戴口罩人脸检测和戴口罩识别(含Python Android源码)
Posted AI吃大瓜
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了戴口罩人脸检测和戴口罩识别(含Python Android源码)相关的知识,希望对你有一定的参考价值。
戴口罩人脸检测和戴口罩识别(含Python android源码)
目录
戴口罩人脸检测和戴口罩识别(含Python Android源码)
(4) 运行APP闪退:dlopen failed: library "libomp.so" not found
当前疫情反反复复,而防控新冠病毒的最有效手段之一就是戴口罩,因此研究戴口罩检测和识别具有重大意义。疫情防控,人人有责,作为一名程序狗,分享一下鄙人开发的戴口罩人脸检测和戴口罩识别方法。目前项目开发的戴口罩识别(face-mask recognition)的准确率还挺高的,在resnet50,可以高达99%的准确率,即使采用轻量化版本MobileNet-v2,准确率也可以高达98.18%左右。
本项目将手把手教你训练一个戴口罩分类识别模型,包括如何转为ONNX,TNN模型,并移植到Android上进行部署,实现一个戴口罩识别的Android Demo APP 。数据和源码都已备好了,准备好上船吧~
Demo效果展示:
| 图片测试 | 视频测试 |
 |  |
- 戴口罩人脸检测和戴口罩识别Android Demo APP免费体检:https://download.csdn.net/download/guyuealian/85771596
- 戴口罩人脸检测和戴口罩识别整套项目(含数据,训练代码,Android源码):戴口罩人脸检测和戴口罩识别(含Python Android源码)
整套项目项目,支持的主要内容主要有:
- 包含5个数据集: facemask-train1, facemask-train2,facemask-train3, synthetic-train1,synthetic-train2 ,facemask-test ,总共约有50000+的数据:
- 生成戴口罩人脸代码: python create_facemask.py
- 支持戴口罩人脸检测
- 支持戴口罩识别:mask(戴口罩)和nomask(未佩戴口罩)
- 提供戴口罩识别Python Demo源码,在普通电脑CPU/GPU上可以实时检测和识别
- 提供戴口罩识别Android Demo源码,在普通手机CPU/GPU上可以实时检测和识别,约30ms左右
1.戴口罩识别的方法
(1)基于多类别目标检测的戴口罩识别方法
基于多类别目标检测的戴口罩识别方法,一步到位,把未戴口罩(nomask)和戴口罩(mask)两个类别直接当成两个目标检测的类别进行训练
- 优点:直接端到端训练,任务简单,速度快
- 缺点:需要人工标注人脸框mask和nomask,时间花费比较大;训练数据不足的情况下,容易出现误检测的情况
(2)基于人脸检测+戴口罩分类识别方法
该方法,先采用通用的人脸检测模型,进行人脸检测,然后裁剪人脸区域,再训练一个戴口罩分类器,对人脸进行分类识别(未戴口罩和戴口罩)
- 优点:不需要标注人脸框数据,可以自己合成戴口罩人脸数据,人工成本低;精度高,可针对分类模型进行轻量化
- 缺点:需要部署两个模型(人脸检测模型和戴口罩分类模型),人脸越多,速度越慢
考虑到数据标注成本的问题,本项目采用第二种方法,即采用基于人脸检测+戴口罩分类识别方法
2.戴口罩人脸数据集
网上绝大部分人脸数据都是不戴口罩的人脸,不能直接用于戴口罩识别中。鉴于此,我们可以考虑自己合成/生成戴口罩的人脸数据,以下是鄙人收藏和整理的戴口罩人脸数据集和合成的数据集,总共约有50000+的数据:
| 原始图片 | 生成戴口罩人脸 |
|
|
|


关于戴口罩人脸数据和生成方法,详细使用说明请参考我的一篇博客《戴口罩人脸数据集和戴口罩人脸生成方法》
| 数据集 | 说明 |
| facemask-train1 |
|
| facemask-train2 |
|
| facemask-train3 |
|
| synthetic-train1 |
|
| synthetic-train2 |
|
| facemask-test |
|
3.戴口罩人脸检测
通常我们理解的人脸检测是指没有遮挡或者只有少许遮挡情况下的人脸检测,当人脸戴有口罩,其检测效果势必会变得比较差,而大量标注带有人脸口罩的人脸数据集还是比较耗时费力的。所以我的方法是:
先在WiderFace人脸数据集上,训练人脸检测;然后在facemask-train1数据集finetune人脸检测模型,经过这个方法训练后,其戴口罩检测效果会好很多。
当然,即使使用开源的人脸检测算法,在带有口罩人脸检测,其实效果也不会太差,比如使用FaceBox,MTCNN检测带有口罩的图片,效果也可以的,只不过会经常出现人脸检测框不完整,存在缺少等问题,对后续的戴口罩的识别有一定的影响。
关于人脸检测的方法,可以参考我的另一篇博客:
 https://panjinquan.blog.csdn.net/article/details/125348189
https://panjinquan.blog.csdn.net/article/details/1253481894.戴口罩识别模型训练
本项目将手把手教你训练一个戴口罩分类识别模型,包括如何转为ONNX,TNN模型,并移植到
Android上进行部署,实现一个戴口罩识别的Android APP Demo
整套工程项目基本结构如下:
.
├── classifier # 训练模型相关工具
├── configs # 训练配置文件
├── data # 训练数据
├── libs
│ ├── convert # 将模型转换为ONNX工具
│ ├── facemask # 戴口罩人脸数据生成工具
│ ├── light_detector # 人脸检测
│ ├── create_facemask.py # 戴口罩人脸数据生成demo
│ ├── detector.py # 人脸检测demo
│ └── README.md
├── demo.py # 戴口罩人脸识别demo
├── README.md # 项目工程说明文档
├── requirements.txt # 项目相关依赖包
└── train.py # 训练文件(1)准备数据
总共有5个数据集,包括 facemask-train1, facemask-train2,facemask-train3,synthetic-train1,synthetic-train2 ,facemask-test ,总共约有50000+的数据。

当然,你也可以使用自己的数据集,数据结构如下,其中mask目录存放戴口罩的人脸图片,而nomask目录存放未戴口罩的人脸图像。

(2)戴口罩分类模型训练(Pytorch)
鄙人在《Pytorch基础训练库Pytorch-Base-Trainer(支持模型剪枝 分布式训练)》基础上实现了戴口罩和未佩戴口罩二分类识别训练和测试,整套训练代码非常简单操作,用户只需要将相同类别的数据放在同一个目录下,并填写好对应的数据路径,即可开始训练了。
训练框架采用Pytorch,整套训练代码支持的内容主要有:
- 目前支持的backbone有:googlenet,resnet[18,34,50], ,mobilenet_v2等, 其他backbone可以自定义添加
- 训练参数可以通过(configs/config.yaml)配置文件进行设置
训练参数说明如下:
# 设置训练数据集,支持多个训练数据集
train_data:
- 'dataset/face_mask/facemask-train1/crops'
- 'dataset/face_mask/facemask-train2/crops'
- 'dataset/face_mask/facemask-train3/crops'
- 'dataset/face_mask/synthetic-train1/crops'
- 'dataset/face_mask/synthetic-train1/crops'
# 设置测试数据集
test_data: 'dataset/face_mask/facemask-test/crops'
class_name: 'dataset/face_mask/class_name.txt' # 类别标签
train_transform: "train" # 训练使用的数据增强方法
test_transform: "val" # 测试使用的数据增强方法
work_dir: "work_space/" # 保存输出模型的目录
net_type: "mobilenet_v2" # 骨干网络,支持:resnet18,mobilenet_v2,googlenet
resample: True # 进行样本均衡
width_mult: 1.0
input_size: [ 128,128 ]
rgb_mean: [ 0.5, 0.5, 0.5 ] # for normalize inputs to [-1, 1],Sequence of means for each channel.
rgb_std: [ 0.5, 0.5, 0.5 ] # for normalize,Sequence of standard deviations for each channel.
batch_size: 64
lr: 0.01 # 初始学习率
optim_type: "SGD" # 选择优化器,SGD,Adam
loss_type: "LabelSmoothing" # 选择损失函数:支持CrossEntropyLoss,LabelSmoothing
momentum: 0.9 # SGD momentum
num_epochs: 100 # 训练循环次数
num_warn_up: 3 # warn-up次数
num_workers: 8 # 加载数据工作进程数
weight_decay: 0.0005 # weight_decay,默认5e-4
scheduler: "multi-step" # 学习率调整策略
milestones: [ 20,50,80 ] # 下调学习率方式
gpu_id: [ 0 ] # GPU ID
log_freq: 50 # LOG打印频率
progress: True # 是否显示进度条
pretrained: False # 是否使用pretrained模型
finetune: False # 是否进行finetune开始训练:
python train.py -c configs/config.yaml
训练完成后,训练集的Accuracy在99%以上,测试集的Accuracy在98%左右
(3) 可视化训练过程
训练过程可视化工具是使用Tensorboard,使用方法:
# 基本方法
tensorboard --logdir=path/to/log/
# 例如
tensorboard --logdir=work_space/mobilenet_v2_1.0_CrossEntropyLoss/log
可视化效果
 | 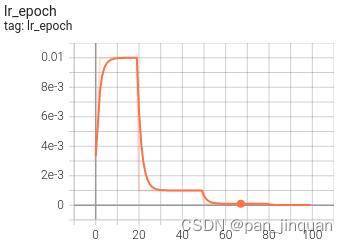 |
 |  |
 | 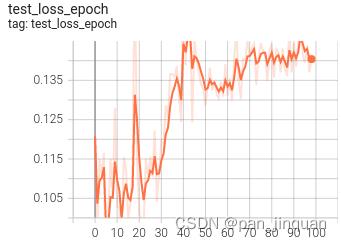 |
(4) 戴口罩识别效果
 |  |
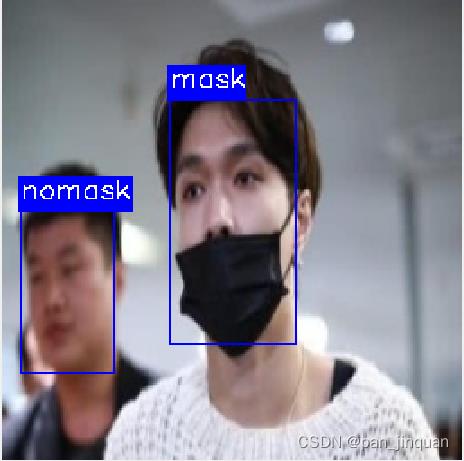 |  |
 |  |
5.戴口罩识别模型Android部署
(1) 将Pytorch模型转换ONNX模型
训练好Pytorch模型后,你可以将模型转换为ONNX模型,方便后续模型部署
python libs/convert/convert_torch_to_onnx.py"""
This code is used to convert the pytorch model into an onnx format model.
"""
import sys
import os
sys.path.insert(0, os.getcwd())
import torch.onnx
import onnx
from classifier.models.build_models import get_models
from basetrainer.utils import torch_tools
def build_net(model_file, net_type, input_size, num_classes, width_mult=1.0):
"""
:param model_file: 模型文件
:param net_type: 模型名称
:param input_size: 模型输入大小
:param num_classes: 类别数
:param width_mult:
:return:
"""
model = get_models(net_type, input_size, num_classes, width_mult=width_mult, is_train=False, pretrained=False)
state_dict = torch_tools.load_state_dict(model_file)
model.load_state_dict(state_dict)
return model
def convert2onnx(model_file, net_type, input_size, num_classes, width_mult=1.0, device="cpu", onnx_type="default"):
model = build_net(model_file, net_type, input_size, num_classes, width_mult=width_mult)
model = model.to(device)
model.eval()
model_name = os.path.basename(model_file)[:-len(".pth")] + ".onnx"
onnx_path = os.path.join(os.path.dirname(model_file), model_name)
# dummy_input = torch.randn(1, 3, 240, 320).to("cuda")
dummy_input = torch.randn(1, 3, input_size[1], input_size[0]).to(device)
# torch.onnx.export(model, dummy_input, onnx_path, verbose=False,
# input_names=['input'],output_names=['scores', 'boxes'])
do_constant_folding = True
if onnx_type == "default":
torch.onnx.export(model, dummy_input, onnx_path, verbose=False, export_params=True,
do_constant_folding=do_constant_folding,
input_names=['input'],
output_names=['output'])
elif onnx_type == "det":
torch.onnx.export(model,
dummy_input,
onnx_path,
do_constant_folding=do_constant_folding,
export_params=True,
verbose=False,
input_names=['input'],
output_names=['scores', 'boxes', 'ldmks'])
elif onnx_type == "kp":
torch.onnx.export(model,
dummy_input,
onnx_path,
do_constant_folding=do_constant_folding,
export_params=True,
verbose=False,
input_names=['input'],
output_names=['output'])
onnx_model = onnx.load(onnx_path)
onnx.checker.check_model(onnx_model)
print(onnx_path)
if __name__ == "__main__":
net_type = "mobilenet_v2"
width_mult = 1.0
input_size = [128, 128]
num_classes = 2
model_file = "work_space/mobilenet_v2_1.0_CrossEntropyLoss/model/best_model_022_98.1848.pth"
convert2onnx(model_file, net_type, input_size, num_classes, width_mult=width_mult)
(2) 将ONNX模型转换为TNN模型
目前CNN模型有多种部署方式,可以采用TNN,MNN,NCNN,以及TensorRT等部署工具,鄙人采用TNN进行Android端上部署:
- (1)将ONNX模型转换为TNN模型,请参考TNN官方说明:TNN/onnx2tnn.md at master · Tencent/TNN · GitHub
- (2)一键转换,懒人必备:一键转换 Caffe, ONNX, TensorFlow 到 NCNN, MNN, Tengine (版本问题,这个工具转换的TNN模型可能不兼容,建议还是自己build源码进行转换)
(3) Android端上部署戴口罩识别
项目实现了Android版本的戴口罩识别Demo,部署框架采用TNN,支持多线程CPU和GPU加速推理,在普通手机上可以实时处理。戴口罩识别Android源码,核心算法均采用C++实现,上层通过JNI接口调用.
如果你想在这个Android Demo部署你自己训练的分类模型,你可将训练好的Pytorch模型转换ONNX ,再转换成TNN模型,然后把TNN模型代替你模型即可。
package com.cv.tnn.model;
import android.graphics.Bitmap;
public class Detector
static
System.loadLibrary("tnn_wrapper");
/***
* 初始化人脸检测和戴口罩识别模型
* @param face_model: 人脸检测模型(不含后缀名)
* @param class_model:戴口罩识别模型(不含后缀名)
* @param root:模型文件的根目录,放在assets文件夹下
* @param model_type:模型类型
* @param num_thread:开启线程数
* @param useGPU:关键点的置信度,小于值的坐标会置-1
*/
public static native void init(String face_model, String class_model, String root, int model_type, int num_thread, boolean useGPU);
/***
* 人脸检测和戴口罩识别
* @param bitmap 图像(bitmap),ARGB_8888格式
* @param score_thresh:置信度阈值
* @param iou_thresh: IOU阈值
* @return
*/
public static native FrameInfo[] detect(Bitmap bitmap, float score_thresh, float iou_thresh);
(4) 运行APP闪退:dlopen failed: library "libomp.so" not found
参考解决方法:
解决dlopen failed: library “libomp.so“ not found_PKing666666的博客-CSDN博客_dlopen failed
6.项目源码下载
整套项目源码内容包含:
- 包含5个数据集: facemask-train1, facemask-train2,facemask-train3, synthetic-train1,synthetic-train2 ,facemask-test ,总共约有50000+的数据:
- 生成戴口罩人脸代码: python create_facemask.py
- 戴口罩分类模型训练和测试代码 Pytorch版本,测试Demo在普通电脑CPU/GPU上可以实时检测和识别
- 戴口罩识别Android Demo源码,支持CPU和GPU,在普通手机上可以实时检测和识别,约30ms左右
- 戴口罩人脸检测和戴口罩识别Android Demo APP免费体检:https://download.csdn.net/download/guyuealian/85771596
- 戴口罩人脸检测和戴口罩识别整套项目(含数据,训练代码,Android源码):戴口罩人脸检测和戴口罩识别(含Python Android源码)
以上是关于戴口罩人脸检测和戴口罩识别(含Python Android源码)的主要内容,如果未能解决你的问题,请参考以下文章