO)?
- Wikipedia: Asynchronous I/O
==================== EOF =================
以上是关于网络编程笔记Linux系统常见的网络编程I/O模型简述的主要内容,如果未能解决你的问题,请参考以下文章