DATA AI Summit 2022提及到的对 aggregate 的优化
Posted 鸿乃江边鸟
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了DATA AI Summit 2022提及到的对 aggregate 的优化相关的知识,希望对你有一定的参考价值。
背景
本文基于SPARK 3.3.0
HashAggregate的优化
该优化是FaceBook(Meta) 内部的优化,还有合并到spark社区。
该优化的主要是partialaggregate的部分:对于类似求count,sum,Avg的聚合操作,会存在现在mapper进行部分聚合的操作,之后在reduce端,再进行FinalAggregate操作。这看起来是没有问题的(能够很好的减少网络IO),但是我们知道对于聚合操作,我们会进行数据的spill的操作,如果在mapper阶段合并的数据很少,以至于抵消不了网络IO带来的消耗的话,这无疑会给任务带来损耗。
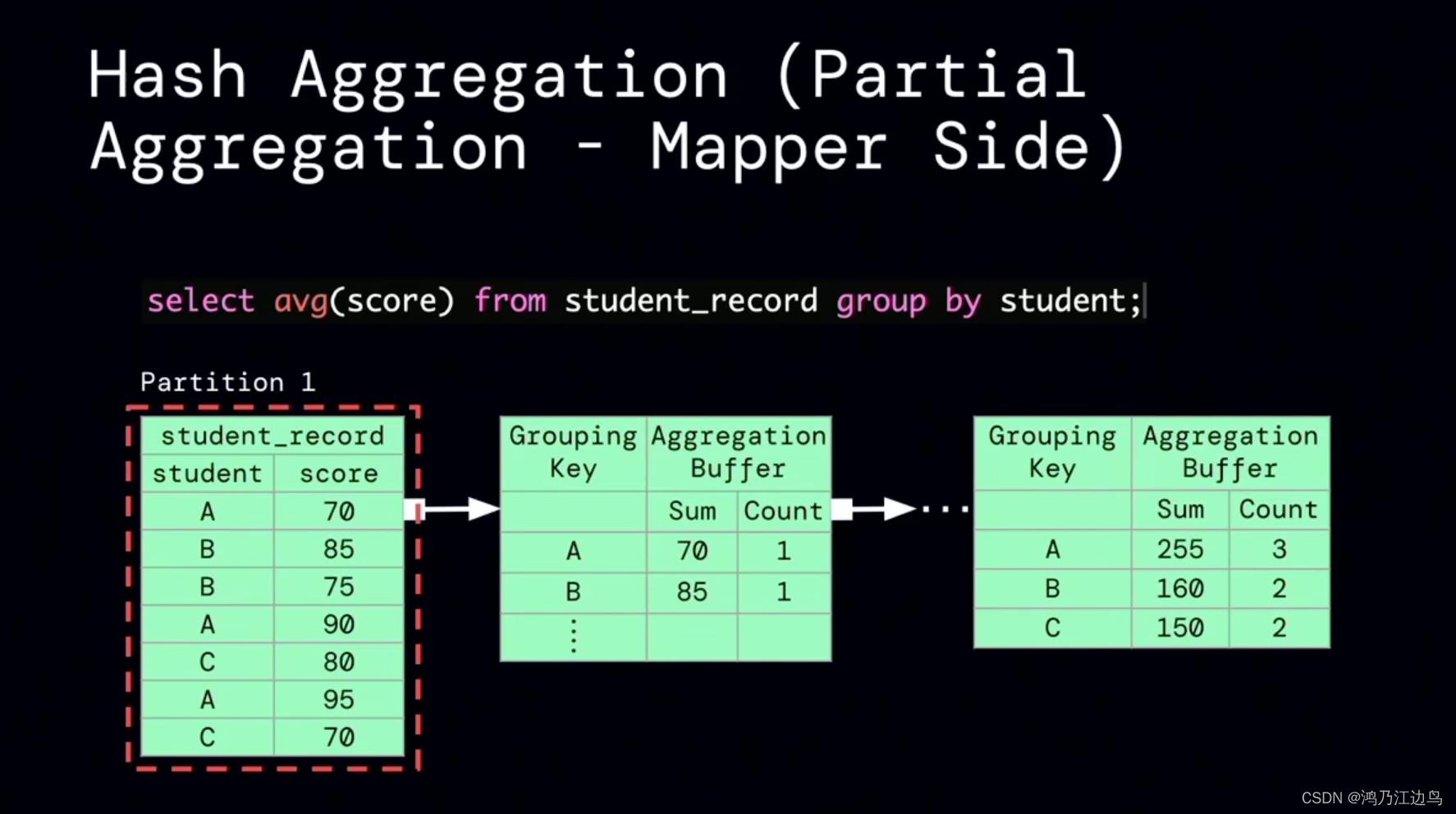
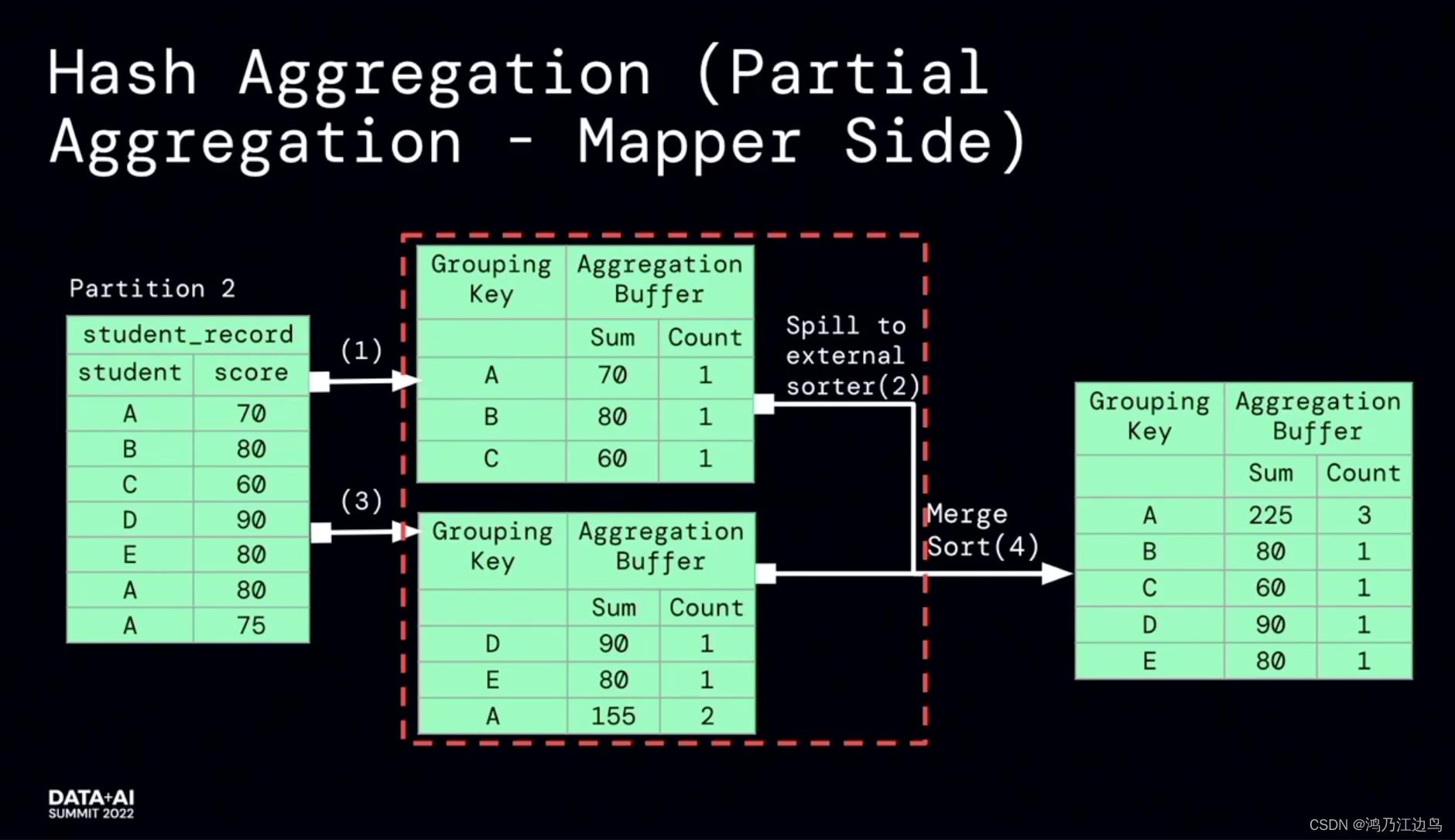
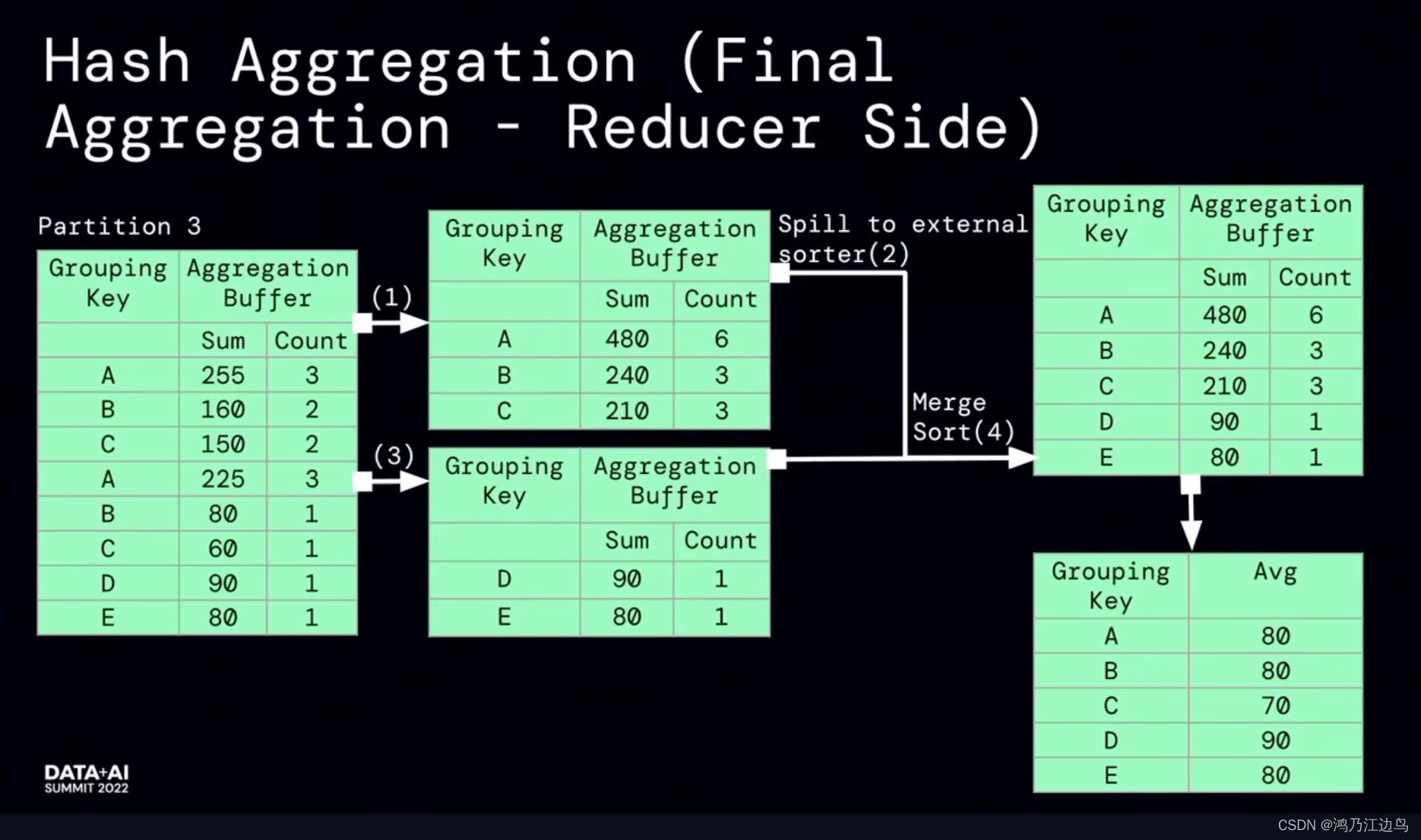
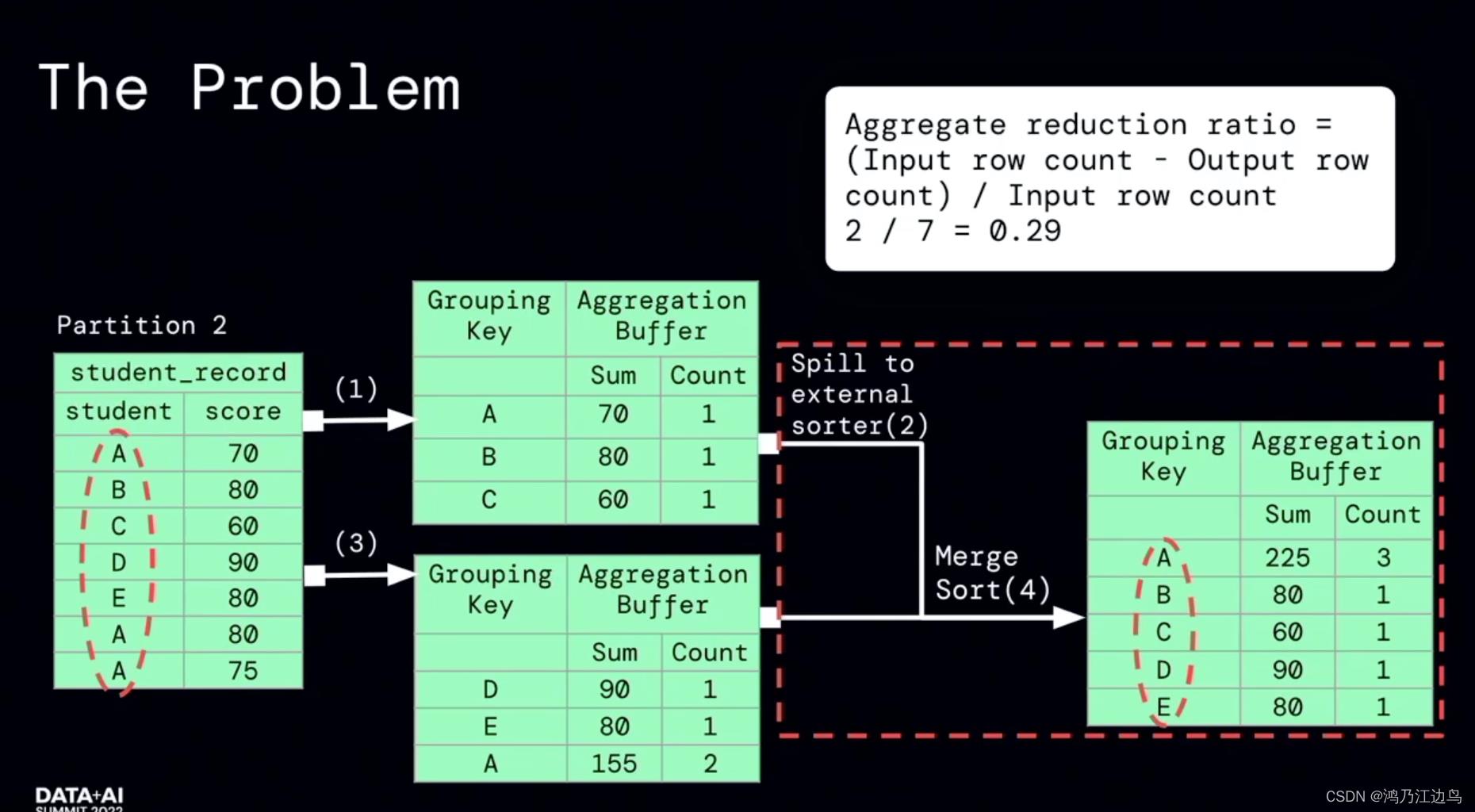
利用运行时的指标信息,能够达到比较好的加速效果。
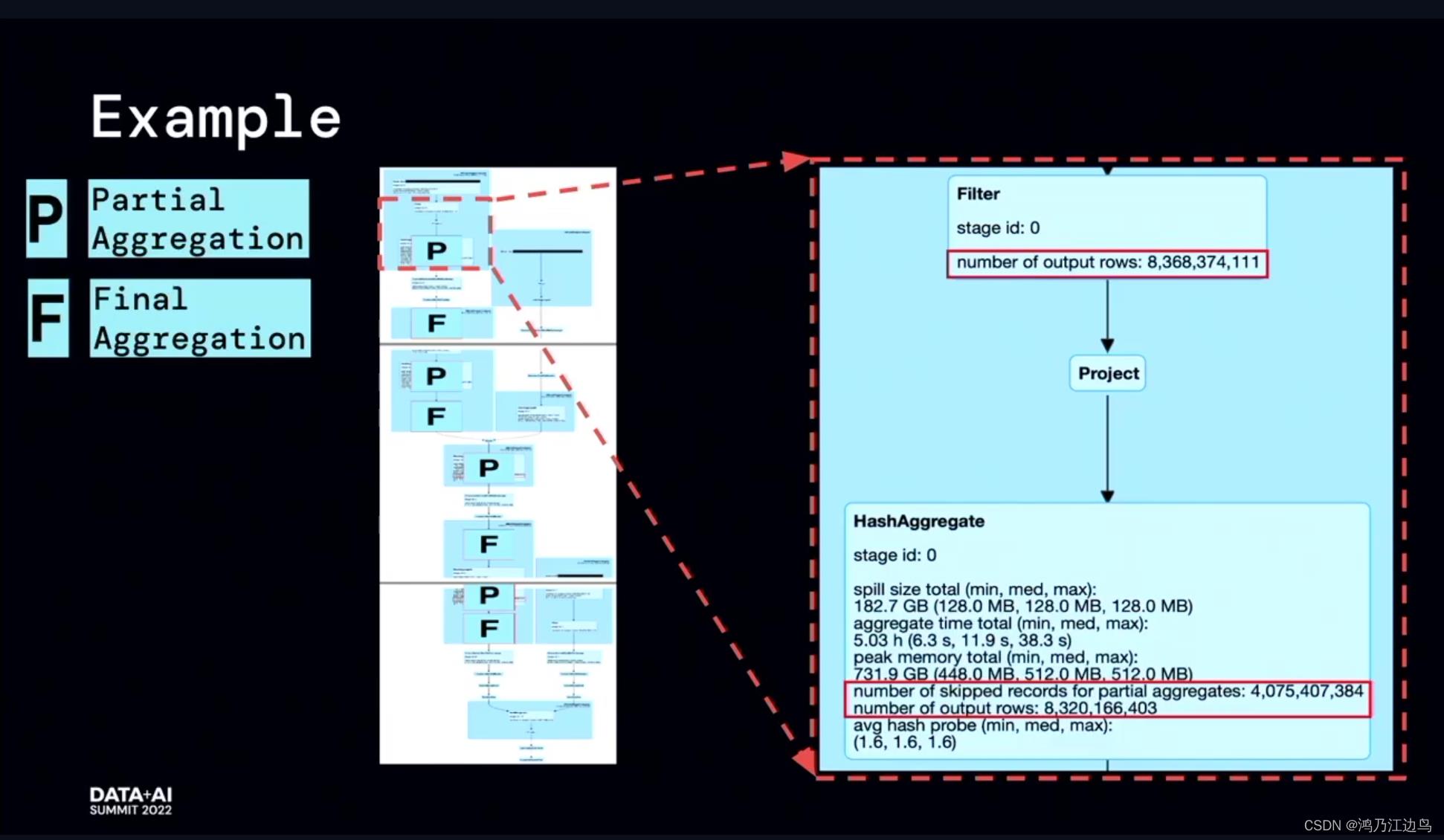
ObjectHashAggregate的优化
对于ObjectHashAggreate的原理,可以参考深入理解SPARK SQL 中HashAggregateExec和ObjectHashAggregateExec以及UnsafeRow,该文可以比较清楚的解释ObjectHashAggregate和HashAggregate的区别:
- ObjectHashAggregate能够弥补HashAggregate 不能支持collect_set等这种表达式,从而不会转变为SortAggregate
- ObjectHashAggregate利用的是java Array对象(SpecificInternalRow)保存聚合的中间缓冲区,这对jvm gc是不太友好的
- ObjectHashAggregate根据hashMap的size(默认是128),而不是输入的行数来进行spill,这会导致提前spill,内存利用率不高。
- 由于提前的spill,ObjectHashAggregate会对剩下的所有数据做额外的一次排序操作(如果没有spill,就不需要额外的sort操作),而HashAggregate则是会对每次需要spill的数据做排序
使用jvm heap的内存使用情况以及处理的行数来指导什么时候开始spill。
但是这种在数据倾斜的情况下,会增加OOM的风险。
SortAggregate优化
目前SortAggreaget的现状是:
- 每个任务在sort Aggreate前需要按照key进行排序
- 根据排序的结果,在相邻的行之间进行聚合操作
不同于Hash Aggregate: - 不需要hashTable,也就不存在内存溢写和回退到sortAggregate
- 优化器更喜欢选择hashAggregate
- 没有codegen的实现.
目前在spark 3.3.0增加的功能:
- 如果数据是有序的话,会选择用sortAggragate替代HashAggregate
通过物理计划RuleReplaceHashWithSortAgg来做替换,当然通过spark.sql.execution.replaceHashWithSortAgg来开启(默认是关闭的),因为对于任何新特性,在release版本默认都是关闭的,在master分支才是开启的 - 支持sortAggretate(without keys)的codegen代码生成
其他
对于Aggregate更多的细节了解可以参考sparksql源码系列 | 一文搞懂with one count distinct 执行原理
以上是关于DATA AI Summit 2022提及到的对 aggregate 的优化的主要内容,如果未能解决你的问题,请参考以下文章